Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下:
Hive文件存储格式
Hive 操作之表操作:创建外、内部表
Hive操作之表操作:表查询
Hive操作之表操作:数据加载
Hive操作之表操作:插入单表、插入多表
Hive语法结构:where 查询、all 和 distinct 选项、基于 Partition 的查询、基于 HAVING 的查询、 LIMIT 限制查询、 GROUP BY 分组查询、 ORDER BY 排序查询、SORT BY 查询、DISTRIBUTE BY 排序查询、CLUSTER BY 查询
Hive操作之视图操作
Hive操作之索引操作
Hive操作之分区操作:创建分区
Hive操作之分区操作:插入数据
Hive操作之分区操作:动态分区
Hive操作之桶操作
Hive操作之符合类型:Struct使用
Hive操作之符合类型:Array使用
Hive操作之符合类型:Map使用
Hive操作之join用法:等连接
Hive操作之join用法:多表连接
Hive操作之join用法:join的缓存和任务转换
Hive操作之join用法:join的结果
Hive操作之join用法:join的过滤
Hive操作之join用法:join的顺序
Hive操作之join用法:map 端 join
Hive操作之Hive 内置操作符与函数:字符串函数
Hive操作之Hive 内置操作符与函数:集合统计函数
Hive操作之复合类型操作:Map类型构建
Hive操作之复合类型操作:Struct 类型构建
Hive操作之复合类型操作: Array 类型构建
Hive操作之用户自定义函数 UDF
Hive操作之Hive 查询优化:join优化
Hive操作之Hive 查询优化:group by 优化
Hive操作之Hive 查询优化:合并小文件
Hive操作之Hive 查询优化:Hive实现(not) in
Hive操作之Hive 查询优化:排序优化
Hive操作之Hive 查询优化:使用分区
Hive操作之Hive 查询优化:Distinct 使用
Hive操作之Hive 查询优化:Hql使用自定义的mapred脚本
Hive操作之Hive 查询优化:UDTF
Hive操作之Hive 查询优化: 聚合函数count和sum
Hive操作之Hive的权限控制
Hive操作之角色的创建和删除
Hive操作之角色的授权和撤销
Hive操作之Hive支持的权限控制
Hive操作之超级管理权限
Hive操作之Hive与JDBC示例
Hive操作之Hive案例分析
Hive文件存储格式包括以下几类:
1、TEXTFILE
2、SEQUENCEFILE
3、RCFILE
4、ORCFILE(0.11以后出现)
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。
SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从TextFile表中用insert导入SequenceFile,RCFile,ORCFile表中。
当用户的数据文件格式不能被当前Hive所识别的时候,可以自定义文件格式。用户可以通过实现InputFormat和OutputFormat来自定义输入、输出格式。
《其实,这些,都可以看Hadoop应用开发技术详解 刘刚》
更多用法,一定要去看官网啊!!!
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
一、TEXTFILE 格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,Hive不会对数据进行切分, 从而无法对数据进行并行操作。
示例:

create table if not exists textfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as textfile;
插入数据操作:
Hive> set Hive.exec.compress.output=true;
Hive> set mapred.output.compress=true;
Hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
Hive> set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
Hive> insert overwrite table textfile_table select * from textfile_table;
二、SEQUENCEFILE 格式
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。 SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
示例:
create table if not exists seqfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as sequencefile;
插入数据操作:
Hive> set Hive.exec.compress.output=true;
Hive> set mapred.output.compress=true;
Hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
Hive> set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
Hive> SET mapred.output.compression.type=BLOCK;
Hive> insert overwrite table seqfile_table select * from textfile_table;
三、RCFILE 文件格式
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
示例:
create table if not exists rcfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as rcfile;
插入数据操作:
Hive> set Hive.exec.compress.output=true;
Hive> set mapred.output.compress=true;
Hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
Hive> set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
Hive> insert overwrite table rcfile_table select * from textfile_table;
四、ORCFILE()
省略
五、再看TEXTFILE、SEQUENCEFILE、RCFILE三种文件的存储情况:
[hadoop@hadoop1 ~]$ hadoop dfs -dus /user/Hive/warehouse/*
hdfs://hadoop@hadoop1:19000/user/Hive/warehouse/hbase_table_1 0
hdfs://hadoop@hadoop1:19000/user/Hive/warehouse/hbase_table_2 0
hdfs://hadoop@hadoop1:19000/user/Hive/warehouse/orcfile_table 0
hdfs://hadoop@hadoop1:19000/user/Hive/warehouse/rcfile_table 102638073
hdfs://hadoop@hadoop1:9000/user/Hive/warehouse/seqfile_table 112497695
hdfs://hadoop@hadoop1:19000/user/Hive/warehouse/testfile_table 536799616
hdfs://hadoop@hadoop1:19000/user/Hive/warehouse/textfile_table 107308067
[hadoop@hadoop1 ~]$ hadoop dfs -ls /user/Hive/warehouse/*/
-rw-r--r-- 2 hadoop supergroup 51328177 2014-03-20 00:42 /user/Hive/warehouse/rcfile_table/000000_0
-rw-r--r-- 2 hadoop supergroup 51309896 2014-03-20 00:43 /user/Hive/warehouse/rcfile_table/000001_0
-rw-r--r-- 2 hadoop supergroup 56263711 2014-03-20 01:20 /user/Hive/warehouse/seqfile_table/000000_0
