机器学习实战之Logistic回归
Logistic回归
一、概述
1. Logistic Regression
1.1 线性回归
1.2 Sigmoid函数
1.3 逻辑回归
1.4 LR 与线性回归的区别
2. LR的损失函数
3. LR 正则化
3.1 L1 正则化
3.2 L2 正则化
3.3 L1正则化和L2正则化的区别
4. RL 损失函数求解
4.1 基于对数似然损失函数
4.2 基于极大似然估计
二、 梯度下降法
1. 梯度
2. 梯度下降的直观解释
3. 梯度下降的详细算法
3.1 梯度下降法的代数方式描述
3.2 梯度下降法的矩阵方式描述
4. 梯度下降的种类
4.1 批量梯度下降法BGD
4.2 随机梯度下降法SGD
4.3 小批量梯度下降法MBGD
5. 梯度下降的算法调优
三、使用梯度下降求解逻辑回归
1. 使用BGD求解逻辑回归
1.1 导入数据集
1.2 定义辅助函数
1.3 BGD算法python实现
1.4 准确率计算函数
2. 使用SGD求解逻辑回归
2.1 SGD算法python实现
四、从疝气病症预测病马的死亡率
1. 准备数据
2. logistic回归分类函数
一、概述
分类技术是机器学习和数据挖掘应用中的重要组成部分。在数据科学中,大约70%的问题属于分类问题。解决分类问题的算法也有很多种,比如:k-近邻算法,使用距离计算来实现分类;决策树,通过构建直观易懂的树来实现分类;朴素贝叶斯,使用概率论构建分类器。这里我们要讲的是Logistic回归,它是一种很常见的用来解决二元分类问题的回归方法,它主要是通过寻找最优参数来正确地分类原始数据。
1. Logistic Regression
逻辑回归(Logistic Regression,简称LR),其实是一个很有误导性的概念,虽然它的名字中带有“回归”两个字,但是它最擅长处理的却是分类问题。LR分类器适用于各项广义上的分类任务,例如:评论信息的正负情感分析(二分类)、用户点击率(二分类)、用户违约信息预测(二分类)、垃圾邮件检测(二分类)、疾病预测(二分类)、用户等级分类(多分类)等场景。我们这里主要讨论的是二分类问题。
1.1 线性回归
提到逻辑回归我们不得不提一下线性回归,逻辑回归和线性回归同属于广义线性模型,逻辑回归就是用线性回归模型的预测值去拟合真实标签的的对数几率(一个事件的几率(odds)是指该事件发生的概率与不发生的概率之比,如果该事件发生的概率是P,那么该事件的几率是P/(1-P),对数几率就是log(P/(1-P))。
逻辑回归和线性回归本质上都是得到一条直线,不同的是,线性回归的直线是尽可能去拟合输入变量X的分布,使得训练集中所有样本点到直线的距离最短;而逻辑回归的直线是尽可能去拟合决策边界,使得训练集样本中的样本点尽可能分离开。因此,两者的目的是不同的。
线性回归方程:y = wx + b,此处,y为因变量,x为自变量。在机器学习中y是标签,x是特征。
1.2 Sigmoid函数
我们想要的函数应该是,能接受所有的输入然后预测出类别。例如在二分类的情况下,函数能输出0或1。那拥有这类性质的函数称为海维赛德阶跃函数(Heaviside step function),又称之为单位阶跃函数(如下图所示):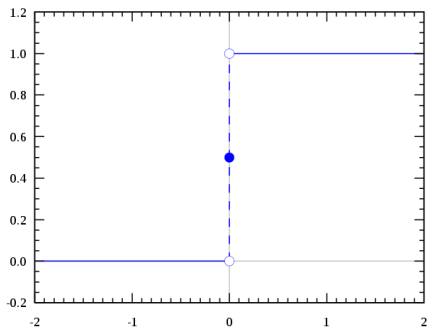
单位阶跃函数的问题在于:在0点位置该函数从0瞬间跳跃到1,这个瞬间跳跃过程很难处理(不好求导)。幸运的是,Sigmoid函数也有类似的性质,且数学上更容易处理。
Sigmoid函数公式: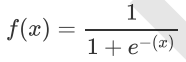
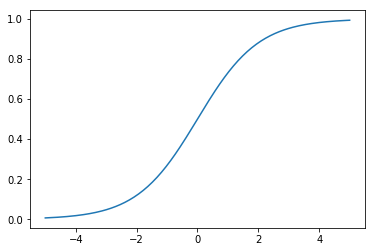
import numpy as np
import math
import matplotlib.pyplot as plt
%matplotlib inline
X = np.linspace(-5,5,200)
y = [1/(1+math.e**(-x)) for x in X]
plt.plot(X,y)
plt.show()
X = np.linspace(-60,60,200)
y = [1/(1+math.e**(-x)) for x in X]
plt.plot(X,y)
plt.show()
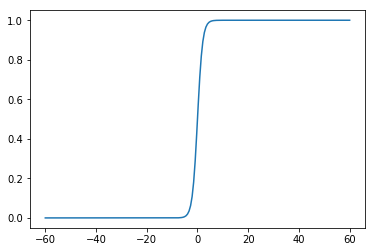
上图给出了Sigmoid函数在不同坐标尺度下的两条曲线。当x为0时,Sigmoid函数值为0.5。随着x的增大,对应的函数值将逼近于1;而随着x的减小,函数值逼近于0。所以Sigmoid函数值域为(0,1),注意这是开区间,它仅无限接近0和1。如果横坐标刻度足够大,Sigmoid函数看起来就很像一个阶跃函数了。
1.3 逻辑回归
通过将线性模型和Sigmoid函数结合,我们可以得到逻辑回归的公式: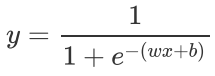
这样y就是(0,1)的取值。
对式子进行变换,可得: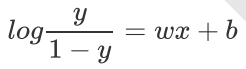
这个其实就是一个对数几率公式。
二项Logistic回归: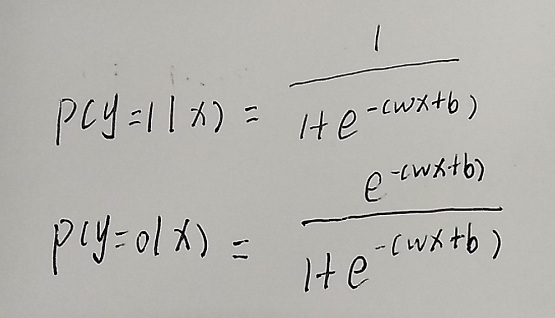
多项Logistic回归: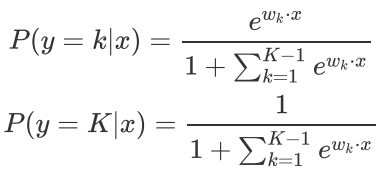
1.4 LR 与线性回归的区别
逻辑回归和线性回归是两类模型,逻辑回归是分类模型,线性回归是回归模型,具体的请看我上一篇博客。
2. LR的损失函数
在机器学习算法中,我们常常使用损失函数来衡量模型预测的好坏。损失函数,通俗讲,就是衡量真实值和预测值之间差距的函数。所以,损失函数越小,模型就越好。在这里,最小损失是0。
LR损失函数为:
看一下这个函数的图像:
X = np.linspace(0.0001,1,200)
y = [(-np.log(x)) for x in X]
plt.plot(X,y)
plt.show()
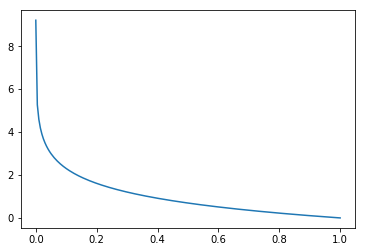
X = np.linspace(0,0.99999,200)
y = [(-np.log(1-x)) for x in X]
plt.plot(X,y)
plt.show()

我们把这两个损失函数综合起来:
y就是标签,分别取0,1。
对于m个样本,总的损失函数为: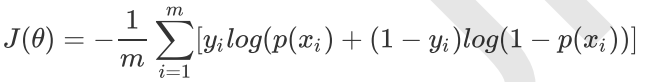
这个式子中,m是样本数,y是标签,取值0或1,i表示第i个样本,p(x)表示预测的输出。
不过当损失过于小的时候,也就是模型能够拟合绝大部分的数据,这时候就容易出现过拟合。为了防止过拟合,我们会引入正则化。
3. LR 正则化
3.1 L1 正则化
Lasso 回归,相当于为模型添加了这样一个先验知识: 服从零均值拉普拉斯分布。
拉普拉斯分布: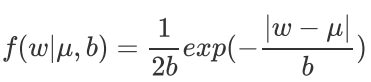
其中μ,b为常数,且μ>0。
下面证明这一点,由于引入了先验知识,所以似然函数这样写:
取log再取负,得到目标函数: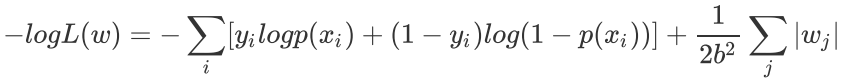
等价于原始的cross−entropy后面加上了L1正则,因此L1正则的本质其实是为模型增加了“模型参数服从零均值拉普拉斯分布”这一先验知识。
3.2 L2 正则化
Ridge 回归,相当于为模型添加了这样一个先验知识: 服从零均值正态分布。
正态分布公式: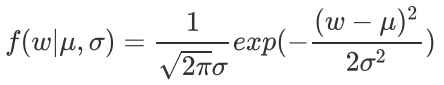
下面证明这一点,由于引入了先验知识,所以似然函数这样写: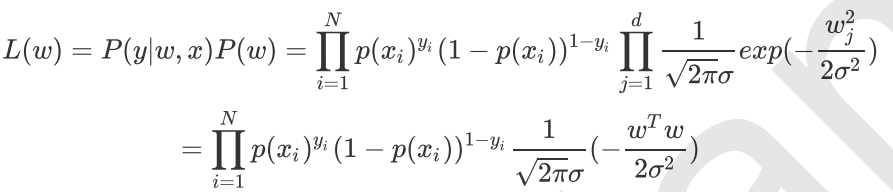
取log再取负,得到目标函数: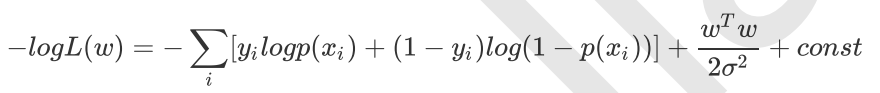
等价于原始的cross−entropy后面加上了L2正则,因此L2正则的的本质其实是为模型增加了“模型参数服从零均值正态分布”这一先验知识。
3.3 L1正则化和L2正则化的区别
请参照我的两篇文章:
4. RL损失函数求解
4.1 基于对数似然损失函数
对数似然损失函数为: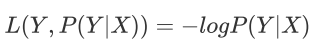
对于LR来说,单个样本的对数似然损失函数可以写成如下形式: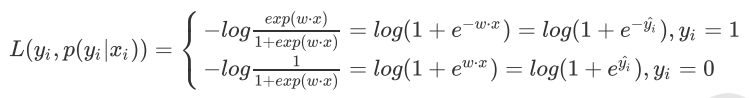
综合起来,写成同一个式子: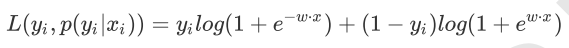
于是对整个训练样本集而言,对数似然损失函数是: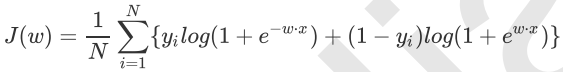
4.2 基于极大似然估计
设p(y=1l x)=p(x),p(y=0 l x)=1 - p(x),假设样本是独立同分布生成的,它们的似然函数就是各样本后验概率连乘:
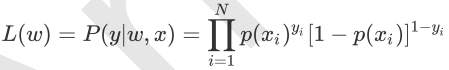
为了防止数据下溢,写成对数似然函数形式: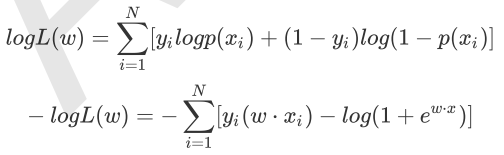
可以看出实际上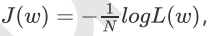
J(w)要最小化,而logL(w)要最大化,实际上是等价的。
讨论:损失函数为什么是log损失函数(交叉熵),而不是MSE?
假设目标函数是MSE而不是交叉熵,即: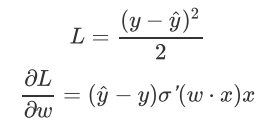
这里sigmoid的导数: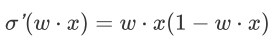
根据 w 的初始化,导数值可能很小(想象一下sigmoid函数在输入较大时的梯度)而导致收敛变慢,而训练途中也可能因为该值过小而提早终止训练。
另一方面,logloss的梯度如下,当模型输出概率偏离于真实概率时,梯度较大,加快训练速度,当拟合值接近于真实概率时训练速度变缓慢,没有MSE的问题。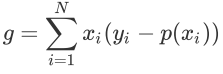
我仅仅从一个点对本题进行了解答,还有别的点你可以想一想。
二、 梯度下降法
由于极大似然函数无法直接求解,所以在机器学习算法中,在最小化损失函数时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。
1. 梯度
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是
简称grad f(x,y)或者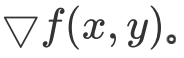 对于在点(x0,y0)的具体梯度向量就是
对于在点(x0,y0)的具体梯度向量就是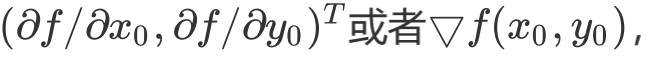
如果是3个参数的向量梯度,就是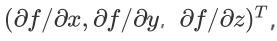
以此类推。那么这个梯度向量求出来有什么意义呢?他的意义从几何意义上讲,就是函数变化增加最快的地方。具体来说,对于函数f(x,y),在点(x0,y0),沿着梯度向量的方向就是
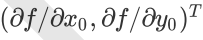
的方向是f(x,y)增加最快的地方。或者说,沿着梯度向量的方向,更加容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是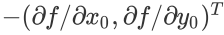
的方向,梯度减少最快,也就是更加容易找到函数的最小值。
2. 梯度下降的直观解释
首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。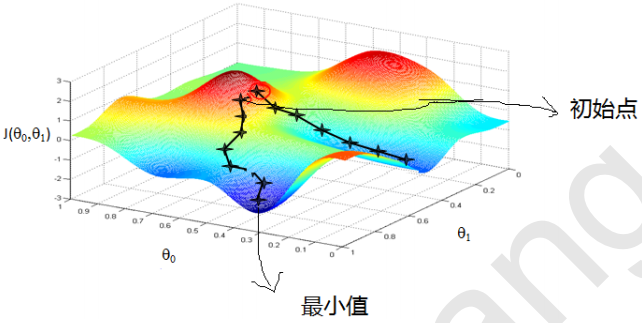
3. 梯度下降的详细算法
梯度下降法的算法可以有代数法和矩阵法(也称向量法)两种表示,如果对矩阵分析不熟悉,则代数法更加容易理解。不过矩阵法更加的简洁,且由于使用了矩阵,实现逻辑更加的一目了然。这里先介绍代数法,后介绍矩阵法。
3.1 梯度下降法的代数方式描述
1. 先决条件: 确认优化模型的假设函数和损失函数。
比如对于线性回归,假设函数表示为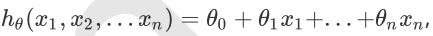
其中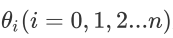
为模型参数,xi(i=0,1,2...n)为每个样本的n个特征值。这个表示可以简化,我们增加一个特征x0=1,这样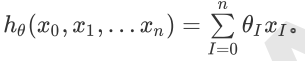
同样是线性回归,对应于上面的假设函数,损失函数为(此处在损失函数之前加上1/(2m),主要是为了修正SSE让计算公式结果更加美观,实际上损失函数取MSE或SSE均可,二者对于一个给定样本而言只相差一个固定数值):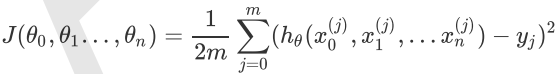
2. 算法相关参数初始化:主要是初始化 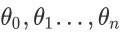 和算法终止距离
和算法终止距离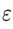 以及步长 。在没有任何先验知识的时候,我们比较倾向于将所有的
以及步长 。在没有任何先验知识的时候,我们比较倾向于将所有的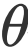 初始化为0, 将步长初始化为1。在调优的时候再进行优化。
初始化为0, 将步长初始化为1。在调优的时候再进行优化。
3. 算法过程:
(1).确定当前位置的损失函数的梯度,对于 ,其梯度表达式如下:
,其梯度表达式如下:

(2).用步长乘以损失函数的梯度,得到当前位置下降的距离,即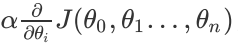
,对应于前面登山例子中的某一步。
(3).确定是否所有的 ,梯度下降的距离都小于,如果小于则算法终止,当前所有的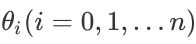
即为最终结果。否则进入步骤4.
