TinkerPop中的遍历:图的遍历步骤(3/3)
48 Project Step
project() 步骤(map)将当前对象投射到由提供的标签键入的Map<String,Object>中。
gremlin> g.V().out('created').
project('a','b').
by('name').
by(__.in('created').count())
==>[a:lop,b:3]
==>[a:lop,b:3]
==>[a:lop,b:3]
==>[a:ripple,b:1]
使用该步骤,可以提供灵活的方式进行遍历的调整。如根据(工程)创建者的人数进行排序,并返回(工程)的名字:
gremlin> g.V().out('created').
project('a','b').
by('name').
by(__.in('created').count()).
order().by(select('b'),decr).
select('a')
==>lop
==>lop
==>lop
==>ripple
49 Program Step
program() - 步骤(map / sideEffect)是GraphComputer作业的“lambda”步骤。该步骤将使用VertexProgram作为参数,并相应地处理传入图形。因此,用户可以创建自己的VertexProgram并使其在遍历中执行。
比如,使用PageRankVertexProgram 计算PageRank,并降序排列:
gremlin> g = graph.traversal().withComputer()
gremlin> g.V().program(PageRankVertexProgram.build().property('rank').create(graph)).
order().by('rank', decr).
valueMap('name', 'rank')
==>[name:[lop],rank:[0.4018125]]
==>[name:[ripple],rank:[0.23181250000000003]]
==>[name:[vadas],rank:[0.19250000000000003]]
==>[name:[josh],rank:[0.19250000000000003]]
==>[name:[marko],rank:[0.15000000000000002]]
==>[name:[peter],rank:[0.15000000000000002]]
Note
开发VertexProgram是专家用户,需要对OLAP有深入研究。
50 Properties Step
properties()步骤(map)从遍历流中的Element中提取属性。
gremlin> g.V().properties()
==>vp[name->marko]
==>vp[age->29]
==>vp[name->lop]
==>vp[lang->java]
==>vp[name->vadas]
==>vp[age->27]
==>vp[name->josh]
==>vp[age->32]
==>vp[name->ripple]
==>vp[lang->java]
==>vp[name->peter]
==>vp[age->35]
51 PropertyMap Step
propertiesMap()- 步骤产生元素属性的Map表示。
gremlin> g.V().propertyMap()
==>[name:[vp[name->marko]],age:[vp[age->29]]]
==>[name:[vp[name->vadas]],age:[vp[age->27]]]
==>[name:[vp[name->lop]],lang:[vp[lang->java]]]
==>[name:[vp[name->josh]],age:[vp[age->32]]]
==>[name:[vp[name->ripple]],lang:[vp[lang->java]]]
==>[name:[vp[name->peter]],age:[vp[age->35]]]
52 Range Step
range()步骤(filter)用于指定范围。
如返回第0/1/2个顶点:
gremlin> g.V().range(0,3) //返回位置在[0,3)即0,1,2的节点
==>v[1]
==>v[3]
==>v[2]
53 Repeat Step
`repeat()·步骤(branch)会根据给定的谓词(predicate)进行循环遍历。
如以下语句产生相同的结果:
gremlin> g.V(1).out().out().values('name')
==>ripple
==>lop
gremlin> g.V(1).repeat(out()).times(2).values('name')
==>ripple
==>lop
- 发现两个节点之间存在的关系
从id为1的节点开始向外发现关系,直至发现name=ripple的节点,输出所遍历路径上节点的名字:
gremlin> g.V(1).until(has('name','ripple')).repeat(out()).path().by('name')
==>[marko,josh,ripple]
repeat()有两个调制器:until()和emit()。
until()
如果until()在repeat()之后出现,则是do/while循环。如果until()在repeat()之前出现,则是while/do循环。emit()
如果在repeat()之后放置emit(),则对遍历遍历器进行重复遍历评估。如果将emit()放在repeat()之前,则在进入重复遍历之前对遍历器进行求值。
除了emit()位置不同造成的影响外,emit()还使得repeat()中每次循环都会输出。
gremlin> g.V(1).repeat(out()).times(2).values('name') //两次循环完后的节点
==>ripple
==>lop
gremlin> g.V(1).repeat(out()).emit().times(2).values('name') //一次循环和两次循环结果都返回
==>lop
==>vadas
==>josh
==>ripple
==>lop
gremlin> g.V(1).emit().repeat(out()).times(2).values('name') //初始节点1、一次循环和两次循环结果都返回
==>marko
==>lop
==>vadas
==>josh
==>ripple
==>lop
emit()和until()可以加入限定,比如:
//从节点1开始按照向外的方向发现节点,直至叶子节点(没有向外发出的边)
gremlin> g.V(1).repeat(out()).until(outE().count().is(0)).path().by('name')
==>[marko,lop]
==>[marko,vadas]
==>[marko,josh,ripple]
==>[marko,josh,lop]
//从节点1开始按照向外的方向发现节点,所有路径上出现的人名字都输出
gremlin> g.V(1).repeat(out()).emit(hasLabel('person')).path().by('name')
==>[marko,vadas]
==>[marko,josh]
54 Sack Step
遍历器可以包含称为“麻袋(sack)”的本地数据结构。 sack()步骤用于读取和写入sack(sideEffect或map)。每个遍历器的每个袋子都会在使用以下语句时创建:
GraphTraversal.withSack(initialValueSupplier,splitOperator?,mergeOperator?).
