SQL优化的一些总结 SQL编写一般要求
SQL编写一般要求
---SQL语句尽可能简单
---分解联接保证高并发
---同数据类型的列值比较
---不在索引列做运算
---禁止使用SELECT *
---避免负向查询和%前缀模糊查询
---保持事务(连接)短小
---改写OR为IN()
---改写OR为UNION
---LIMIT高效分页
---用UNION ALL而非 UNION
---GROUP BY 去除排序
SQL语句尽可能简单
分解联接保证高并发
MySQL> Select post_name from tag JOIN tag_post
on tag_post.tag_id=tag.id JOIN post
on tag_post.post_id=post.id
WHERE tag.tag='二手玩具';
MySQL> Select tag_id from tag WHERE tag='二手玩具';
MySQL> Select post_id from tag_post WHERE tag_id=1321;
MySQL> Select post_name from post WHERE post.id in (123,456,314,141);
同数据类型的列值比较
不在索引列做运算

禁止使用SELECT *
SELECT * FROM tag WHERE id = 999184;
SELECT keyword FROM tag WHERE id = 999184;
避免负向查询和%前缀模糊查询
MySQL> select * from post WHERE title like '北京%' ;
298 rows in set (0.01 sec)
MySQL> select * from post WHERE title like '%北京%' ;
572 rows in set (3.27 sec)
保持事务(连接)短小
保持事务/DB连接短小精悍
改写OR为IN()
Select * from opp WHERE phone='12347856' or phone='42242233' ;
Select * from opp WHERE phone in ('12347856' , '42242233') ;
改写OR为UNION
Select * from opp WHERE phone='010-88886666' or cellPhone='13800138000';
Select * from opp WHERE phone='010-88886666'
union
Select * from opp WHERE cellPhone='13800138000';
LIMIT高效分页(一)
Select * from table WHERE id>=23423 limit 11; #10+1 (每页10条)
select * from table WHERE id>=23434 limit 11;
LIMIT高效分页(二)
Select * from table WHERE id >= ( select id from table limit 10000,1 ) limit 10;
SELECT * FROM table INNER JOIN (SELECT id FROM table LIMIT 10000,10) USING (id) ;
LIMIT高效分页(三)
MySQL> select sql_no_cache * from post limit 10,10;
10 row in set (0.01 sec)
MySQL> select sql_no_cache * from post limit 20000,10;
10 row in set (0.13 sec)
MySQL> select sql_no_cache * from post limit 80000,10;
10 rows in set (0.58 sec)
MySQL> select sql_no_cache id from post limit 80000,10;
10 rows in set (0.02 sec)
MySQL> select sql_no_cache * from post WHERE id>=323423 limit 10;
10 rows in set (0.01 sec)
MySQL> select * from post WHERE id >=
( select sql_no_cache id from post limit 80000,1 ) limit 10 ;
10 rows in set (0.02 sec)
用UNION ALL而非 UNION
MySQL> SELECT * FROM detail20091128 UNION ALL
SELECT * FROM detail20110427 UNION ALL
SELECT * FROM detail20110426 UNION ALL
SELECT * FROM detail20110425 UNION ALL
SELECT * FROM detail20110424 UNION ALL
SELECT * FROM detail20110423;
GROUP BY 去除排序
MySQL> select phone,count(*) from post group by phone limit 1 ;
1 row in set (2.19 sec)
MySQL> select phone,count(*) from post group by phone order by null limit 1;
1 row in set (2.02 sec)
http://www.taobaodba.com/html/851_sql%E4%BC%98%E5%8C%96%E7%9A%84%E4%B8%80%E4%BA%9B%E6%80%BB%E7%BB%93.html SQL的优化是DBA日常工作中不可缺少的一部分,记得在学生时期,曾经在ITPUB上看到一篇帖子,当时楼主在介绍SQL优化的时候,用一个公式来讲解他在做sql优化的时候遵循的原则:
T=S/V(T代表时间,S代表路程,V代表速度)
S指SQL所需访问的资源总量,V指SQL单位时间所能访问的资源量,T自然就是SQL执行所需时间了;我们为了获得SQL最快的执行时间,可以根据公式定义上去反推:
- 在S不变的情况下,我们可以提升V来降低T:通过适当的索引调整,我们可以将大量的速度较慢的随机IO转换为速度较快的顺序IO;通过提升服务器的内存,使得将更多的数据放到内存中,会比数据放到磁盘上会得到明显的速度提升;采用电子存储介质进行数据存储和读取的SSD,突破了传统机械硬盘的性能瓶颈,使其拥有极高的存储性能;在提升V上我们可以采用较高配置的硬件来完成速度的提升;
- 在V不变的情况下,我们可以减小S来降低T:这是SQL优化中非常核心的一个环节,在减小S环节上,DBA可以做的可以有很多,通常可以在查询条件中建立适当的索引,来避免全表扫描;有时候可以改写SQl,添加一些适当的提示符,来改变SQL的执行计划,使SQL以最少的扫描路径完成查询;当这些方法都使用完了之后,你是否还有其他方案来优化喃?在阿里系的DBA职位描述中有条就是要求DBA需要深入的了解业务,当DBA深入的了解业务之后,这个时候能站在业务上,又站DB角度上考虑,这个时候在去做优化,有时候能达到事半功倍的效果。
案例一:通过降低S,来提升T
原理介绍:
我们知道B+索引叶子节点的值是按照索引字段升序的,比如我们对(nick,appkey)两个字段做了索引,那么在索引中的则是按照nick,appkey的升序排列;如果我们现在的一条sql:
select count(distinct nick) from xxxx_nickapp_09_29;
用于查询统计某天日志表中的UV,优化器选择了该表上索引ind_nick_appkey(nick,appkey)来完成查询,则开始从nick1开始一条条扫描下来,直到扫描到最后一个nick_n,那么中间过程会扫描很多重复的nick(最左边普通扫描),如果我们能够跳过中间重复的nick,则性能会优化非常多(最右边的松散扫描):

从上面的可以得到一个结论:
如果这条统计uv的sql能够按照右边的loose index scan的方式来扫描话,会大大的减小我们上面提到的S;所以需要通过改写sql来达到伪loose index scan:(MySql优化器不能直接的对count(distinct column)做优化)
root@DB 09:41:30>select count(*) from ( select distinct(nick) from xxxx_nickapp_09_29)t ;
+———-+
| count(*) |
+———-+
| 806934 |
+———-+
Sql内查询中先选出不同的nick,最后在外面套一层count,就可以得到nick的distinct值总和;
最重要的是在子查询中:select distinct(nick) 实现了上图中的伪loose index scan,优化器在这个时候的执行计划为Using index for group-by ,这样mysql就把distinct优化为group by,首先利用索引来分组,然后扫描索引,对需要的nick只扫描一条记录。
真实案例:
该案例选自我们的一个线上的生产系统,该系统每天有大量的日志数据入库,单表的容量在10G-50G之间,然后做汇总分析,计算日志数据中的uv就是其中一个逻辑,sql如下:
select count(distinct nick) from xxxx_nickapp_09_29;
即使在_xxxx分表上加上nick的索引,通过查看执行计划,为全索引扫描,由于单表的数据量过大,sql在执行的时候,会对整个服务器带来抖动,需要对原来的SQL进行改写,使其支持loose index scan;
优化前:
root@DB 09:41:30>select count(distinct nick) from xxxx_nickapp_09_29;
+———-+
| count(*) |
+———-+
| 806934 |
1 row in set (52.78 sec)
执行一次sql需要花费52.78s
优化后:
root@DB 09:41:30>select count(*) from ( select distinct(nick) from xxxx_nickapp_09_29)t ;
+———-+
| count(*) |
+———-+
| 806934 |
+———-+
1 row in set (5.81 sec)
由52.78秒降至5.81秒,速度提升了差不多10倍;
查看SQL的执行计划:
优化写法:
root@DB 09:41:30>explain select count(*) from ( select distinct(nick) from xxxx_nickapp_09_29)t ;
+—-+————-+——————————+——-+—————+———————————+———+—–
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+——————————+——-+—————+———————————+———+—–
| 1 | SIMPLE | xxxx_nickapp_09_29 | range | NULL |ind_nick_appkey | 67 | NULL | 2124695 |Using index for group-by |
+—-+————-+——————————+——-+—————+———————————+———+—–
原始写法:
root@DB 09:41:50>explain select count(distinct nick) from xxxx_nickapp_09_29;
+—-+————-+——————————+——-+—————+—————————-+———+——+–
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+——————————+——-+—————+—————————-+———+——+–
| 1 | SIMPLE | xxxx_nickapp_09_29 | index | NULL | ind_nick_appkey | 177 | NULL | 19546123 |Using index |
+—-+————-+——————————+——-+————–+—————————-+———+——+–
可以看到我们的路程由19546123减小到2124695,减小了9倍多.^_^
案例二:结合业务递增的写入特点,巧妙优化UV统计count(*)
有时候觉得,优化一条sql的最高境界就是让这sql能够从把这条从系统中拿掉,不管怎样,这些都是建立在你足够的了解业务上,就能够推动一些业务产品的升级或者下线,这样的DBA你能做到吗?