(4).更新所有的,对于,其更新表达式如下。更新完毕后继续转入步骤1.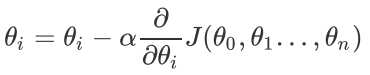
下面用线性回归的例子来具体描述梯度下降。假设我们的样本是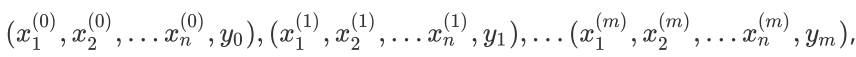
损失函数如前面先决条件所述: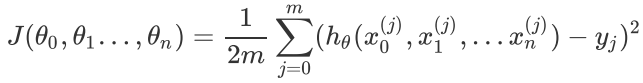
则在算法过程步骤1中对于的偏导数计算如下: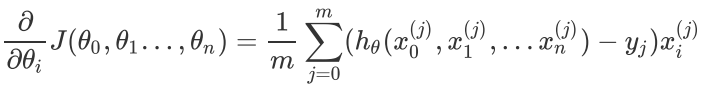
由于样本中没有x0上式中令所有的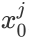 为1. 步骤4中
为1. 步骤4中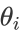 的更新表达式如下:
的更新表达式如下: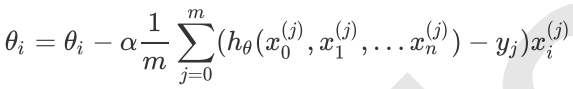
从这个例子可以看出当前点的梯度方向是由所有的样本决定的,加1/m是为了好理解。由于步长也为常数,他们的乘积也为常数,所以这里 可以用一个常数表示。 在下面会详细讲到的梯度下降法的变种,他们主要的区别就是对样本的采用方法不同。这里我们采用的是用所有样本。
可以用一个常数表示。 在下面会详细讲到的梯度下降法的变种,他们主要的区别就是对样本的采用方法不同。这里我们采用的是用所有样本。
3.2 梯度下降法的矩阵方式描述
这一部分主要讲解梯度下降法的矩阵方式表述,相对于上面的代数法,要求有一定的矩阵分析的基础知识,尤其是矩阵求导的知识。
1. 先决条件: 需要确认优化模型的假设函数和损失函数。对于线性回归,假设函数 的矩阵表达方式为:
的矩阵表达方式为: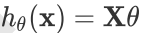
其中, 假设函数 的向量,
的向量,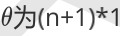 的向量,里面有n个代数法的的模型参数。
的向量,里面有n个代数法的的模型参数。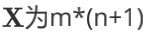 维的矩阵。m代表样本的个数,n+1代表样本的特征数。 损失函数的表达式为:
维的矩阵。m代表样本的个数,n+1代表样本的特征数。 损失函数的表达式为: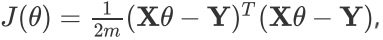
其中Y是样本的输出向量,维度为m*1。
2. 算法相关参数初始化: 向量可以初始化为默认值,或者调优后的值。算法终止距离 ,步长
,步长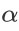 和3.1比没有变化。
和3.1比没有变化。
3. 算法过程:
(1).确定当前位置的损失函数的梯度,对于向量,其梯度表达式如下: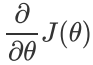
(2).用步长乘以损失函数的梯度,得到当前位置下降的距离,即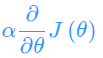 对应于前面登山例子中的某一步。
对应于前面登山例子中的某一步。
(3).确定向量里面的每个值,梯度下降的距离都小于,如果小于则算法终止,当前向量即为最终结果。否则进入步骤4.
(4).更新向量,其更新表达式如下。更新完毕后继续转入步骤1.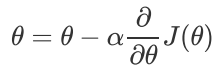
还是用线性回归的例子来描述具体的算法过程。 损失函数对于向量的偏导数计算如下: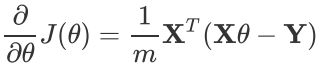
步骤4中向量的更新表达式如下: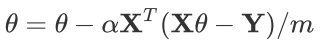
可以看到矩阵法要简洁很多。这里面用到了矩阵求导链式法则,和两个矩阵求导的公式。
公式1:
公式2: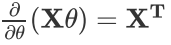
4. 梯度下降的种类
4.1 批量梯度下降法BGD
批量梯度下降法(Batch Gradient Descent,BGD)是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新。
由于我们有m个样本,这里求梯度的时候就用了所有样本的梯度数据。
4.2 随机梯度下降法SGD
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。对应的更新公式是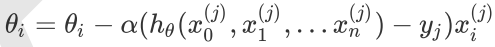
随机梯度下降法和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。 但值得一提的是,随机梯度下降法在处理非凸函数优化的过程当中有非常好的表现,由于其下降方向具有一定随机性,因此能很好的绕开局部最优解,从而逼近全局最优解。
那么,有没有一个中庸的办法能够结合两种方法的优点呢?有!这就是下面的小批量梯度下降法。
4.3 小批量梯度下降法MBGD
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个子样本来迭代,1<x<m。一般可以取x=10,当然根据样本的数据,可以调整这个x的值。对应的更新公式是: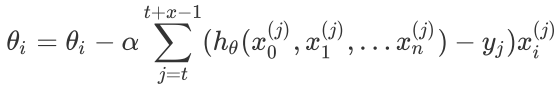
总结:
BGD会获得全局最优解,缺点是在更新每个参数的时候需要遍历所有的数据,计算量会很大,并且会有很多的冗余计算,导致的结果是当数据量大的时候,每个参数的更新都会很慢。
SGD以高方差频繁更新,优点是使得SGD会跳到新的和潜在更好的局部最优解,缺点是使得收敛到局部最优解的过程更加的复杂。
MBGD降结合了BGD和SGD的优点,每次更新的时候使用n个样本。减少了参数更新的次数,可以达到更加稳定收敛结果,一般在深度学习当中可以采用这种方法,将数据一个batch一个batch的送进去训练。
不过在使用上述三种方法时有两个问题是不可避免的:
1、如何选择合适的学习率(learning_rate)。自始至终保持同样的学习率显然是不太合适的,开始学习参数的时候,距离最优解比较远,需要一个较大的学习率能够快速的逼近最优解。当参数接近最优解时,继续保持最初的学习率,容易越过最优点,在最优点附近震荡。
2、如何对参数选择合适的学习率。对每个参数都保持的同样的学习率也是很不合理的。有些参数更新频繁,那么学习率可以适当小一点。有些参数更新缓慢,那么学习率就应该大一点。针对以上问题,就提出了诸如Adam,动量法等优化方法,感兴趣的小伙伴可以自行研究。
5. 梯度下降的算法调优
1. 算法的步长选择。步长的选择实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。前面说了。步长太大,会导致迭代过快,甚至有可能错过最优解。步长太小,迭代速度太慢,很长时间算法都不能结束。所以算法的步长需要多次运行后才能得到一个较为优的值。
2. 算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
3. 标准化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据标准化,也就是对于每个特征x,求出它的期望 和标准差std(x),然后转化为:
和标准差std(x),然后转化为: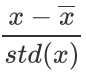
这样特征的新期望为0,新方差为1,收敛速度可以大大加快。
三、使用梯度下降求解逻辑回归
testSet数据集中一共有100个点,每个点包含两个数值型特征:X1和X2。因此可以将数据在一个二维平面上展示出来。我们可以将第一列数据(X1)看作x轴上的值,第二列数据(X2)看作y轴上的值。而最后一列数据即为分类标签。根据标签的不同,对这些点进行分类。
在此数据集上,我们将通过批量梯度下降法和随机梯度下降法找到最佳回归系数。
1. 使用BGD求解逻辑回归
批量梯度下降法的伪代码:
每个回归系数初始化为1
重复下面步骤直至收敛:
计算整个数据集的梯度
使用alpha*gradient更新回归系数的向量
返回回归系数
1.1 导入数据集
import pandas as pd
import numpy as np
dataSet = pd.read_table('testSet.txt',header = None)
dataSet.columns =['X1','X2','labels']
dataSet.head()
结果:
| X1 | X2 | labels | |
|---|---|---|---|
| 0 | -0.017612 | 14.053064 | 0 |
| 1 | -1.395634 | 4.662541 | 1 |
| 2 | -0.752157 | 6.538620 | 0 |
| 3 | -1.322371 | 7.152853 | 0 |
| 4 | 0.423363 | 11.054677 | 0 |
1.2 定义辅助函数
Sigmoid函数
"""
函数功能:计算sigmoid函数值
参数说明:
inX:数值型数据
返回:
s:经过sigmoid函数计算后的函数值
"""
def sigmoid(inX):
s = 1/(1+np.exp(-inX))
return s
sigmoid(5)#0.9933071490757153
sigmoid(0)#0.5
sigmoid(-5)#0.0066928509242848554
标准化函数
'''
函数功能:标准化(期望为0,方差为1)
参数说明:
xMat:特征矩阵
返回:
inMat:标准化之后的特征矩阵
'''
def regularize(xMat):#标准化函数
inMat = xMat.copy()
inMeans = np.mean(inMat,axis = 0)
inVar = np.std(inMat,axis = 0)
inMat = (inMat - inMeans)/inVar