- Initial value supplier: 供应商提供每个横穿袋的初始值。
- Split operator: 一个一元操作符克隆(UnaryOperator),它会在遍历器分裂时克隆所有的sack。
- Merge operator: 一个二进制运算符,它会在两个遍历器合并时,统一它们的sack。
Initial value supplier的例子:
gremlin> g.withSack(1.0f).V().sack()
==>1.0
==>1.0
==>1.0
==>1.0
==>1.0
==>1.0
gremlin> rand = new Random()
==>java.util.Random@4a52178
gremlin> g.withSack {rand.nextFloat()}.V().sack()
==>0.5063787
==>0.1647762
==>0.69914645
==>0.042134523
==>0.18742532
==>0.0388152
下面给出了一个更复杂的Initial value supplier示例,其中sack运行值用于运行计算,然后在遍历结束时打印出来。当某条边被遍历后,边缘权重会乘以sack值:
gremlin> g.withSack(1.0f).V(1).repeat(outE().sack(mult).by('weight').inV()).times(2).path().sack()
==>1.0
==>0.4
Note
mult来自于静态引入的Operator.mult。
sack()语法还有其他两个可选参数Split operator 和Merge operator。
查看:http://tinkerpop.apache.org/docs/current/reference/#sack-step
55 Sample Step
sample()步骤对于在遍历之前的某些数量的遍历器进行抽样很有用。
gremlin> g.V().out('knows')
==>v[2]
==>v[4]
gremlin> g.V().out('knows').sample(1)
==>v[2]
gremlin> g.V().out('knows').sample(1)
==>v[4]
56 Select Step
Gremlin数据流处理图形处理的一个区别在于流程不一定要“前进”,但实际上可以回到之前看到的计算区域。
一般有两种方法来使用select()步骤(map)。
- 在路径中选择标记的步骤(在遍历中由
as()定义)。 - 从
Map <String,Object>流(即子地图)中选择对象。
- 使用
as()在路径中标记
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')
==>[a:v[1],b:v[4],c:v[5]]
==>[a:v[1],b:v[4],c:v[3]]
- 使用map进行映射
gremlin> g.V().out('created').
project('a','b').
by('name').
by(__.in('created').count()).