-rw-r--r-- 2 hadoop supergroup 56233984 2014-03-20 01:21 /user/Hive/warehouse/seqfile_table/000001_0
-rw-r--r-- 2 hadoop supergroup 536799616 2014-03-19 23:15 /user/Hive/warehouse/testfile_table/weibo.txt
-rw-r--r-- 2 hadoop supergroup 53659758 2014-03-19 23:24 /user/Hive/warehouse/textfile_table/000000_0.gz
-rw-r--r-- 2 hadoop supergroup 53648309 2014-03-19 23:26 /user/Hive/warehouse/textfile_table/000001_1.gz
总结: 相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
Hive 操作
1、表操作
Hive 和 Mysql 的表操作语句类似,如果熟悉 Mysql,学习Hive 的表操作就非常容易了,下面对 Hive 的表操作进行深入讲解。
1.1、创建表
Hive 的数据表分为两种,内部表和外部表。
内部表:Hive 创建并通过 LOAD DATA INPATH 进数据库的表,这种表可以理解为数据和表结构都保存在一起的数据表。当通过 DROP TABLE table_name 删除元数据中表结构的同时,表中的数据也同样会从 HDFS 中被删除。
外部表:在表结构创建以前,数据已经保存在 HDFS 中,通过创建表结构,将数据格式化到表的结果里。当进行 DROP TABLE table_name 操作的时候,Hive 仅仅删除元数据的表结构,而不删除 HDFS 上的文件,所以,相比内部表,外部表可以更放心大胆地使用。
下面详细介绍对表操作的命令及使用方法:
1) 创建内部表使用 CREATE TABLE 命令。与Mysql 创建表的命令一样,COMMENT 是对字段的注释。例如
Hive> CREATE TABLE IF NOT EXISTS table1(id INT COMMENT 'comment1',name STRING COMMENT 'comment2',no INT COMMENT 'comment3')
2) 创建外部表使用 EXTERNAL 关键字。IF NOT EXISTS 表示如果 table2 表不存在就创建,存在就不创建。例如
Hive> CREATE EXTERNAL TABLE IF NOT EXISTS table2(id INT COMMENT 'comment1',name STRING COMMENT 'comment2',no INT COMMENT 'comment3');
3) 删除表。数据表在删除的时候,内部表会连数据一起删除,而外部表只删除表结构,数据还是保留的。删除表的命令如下。
Hive> DROP TABLE table1;
Hive> DROP TABLE table1 cascade; //当table里有数据的时候上面的命令行是无法删除table的。加上cascade强制删除
4) 改表结构。例如对 table2 表添加两个字段 data_time 和 password,操作命令如下。
Hive> ALTER TABLE table2 ADD COLUMNS(data_time STRING COMMENT 'comment1',password STRING COMMENT 'comment2');
COMMENT是注释作用
5) 修改表名。例如把 table2 表重命名为 table3 ,操作命令如下。
Hive> ALTER TABLE table2 RENAME TO table3;
这个命令可以让用户为表更名,数据所在的位置和分区名并不改变。换而言之,旧的表名并未“释放” ,对旧表的更改会改变新表的数据。
6) 创建与已知表相同结构的表。例如创建一个与 table2 表结构相同的表,表名为
copy_table2,这里要用到 LIKE 关键字,操作命令如下。
Hive> CREATE TABLE copy_table2 LIKE table2;
其实啊,如果是对旧表的复制,将旧表的结构和数据一起复制,来得到新表,则
CREATE TABLE djt_user_copy
as
SELECT * FROM djt_user
其实啊,如果是对旧表的复制,只将旧表的结构复制,来得到新表,则
CREATE TABLE djt_user_copy as SELECT * FROM djt_user WHERE 1=2;
djt_user是旧表,djt_user_copy是新表。跟like的用法相同
1.2、表查询
Hive 的查询语句与标准 SQL 语句类似,具体的语法如下。
SELECT [ALL | DISTINCT] select_expr,select_expr,...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[
CLUSTER BY col_list|[DISTRIBUTE BY col_list]
[SORT BY col_list]
]
[LIMIT number]
一个 SELECT 语句可以是一个 union 查询或一个子查询的一部分;table_reference 是查询的输入,可以是一个普通表、视图、join或子查询。
首先创建一个 TextFile 格式的表 table1,并指定数据分隔符。
Hive> create table table1(id INT,name STRING,no INT) row format delimited fields terminated by '\t' STORED AS TEXTFILE;
先将 /home/hadoop/zhouls/data.txt 插入表 table1 中。
Hive> LOAD DATA LOCAL INPATH '/home/hadoop/zhouls/data.txt' INTO TABLE table1;
1) 查询 table1 表的所有内容,查询语句如下:
Hive> select * from table1;
OK
1 liugang 1000
2 lisi 1001
3 wangwu 1002
Time taken: 0.075 seconds, Fetched: 3 row(s)
SELECT * 查询没有开启 MapReduce 任务,这是 Hive 查询语句中唯一没有把 Hive 查询语句解释为 MapReduce 任务执行。
2) 查询 table1 表的 name 属性,查询语句如下
Hive> SELECT name FROM table1;
OK
liugang
lisi
wangwu
Time taken: 0.095 seconds, Fetched: 3 row(s)
"SELECT name FROM table1;" 被解释成了一个 MapReduce 任务执行。
1.3、 数据加载
首先创建一个表 table2,table4,必须声明文件格式STORED AS TEXTFILE,否则数据无法加载。
Hive> create table table2(uid STRING,gender STRING,ip STRING) row format delimited fields terminated by '\t' STORED AS TEXTFILE;
Hive> create table table4(uid STRING,gender STRING,ip STRING) row format delimited fields terminated by '\t' STORED AS TEXTFILE;
(1) 加载本地数据
加载本地数据使用 LOCAL 关键字,操作如下。
Hive> LOAD DATA LOCAL INPATH '/home/hadoop/djt/user.txt' INTO TABLE table2;
1.4、 插入表
(1) 单表插入
创建一个表 insert_table,表结构和 table2 的结构相同,把 table2 表中的数据插入到新建的表 insert_table 中,代码如下。
Hive> create table insert_table like table2;----复制表结构(不包括旧表的数据)
Hive> insert overwrite table insert_table select * from table2;
overwrite 关键字表示如果 insert_table 表中有数据就删除。(覆盖的意思)
(2) 多表插入
在table2中,查询字段 uid 并插入 test_insert1 表,查询字段 uid 并插入 test_insert2 表。操作命令如下。
