Canal入门
配置mysql
1、mysql开启binlog
mysql默认没有开启binlog,修改mysql的my.cnf文件,添加如下配置,注意binlog-format必须为row,因为binlog如果为STATEMENT或者MIXED,则binlog中记录的是sql语句,不是具体的数据行,canal就无法解析到具体的数据变更了。
log-bin=E:/mysql5.5/bin_log/mysql-bin.log
binlog-format=ROW
server-id=123
更详细的步骤见《MySQL安装》的第3章节。
2、给canal服务器分配一个mysql的账号权限,方便读取mysql的binlog日志
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
show grants for 'canal';
+----------------------------------------------------------------------------------------------------------------------------------------------+
| Grants for canal@% |
+----------------------------------------------------------------------------------------------------------------------------------------------+
| GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY PASSWORD '*E3619321C1A937C46A0D8BD1DAC39F93B27D4458' |
+----------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) mysql>
Canal安装
1.下载canal安装包:
地址:https://github.com/alibaba/canal/releases
我下载的是最新的release版本:https://github.com/alibaba/canal/releases/tag/canal-1.1.2
图例:
2.将下载好的安装包复制到Linux,解压
HA机制
canal是支持HA的,其实现机制也是依赖zookeeper来实现的,用到的特性有watcher和EPHEMERAL节点(和session生命周期绑定),与HDFS的HA类似。
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
- canal server: 为了减少对mysql dump的请求,不同server上的instance(不同server上的相同instance)要求同一时间只能有一个处于running,其他的处于standby状态(standby是instance的状态)。
- canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
server ha的架构图如下:
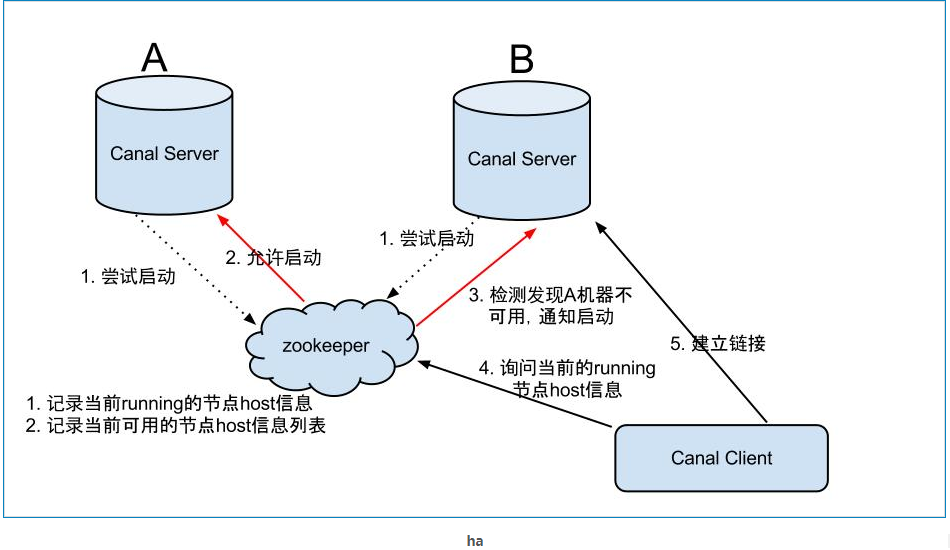
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断(实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态。
- 一旦zookeeper发现canal server A创建的instance节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance。
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect。
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制.