return inMat
1.3 BGD算法python实现
dataSet.head()
结果:
| X1 | X2 | labels | |
|---|---|---|---|
| 0 | -0.017612 | 14.053064 | 0 |
| 1 | -1.395634 | 4.662541 | 1 |
| 2 | -0.752157 | 6.538620 | 0 |
| 3 | -1.322371 | 7.152853 | 0 |
| 4 | 0.423363 | 11.054677 | 0 |
np.mat(dataSet.iloc[:,:-1].values)
matrix([[-1.7612000e-02, 1.4053064e+01],
[-1.3956340e+00, 4.6625410e+00],
[-7.5215700e-01, 6.5386200e+00],
[-1.3223710e+00, 7.1528530e+00],
[ 4.2336300e-01, 1.1054677e+01],
[ 4.0670400e-01, 7.0673350e+00],
[ 6.6739400e-01, 1.2741452e+01],
[-2.4601500e+00, 6.8668050e+00],
[ 5.6941100e-01, 9.5487550e+00],
[-2.6632000e-02, 1.0427743e+01],
[ 8.5043300e-01, 6.9203340e+00],
[ 1.3471830e+00, 1.3175500e+01],
[ 1.1768130e+00, 3.1670200e+00],
[-1.7818710e+00, 9.0979530e+00],
[-5.6660600e-01, 5.7490030e+00],
[ 9.3163500e-01, 1.5895050e+00],
[-2.4205000e-02, 6.1518230e+00],
[-3.6453000e-02, 2.6909880e+00],
[-1.9694900e-01, 4.4416500e-01],
[ 1.0144590e+00, 5.7543990e+00],
[ 1.9852980e+00, 3.2306190e+00],
[-1.6934530e+00, -5.5754000e-01],
[-5.7652500e-01, 1.1778922e+01],
[-3.4681100e-01, -1.6787300e+00],
[-2.1244840e+00, 2.6724710e+00],
[ 1.2179160e+00, 9.5970150e+00],
[-7.3392800e-01, 9.0986870e+00],
[-3.6420010e+00, -1.6180870e+00],
[ 3.1598500e-01, 3.5239530e+00],
[ 1.4166140e+00, 9.6192320e+00],
[-3.8632300e-01, 3.9892860e+00],
[ 5.5692100e-01, 8.2949840e+00],
[ 1.2248630e+00, 1.1587360e+01],
[-1.3478030e+00, -2.4060510e+00],
[ 1.1966040e+00, 4.9518510e+00],
[ 2.7522100e-01, 9.5436470e+00],
[ 4.7057500e-01, 9.3324880e+00],
[-1.8895670e+00, 9.5426620e+00],
[-1.5278930e+00, 1.2150579e+01],
[-1.1852470e+00, 1.1309318e+01],
[-4.4567800e-01, 3.2973030e+00],
[ 1.0422220e+00, 6.1051550e+00],
[-6.1878700e-01, 1.0320986e+01],
[ 1.1520830e+00, 5.4846700e-01],
[ 8.2853400e-01, 2.6760450e+00],
[-1.2377280e+00, 1.0549033e+01],
[-6.8356500e-01, -2.1661250e+00],
[ 2.2945600e-01, 5.9219380e+00],
[-9.5988500e-01, 1.1555336e+01],
[ 4.9291100e-01, 1.0993324e+01],
[ 1.8499200e-01, 8.7214880e+00],
[-3.5571500e-01, 1.0325976e+01],
[-3.9782200e-01, 8.0583970e+00],
[ 8.2483900e-01, 1.3730343e+01],
[ 1.5072780e+00, 5.0278660e+00],
[ 9.9671000e-02, 6.8358390e+00],
[-3.4400800e-01, 1.0717485e+01],
[ 1.7859280e+00, 7.7186450e+00],
[-9.1880100e-01, 1.1560217e+01],
[-3.6400900e-01, 4.7473000e+00],
[-8.4172200e-01, 4.1190830e+00],
[ 4.9042600e-01, 1.9605390e+00],
[-7.1940000e-03, 9.0757920e+00],
[ 3.5610700e-01, 1.2447863e+01],
[ 3.4257800e-01, 1.2281162e+01],
[-8.1082300e-01, -1.4660180e+00],
[ 2.5307770e+00, 6.4768010e+00],
[ 1.2966830e+00, 1.1607559e+01],
[ 4.7548700e-01, 1.2040035e+01],
[-7.8327700e-01, 1.1009725e+01],
[ 7.4798000e-02, 1.1023650e+01],
[-1.3374720e+00, 4.6833900e-01],
[-1.0278100e-01, 1.3763651e+01],
[-1.4732400e-01, 2.8748460e+00],
[ 5.1838900e-01, 9.8870350e+00],
[ 1.0153990e+00, 7.5718820e+00],
[-1.6580860e+00, -2.7255000e-02],
[ 1.3199440e+00, 2.1712280e+00],
[ 2.0562160e+00, 5.0199810e+00],
[-8.5163300e-01, 4.3756910e+00],
[-1.5100470e+00, 6.0619920e+00],
[-1.0766370e+00, -3.1818880e+00],
[ 1.8210960e+00, 1.0283990e+01],
[ 3.0101500e+00, 8.4017660e+00],
[-1.0994580e+00, 1.6882740e+00],
[-8.3487200e-01, -1.7338690e+00],
[-8.4663700e-01, 3.8490750e+00],
[ 1.4001020e+00, 1.2628781e+01],
[ 1.7528420e+00, 5.4681660e+00],
[ 7.8557000e-02, 5.9736000e-02],
[ 8.9392000e-02, -7.1530000e-01],
[ 1.8256620e+00, 1.2693808e+01],
[ 1.9744500e-01, 9.7446380e+00],
[ 1.2611700e-01, 9.2231100e-01],
[-6.7979700e-01, 1.2205300e+00],
[ 6.7798300e-01, 2.5566660e+00],
[ 7.6134900e-01, 1.0693862e+01],
[-2.1687910e+00, 1.4363200e-01],
[ 1.3886100e+00, 9.3419970e+00],
[ 3.1702900e-01, 1.4739025e+01]])
np.mat(dataSet.iloc[:,-1].values).T
matrix([[0],
[1],
[0],
[0],
[0],
[1],
[0],
[1],
[0],
[0],
[1],
[0],
[1],
[0],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[1],
[0],
[1],
[1],
[0],
[0],
[1],
[1],
[0],
[1],
[1],
[0],
[1],
[1],
[0],
[0],
[0],
[0],
[0],
[1],
[1],
[0],
[1],
[1],
[0],
[1],
[1],
[0],
[0],
[0],
[0],
[0],
[0],
[1],
[1],
[0],
[1],
[0],
[1],
[1],
[1],
[0],
[0],
[0],
[1],
[1],
[0],
[0],
[0],
[0],
[1],
[0],
[1],
[0],
[0],
[1],
[1],
[1],
[1],
[0],
[1],
[0],
[1],
[1],
[1],
[1],
[0],
[1],
[1],
[1],
[0],
[0],
[1],
[1],
[1],
[0],
[1],
[0],
[0]], dtype=int64)
xMat = np.mat(dataSet.iloc[:,:-1].values)
yMat = np.mat(dataSet.iloc[:,-1].values).T
m,n = xMat.shape
weights = np.zeros((n,1))
weights
array([[0.],
[0.]])