Hive> create table test_insert1(num INT);
Hive> create table test_insert2(num INT);
from table2 insert overwrite table test_insert1 select uid insert overwrite table test_insert2 select uid;
insert 操作的时候,from 子句既可以放在 select 子句后面,也可以放在 insert 子句前面。
Hive 不支持用 insert 语句一条一条地进行插入操作,也不支持 update 操作。数据是以 load 的方式加载到建立好的表中。数据一旦导入就不可以修改。
通过查询将数据保存到 HDFS ,directory 为 HDFS 文件系统的目录。操作命令如下。
Hive> insert overwrite directory '/advance/Hive' select * from table2;
导入数据到本地目录,操作命令如下。
Hive> insert overwrite local directory '/home/hadoop/djt/test2' select * from table2;
产生的文件会覆盖指定目录中的其它文件,即将目录中已经存在的文件进行删除。
同一个查询结果可以同时插入到多个表或者多个目录中,命令如下。
from table2 insert overwrite local directory '/home/hadoop/djt/test2' select * insert overwrite directory '/advance/Hive' select ip;
select * 表示把 table2 表中的所有数据复制到本地 /home/hadoop/djt/test2 目录下面,select ip 表示把 table2 的 ip 字段内容复制到 HDFS 文件系统的 /advance/Hive 目录下。
下面我们逐一学习 Hive 的语法结构,很easy的哦。
2、Hive 的语法结构
(1) where 查询
where 查询是一个布尔表达式。例如,下面的查询语句只返回销售记录大于10,且归属地属于北京的销售代表。Hive 不支持在 where 子句中的 in,exist或子查询。
Hive> select * from sales where amount >10 and region = "beijing";
(2) all 和 distinct 选项
使用 all 和 distinct 选项区分对重复记录的处理。默认是 all,表示查询所有记录,distinct 表示去掉重复的记录。
Hive> select * from sales where amount >10 and region = "beijing";
1) 查询 table1 表中的所有 age、grade 的内容,等同于如下操作。
Hive> select all age,grade from table1;
2) 查询去掉 age 和 grade 重复的记录,操作如下。
Hive> select distinct age ,grade from table1;
3) 查询去掉 age 重复的记录,操作如下。
Hive> select distinct age from table1;
(3) 基于 Partition 的查询
一般 SELECT 查询会扫描整个表(除非是为了抽样查询)。但是如果一个表使用 PARTITIONED BY 子句建表,查询就可以利用分区剪枝(input pruning)的特性,只扫描一个表中它关心的那一部分。Hive 当前的实现是,只有分区断言出现在离 FROM 子句最近的那个 WHERE 子句中,才会启用分区剪枝。例如,page_views 表使用 date 列分区,以下语句只会读取分区为 ‘2013-08-01’ 的数据。
select page_views.* from page_views where page_views.date between '2013-08-01' and '2013-08-31';
(4) 基于 HAVING 的查询
Hive 不支持 HAVING 子句,可以将 HAVING 子句转化为一个子查询。例如以下这条语句 Hive 不支持。
select col1 from table1 group by coll having sum(col2) > 10;
可以用以下查询来表达。
select col1 from (select col1,sum(col2) as col2sum from table1 group by col1) table2 where table2.col2sum > 10;
(5) LIMIT 限制查询
limit 可以限制查询的记录数,查询的结果是随机选择的。下面的语句用来从 table1 表中随机查询 5 条记录。
select * from table1 limit 5;
(6) GROUP BY 分组查询
group by 分组查询在数据统计时比较常用,接下来讲解 group by 的使用。
1) 创建一个表 group_test,表的内容如下。
Hive> create table group_test(uid STRING,gender STRING,ip STRING) row format delimited fields terminated by '\t' STORED AS TEXTFILE;
向 group_test 表中导入数据。
Hive> LOAD DATA LOCAL INPATH '/home/hadoop/djt/user.txt' INTO TABLE group_test;
2) 计算表的行数命令如下。
Hive> select count(*) from group_test;
3) 根据性别计算去重用户数。
首先创建一个表 group_gender_sum
Hive> create table group_gender_sum(gender STRING,sum INT);
将表 group_test 去重后的数据导入表 group_gender_sum。
Hive> insert overwrite table group_gender_sum select group_test.gender,count(distinct group_test.uid) from group_test group by group_test.gender;
同时可以做多个聚合操作,但是不能有两个聚合操作有不同的 distinct 列。下面正确合法的聚合操作语句。
首先创建一个表 group_gender_agg
Hive> create table group_gender_agg(gender STRING,sum1 INT,sum2 INT,sum3 INT);
将表 group_test 聚合后的数据插入表 group_gender_agg。
Hive> insert overwrite table group_gender_agg select group_test.gender,count(distinct group_test.uid),count(*),sum(distinct group_test.uid) from group_test group by group_test.gender;
但是,不允许在同一个查询内有多个 distinct 表达式。下面的查询是不允许的。
Hive> insert overwrite table group_gender_agg select group_test.gender,count(distinct group_test.uid),count(distinct group_test.ip) from group_test group by group_test.gender;
这条查询语句是不合法的,因为 distinct group_test.uid 和 distinct group_test.ip 操作了uid 和 ip 两个不同的列。
(7) ORDER BY 排序查询
ORDER BY 会对输入做全局排序,因此只有一个 Reduce(多个 Reduce 无法保证全局有序)会导致当输入规模较大时,需要较长的计算时间。使用 ORDER BY 查询的时候,为了优化查询的速度,使用 Hive.mapred.mode 属性。
Hive.mapred.mode = nonstrict;(default value/默认值)
Hive.mapred.mode=strict;
与数据库中 ORDER BY 的区别在于,在 Hive.mapred.mode=strict 模式下必须指定limit ,否则执行会报错。
Hive> set Hive.mapred.mode=strict;
Hive> select * from group_test order by uid limit 5;
Total jobs = 1
..............