select(`a`)
==>lop
==>lop
==>lop
==>ripple
- 使用
where()进行过滤
例如,找出所有项目的共同开发者:
gremlin> g.V().as('a').out('created').in('created').as('b').select('a','b').by('name') //“共同开发者”包含自己
==>[a:marko,b:marko]
==>[a:marko,b:josh]
==>[a:marko,b:peter]
==>[a:josh,b:josh]
==>[a:josh,b:marko]
==>[a:josh,b:josh]
==>[a:josh,b:peter]
==>[a:peter,b:marko]
==>[a:peter,b:josh]
==>[a:peter,b:peter]
gremlin> g.V().as('a').out('created').in('created').as('b').select('a','b').by('name').where('a',neq('b')) //“共同开发者”排除自己
==>[a:marko,b:josh]
==>[a:marko,b:peter]
==>[a:josh,b:marko]
==>[a:josh,b:peter]
==>[a:peter,b:marko]
==>[a:peter,b:josh]
57 SimplePath Step
当遍历时不想获取循环的路径,那么使用simplePath();当想获取循环路径,则使用cyclicPath()。若不指定,则返回全部路径。
gremlin> g.V(1).both().both().path() //所有路径
==>[v[1],v[3],v[1]]
==>[v[1],v[3],v[4]]
==>[v[1],v[3],v[6]]
==>[v[1],v[2],v[1]]
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
==>[v[1],v[4],v[1]]
gremlin> g.V(1).both().both().simplePath().path() //非重复路径
==>[v[1],v[3],v[4]]
==>[v[1],v[3],v[6]]
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
gremlin> g.V(1).both().both().cyclicPath().path() //重复路径
==>[v[1],v[3],v[1]]
==>[v[1],v[2],v[1]]
==>[v[1],v[4],v[1]]
58 Skip Step
gremlin> g.V().values('age').order()
==>27
==>29
==>32
==>35
gremlin> g.V().values('age').order().skip(2)
==>32
==>35
gremlin> g.V().values('age').order().range(2, -1)
==>32
==>35
59 Store Step
gremlin> g.V().aggregate('x').limit(1).cap('x')
==>[v[1],v[2],v[3],v[4],v[5],v[6]]
gremlin> g.V().store('x').limit(1).cap('x')
==>[v[1],v[2]]
有趣的是,即使limit()选择是针对1个对象,store()也有两个结果。官网解释为“Realize that when the second object is on its way to the range() filter (i.e. [0..1]), it passes through store() and thus, stored before filtered.”
60 Subgraph Step
subgraph()步骤(sideEffect)提供了从遍历生成边导出子图(Edge-Induced Subgraph)。
以下示例演示如何生成由边“knows”导出的子图:
gremlin> subGraph = g.E().hasLabel('knows').subgraph('subGraph').cap('subGraph').next() //1
==>tinkergraph[vertices:3 edges:2]
gremlin> sg = subGraph.traversal()
==>graphtraversalsource[tinkergraph[vertices:3 edges:2], standard]
gremlin> sg.E() //2
==>e[7][1-knows->2]
==>e[8][1-knows->4]
1:subgraph()需要在边步骤操作后调用;
2:子图中只含有“knows”的边。
更常见的子图用例是获取围绕单个顶点的所有图形结构.
例如,从顶点3开始,按照入射边的方向逆行1次,将结果全部输出到子图中:
gremlin> subGraph = g.V(3).repeat(__.inE().subgraph('subGraph').outV()).times(1).cap('subGraph').next()
==>tinkergraph[vertices:4 edges:3]
gremlin> sg = subGraph.traversal()
==>graphtraversalsource[tinkergraph[vertices:4 edges:3], standard]
gremlin> sg.E()
==>e[9][1-created->3]
==>e[11][4-created->3]
==>e[12][6-created->3]
可以考虑上述例子中,逆行2步的结果:
gremlin> subGraph = g.V(3).repeat(__.inE().subgraph('subGraph').outV()).times(2).cap('subGraph').next()
==>tinkergraph[vertices:4 edges:4]
gremlin> sg = subGraph.traversal()
==>graphtraversalsource[tinkergraph[vertices:4 edges:4], standard]
gremlin> sg.E()
==>e[8][1-knows->4]
==>e[9][1-created->3]
==>e[11][4-created->3]
==>e[12][6-created->3]
接着考虑,逆行3步的结果,在Modern图的情形中,结果是否与逆行2步一样?其实结果是一样的。
61 Sum Step
sum()步骤(map)示例:
gremlin> g.V().values('age')
==>29
==>27
==>32
==>35
gremlin> g.V().values('age').sum()
==>123
62 Tail Step
tail()步骤,用于从尾部开始获取元素。示例如下:
gremlin> g.V().values('age').order()
==>27
==>29
==>32
==>35
gremlin> g.V().values('age').order().tail()
==>35
gremlin> g.V().values('age').order().tail(2)
==>32
==>35
tail()步骤支持Scope.local参数,如下:
gremlin> g.V().valueMap()
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
==>[name:[lop],lang:[java]]
==>[name:[josh],age:[32]]
==>[name:[ripple],lang:[java]]
==>[name:[peter],age:[35]]
gremlin> g.V().valueMap().tail(local,1)
==>[age:[29]]
==>[age:[27]]
==>[lang:[java]]
==>[age:[32]]
==>[lang:[java]]
==>[age:[35]]
63 TimeLimit Step
可能希望遍历执行不超过2毫秒。在这种情况下,可以使用timeLimit()步骤(filter)。
64 To Step
to() - 步骤不是一个实际的步骤,而是一个类似于as()和by()的“步骤调制器”。如果一个步骤能够接受遍历或字符串,那么to()是添加它们的手段。
支持to()的步骤包括:
simplePath()
cyclicPath()
path()
addE()
示例:
gremlin> g.addV().property(id, "101").as("a").