"""
函数功能:标准化(期望为0,方差为1)
参数说明:
xMat:特征矩阵
返回:
inMat:标准化之后的特征矩阵
"""
def BGD_LR(dataSet,alpha=0.001,maxCycles=500):#maxCycles指的是最大迭代次数
xMat = np.mat(dataSet.iloc[:,:-1].values)
yMat = np.mat(dataSet.iloc[:,-1].values).T
xMat = regularize(xMat)
m,n = xMat.shape
weights = np.zeros((n,1))
for i in range(maxCycles):
grad = xMat.T*(xMat * weights-yMat)/m
weights = weights -alpha*grad
return weights
BGD_LR(dataSet,alpha=0.001,maxCycles=500)
matrix([[ 0.00216921],
[-0.16320532]])
ws=BGD_LR(dataSet,alpha=0.01,maxCycles=500)
xMat = np.mat(dataSet.iloc[:, :-1].values)
yMat = np.mat(dataSet.iloc[:, -1].values).T
xMat = regularize(xMat)
(xMat * ws).A.flatten()#对(xMat * ws)做扁平化处理
array([-0.70915655, 0.06316312, -0.06083467, -0.16569736, -0.39005307,
-0.01533216, -0.52906893, -0.23235356, -0.23599289, -0.36795332,
0.03505109, -0.51406386, 0.41592948, -0.38697784, 0.02891359,
0.54454538, 0.03555741, 0.36098043, 0.55969558, 0.15852275,
0.47646723, 0.53101892, -0.54065346, 0.74759682, 0.19088669,
-0.18717433, -0.30080371, 0.47069011, 0.31141881, -0.17291747,
0.20972955, -0.11876328, -0.37433484, 0.73381939, 0.24921037,
-0.25972227, -0.22372825, -0.43778658, -0.65400415, -0.54645619,
0.27011361, 0.12772377, -0.40661688, 0.66087998, 0.43357637,
-0.47906407, 0.76585452, 0.07811623, -0.55111417, -0.37854252,
-0.18960068, -0.38543731, -0.17502127, -0.6093852 , 0.2676083 ,
-0.01876525, -0.42140155, 0.03674238, -0.54819343, 0.14006896,
0.16000859, 0.4732384 , -0.23883563, -0.52699542, -0.51238534,
0.68934636, 0.21517432, -0.37032942, -0.47870378, -0.48511691,
-0.41581268, 0.46355296, -0.68886791, 0.33451424, -0.27209895,
-0.01282753, 0.48391229, 0.52163339, 0.3135284 , 0.13498929,
-0.07825107, 0.82931382, -0.20233044, 0.07306015, 0.36807493,
0.71263128, 0.18507164, -0.45814141, 0.24628793, 0.61862901,
0.69262323, -0.42925222, -0.28508083, 0.54118376, 0.44673039,
0.43244636, -0.32820498, 0.4257641 , -0.14907293, -0.74631718])
p = sigmoid(xMat * ws).A.flatten()
p
array([0.32978524, 0.51578553, 0.48479602, 0.45867018, 0.40370453,
0.49616703, 0.37073407, 0.44217155, 0.44127408, 0.40903566,
0.50876188, 0.37424135, 0.6025088 , 0.40444503, 0.50722789,
0.63286916, 0.50888842, 0.58927775, 0.6363821 , 0.5395479 ,
0.61691332, 0.62972073, 0.36803558, 0.67865483, 0.54757729,
0.45334256, 0.42536102, 0.61554708, 0.57723154, 0.45687803,
0.55224104, 0.47034403, 0.40749399, 0.67564285, 0.56198214,
0.43543198, 0.44430008, 0.39226851, 0.34208778, 0.36668699,
0.5671208 , 0.5318876 , 0.39972361, 0.65945804, 0.60672735,
0.38247316, 0.68262346, 0.51951913, 0.36560595, 0.40647847,
0.45274132, 0.40481616, 0.45635604, 0.35219945, 0.56650565,
0.49530882, 0.39618142, 0.50918456, 0.36628365, 0.5349601 ,
0.53991702, 0.61614996, 0.44057331, 0.37121793, 0.37463451,
0.66582151, 0.55358698, 0.40846143, 0.38255826, 0.38104457,
0.39751917, 0.6138567 , 0.33428496, 0.58285735, 0.43239188,
0.49679316, 0.61867128, 0.62752963, 0.57774627, 0.53369617,
0.48044721, 0.69620982, 0.44958925, 0.51825692, 0.59099373,
0.67098232, 0.5461363 , 0.38742683, 0.56126263, 0.64990667,
0.66655022, 0.39430491, 0.42920859, 0.63208775, 0.60986157,
0.60645768, 0.41867744, 0.60486172, 0.46280063, 0.3216243 ])
for i, j in enumerate(p):
if j < 0.5:
p[i] = 0
else:
p[i] = 1
p
array([0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 1., 1., 1.,
1., 1., 1., 1., 1., 0., 1., 1., 0., 0., 1., 1., 0., 1., 0., 0., 1.,
1., 0., 0., 0., 0., 0., 1., 1., 0., 1., 1., 0., 1., 1., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 1., 0., 1., 1., 1., 0., 0., 0., 1., 1., 0.,
0., 0., 0., 1., 0., 1., 0., 0., 1., 1., 1., 1., 0., 1., 0., 1., 1.,
1., 1., 0., 1., 1., 1., 0., 0., 1., 1., 1., 0., 1., 0., 0.])
train_error = (np.fabs(yMat.A.flatten() - p)).sum()
train_error#4.0
train_error_rate = train_error / yMat.shape[0]
train_error_rate#0.04
1.4 准确率计算函数
将上述过程封装为函数,方便后续调用。
"""
函数功能:计算准确率
参数说明:
dataSet:DF数据集
method:计算权重函数
alpha:步长
maxCycles:最大迭代次数
返回:
trainAcc:模型预测准确率
"""
def logisticAcc(dataSet, method, alpha=0.01, maxCycles=500):
weights = method(dataSet,alpha=alpha,maxCycles=maxCycles)
p = sigmoid(xMat * ws).A.flatten()
for i, j in enumerate(p):
if j < 0.5:
p[i] = 0
else:
p[i] = 1
train_error = (np.fabs(yMat.A.flatten() - p)).sum()
trainAcc = 1 - train_error / yMat.shape[0]
return trainAcc
测试函数运行效果:
logisticAcc(dataSet, BGD_LR, alpha=0.01, maxCycles=5000)#0.96
2. 使用SGD求解逻辑回归
随机梯度下降法的伪代码:
每个回归系数初始化为1
对数据集中每个样本:
计算该样本的梯度
使用alpha*gradient更新回归系数值
返回回归系数值
2.1 SGD算法python实现
'''
函数功能:使用SGD求解逻辑回归
参数说明:
dataSet:DF数据集
alpha:步长
maxCycles:最大迭代次数
返回:
weights:各特征权重值
'''
def SGD_LR(dataSet,alpha=0.001,maxCycles=500):
dataSet = dataSet.sample(maxCycles, replace=True)
dataSet.index = range(dataSet.shape[0])