canal配置
canal的模式是这样的,一个canal里面可能会有多个instance,也就说一个instance可以监控一个mysql实例,多个instance也就可以对应多台服务器的mysql实例。也就是一个canal就可以监控分库分表下的多机器mysql。
《1》canal.properties
它是全局性的canal服务器配置,具体如下,这里面的参数涉及到方方面面。
#################################################
######### common argument #############
#################################################
canal.id= 1
canal.ip=
canal.port= 11111
canal.zkServers=
# flush data to zk
canal.zookeeper.flush.period = 1000
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE ## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60 # network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30 # binlog filter config
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false # binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation
canal.instance.get.ddl.isolation = false #################################################
######### destinations #############
#################################################
canal.destinations= example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5 canal.instance.global.mode = spring
canal.instance.global.lazy = false
#canal.instance.global.manager.address = 127.0.0.1:1099
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml #################################################
## mysql serverId
canal.instance.mysql.slaveId = 1234 # position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp = #canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp = # username/password,需要改成自己的数据库信息
canal.instance.dbUsername = root
canal.instance.dbPassword = 123456
canal.instance.defaultDatabaseName = datamip
canal.instance.connectionCharset = UTF-8 # table regex
canal.instance.filter.regex = .*\\..* #################################################
说明:
由于是全局性的配置,所以上面三处标红的地方要注意一下:
canal.port= 11111 当前canal的服务器端口号
canal.destinations= example 当前默认开启了一个名为example的instance实例,如果想开多个instance,用","逗号隔开就可以了。。。
canal.instance.filter.regex = .*\\..* mysql实例下的所有db的所有表都在监控范围内。
《2》conf/example/instance.properties
修改配置文件 vi conf/example/instance.properties,
#################################################
## mysql serverId
canal.instance.mysql.slaveId = 1234 # position info#设置要监听的mysql服务器的地址和端口
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp = #canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp = # username/password#设置一个可访问mysql的用户名和密码并具有相应的权限,本示例用户名、密码都为canal
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
#连接的数据库
canal.instance.defaultDatabaseName =test
canal.instance.connectionCharset = UTF-8 # table regex#订阅实例中所有的数据库和表
canal.instance.filter.regex = .*\\..*
# table black regex
canal.instance.filter.black.regex = #################################################
上面标红的地方注意下就好了,配置的mysql的账户和密码都是用来访问binlog的。
启动canal
启动 bin/startup.sh 或bin/startup.bat
查看canal日志:
[root@localhost canal]# tail -10f canal.log
at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$3.run(AbstractEventParser.java:175)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Error When doing Client Authentication:ErrorPacket [errorNumber=1045, fieldCount=-1, message=Access denied for user 'canal'@'localhost' (using password: YES), sqlState=28000, sqlStateMarker=#]
at com.alibaba.otter.canal.parse.driver.mysql.MysqlConnector.negotiate(MysqlConnector.java:199)
at com.alibaba.otter.canal.parse.driver.mysql.MysqlConnector.connect(MysqlConnector.java:74)
... 4 more
]
2019-03-28 17:19:50.328 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2019-03-28 17:19:50.328 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status
2019-03-28 17:19:50.838 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000004,position=4,serverId=1,gtid=<null>,timestamp=1553763617000] cost : 484ms , the next step is binlog dump
查看example日志
[root@localhost logs]# cd example/
[root@localhost example]# tail -10f example.log
at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$3.run(AbstractEventParser.java:175)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Error When doing Client Authentication:ErrorPacket [errorNumber=1045, fieldCount=-1, message=Access denied for user 'canal'@'localhost' (using password: YES), sqlState=28000, sqlStateMarker=#]
at com.alibaba.otter.canal.parse.driver.mysql.MysqlConnector.negotiate(MysqlConnector.java:199)
at com.alibaba.otter.canal.parse.driver.mysql.MysqlConnector.connect(MysqlConnector.java:74)
... 4 more
]
2019-03-28 17:19:50.328 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2019-03-28 17:19:50.328 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status
2019-03-28 17:19:50.838 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000004,position=4,serverId=1,gtid=<null>,timestamp=1553763617000] cost : 484ms , the next step is binlog dump
表示启动成功,可以在java项目中通过客户端代码进行访问。
客户端代码
新建一个canal-example的springboot工程
添加canal依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>
代码
package com.dxz.canalexample;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException; import java.net.InetSocketAddress;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class CanalClient { public static void main(String[] args) {
while (true) {
//连接canal
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("10.200.110.93", 11111), "example", "canal", "canal");
connector.connect();
//订阅 监控的 数据库.表
connector.subscribe("test.t_base_daily");
//一次取5条
Message msg = connector.getWithoutAck(5); long batchId = msg.getId();
int size = msg.getEntries().size();
if (batchId < 0 || size == 0) {
System.out.println("没有消息,休眠5秒");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
//
CanalEntry.RowChange row = null;
for (CanalEntry.Entry entry : msg.getEntries()) {
try {
row = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
List<CanalEntry.RowData> rowDatasList = row.getRowDatasList();
for (CanalEntry.RowData rowdata : rowDatasList) {
List<CanalEntry.Column> afterColumnsList = rowdata.getAfterColumnsList();
Map<String, Object> dataMap = transforListToMap(afterColumnsList);
if (row.getEventType() == CanalEntry.EventType.INSERT) {
//具体业务操作
System.out.println(dataMap);
} else if (row.getEventType() == CanalEntry.EventType.UPDATE) {
//具体业务操作
System.out.println(dataMap);
} else if (row.getEventType() == CanalEntry.EventType.DELETE) {
List<CanalEntry.Column> beforeColumnsList = rowdata.getBeforeColumnsList();
for (CanalEntry.Column column : beforeColumnsList) {
if ("id".equals(column.getName())) {
//具体业务操作
System.out.println("删除的id:" + column.getValue());
}
}
} else {
System.out.println("其他操作类型不做处理");
} } } catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
//确认消息
connector.ack(batchId);
} }
} public static Map<String, Object> transforListToMap(List<CanalEntry.Column> afterColumnsList) {
Map map = new HashMap();
if (afterColumnsList != null && afterColumnsList.size() > 0) {
for (CanalEntry.Column column : afterColumnsList) {
map.put(column.getName(), column.getValue());
}
}
return map;
} }
启动:

打开mysql客户端,修改一行记录:
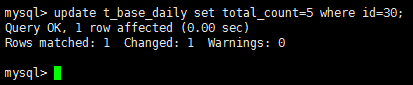
再回到canal的运行控制台

Canal入门的更多相关文章
- canal入门Demo
关于canal具体的原理,以及应用场景,可以参考开发文档:https://github.com/alibaba/canal 下面给出canal的入门Demo (一)部署canal服务器 可以参考官方文 ...