Total MapReduce CPU Time Spent: 4 seconds 340 msec
OK
01 male 192.168.1.2
01 male 192.168.1.32
01 male 192.168.1.26
01 male 192.168.1.22
02 female 192.168.1.3
Time taken: 58.04 seconds, Fetched: 5 row(s)
(8) SORT BY 查询
sort by 不受 Hive.mapred.mode 的值是否为 strict 和 nostrict 的影响。sort by 的数据只能保证在同一个 Reduce 中的数据可以按指定字段排序。
使用 sort by 可以指定执行的 Reduce 个数(set mapred.reduce.tasks=< number>)这样可以输出更多的数据。对输出的数据再执行归并排序,即可以得到全部结果。
Hive> set Hive.mapred.mode=strict;
Hive> select * from group_test sort by uid ;
Total MapReduce CPU Time Spent: 4 seconds 450 msec
OK
01 male 192.168.1.2
01 male 192.168.1.32
01 male 192.168.1.26
01 male 192.168.1.22
02 female 192.168.1.3
03 male 192.168.1.23
03 male 192.168.1.5
04 male 192.168.1.9
05 male 192.168.1.8
05 male 192.168.1.29
06 female 192.168.1.201
06 female 192.168.1.52
06 female 192.168.1.7
07 female 192.168.1.11
08 female 192.168.1.21
08 female 192.168.1.62
08 female 192.168.1.88
08 female 192.168.1.42
Time taken: 77.875 seconds, Fetched: 18 row(s)
(9) DISTRIBUTE BY 排序查询
按照指定的字段对数据划分到不同的输出 Reduce 文件中,操作如下。
Hive> insert overwrite local directory '/home/hadoop/djt/test' select * from group_test distribute by length(gender);
此方法根据 gender 的长度划分到不同的 Reduce 中,最终输出到不同的文件中。length 是内建函数,也可以指定其它的函数或者使用自定义函数。
Hive> insert overwrite local directory '/home/hadoop/djt/test' select * from group_test order by gender distribute by length(gender);
order by gender 与 distribute by length(gender) 不能共用。
(10) CLUSTER BY 查询
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。
3、视图操作
1) 创建一个测试表。
Hive> create table test(id int,name string);
OK
Time taken: 0.385 seconds
Hive> desc test;
OK
id int
name string
Time taken: 0.261 seconds, Fetched: 2 row(s)
2) 基于表 test 创建一个 test_view 视图。
Hive> create view test_view(id,name_length) as select id,length(name) from test;
3) 查看 test_view 视图属性。
Hive> desc test_view;
4) 查看视图结果。
视图是指计算机数据库中的视图,是一个虚拟表,即不是实实在在的,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
一般情况,是多表关联查询的时候,才用视图
索引是为了提高查询速度的,视图是在查询sql的基础上的。
4、索引操作
1) Hive 创建索引。
2) 更新数据。
Hive> alter index user_index on user rebuild;
3) 删除索引
Hive> drop index user_index on user;
4) 查看索引
Hive> show index on user;
5) 创建表和索引案例
Hive> create table index_test(id INT,name STRING) PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FILEDS TERMINATED BY ',';
创建一个索引测试表 index_test,dt作为分区属性,“ROW FORMAT DELIMITED FILEDS TERMINATED BY ','” 表示用逗号分割字符串,默认为‘\001’。
6) 创建一个临时索引表 index_tmp。
Hive> create table index_tmp(id INT,name STRING,dt STRING) ROW FORMAT DELIMITED FILEDS TERMINATED BY ',';
7) 加载本地数据到 index_tmp 表中。
Hive> load data local inpath '/home/hadoop/djt/test.txt' into table index_tmp;
设置 Hive 的索引属性来优化索引查询,命令如下。
Hive> set Hive.exec.dynamic.partition.mode=nonstrict;----设置所有列为 dynamic partition
Hive> set Hive.exec.dynamic.partition=true;----使用动态分区
8) 查询index_tmp 表中的数据,插入 table_test 表中。
Hive> insert overwrite table index_test partition(dt) select id,name,dt from index_tmp;
9) 使用 index_test 表,在属性 id 上创建一个索引 index1_index_test 。
Hive> create index index1_index_test on table index_test(id) as 'org.apache.hadoop.Hive.ql.index.compact.CompactIndexHandler' WITH DEFERERD REBUILD;
10) 填充索引数据。
Hive> alter index index1_index_test on index_test rebuild;
11) 查看创建的索引。
Hive> show index on index_test
12) 查看分区信息。
Hive> show partitions index_test;
13) 查看索引数据。
$ hadoop fs -ls /usr/Hive/warehouse/default_index_test_index1_index_test_
14) 删除索引。
Hive> drop index index1_index_test on index_test;
Hive> show index on index_test;
15) 索引数据也被删除。
$ hadoop fs -ls /usr/Hive/warehouse/default_index_test_index1_index_test_