xMat = np.mat(dataSet.iloc[:, :-1].values)
yMat = np.mat(dataSet.iloc[:, -1].values).T
xMat = regularize(xMat)
m, n = xMat.shape
weights = np.zeros((n,1))
for i in range(m):
grad = xMat[i].T * (xMat[i] * weights - yMat[i])
weights = weights - alpha * grad
return weights
SGD_LR(dataSet,alpha=0.001,maxCycles=500)
matrix([[-0.00492631],
[-0.16468823]])
计算准确率:
logisticAcc(dataSet, SGD_LR, alpha=0.001, maxCycles=50000)#0.96
四、从疝气病症预测病马的死亡率
将使用Logistic回归来预测患疝气病的马的存活问题。原始数据集下载地址:http://archive.ics.uci.edu/ml/datasets/Horse+Colic
这里的数据包含了368个样本和28个特征。这种病不一定源自马的肠胃问题,其他问题也可能引发马疝病。该数据集中包含了医院检测马疝病的一些指标,有的指标比较主观,有的指标难以测量,例如马的疼痛级别。另外需要说明的是,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有30%的值是缺失的。下面将首先介绍如何处理数据集中的数据缺失问题,然后再利用Logistic回归和随机梯度上升算法来预测病马的生死。
1. 准备数据
数据中的缺失值是一个非常棘手的问题,很多文献都致力于解决这个问题。那么,数据缺失究竟带来了什么问题?假设有100个样本和20个特征,这些数据都是机器收集回来的。若机器上的某个传感器损坏导致一个特征无效时该怎么办?它们是否还可用?答案是肯定的。因为有时候数据相当昂贵,扔掉和重新获取都是不可取的,所以必须采用一些方法来解决这个问题。下面给出了一些可选的做法:
- 使用可用特征的均值来填补缺失值;
- 使用特殊值来填补缺失值,如-1;
- 忽略有缺失值的样本;
- 使用相似样本的均值添补缺失值;
- 使用另外的机器学习算法预测缺失值。
预处理数据做两件事:
- 如果测试集中一条数据的特征值已经确实,那么我们选择实数0来替换所有缺失值,因为本文使用Logistic回归。因此这样做不会影响回归系数的值。sigmoid(0)=0.5,即它对结果的预测不具有任何倾向性。
- 如果测试集中一条数据的类别标签已经缺失,那么我们将该类别数据丢弃,因为类别标签与特征不同,很难
确定采用某个合适的值来替换。原始的数据集经过处理,保存为两个文件:horseColicTest.txt和horseColicTraining.txt。
train = pd.read_table('horseColicTraining.txt',header=None)
train.shape#(299, 22)
train.head()
结果:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.0 | 1.0 | 38.5 | 66.0 | 28.0 | 3.0 | 3.0 | 0.0 | 2.0 | 5.0 | ... | 0.0 | 0.0 | 0.0 | 3.0 | 5.0 | 45.0 | 8.4 | 0.0 | 0.0 | 0.0 |
| 1 | 1.0 | 1.0 | 39.2 | 88.0 | 20.0 | 0.0 | 0.0 | 4.0 | 1.0 | 3.0 | ... | 0.0 | 0.0 | 0.0 | 4.0 | 2.0 | 50.0 | 85.0 | 2.0 | 2.0 | 0.0 |
| 2 | 2.0 | 1.0 | 38.3 | 40.0 | 24.0 | 1.0 | 1.0 | 3.0 | 1.0 | 3.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 33.0 | 6.7 | 0.0 | 0.0 | 1.0 |
| 3 | 1.0 | 9.0 | 39.1 | 164.0 | 84.0 | 4.0 | 1.0 | 6.0 | 2.0 | 2.0 | ... | 1.0 | 2.0 | 5.0 | 3.0 | 0.0 | 48.0 | 7.2 | 3.0 | 5.3 | 0.0 |
| 4 | 2.0 | 1.0 | 37.3 | 104.0 | 35.0 | 0.0 | 0.0 | 6.0 | 2.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 74.0 | 7.4 | 0.0 | 0.0 | 0.0 |
5 rows × 22 columns
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 299 entries, 0 to 298
Data columns (total 22 columns):
0 299 non-null float64
1 299 non-null float64
2 299 non-null float64
3 299 non-null float64
4 299 non-null float64
5 299 non-null float64
6 299 non-null float64
7 299 non-null float64
8 299 non-null float64
9 299 non-null float64
10 299 non-null float64
11 299 non-null float64
12 299 non-null float64
13 299 non-null float64
14 299 non-null float64
15 299 non-null float64
16 299 non-null float64
17 299 non-null float64
18 299 non-null float64
19 299 non-null float64
20 299 non-null float64
21 299 non-null float64
dtypes: float64(22)
memory usage: 51.5 KB
test = pd.read_table('horseColicTest.txt',header=None)
test.head()
结果:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 1 | 38.5 | 54 | 20 | 0 | 1 | 2 | 2 | 3 | ... | 2 | 2 | 5.9 | 0 | 2 | 42.0 | 6.3 | 0 | 0.0 | 1 |
| 1 | 2 | 1 | 37.6 | 48 | 36 | 0 | 0 | 1 | 1 | 0 | ... | 0 | 0 | 0.0 | 0 | 0 | 44.0 | 6.3 | 1 | 5.0 | 1 |
| 2 | 1 | 1 | 37.7 | 44 | 28 | 0 | 4 | 3 | 2 | 5 | ... | 1 | 1 | 0.0 | 3 | 5 | 45.0 | 70.0 | 3 | 2.0 | 1 |
| 3 | 1 | 1 | 37.0 | 56 | 24 | 3 | 1 | 4 | 2 | 4 | ... | 1 | 1 | 0.0 | 0 | 0 | 35.0 | 61.0 | 3 | 2.0 | 0 |
| 4 | 2 | 1 | 38.0 | 42 | 12 | 3 | 0 | 3 | 1 | 1 | ... | 0 | 0 | 0.0 | 0 | 2 | 37.0 | 5.8 | 0 | 0.0 | 1 |
5 rows × 22 columns
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 67 entries, 0 to 66
Data columns (total 22 columns):
0 67 non-null int64
1 67 non-null int64
2 67 non-null float64
3 67 non-null int64
4 67 non-null int64
5 67 non-null int64
6 67 non-null int64
7 67 non-null int64
8 67 non-null int64
9 67 non-null int64
10 67 non-null int64
11 67 non-null int64
12 67 non-null int64
13 67 non-null int64
14 67 non-null float64
15 67 non-null int64
16 67 non-null int64
17 67 non-null float64
18 67 non-null float64
19 67 non-null int64
20 67 non-null float64
21 67 non-null int64
dtypes: float64(5), int64(17)
memory usage: 11.6 KB
2. logistic回归分类函数
得到训练集和测试集之后,我们可以利用前面的BGD_LR或者SGD_LR得到训练集的weights。这里需要定义一个分类函数,根据sigmoid函数返回的值来确定y是0还是1。
'''
函数功能:给定测试数据和权重,返回标签类别
参数说明:
inX:测试数据
weights:特征权重
'''
def classify(inX,weights):
p = sigmoid(sum(inX * weights))
if p < 0.5:
return 0
else:
return 1
构建logistic模型:
"""
函数功能:logistic分类模型
参数说明:
train:测试集
test:训练集
alpha:步长
maxCycles:最大迭代次数
返回:
retest:预测好标签的测试集
"""
def get_acc(train,test,alpha=0.001, maxCycles=5000):
weights = SGD_LR(train,alpha=alpha,maxCycles=maxCycles)
xMat = np.mat(test.iloc[:, :-1].values)
xMat = regularize(xMat)
result = []
for inX in xMat:
label = classify(inX,weights)