addV().property(id, "102").as("b").
addV().property(id, "103").as("c").
addV().property(id, "104").as("d").
addE("link").from("a").to("b").
addE("link").from("b").to("c").
addE("link").from("c").to("d").iterate()
gremlin> g.V('101').repeat(both().simplePath()).times(3).path()
==>[v[101],v[102],v[103],v[104]]
65 Tree Step
从任何一个元素(即顶点或边),可以聚合来自该元素的发出路径以形成树。 Gremlin为这种情况提供了tree()步骤(sideEffect)。
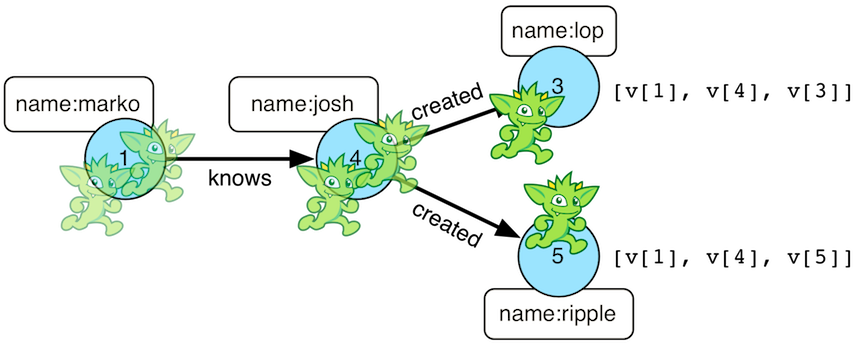
gremlin> tree = g.V().out().out().tree().next()
==>v[1]={v[4]={v[3]={}, v[5]={}}}
- 获取树后进行深度遍历
gremlin> tree = g.V().out().out().tree().next()
==>v[1]={v[4]={v[3]={}, v[5]={}}}
gremlin> tree.getObjectsAtDepth(3)
==>v[3]
==>v[5]
66 Unfold Step
如果达到unfold()(flatMap)的对象是一个迭代器,可迭代或映射,那么它将被展开成一个线性形式。
gremlin> g.V(1).out().fold()
==>[v[3],v[2],v[4]]
gremlin> g.V(1).out().fold().unfold()
==>v[3]
==>v[2]
==>v[4]
67 Union Step
union() 步骤(branch)支持合并任意数量的遍历的结果。当遍历器达到union() 步骤时,它被复制到其每个内部步骤。

gremlin> g.V(4).union(
__.in().values('age'),
out().values('lang'))
==>29
==>java
==>java
gremlin> g.V(4).union(
__.in().values('age'),
out().values('lang')).path()
==>[v[4],v[1],29]
==>[v[4],v[5],java]
==>[v[4],v[3],java]
68 Value Step
value()步骤(map)取一个Property并从中提取该值。
gremlin> g.V(1).properties().value()
69 ValueMap Step
valueMap() 步骤生成元素属性的Map表示。
gremlin> g.V().valueMap()
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
==>[name:[lop],lang:[java]]
==>[name:[josh],age:[32]]
==>[name:[ripple],lang:[java]]
==>[name:[peter],age:[35]]
重要的是注意,顶点的地图维护每个键的值列表。边或顶点属性的映射表示单个属性(不是列表)。原因是TinkerPop3中的顶点会利用每个键支持多个值的顶点属性(VertexProperty)。
如果需要该元素的id,label,key和value,则boolean会将其插入到返回的映射中:
gremlin> g.V().hasLabel('person').valueMap(true)
==>[name:[marko],id:1,location:[san diego,santa cruz,brussels,santa fe],label:person]
==>[name:[stephen],id:7,location:[centreville,dulles,purcellville],label:person]
==>[name:[matthias],id:8,location:[bremen,baltimore,oakland,seattle],label:person]
==>[name:[daniel],id:9,location:[spremberg,kaiserslautern,aachen],label:person]
来源: http://tinkerpop.apache.org/docs/current/reference/#union-step
70 Values Step
values()步骤(map)从遍历流中的元素中提取属性的值。
gremlin> g.V(1).values()
==>marko
==>san diego
==>santa cruz
==>brussels