no such file or directory
16) 修改配置文件信息。
<property>
<name>Hive.optimize.index.filter</name>
<value>true</value>
</property>
<property>
<name>Hive.optimize.index.groupby</name>
<value>true</value>
</property>
<property>
<name>Hive.optimize.index.filter.compact.minsize</name>
<value>5120</value>
</property>
Hive.optimize.index.filter 和 Hive.optimize.index.groupby 参数默认是 false。使
用索引的时候必须把这两个参数开启,才能起到作用。
Hive.optimize.index.filter.compact.minsize 参数为输入一个紧凑的索引将被自动采用
最小尺寸、默认5368709120(以字节为单位)。
5、分区操作
注意:注意:普通表(外部表、内部表)、分区表这三个都是对应HDFS上的目录,桶表对应是目录里的文件
Hive 的分区通过在创建表时启动 PARTITION BY 实现,用来分区的维度并不是实际数据的某一列,具体分区的标志是由插入内容时给定的。当要查询某一分区的内容时可以采用 WHERE 语句, 例如使用 “WHERE tablename.partition_key>a” 创建含分区的表。创建分区语法如下。
CREATE TABLE table_name(
...
)
PARTITION BY (dt STRING,country STRING)
5.1、 创建分区
Hive 中创建分区表没有什么复杂的分区类型(范围分区、列表分区、hash 分区,混合分区等)。分区列也不是表中的一个实际的字段,而是一个或者多个伪列。意思是说,在表的数据文件中实际并不保存分区列的信息与数据。
创建一个简单的分区表。
Hive> create table partition_test(member_id string,name string) partitioned by (stat_date string,province string) row format delimited fields terminated by ',';
这个例子中创建了 stat_date 和 province 两个字段作为分区列。
通常情况下需要预先创建好分区,然后才能使用该分区。例如:
Hive> alter table partition_test add partition (stat_date='2015-01-18',province='beijing');
这样就创建了一个分区。
这时会看到 Hive 在HDFS 存储中创建了一个相应的文件夹。
$ hadoop fs -ls /user/Hive/warehouse/partition_test/stat_date=2015-01-18
/user/Hive/warehouse/partition_test/stat_date=2015-01-18/province=beijing----显示刚刚创建的分区
每一个分区都会有一个独立的文件夹(目录),在上面例子中,stat_date 是主层次,province 是 副层次。
5.2、 插入数据
使用一个辅助的非分区表 partition_test_input 准备向 partition_test 中插入数据,实现步骤如下。
1) 查看 partition_test_input 表的结构,命令如下。
Hive> desc partition_test_input;
2) 查看 partition_test_input 的数据,命令如下。
Hive> select * from partition_test_input;
3) 向 partition_test 的分区中插入数据,命令如下。
insert overwrite table partition_test partition(stat_date='2015-01-18',province='jiangsu') select member_id,name from partition_test_input where stat_date='2015-01-18' and province='jiangsu';
向多个分区插入数据,命令如下。
Hive> from partition_test_input
insert overwrite table partition_test partition(stat_date='2015-01-18',province='jiangsu') select member_id,name from partition_test_input where stat_date='2015-01-18' and province='jiangsu'
insert overwrite table partition_test partition(stat_date='2015-01-28',province='sichuan') select member_id,name from partition_test_input where stat_date='2015-01-28' and province='sichuan'
insert overwrite table partition_test partition(stat_date='2015-01-28',province='beijing') select member_id,name from partition_test_input where stat_date='2015-01-28' and province='beijing';
5.3、 动态分区
按照上面的方法向分区表中插入数据,如果数据源很大,针对一个分区就要写一个 insert ,非常麻烦。使用动态分区可以很好地解决上述问题。动态分区可以根据查询得到的数据自动匹配到相应的分区中去。
动态分区可以通过下面的设置来打开:
set Hive.exec.dynamic.partition=true;
set Hive.exec.dynamic.partition.mode=nonstrict;
动态分区的使用方法很简单,假设向 stat_date='2015-01-18' 这个分区下插入数据,至于 province 插到哪个子分区下让数据库自己来判断。stat_date 叫做静态分区列,province 叫做动态分区列。
Hive> insert overwrite table partition_test partition(stat_date='2015-01-18',province)
select member_id,name province from partition_test_input where stat_date='2015-01-18';
注意,动态分区不允许主分区采用动态列而副分区采用静态列,这样将导致所有的主分区都要创建副分区静态列所定义的分区。
Hive.exec.max.dynamic.partitions.pernode:每一个 MapReduce Job 允许创建的分区的最大数量,如果超过这个数量就会报错(默认值100)。
Hive.exec.max.dynamic.partitions:一个 dml 语句允许创建的所有分区的最大数量(默认值100)。
Hive.exec.max.created.files:所有 MapReduce Job 允许创建的文件的最大数量(默认值10000)。
尽量让分区列的值相同的数据在同一个 MapReduce 中,这样每一个 MapReduce 可以尽量少地产生新的文件夹,可以通过 DISTRIBUTE BY 将分区列值相同的数据放到一起,命令如下。
