java大批量数据导入(MySQL)
© 版权声明:本文为博主原创文章,转载请注明出处
最近同事碰到大批量数据导入问题,因此也关注了一下。大批量数据导入主要存在两点问题:内存溢出和导入速率慢。
内存溢出:将文件中的数据全部取出放在集合中,当数据过多时就出现Java内存溢出,此时可通过调大JVM的最大可用内存(Xmx)解决,
但终究不是王道。
MySQL支持一条SQL语句插入多条记录的操作,并且效率比单条插入快的不是一点点;但是MySQL一次可接受的数据包大小
也是有限制的,当一次插入过多时也可能造成数据包内存溢出,此时可通过调大MySQL的max_allowed_packet 解决,
但也不是王道。
导入速率慢:单条插入就不用考虑了,因此考虑一条SQL语句插入多条记录,
根据上述所说还应控制好一条插入的数据大小不能超过max_allowed_packet 的配置。
下面比较了用PreparedStatement和直接拼接SQL两种批量插入的方式的速率(一次插入1w条)
package org.javaio.CSV; import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.text.SimpleDateFormat;
import java.util.Date; import com.mysql.jdbc.Connection; /**
* 导入大批量CSV文件
*
*/
public class Test { /**
* jdbc所属,暂不使用
*/
private final static String url = "jdbc:mysql://localhost:3306/demo_test?useSSL=true&characterEncoding=utf8";
private final static String name = "root";
private final static String pwd = "20121221";
private static Connection conn;
private static PreparedStatement ps; /**
* 解析csv文件并插入到数据库中,暂不使用(jdbc)
*
* @param args
*
* @throws Exception
*/
public static void main(String[] args) throws Exception { Test test = new Test(); // psBatch 时间统计 - 开始
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String startTime = sdf.format(new Date());
System.out.println("psBatch 开始时间为:" + startTime);
System.out.println("psBatch 开始执行..."); // 使用PreparedStatement批量插入
int idx = test.psBatch(); // 统计时间 - 结束
System.out.println("psBatch 执行完成,共插入" + idx + "条数据");
String endTime = sdf.format(new Date());
System.out.println("psBatch 结束时间为:" + endTime); System.out.println(); // 时间统计 - 开始
startTime = sdf.format(new Date());
System.out.println("sqlBatch 开始时间为:" + startTime);
System.out.println("sqlBatch 开始执行..."); // 使用SQL语句批量插入
idx = test.sqlBatch(); // 统计时间 - 结束
System.out.println("sqlBatch 执行完成,共插入" + idx + "条数据");
endTime = sdf.format(new Date());
System.out.println("sqlBatch 结束时间为:" + endTime); } /**
* 使用PreparedStatement批量插入
*
* @return
*
* @throws Exception
*/
private int psBatch() throws Exception { int idx = 0;// 行数 try {
// 读取CSV文件
FileInputStream fis = new FileInputStream("C:/Users/chen/Desktop/data/ceshi .csv");
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
BufferedReader br = new BufferedReader(isr); String line;// 行数据
String[] column = new String[4];// 列数据 // 获取数据库连接
conn = getConnection();
// 设置不自动提交
conn.setAutoCommit(false); // SQL
String sql = "insert into test (name, `desc`, column1, column2, column3, column4) "
+ "values (?, ?, ?, ?, ?, ?)";
ps = conn.prepareStatement(sql); while ((line = br.readLine()) != null) {// 循环读取每一行
idx++;// 计数
column = line.split(",");
ps.setString(1, column[0]);
if (column.length >= 2 && column[1] != null) {
ps.setString(2, column[1]);
} else {
ps.setString(2, "");
}
if (column.length >= 3 && column[2] != null) {
ps.setString(3, column[2]);
} else {
ps.setString(3, "");
}
if (column.length >= 4 && column[3] != null) {
ps.setString(4, column[3]);
} else {
ps.setString(4, "");
}