==>santa fe
gremlin> g.V(1).values('location')
==>san diego
==>santa cruz
==>brussels
==>santa fe
71 Vertex Steps
顶点步骤(flatMap)是Gremlin语言的基础。通过这些步骤,它可能在图形上“移动” - 即遍历。
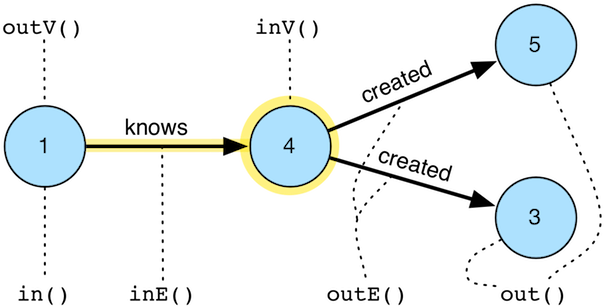
out(string…):移动到给定边标签的出站的相邻顶点。
in(string…):移动到给定边标签的传入的相邻顶点。
both(string…):移动到给定边标签的传入和传出的相邻顶点。
outE(string…):移动到给定边标签的出站事件边。
inE(string…):移动到给定边标签的入站事件边。
bothE(string…):移动到给定边标签的入站和出站事件边。
outV():移动到传出的顶点。
inV():移动到传入的顶点。
bothV():移动到两个顶点。
otherV() :移动到不是从中移出的顶点的顶点。
Note
out/in/both等独立单词的顶点步骤,由定点调用;
outE/inE等涉及边的顶点步骤,由定点调用;
outV/inV/bothV/otherV等步骤,由边调用;
72 Where Step
where()步骤(filter)根据对象本身(Scope.local)或对象(Scope.global)的路径历史来过滤当前对象。该步骤通常与match()或select()结合使用,但可以独立使用。
如获取节点1的合作者,去除节点1本身:
gremlin> g.V(1).as('a').out('created').in('created').where(neq('a'))\
==>v[4]
==>v[6]
几个典型的例子:
gremlin> g.V().where(out('created')).values('name') //1\
==>marko
==>josh
==>peter
gremlin> g.V().out('knows').where(out('created')).values('name') //2\
==>josh
gremlin> g.V().where(out('created').count().is(gte(2))).values('name') //3\
==>josh
gremlin> g.V().where(out('knows').where(out('created'))).values('name') //4\
==>marko
gremlin> g.V().where(__.not(out('created'))).where(__.in('knows')).values('name') //5\
==>vadas
gremlin> g.V().where(__.not(out('created')).and().in('knows')).values('name') //6\
==>vadas
gremlin> g.V().as('a').out('knows').as('b').
where('a',gt('b')).
by('age').
select('a','b').
by('name') //7\
==>[a:marko,b:vadas]
gremlin> g.V().as('a').out('knows').as('b').
where('a',gt('b').or(eq('b'))).
by('age').
by('age').
by(__.in('knows').values('age')).
select('a','b').
by('name') //8\
==>[a:marko,b:vadas]
==>[a:marko,b:josh]
1、创建项目的人的名字是什么?
2、被人熟知,且创建了一个项目的人的名字是什么?
3、创造了两个或多个项目的人的名字是什么?
4、那些知道有人创造了一个项目的人的名字是什么?
5、没有创造任何东西但被某人知道的人的名字是什么?
6、where()步骤的连接与一个单一的where()加and子句的相果相同。
7、marko知道josh和vadas,但是比vadas老了。
8、marko比josh小,但是知道josh的人与marko年龄相等(就是marko)。
TinkerPop中的遍历:图的遍历步骤(3/3)的更多相关文章
- TinkerPop中的遍历:图的遍历步骤(2/3)
24 Group Step 有时,所运行的实际路径或当前运行位置不是计算的最终输出,而是遍历的一些其他表示.group()步骤(map / sideEffect)是根据对象的某些功能组织对象的一个方法 ...
- TinkerPop中的遍历:图的遍历步骤(1/3)
图遍历步骤(Graph Traversal Steps) 在最一般的层次上,Traversal<S,E>实现了Iterator,S代表起点,E代表结束.遍历由四个主要组成部分组成: Ste ...