result.append(label)
retest=test.copy()
retest['predict']=result
acc = (retest.iloc[:,-1]==retest.iloc[:,-2]).mean()
print(f'模型准确率为:{acc}')
return retest
get_acc(train,test,alpha=0.001, maxCycles=5000)
结果:模型准确率为:0.7611940298507462
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | predict | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 1 | 38.5 | 54 | 20 | 0 | 1 | 2 | 2 | 3 | ... | 2 | 5.9 | 0 | 2 | 42.0 | 6.3 | 0 | 0.0 | 1 | 1 |
| 1 | 2 | 1 | 37.6 | 48 | 36 | 0 | 0 | 1 | 1 | 0 | ... | 0 | 0.0 | 0 | 0 | 44.0 | 6.3 | 1 | 5.0 | 1 | 1 |
| 2 | 1 | 1 | 37.7 | 44 | 28 | 0 | 4 | 3 | 2 | 5 | ... | 1 | 0.0 | 3 | 5 | 45.0 | 70.0 | 3 | 2.0 | 1 | 0 |
| 3 | 1 | 1 | 37.0 | 56 | 24 | 3 | 1 | 4 | 2 | 4 | ... | 1 | 0.0 | 0 | 0 | 35.0 | 61.0 | 3 | 2.0 | 0 | 0 |
| 4 | 2 | 1 | 38.0 | 42 | 12 | 3 | 0 | 3 | 1 | 1 | ... | 0 | 0.0 | 0 | 2 | 37.0 | 5.8 | 0 | 0.0 | 1 | 1 |
| 5 | 1 | 1 | 0.0 | 60 | 40 | 3 | 0 | 1 | 1 | 0 | ... | 2 | 0.0 | 0 | 5 | 42.0 | 72.0 | 0 | 0.0 | 1 | 1 |
| 6 | 2 | 1 | 38.4 | 80 | 60 | 3 | 2 | 2 | 1 | 3 | ... | 2 | 0.0 | 1 | 1 | 54.0 | 6.9 | 0 | 0.0 | 1 | 1 |
| 7 | 2 | 1 | 37.8 | 48 | 12 | 2 | 1 | 2 | 1 | 3 | ... | 0 | 0.0 | 2 | 0 | 48.0 | 7.3 | 1 | 0.0 | 1 | 1 |
| 8 | 2 | 1 | 37.9 | 45 | 36 | 3 | 3 | 3 | 2 | 2 | ... | 1 | 0.0 | 3 | 0 | 33.0 | 5.7 | 3 | 0.0 | 1 | 1 |
| 9 | 2 | 1 | 39.0 | 84 | 12 | 3 | 1 | 5 | 1 | 2 | ... | 2 | 7.0 | 0 | 4 | 62.0 | 5.9 | 2 | 2.2 | 0 | 0 |
| 10 | 2 | 1 | 38.2 | 60 | 24 | 3 | 1 | 3 | 2 | 3 | ... | 3 | 0.0 | 4 | 4 | 53.0 | 7.5 | 2 | 1.4 | 1 | 1 |
| 11 | 1 | 1 | 0.0 | 140 | 0 | 0 | 0 | 4 | 2 | 5 | ... | 1 | 0.0 | 0 | 5 | 30.0 | 69.0 | 0 | 0.0 | 0 | 0 |
| 12 | 1 | 1 | 37.9 | 120 | 60 | 3 | 3 | 3 | 1 | 5 | ... | 2 | 7.5 | 4 | 5 | 52.0 | 6.6 | 3 | 1.8 | 0 | 0 |
| 13 | 2 | 1 | 38.0 | 72 | 36 | 1 | 1 | 3 | 1 | 3 | ... | 1 | 0.0 | 3 | 5 | 38.0 | 6.8 | 2 | 2.0 | 1 | 1 |
| 14 | 2 | 9 | 38.0 | 92 | 28 | 1 | 1 | 2 | 1 | 1 | ... | 0 | 7.2 | 0 | 0 | 37.0 | 6.1 | 1 | 1.1 | 1 | 1 |
| 15 | 1 | 1 | 38.3 | 66 | 30 | 2 | 3 | 1 | 1 | 2 | ... | 2 | 8.5 | 4 | 5 | 37.0 | 6.0 | 0 | 0.0 | 1 | 1 |
| 16 | 2 | 1 | 37.5 | 48 | 24 | 3 | 1 | 1 | 1 | 2 | ... | 1 | 0.0 | 3 | 2 | 43.0 | 6.0 | 1 | 2.8 | 1 | 1 |
| 17 | 1 | 1 | 37.5 | 88 | 20 | 2 | 3 | 3 | 1 | 4 | ... | 0 | 0.0 | 0 | 0 | 35.0 | 6.4 | 1 | 0.0 | 0 | 0 |
| 18 | 2 | 9 | 0.0 | 150 | 60 | 4 | 4 | 4 | 2 | 5 | ... | 0 | 0.0 | 0 | 0 | 0.0 | 0.0 | 0 | 0.0 | 0 | 0 |
| 19 | 1 | 1 | 39.7 | 100 | 30 | 0 | 0 | 6 | 2 | 4 | ... | 0 | 0.0 | 4 | 5 | 65.0 | 75.0 | 0 | 0.0 | 0 | 0 |
| 20 | 1 | 1 | 38.3 | 80 | 0 | 3 | 3 | 4 | 2 | 5 | ... | 1 | 0.0 | 4 | 4 | 45.0 | 7.5 | 2 | 4.6 | 1 | 0 |
| 21 | 2 | 1 | 37.5 | 40 | 32 | 3 | 1 | 3 | 1 | 3 | ... | 1 | 0.0 | 0 | 5 | 32.0 | 6.4 | 1 | 1.1 | 1 | 1 |
| 22 | 1 | 1 | 38.4 | 84 | 30 | 3 | 1 | 5 | 2 | 4 | ... | 3 | 6.5 | 4 | 4 | 47.0 | 7.5 | 3 | 0.0 | 0 | 0 |
| 23 | 1 | 1 | 38.1 | 84 | 44 | 4 | 0 | 4 | 2 | 5 | ... | 3 | 5.0 | 0 | 4 | 60.0 | 6.8 | 0 | 5.7 | 0 | 0 |
| 24 | 2 | 1 | 38.7 | 52 | 0 | 1 | 1 | 1 | 1 | 1 | ... | 0 | 0.0 | 1 | 3 | 4.0 | 74.0 | 0 | 0.0 | 1 | 1 |
| 25 | 2 | 1 | 38.1 | 44 | 40 | 2 | 1 | 3 | 1 | 3 | ... | 0 | 0.0 | 1 | 3 | 35.0 | 6.8 | 0 | 0.0 | 1 | 1 |
| 26 | 2 | 1 | 38.4 | 52 | 20 | 2 | 1 | 3 | 1 | 1 | ... | 1 | 0.0 | 3 | 5 | 41.0 | 63.0 | 1 | 1.0 | 1 | 1 |
| 27 | 1 | 1 | 38.2 | 60 | 0 | 1 | 0 | 3 | 1 | 2 | ... | 1 | 0.0 | 4 | 4 | 43.0 | 6.2 | 2 | 3.9 | 1 | 1 |
| 28 | 2 | 1 | 37.7 | 40 | 18 | 1 | 1 | 1 | 0 | 3 | ... | 1 | 0.0 | 3 | 3 | 36.0 | 3.5 | 0 | 0.0 | 1 | 1 |
| 29 | 1 | 1 | 39.1 | 60 | 10 | 0 | 1 | 1 | 0 | 2 | ... | 0 | 0.0 | 4 | 4 | 0.0 | 0.0 | 0 | 0.0 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 37 | 2 | 1 | 37.5 | 44 | 0 | 1 | 1 | 1 | 1 | 3 | ... | 0 | 0.0 | 0 | 0 | 45.0 | 5.8 | 2 | 1.4 | 1 | 1 |
| 38 | 2 | 1 | 38.2 | 42 | 16 | 1 | 1 | 3 | 1 | 1 | ... | 0 | 0.0 | 1 | 0 | 35.0 | 60.0 | 1 | 1.0 | 1 | 1 |
| 39 | 2 | 1 | 38.0 | 56 | 44 | 3 | 3 | 3 | 0 | 0 | ... | 1 | 0.0 | 4 | 0 | 47.0 | 70.0 | 2 | 1.0 | 1 | 1 |
| 40 | 2 | 1 | 38.3 | 45 | 20 | 3 | 3 | 2 | 2 | 2 | ... | 0 | 0.0 | 4 | 0 | 0.0 | 0.0 | 0 | 0.0 | 1 | 1 |
| 41 | 1 | 1 | 0.0 | 48 | 96 | 1 | 1 | 3 | 1 | 0 | ... | 1 | 0.0 | 1 | 4 | 42.0 | 8.0 | 1 | 0.0 | 1 | 1 |
| 42 | 1 | 1 | 37.7 | 55 | 28 | 2 | 1 | 2 | 1 | 2 | ... | 3 | 5.0 | 4 | 5 | 0.0 | 0.0 | 0 | 0.0 | 1 | 0 |
| 43 | 2 | 1 | 36.0 | 100 | 20 | 4 | 3 | 6 | 2 | 2 | ... | 1 | 0.0 | 4 | 5 | 74.0 | 5.7 | 2 | 2.5 | 0 | 0 |
| 44 | 1 | 1 | 37.1 | 60 | 20 | 2 | 0 | 4 | 1 | 3 | ... | 2 | 5.0 | 3 | 4 | 64.0 | 8.5 | 2 | 0.0 | 1 | 0 |
| 45 | 2 | 1 | 37.1 | 114 | 40 | 3 | 0 | 3 | 2 | 2 | ... | 0 | 0.0 | 0 | 3 | 32.0 | 0.0 | 3 | 6.5 | 1 | 0 |
| 46 | 1 | 1 | 38.1 | 72 | 30 | 3 | 3 | 3 | 1 | 4 | ... | 1 | 0.0 | 3 | 5 | 37.0 | 56.0 | 3 | 1.0 | 1 | 0 |