ps.setString(5, "type");
ps.setString(6, "1");
ps.addBatch();
if (idx % 10000 == 0) {
ps.executeBatch();
conn.commit();
ps.clearBatch();
}
}
if (idx % 10000 != 0) {
ps.executeBatch();
conn.commit();
ps.clearBatch();
}
} catch (Exception e) {
System.out.println("第" + idx + "前一万条数据插入出错...");
} finally {
try {
if (ps != null) {
// 关闭连接
ps.close();
}
if (conn != null) {
conn.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
} return idx; } /**
* 使用sql语句批量插入
*
* @return
*
* @throws Exception
*/
private int sqlBatch() { int idx = 0;// 行数 try { // 读取CSV文件
FileInputStream fis = new FileInputStream("C:/Users/chen/Desktop/data/ceshi .csv");
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
BufferedReader br = new BufferedReader(isr); String line;// 行数据
String[] column = new String[4];// 列数据 // 获取数据库连接
conn = getConnection(); // SQL
StringBuffer sql = new StringBuffer("insert into test (name, `desc`, column1, column2, column3, column4) "
+ "values "); while ((line = br.readLine()) != null) {// 循环读取每一行
idx++;// 计数
column = line.split(",");
sql.append("('" + column[0] + "', '");
if (column.length >= 2 && column[1] != null) {
sql.append(column[1] + "', '");
} else {
sql.append("', '");
}
if (column.length >= 3 && column[2] != null) {
sql.append(column[2] + "', '");
} else {
sql.append("', '");
}
if (column.length >= 4 && column[3] != null) {
sql.append(column[3] + "', '");
} else {
sql.append("', '");
}
sql.append("type', '1'),");
if (idx % 10000 == 0) {
String executeSql = sql.toString().substring(0, sql.toString().lastIndexOf(","));
ps = conn.prepareStatement(executeSql);
ps.executeUpdate();
sql = new StringBuffer("insert into test (name, `desc`, column1, column2, column3, column4) "
+ "values ");
}
}
if (idx % 10000 != 0) {
String executeSql = sql.toString().substring(0, sql.toString().lastIndexOf(","));
ps = conn.prepareStatement(executeSql);
ps.executeUpdate();
}
} catch (Exception e) {
System.out.println("第" + idx + "前一万条数据插入出错...");
} finally {
try {
if (ps != null) {
// 关闭连接
ps.close();
}
if (conn != null) {
conn.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
} return idx; } /**
* 获取数据库连接
*
* @param sql
* SQL语句
*/
private Connection getConnection() throws Exception { Class.forName("com.mysql.jdbc.Driver");
conn = (Connection) DriverManager.getConnection(url, name, pwd);
return conn; } }
速率比较:为了排除其他影响,两次次都是在空表的情况下进行导入的
用SQL拼接批量插入用时大概3-4分钟
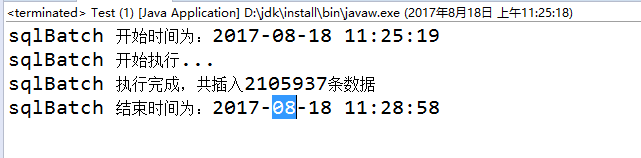
用PreparedStatement批量插入用时大概10分钟

java大批量数据导入(MySQL)的更多相关文章
- Java实现大批量数据导入导出(100W以上) -(二)导出
使用POI或JXLS导出大数据量(百万级)Excel报表常常面临两个问题: 1. 服务器内存溢出: 2. 一次从数据库查询出这么大数据,查询缓慢. 当然也可以分页查询出数据,分别生成多个Excel打包 ...
- Java实现大批量数据导入导出(100W以上) -(一)导入
最近业务方有一个需求,需要一次导入超过100万数据到系统数据库.可能大家首先会想,这么大的数据,干嘛通过程序去实现导入,为什么不直接通过SQL导入到数据库. 大数据量报表导出请参考:Java实现大批量 ...
- Java实现大批量数据导入导出(100W以上) -(三)超过25列Excel导出
前面一篇文章介绍大数据量导出实现: Java实现大批量数据导入导出(100W以上) -(二)导出 这篇文章在Excel列较少时,按以上实际验证能很快实现生成.但如果列较多时用StringTemplat ...