下面看一个案例:应用每天都会对入库的分表统计一个总数:select count(*) from xx_01_01;
随着单表的数据量越来越大(单表在20G左右),每次进行count的时候,速度越来越慢,同时需要扫描较多的数据页块,导致整个数据库性能的抖动,通过分析业务的特点,由于每张表采用自增id的方式进行插入,并且没有数据的删除,所以统计全表的总数就可以变通一下:
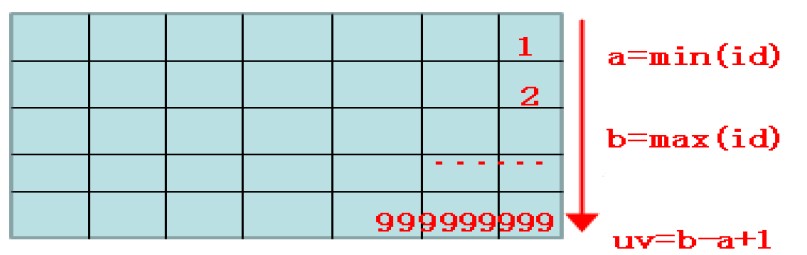
所以这条sql:select count(*) from xx_01_01;
可以变通为: select max(id)-min(id)+1 from xx_01_01;
执行速度可以得到质的飞跃 ^_^.
案例三:通过提升V,来降低T—随机IO VS 顺序IO
在前面我们提到,提升V的一些方法,通常可以采用提升服务器硬件的方式来达到,但是很多中小型企业来说,现在比较高的成本对于他们来说还是望尘莫及,同时没有成熟的使用经验,对于他们可能还是一件坏事情。总的来说,你的服务器硬件无论在牛,如果SQL写的烂,索引建的不好,那还是不行的。
真实线上案例:在我们的一个核心产品库上,承载着非常大量的随机读,就叫它读库好了。一天读库的load非常的高,通过慢日志发现,有一条sql频繁的出现在慢日中,这条sql的查询条件很复杂,同时该表上的类似相同的索引也非常的多,当时是怀疑索引走错,通过explain 来查看SQL的执行计划:发现执行计划中的using where代表查询回表了,同时由于回表的记录rows较大,所以带来了大量的随机IO:

所以我们只需要在原来的索引冗余掉is_detail字段就可以通过覆盖索引的方法优化掉该sql,避免了查询回表而导致的随机io,用顺序io替换了原来的随机io,SQL的执行速度得到极大提升:(下图会去掉is_detail字段的测试)
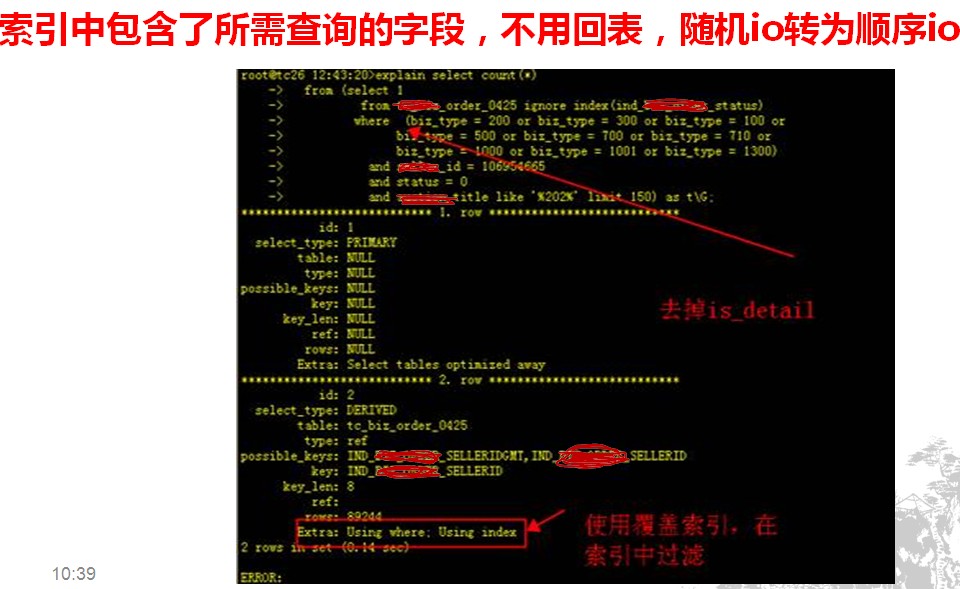
总结:SQL优化是很有趣的一件事情,我们在日常工作中可以按照t=s/v的思路来进行优化,也许你第一次运用它的时候有些陌生,但是只要不断的练习,善于总结,你也会发现其中的规律,真是妙哉妙哉。还有一点很重要的是,你的SQL优化不要脱离实际业务,也许你在哪里优化一条sql花了1个小时,但是去和开发同学讨论优化成果的时候,开发同学说这条sql其实可以下线了,那时候真的哭笑不得了 ^_^.