| 47 | 1 | 1 | 37.0 | 44 | 12 | 3 | 1 | 1 | 2 | 1 | ... | 0 | 0.0 | 4 | 2 | 40.0 | 6.7 | 3 | 8.0 | 1 | 1 |
| 48 | 1 | 1 | 38.6 | 48 | 20 | 3 | 1 | 1 | 1 | 4 | ... | 0 | 0.0 | 3 | 0 | 37.0 | 75.0 | 0 | 0.0 | 1 | 1 |
| 49 | 1 | 1 | 0.0 | 82 | 72 | 3 | 1 | 4 | 1 | 2 | ... | 3 | 0.0 | 4 | 4 | 53.0 | 65.0 | 3 | 2.0 | 0 | 0 |
| 50 | 1 | 9 | 38.2 | 78 | 60 | 4 | 4 | 6 | 0 | 3 | ... | 0 | 0.0 | 1 | 0 | 59.0 | 5.8 | 3 | 3.1 | 0 | 0 |
| 51 | 2 | 1 | 37.8 | 60 | 16 | 1 | 1 | 3 | 1 | 2 | ... | 2 | 0.0 | 3 | 0 | 41.0 | 73.0 | 0 | 0.0 | 0 | 1 |
| 52 | 1 | 1 | 38.7 | 34 | 30 | 2 | 0 | 3 | 1 | 2 | ... | 0 | 0.0 | 0 | 0 | 33.0 | 69.0 | 0 | 2.0 | 0 | 1 |
| 53 | 1 | 1 | 0.0 | 36 | 12 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 0.0 | 1 | 5 | 44.0 | 0.0 | 0 | 0.0 | 1 | 0 |
| 54 | 2 | 1 | 38.3 | 44 | 60 | 0 | 0 | 1 | 1 | 0 | ... | 0 | 0.0 | 0 | 0 | 6.4 | 36.0 | 0 | 0.0 | 1 | 1 |
| 55 | 2 | 1 | 37.4 | 54 | 18 | 3 | 0 | 1 | 1 | 3 | ... | 2 | 0.0 | 4 | 5 | 30.0 | 7.1 | 2 | 0.0 | 1 | 1 |
| 56 | 1 | 1 | 0.0 | 0 | 0 | 4 | 3 | 0 | 2 | 2 | ... | 0 | 0.0 | 0 | 0 | 54.0 | 76.0 | 3 | 2.0 | 1 | 1 |
| 57 | 1 | 1 | 36.6 | 48 | 16 | 3 | 1 | 3 | 1 | 4 | ... | 1 | 0.0 | 0 | 0 | 27.0 | 56.0 | 0 | 0.0 | 0 | 0 |
| 58 | 1 | 1 | 38.5 | 90 | 0 | 1 | 1 | 3 | 1 | 3 | ... | 3 | 2.0 | 4 | 5 | 47.0 | 79.0 | 0 | 0.0 | 1 | 0 |
| 59 | 1 | 1 | 0.0 | 75 | 12 | 1 | 1 | 4 | 1 | 5 | ... | 3 | 5.8 | 0 | 0 | 58.0 | 8.5 | 1 | 0.0 | 1 | 0 |
| 60 | 2 | 1 | 38.2 | 42 | 0 | 3 | 1 | 1 | 1 | 1 | ... | 1 | 0.0 | 3 | 2 | 35.0 | 5.9 | 2 | 0.0 | 1 | 1 |
| 61 | 1 | 9 | 38.2 | 78 | 60 | 4 | 4 | 6 | 0 | 3 | ... | 0 | 0.0 | 1 | 0 | 59.0 | 5.8 | 3 | 3.1 | 0 | 0 |
| 62 | 2 | 1 | 38.6 | 60 | 30 | 1 | 1 | 3 | 1 | 4 | ... | 1 | 0.0 | 0 | 0 | 40.0 | 6.0 | 1 | 0.0 | 1 | 1 |
| 63 | 2 | 1 | 37.8 | 42 | 40 | 1 | 1 | 1 | 1 | 1 | ... | 0 | 0.0 | 3 | 3 | 36.0 | 6.2 | 0 | 0.0 | 1 | 1 |
| 64 | 1 | 1 | 38.0 | 60 | 12 | 1 | 1 | 2 | 1 | 2 | ... | 1 | 0.0 | 1 | 4 | 44.0 | 65.0 | 3 | 2.0 | 0 | 1 |
| 65 | 2 | 1 | 38.0 | 42 | 12 | 3 | 0 | 3 | 1 | 1 | ... | 0 | 0.0 | 0 | 1 | 37.0 | 5.8 | 0 | 0.0 | 1 | 1 |
| 66 | 2 | 1 | 37.6 | 88 | 36 | 3 | 1 | 1 | 1 | 3 | ... | 3 | 1.5 | 0 | 0 | 44.0 | 6.0 | 0 | 0.0 | 0 | 1 |
67 rows × 23 columns
机器学习实战之Logistic回归的更多相关文章
- 05机器学习实战之Logistic 回归
Logistic 回归 概述 Logistic 回归 或者叫逻辑回归 虽然名字有回归,但是它是用来做分类的.其主要思想是: 根据现有数据对分类边界线(Decision Boundary)建立回归公式, ...
- 《机器学习实战》Logistic回归
注释:Ng的视频有完整的推到步骤,不过理论和实践还是有很大差别的,代码实现还得完成 1.Logistic回归理论 http://www.cnblogs.com/wjy-lulu/p/7759515.h ...
- 机器学习实战之logistic回归分类
利用logistic回归进行分类的主要思想:根据现有数据对分类边界建立回归公式,并以此进行分类. logistic优缺点: 优点:计算代价不高,易于理解和实现.缺点:容易欠拟合,分类精度可能不高. . ...
- 05机器学习实战之Logistic 回归scikit-learn实现
https://blog.csdn.net/zengxiantao1994/article/details/72787849似然函数 原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概 ...
- 机器学习(4)之Logistic回归
机器学习(4)之Logistic回归 1. 算法推导 与之前学过的梯度下降等不同,Logistic回归是一类分类问题,而前者是回归问题.回归问题中,尝试预测的变量y是连续的变量,而在分类问题中,y是一 ...
- 机器学习实践之Logistic回归
关于本文说明,本人原博客地址位于http://blog.csdn.net/qq_37608890,本文来自笔者于2017年12月17日 19:18:31所撰写内容(http://blog.cs ...
- 机器学习之线性回归---logistic回归---softmax回归
在本节中,我们介绍Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 可以取两个以上的值. Softmax回归模型对于诸如MNIST手写数字分类等问题 ...
- 机器学习(1):Logistic回归原理及其实现
Logistic回归是机器学习中非常经典的一个方法,主要用于解决二分类问题,它是多分类问题softmax的基础,而softmax在深度学习中的网络后端做为常用的分类器,接下来我们将从原理和实现来阐述该 ...
- 机器学习入门-逻辑(Logistic)回归(1)
原文地址:http://www.bugingcode.com/machine_learning/ex3.html 关于机器学习的教程确实是太多了,处于这种变革的时代,出去不说点机器学习的东西,都觉得自 ...
随机推荐
- java——HashMap、Hashtable
Map:类似Python的字典 HashMap: 不支持线程的同步,即同一时刻不能有多个线程同时写HashMap: 最多只允许一条记录的键值为null,不允许多条记录的值为null HashMap遍历 ...
- JavaSE---Collections
1.简介: Collections是一个工具类 1.1 排序 a,正序 sort是其静态方法,有2种参数形式: public static <T extends Comparable<? ...
- DB Intro - MySQL and MongoDB
mysql> CREATE TABLE tutorials_tbl( tutorial_id INT, tutorial_title VARCHAR(100), tutorial_author ...
- [转]25个HTML5和JavaScript游戏引擎库
本文转自:http://www.open-open.com/news/view/27c6ed 1. The GMP JavaScript Game Engine GMP是一个基于精灵2-D游戏,它可以 ...
- pat04-树5. File Transfer (25)
04-树5. File Transfer (25) 时间限制 150 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue We have ...
- HDU 4578——Transformation——————【线段树区间操作、确定操作顺序】
Transformation Time Limit: 15000/8000 MS (Java/Others) Memory Limit: 65535/65536 K (Java/Others)T ...
- POJ 1861 ——Network——————【最小瓶颈生成树】
Network Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 15268 Accepted: 5987 Specia ...
- 深入理解.net remoting 与webservice
1. .NET Remoting .NET Remoting是微软随.NET推出的一种分布式应用解决方案,被誉为管理应用程序域之间的 RPC 的首选技,它允许不同应用程序域之间进行通信(这里的通信可以 ...
- 使用Zxing生成一维码和二维码
首先引用zxing.dll 到项目中引用 using System; using System.Collections.Generic; using System.Drawing; using Sys ...
- Chrome调式技巧
1. 使用alert()调试 2. console 基本输出 console.log("打印字符串"); console.error("我是个错误"); co ...