Hive> insert overwrite table partition_test partition(stat_date,province)
select memeber_id,name,stat_date,province from partition_test_input distribute by stat_date,province;
6、桶操作
Hive 中 table 可以拆分成 Partition table 和 桶(BUCKET),桶操作是通过 Partition 的 CLUSTERED BY 实现的,BUCKET 中的数据可以通过 SORT BY 排序。
BUCKET 主要作用如下。
1)数据 sampling;
2)提升某些查询操作效率,例如 Map-Side Join。
需要特别主要的是,CLUSTERED BY 和 SORT BY 不会影响数据的导入,这意味着,用户必须自己负责数据的导入,包括数据额分桶和排序。 'set Hive.enforce.bucketing=true' 可以自动控制上一轮 Reduce 的数量从而适配 BUCKET 的个数,当然,用户也可以自主设置 mapred.reduce.tasks 去适配 BUCKET 个数,推荐使用:
Hive> set Hive.enforce.bucketing=true;
操作示例如下。
1) 创建临时表 student_tmp,并导入数据。
Hive> desc student_tmp; Hive> select * from student_tmp;
2) 创建 student 表。
Hive> create table student(id int,age int,name string)
partitioned by (stat_date string)
clustered by (id) sorted by(age) into 2 bucket
row format delimited fields terminated by ',';
3) 设置环境变量。
Hive> set Hive.enforce.bucketing=true;
4) 插入数据。
Hive> from student_tmp
insert overwrite table student partition(stat_date='2015-01-19')
select id,age,name where stat_date='2015-01-18' sort by age;
5) 查看文件目录。
$ hadoop fs -ls /usr/Hive/warehouse/student/stat_date=2015-01-19/
6) 查看 sampling 数据。
Hive> select * from student tablesample(bucket 1 out of 2 on id);
tablesample 是抽样语句,语法如下。
tablesample(bucket x out of y)
y 必须是 table 中 BUCKET 总数的倍数或者因子。
7、Hive 复合类型
Hive提供了复合数据类型:
1)Structs: structs内部的数据可以通过DOT(.)来存取。例如,表中一列c的类型为STRUCT{a INT; b INT},我们可以通过c.a来访问域a。
2)Map(K-V对):访问指定域可以通过["指定域名称"]进行。例如,一个Map M包含了一个group-》gid的kv对,gid的值可以通过M['group']来获取。
3)Array:array中的数据为相同类型。例如,假如array A中元素['a','b','c'],则A[1]的值为'b'
7.1、Struct使用
1) 建表
Hive> create table student_test(id INT, info struct< name:STRING, age:INT>)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY ':';
'FIELDS TERMINATED BY' :字段与字段之间的分隔符。'COLLECTION ITEMS TERMINATED BY' :一个字段各个item的分隔符。
2) 导入数据
$ cat test5.txt
1,zhou:30
2,yan:30
3,chen:20
4,li:80 Hive> LOAD DATA LOCAL INPATH '/home/hadoop/djt/test5.txt' INTO TABLE student_test;
3)查询数据
Hive> select info.age from student_test;
7.2、Array使用
1) 建表
Hive> create table class_test(name string, student_id_list array< INT>)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY ':';
2) 导入数据
$ cat test6.txt
034,1:2:3:4
035,5:6
036,7:8:9:10
Hive> LOAD DATA LOCAL INPATH '/home/work/data/test6.txt' INTO TABLE class_test ;
3) 查询
Hive> select student_id_list[3] from class_test;
7.3、Map使用
1) 建表
Hive> create table employee(id string, perf map< string, int>)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> COLLECTION ITEMS TERMINATED BY ','
> MAP KEYS TERMINATED BY ':';
‘MAP KEYS TERMINATED BY’ :key value分隔符
2)导入数据
$ cat test7.txt
1 job:80,team:60,person:70
2 job:60,team:80
3 job:90,team:70,person:100
Hive> LOAD DATA LOCAL INPATH '/home/work/data/test7.txt' INTO TABLE employee;
3)查询
Hive> select perf['person'] from employee;
8、Hive 的 JOIN 用法
Hive只支持等连接,外连接,左半连接。Hive不支持非相等的join条件(通过其他方式实现,如left outer join),因为它很难在map/reduce job实现这样的条件。而且,Hive可以join两个以上的表。
8.1、等连接
只有等连接才允许
Hive> SELECT a.* FROM a JOIN b ON (a.id = b.id)
Hive> SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
8.2、多表连接
同个查询,可以join两个以上的表
Hive> SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
8.3、join的缓存和任务转换
Hive转换多表join时,如果每个表在join字句中,使用的都是同一个列,只会转换为一个单独的map/reduce。
Hive> SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
被转换为两个map/reduce任务,因为b的key1列在第一个join条件使用,而b表的key2列在第二个join条件使用。第一个map/reduce任务join a和b。第二个任务是第一个任务的结果join c。
Hive> SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