- (1)Canal入门
1.前言 在我们系统开发过程中,根据业务场景很多数据库数据并不会直接给用户访问的,需要同步保存到ElasticSearch.Redis等存储应用当中(例如最常见的是搜索页面的ElasticSearch ...
- canal 入门(基于docker)
第一步:安装MySQL:(可以参考:https://my.oschina.net/amhuman/blog/1941540) 命令: sudo docker run -it -d --restart ...
- canal 入门
参考文章:Canal - 安装 https://www.aliyun.com/jiaocheng/1131288.html?spm=5176.100033.2.7.7b422237XAirIe 前 ...
- canal入门使用
1.下载canal安装包: 地址:https://github.com/alibaba/canal/releases 图例: 2.将下载好的安装包复制到Linux,解压 3.修改配置文件 vi con ...
- 数据的异构实战(一) 基于canal进行日志的订阅和转换
什么是数据的异构处理.简单说就是为了满足我们业务的扩展性,将数据从某种特定的格式转换到新的数据格式中来. 为什么会有这种需求出现呢? 传统的企业中,主要都是将数据存储在了关系型数据库中,例如说MySQ ...
- 使用canal分析binlog(一) 入门
canal介绍 canal是应阿里巴巴存在杭州和美国的双机房部署,存在跨机房同步的业务需求而提出的.早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求.不过早期的数据库同步 ...
- canal 结合 kafka 入门
1.kafka的安装: 略 2.cannal 配置 使用卡夫卡: 修改 /home/admin/canal-server/conf/canal.properties 2.1 修改canal.ser ...
- 「从零单排canal 01」 canal 10分钟入门(基于1.1.4版本)
1.简介 canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据 订阅 和 消费.应该是阿里云DTS(Data Transfer Servi ...
随机推荐
- Bootstrap学习-导航条-分页导航
1.导航条基础 导航条(navbar)和上一节介绍的导航(nav),就相差一个字,多了一个“条”字.其实在Bootstrap框架中他们还是明显的区别.在导航条(navbar)中有一个背景色.而且导航条 ...
- 我的Android进阶之旅------>WindowManager.LayoutParams介绍
本文转载于: http://hubingforever.blog.163.com/blog/static/171040579201175111031938/ 本文参照自: http://develop ...
- 找出旋转有序数列的中间值python实现
题目给出一个有序数列随机旋转之后的数列,如原有序数列为:[0,1,2,4,5,6,7] ,旋转之后为[4,5,6,7,0,1,2].假定数列中无重复元素,且数列长度为奇数.求出旋转数列的中间值.如数列 ...
- 自定义ionic弹出框
<img width="64" height="64" src="img/timg.jpg" style="border-r ...
- linux基础part1
linux基础部分一 一.linux简介 1.Linux的定义:Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户.多任务.支持多线程和多CPU的操作系统. ...
- Oracle数据库体系结构(6)数据库归档重做日志文件管理
归档重做日志文件的概念和选择 Oracle数据库能够把已经写满了的重做日志文件保存到一个或多个指定的离线位置,这种保存的文件为归档重做日志文件.通常情况下一个归档重做日志时一个被LGWR写满的重做日志 ...
- 323 id与小数据池
a = 1000b = 1000print(a == b)== 比较的是数值is 比较的是内存地址.print(a is b)查看内存地址id()print(id(a))print(id(b)) 小数 ...
- Spark Mllib源码分析
1. Param Spark ML使用一个自定义的Map(ParmaMap类型),其实该类内部使用了mutable.Map容器来存储数据. 如下所示其定义: Class ParamMap privat ...
- 使用mongify将sqlserver数据导入到mongodb
最近需要将sqlserver数据导入到mongodb中,在github上搜了一圈,发现两个项目有点适合 mongify sql2mongodb 先试了下sql2mongodb(有个好名字果然有好处啊) ...
- Oracle可能会遇到问题和解决方法
1.plsql developer查询一列用中文,出现乱码 添加环境变量NLS_LANG = SIMPLIFIED CHINESE_CHINA.ZHS16GBK->软件重启 2.ORA-1251 ...