- TinkerPop中的遍历:图的遍历策略
遍历策略 一个TraversalStrategy分析一个遍历,如果遍历符合它的标准,可以相应地改变它.遍历策略在编译时被执行,并构成Gremlin遍历机的编译器的基础.有五类策略分列如下: decor ...
- TinkerPop中的遍历:图的遍历中谓词、栅栏、范围和Lambda的说明
关于谓词的注意事项 P是Function<Object,Boolean>形式的谓词.也就是说,给定一些对象,返回true或false.所提供的谓词在下表中概述,并用于各种步骤,例如has( ...
- Python 非递归遍历图
class Queue: def __init__(self,max_size): self.max_size = int(max_size) self.queue = [] def put(self ...
- 图的遍历BFS广度优先搜索
图的遍历BFS广度优先搜索 1. 简介 BFS(Breadth First Search,广度优先搜索,又名宽度优先搜索),与深度优先算法在一个结点"死磕到底"的思维不同,广度优先 ...
- 【PHP数据结构】图的遍历:深度优先与广度优先
在上一篇文章中,我们学习完了图的相关的存储结构,也就是 邻接矩阵 和 邻接表 .它们分别就代表了最典型的 顺序存储 和 链式存储 两种类型.既然数据结构有了,那么我们接下来当然就是学习对这些数据结构的 ...
- 图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
图的遍历的定义: 从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次.(连通图与非连通图) 深度优先遍历(DFS): 1.访问指定的起始顶点: 2.若当前访问的顶点的邻接顶点有未被访问的,则 ...
- Java中关于HashMap的元素遍历的顺序问题
Java中关于HashMap的元素遍历的顺序问题 今天在使用如下的方式遍历HashMap里面的元素时 1 for (Entry<String, String> entry : hashMa ...
随机推荐
- Oracle中OEM的启动与关闭
我已经选择安装了,但安装后发现开始菜单里并没有OEM,在哪里可以打开呢? 从Oracle10g开始,Oracle极大的增强了OEM工具,并通过服务器端进行EM工具全面展现.在10g中,客户端可以不必安 ...
- PHP根据两点间的经纬度计算距离,php两点经纬度计算(转)
这是一个不错的示例,直接贴代码,首先要知道纬度值.经度值 /** * @desc 根据两点间的经纬度计算距离 * @param float $lat 纬度值 * @param float $lng 经 ...
- Spring Boot 集成RabbitMQ
在Spring Boot中整合RabbitMQ是非常容易的,通过在Spring Boot应用中整合RabbitMQ,实现一个简单的发送.接收消息的例子. 首先需要启动RabbitMQ服务,并且add一 ...
- Vue开发模板简介
1. 传统发开模式的问题 用传统模式引用vue.js以及其他的js文件的开发方式,会产生一些问题. 基于页面的开发模式:传统的引用vue.js以及其他的js文件的开发方式,限定了我们的开发模式是 ...
- 发RTX通知
安装sdk 在RTXServer目录下找到WebRoot目录,找到里面的SendNotify.cgi(就是一个php页面,默认是pc - ascii编码).打开页面,在头部加上编码信息 header( ...
- Linux 正文处理命令及tar vi 编辑器 homework
作业一: 1) 将用户信息数据库文件和组信息数据库文件纵向合并为一个文件/1.txt(覆盖) cat /etc/passwd /etc/group >/1.txt 2) 将用户信息数据库文件和用 ...
- 如何配置nagios监控SUN(富士通)MX000系列服务器的XSCF
配置环境说明 192.168.3.80-XSCF地址 192.168.2.80-solaris操作系统IP地址 (nagios客户端) 192.168.2.120-nagios服务器端 check_x ...
- hadoop 更改 tmp目录
配置hadoop临时目录--------------------- 1.配置[core-site.xml]文件 <configuration> <property> <n ...
- C语言学习笔记--递归函数
1. 递归函数的思想 (1)递归是一种数学上分而自治的思想,是将大型复杂问题转化为与原问题相同但规模较小的问题进行处理的一种方法 (2)递归需要有边界条件 ①当边界条件不满足时,递归继续进行 ②当边界 ...
- 『原』在Linux下反编译Android .apk文件 使用apktool dex2jar JD-eclipse
一.使用apktool 将 apk反编译生成程序的源代码和图片.XML配置.语言资源等文件 具体步骤: (1)下载反编译工具包:apktool 官方的打不开 http://apktool.shouji ...