在join的每个map/reduce阶段,序列中的最后一个表,当其他被缓存时,它会流到reducers。所以,reducers需要缓存join关键字的特定值组成的行,通过组织最大的表出现在序列的最后,有助于减少reducers的内存。
Hive> SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
三个表,在同一个独立的map/reduce任务做join。a和b的key对应的特定值组成的行,会缓存在reducers的内存。然后reducers接受c的每一行,和缓存的每一行做join计算。
Hive> SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
这里有两个map/reduce任务在join计算被调用。第一个是a和b做join,然后reducers缓存a的值,另一边,从流接收b的值。第二个阶段,reducers缓存第一个join的结果,另一边从流接收c的值。
在join的每个map/reduce阶段,通过关键字,可以指定哪个表从流接收。
Hive> SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON
三个表的连接,会转换为一个map/reduce任务,reducer会把b和c的key的特定值缓存在内存里,然后从流接收a的每一行,和缓存的行做join。
8.4、join的结果
LEFT,RIGHT,FULL OUTER连接存在是为了提供ON语句在没有匹配时的更多控制。例如,这个查询:
Hive> SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
将会返回a的每一行。如果b.key等于a.key,输出将是a.val,b.val,如果a没有和b.key匹配,输出的行将是 a.val,NULL。如果b的行没有和a.key匹配上,将被抛弃。语法"FROM a LEFT OUTER JOIN b"必须写在一行,为了理解它如何工作——这个查询,a是b的左边,a的所有行会被保持;RIGHT OUTER JOIN将保持b的所有行, FULL OUTER JOIN将会保存a和b的所有行。OUTER JOIN语义应该符合标准的SQL规范。
8.5、join的过滤
Joins发生在where字句前,所以,如果要限制join的输出,需要写在where字句,否则写在JOIN字句。现在讨论的一个混乱的大点,就是分区表
Hive> SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key) WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
将会连接a和b,产生a.val和b.val的列表。WHERE字句,也可以引用join的输出列,然后过滤他们。 但是,无论何时JOIN的行找到a的key,但是找不到b的key时,b的所有列会置成NULL,包括ds列。这就是说,将过滤join输出的所有行,包括没有合法的b.key的行。然后你会在LEFT OUTER的要求扑空。 也就是说,如果你在WHERE字句引用b的任何列,LEFT OUTER的部分join结果是不相关的。所以,当外连接时,使用这个语句
Hive> SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-0
join的输出会预先过滤,然后你不用对有a.key而没有b.key的行做过滤。RIGHT和FULL join也是一样的逻辑。
8.6、join的顺序
join是不可替换的,连接是从左到右,不管是LEFT或RIGHT join。
Hive> SELECT a.val1, a.val2, b.val, c.val FROM a JOIN b ON (a.key = b.key) LEFT OUTER JOIN c ON (a.key = c.key)
首先,连接a和b,扔掉a和b中没有匹配的key的行。结果表再连接c。这提供了直观的结果,如果有一个键都存在于A和C,但不是B:完整行(包括 a.val1,a.val2,a.key)会在"a jOIN b"步骤,被丢弃,因为它不在b中。结果没有a.key,所以当它和c做LEFT OUTER JOIN,c.val也无法做到,因为没有c.key匹配a.key(因为a的行都被移除了)。类似的,RIGHT OUTER JOIN(替换为LEFT),我们最终会更怪的效果,NULL, NULL, NULL, c.val。因为尽管指定了join key是a.key=c.key,我们已经在第一个JOIN丢弃了不匹配的a的所有行。
为了达到更直观的效果,相反,我们应该从Hive> FROM c LEFT OUTER JOIN a ON (c.key = a.key) LEFT OUTER JOIN b ON (c.key = b.key).
LEFT SEMI JOIN实现了相关的IN / EXISTS的子查询语义的有效途径。由于Hive目前不支持IN / EXISTS的子查询,所以你可以用 LEFT SEMI JOIN 重写你的子查询语句。LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
Hive> SELECT a.key, a.value FROM a WHERE a.key in (SELECT b.key FROM B);
可以重写为
Hive> SELECT a.key, a.val FROM a LEFT SEMI JOIN b on (a.key = b.key)
8.7、map 端 join
但如果所有被连接的表是小表,join可以被转换为只有一个map任务。查询是
Hive> SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a join b on a.key = b.key
不需要reducer。对于每一个mapper,A和B已经被完全读出。限制是a FULL/RIGHT OUTER JOIN b不能使用。
如果表在join的列已经分桶了,其中一张表的桶的数量,是另一个表的桶的数量的整倍,那么两者可以做桶的连接。如果A有4个桶,表B有4个桶,下面的连接:
Hive> SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a join b on a.key = b.key
只能在mapper工作。为了为A的每个mapper完整抽取B。对于上面的查询,mapper处理A的桶1,只会抽取B的桶1,这不是默认行为,要使用以下参数:
Hive> set Hive.optimize.bucketmapjoin = true;
如果表在join的列经过排序,分桶,而且他们有相同数量的桶,可以使用排序-合并 join。每个mapper,相关的桶会做连接。如果A和B有4个桶
Hive> SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM A a join B b on a.key = b.key
只能在mapper使用。使用A的桶的mapper,也会遍历B相关的桶。这个不是默认行为,需要配置以下参数:
Hive> set Hive.input.format=org.apache.hadoop.Hive.ql.io.BucketizedHiveInputFormat;
Hive> set Hive.optimize.bucketmapjoin = true;
Hive> set Hive.optimize.bucketmapjoin.sortedmerge = true;
9、Hive 内置操作符与函数
9.1 字符串函数
1) 字符串长度函数:length
语法: length(string A)
返回值: int
说明:返回字符串A的长度
举例:
Hive> select length(‘abcedfg’) from dual;
7
2) 字符串反转函数:reverse
语法: reverse(string A)
返回值: string