SQL优化的一些总结 SQL编写一般要求的更多相关文章
- 智能SQL优化工具--SQL Optimizer for SQL Server(帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 )
SQL Optimizer for SQL Server 帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 SQL Optimizer for SQL Server 让 SQL Serve ...
- Oracle之SQL优化专题01-查看SQL执行计划的方法
在我2014年总结的"SQL Tuning 基础概述"中,其实已经介绍了一些查看SQL执行计划的方法,但是不够系统和全面,所以本次SQL优化专题,就首先要系统的介绍一下查看SQL执 ...
- Oracle之SQL优化专题02-稳固SQL执行计划的方法
首先构建一个简单的测试用例来实际演示: create table emp as select * from scott.emp; create table dept as select * from ...
- 有史以来性价比最高最让人感动的一次数据库&SQL优化(DB & SQL TUNING)——半小时性能提升千倍
昨天,一个客户现场人员急急忙忙打电话找我,说需要帮忙调优系统,因为经常给他们干活,所以,也就没多说什么,先了解情况,据他们说,就是他们的系统最近才出现了明显的反应迟钝问题,他们的那个系统我很了解,软硬 ...
- 基于oracle的sql优化
[基于oracle的sql优化] 基于oracle的sql优化 [博主]高瑞林 [博客地址]http://www.cnblogs.com/grl214 一.编写初衷描述 在应有系统开发初期,由于数据库 ...
- SQL优化的若干原则
SQL语句:是对数据库(数据)进行操作的惟一途径:消耗了70%~90%的数据库资源:独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低:可以有不同的写法:易 ...
- 面试题: 数据库 sql优化 sql练习题 有用 学生表,课程表,成绩表,教师表 练习
什么是存储过程?有哪些优缺点? 什么是存储过程?有哪些优缺点? 存储过程就像我们编程语言中的函数一样,封装了我们的代码(PLSQL.T-SQL). 存储过程的优点: 能够将代码封装起来 保存在数据库之 ...
- 数据库优化 - SQL优化
前面一篇文章从实例的角度进行数据库优化,通过配置一些参数让数据库性能达到最优.但是一些"不好"的SQL也会导致数据库查询变慢,影响业务流程.本文从SQL角度进行数据库优化,提升SQ ...
- 转载 数据库优化 - SQL优化
判断问题SQL判断SQL是否有问题时可以通过两个表象进行判断: 系统级别表象CPU消耗严重IO等待严重页面响应时间过长应用的日志出现超时等错误可以使用sar命令,top命令查看当前系统状态. 也可以通 ...
随机推荐
- (二十四)linux新定时器:timefd及相关操作函数
timerfd是Linux为用户程序提供的一个定时器接口.这个接口基于文件描述符,通过文件描述符的可读事件进行超时通知,所以能够被用于select/poll的应用场景. 一,相关操作函数 #inclu ...
- (3) python--matplotlib
(一)1.如何绘制散点图 import numpy as np import matplotlib.pyplot as plt # 如何绘制散点图 # 先随机生成数据 x = np.array(ran ...
- 利用注册表在右键添加VisualCode快捷方式
分为两种配置,第一种是对于文件右键也就是 关联文件 第一步: Win+R 打开运行,输入regedit,打开注册表,找到HKEY_CLASSES_ROOT\*\shell分支,如果没有shell分支, ...
- json model 互转
1.json转model TestModel tm = new TestModel();JavaScriptSerializer js = new JavaScriptSerializer();tm ...
- jmeter引用cookies进行登录实战
以jmeter登录接口为例,就下面的这个登录页面 在测试之前,我们输入用户和密码先手动登录下,看看有那些网络信息,使用fiddler抓包 登录发送的是这个请求,我们看下使用什么方式,以及用到那些参数 ...
- POJ 2761 Feed the dogs (主席树)(K-th 值)
Feed the dogs Time Limit: 6000MS Memor ...
- DB Link
oracle中DB Link select * from TB_APP_HEADER@SSDPPORTAL
- 非常老的话题 SQLSERVER连接池
原文:非常老的话题 SQLSERVER连接池 非常老的话题 SQLSERVER连接池 写这篇文章不是说要炒冷饭,因为园子里有非常非常多关于SQLSERVER连接池的文章,但是他们说的都是引用MSDN里 ...
- 去除自定义Toolbar中左边距
问题 自定义Toolbar之后,发现左侧不能完全填充,总是留一点空白,如下图: 原因 查看Wiget.AppCompat.Toolbar的parent(Toolbar默认的style),如下: < ...
- 6、Python模块
最常用的两个模块: os #可以允许python调用执行系统命令,如shell sys #处理与python程序本身的事情 Python自带200多个常用模块 Python官网收集了2 ...