- 将Excel数据导入mysql数据库的几种方法
将Excel数据导入mysql数据库的几种方法 “我的面试感悟”有奖征文大赛结果揭晓! 前几天需要将Excel表格中的数据导入到mysql数据库中,在网上查了半天,研究了半天,总结出以下几种方法,下面 ...
- 使用MapReduce将HDFS数据导入Mysql
使用MapReduce将Mysql数据导入HDFS代码链接 将HDFS数据导入Mysql,代码示例 package com.zhen.mysqlToHDFS; import java.io.DataI ...
- 把execel表数据导入mysql数据库
今天,是我来公司第二周的第一天. 作为新入职的实习生,目前还没适合我的实质项目工作,今天的学习任务是: 把execel表数据导入到mysql数据库,再练习下java操作JDBC. 先了解下execel ...
- 使用MySQL Migration Toolkit快速将Oracle数据导入MySQL[转]
使用MySQL Migration Toolkit快速将Oracle数据导入MySQL上来先说点废话本人最近在学习一些数据库方面的知识,之前接触过Oracle和MySQL,最近又很流行MongoDB非 ...
- SQLServer2005数据导入Mysql到详细教程
如果转载请注明转载地址,谢谢. SQL SERVER数据导入MYSQL目录 1.Navicat for MySQL 版本10.0.9 2.创建目标数据库 3.创建正确的SQL SERVER数据库ODB ...
- Excel连接到MySQL,将Excel数据导入MySql,MySQL for Excel,,
Excel连接到MySQL 即使当今时代我们拥有了类似微软水晶报表之类的强大报表工具和其他一些灵活的客户管 理应用工具,众多企业在分析诸如销售统计和收入信息的时候,微软的Excel依然是最常用的工具. ...
随机推荐
- git从远程仓库中更新代码到本地仓库
git从远程仓库中更新代码到本地仓库 有时候在使用git pull的时候,会莫名才报错.查了很多资料,尝试过git的很多命令.包括git fetch命令,都会报同样的错.最后终于发现了一条捷径,由网友 ...
- Guava源码学习(一)Optional
基于版本:Guava 22.0 Wiki:Using and avoiding null 0:Optional简介 null在很多场景下会引发问题,NullPointerException困扰过无数的 ...
- HDU 6235.Permutation (2017中国大学生程序设计竞赛-哈尔滨站-重现赛)
Permutation Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Tot ...
- Kali Linux下运行Sniffjoke出错的解决
Kali Linux下运行Sniffjoke出错的解决 由于Kali Linux版本的更新和Sniffjoke发布时间久远等问题,Sniffjoke在新版本的Kali Linux中运行存在各种问题.下 ...
- Laravel 使用firstOrCreate 报错MassAssignmentException
今天尝试使用firstOrCreate去优化一段查找不到即创建的代码,结果发现会报MassAssignmentException错误,提示我参数错误,去网上找了好久没有找到结果,最后庆幸自己解决了,把 ...
- MySQL判断中文字符的方法(转)
准备: 2.1.环境 MySQL mysql> SHOW VARIABLES LIKE "%version%"; +-------------------------+--- ...
- VUE -- Mac上解决Chrome浏览器跨域问题
最近做前端开发总是遇到一个很奇怪的现象,同一个AJAX请求,在Chrome里调试的时候就会提示跨域,但是在手机模拟器或者真机上调试的时候就不会,于是百度了一下,发现是Chrome的安全策略导致的,需要 ...
- [置顶]
kubernetes资源类型--PetSets/StatefulSet
PetSet首次在K8S1.4版本中,在1.5更名为StatefulSet.除了改了名字之外,这一API对象并没有太大变化. 注意:以下内容的验证环境为CentOS7.K8S版本1.5.2,并部署Sk ...
- POJ 3486 & HDU 1913 Computers(dp)
题目链接:PKU:HDU: PKU:http://poj.org/problem?id=3486 HDU:pid=1913" target="_blank">htt ...
- 前后台JSON传值得一个问题和异常处理net.sf.json.JSONException: Unquotted string '"name"'
项目中做导入的时候遇到个bug,用JSON.stringify()序列号json对象传给后台:然后后台通过getPatameter()获取值时,前台的英文引号变成了中文引号. 原来代码如下:(自己排查 ...