说明:返回字符串A的反转结果
举例:
Hive> select reverse(‘abcedfg’) from dual;
gfdecba
3) 字符串连接函数:concat
语法: concat(string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,支持任意个输入字符串
举例:
Hive> select concat(‘abc’,'def’,'gh’) from dual;
abcdefgh
4) 带分隔符字符串连接函数:concat_ws
语法: concat_ws(string SEP, string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
举例:
Hive> select concat_ws(‘,’,'abc’,'def’,'gh’) from dual;
abc,def,gh
5) 字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
举例:
Hive> select substr(‘abcde’,3) from dual;
cde
Hive> select substring(‘abcde’,3) from dual;
cde
Hive> select substr(‘abcde’,-1) from dual; (和oracle相同)
e
6) 字符串截取函数:substr,substring
语法: substr(string A, int start, int len),substring(string A, int start, int len)
返回值: string
说明:返回字符串A从start位置开始,长度为len的字符串
举例:
Hive> select substr(‘abcde’,3,2) from dual;
cd
Hive> select substring(‘abcde’,3,2) from dual;
cd
Hive>select substring(‘abcde’,-2,2) from dual;
de
7) 字符串转大写函数:upper,ucase
语法: upper(string A) ucase(string A)
返回值: string
说明:返回字符串A的大写格式
举例:
Hive> select upper(‘abSEd’) from dual;
ABSED
Hive> select ucase(‘abSEd’) from dual;
ABSED
8) 字符串转小写函数:lower,lcase
语法: lower(string A) lcase(string A)
返回值: string
说明:返回字符串A的小写格式
举例:
Hive> select lower(‘abSEd’) from dual;
absed
Hive> select lcase(‘abSEd’) from dual;
absed
9) 去空格函数:trim
语法: trim(string A)
返回值: string
说明:去除字符串两边的空格
举例:
Hive> select trim(‘ abc ‘) from dual;
abc
10) 左边去空格函数:ltrim
语法: ltrim(string A)
返回值: string
说明:去除字符串左边的空格
举例:
Hive> select ltrim(‘ abc ‘) from dual;
abc
11) 右边去空格函数:rtrim
语法: rtrim(string A)
返回值: string
说明:去除字符串右边的空格
举例:
Hive> select rtrim(‘ abc ‘) from dual;
abc
9.2 集合统计函数
1) 个数统计函数 count。
语法:count(*),count(expr),count(distinct expr)
返回值 int。
count(*)统计检索出行的个数,包括 NULL 值的行;
count(expr)返回指定字段的非空值的个数;
count(distinct expr)返回指定字段的不同的非空值的个数。
举例:
Hive> select count(*) from user;
Hive> select count(distinct age);
2) 总和统计函数 sum。
语法:sum(col),sum(distinct col)
返回值 double。
sum(col) 统计结果集中 col 的相加的结果;
sum(distinct col) 统计结果中 col 不同值相加的结果。
举例:
Hive> select sum(age) from user;
Hive> select sum(distinct age) from user;
3) 平均值统计函数avg。
语法:avg(col),avg(distinct col)
返回值 double。
avg(col) 统计结果集中的平均值;
avg(distinct col) 统计结果中 col 不同值相加的平均值。
举例:
Hive> select avg(mark) from user;
Hive> select avg(distinct mark) from user
4) 最小值统计函数 min。统计结果集中 col 字段的最小值
语法:min(col)
返回值double。
举例:
Hive>select min(mark) from user;
5) 最大值统计函数 max。统计结果集中 col 字段的最大值。
语法:max(col)
返回值 double。
举例:
Hive> select max(mark) from user;
10、复合类型操作
1) Map 类型构建。根据输入的 Key-Value 对构建 Map 类型。
语法:map(key1, value1, key2, value2,...)
举例:
Hive> create table map_test as select map('100','jay','200','liu') from student;
Hive> describe map_test;
Hive> select map_test from student;
2) Struct 类型构建。根据输入的参数构建结构体 Struct 类型。
语法:struct(val1, val2, val3, ...)
举例:
Hive> create table struct_test as select struct('jay','liu','gang') from student;
Hive> describe struct_test;
Hive> select struct_test from student;
3) Array 类型构建。根据输入的参数构建数组 Array 类型
语法:array(val1,val2, ...)
举例:
Hive> create table array_test as select array('jay','liu','gang') from student;
Hive> describe array_test;
Hive> select array_test from array_test;
对于,复合类型操作。进一步学习,请移步
3 hql语法及自定义函数(含array、map讲解) + hive的java api
11、用户自定义函数 UDF
UDF(User Defined Function,用户自定义函数) 对数据进行处理。UDF 函数可以直接应用于 select 语句,对查询结构做格式化处理后,再输出内容。
Hive可以允许用户编写自己定义的函数UDF,来在查询中使用。Hive中有3种UDF:
1) UDF:操作单个数据行,产生单个数据行。
2) UDAF:操作多个数据行,产生一个数据行。
3) UDTF:操作一个数据行,产生多个数据行一个表作为输出。
用户构建的UDF使用过程如下:
第一步:继承UDF或者UDAF或者UDTF,实现特定的方法。
第二步:将写好的类打包为jar。如Hivefirst.jar。
第三步:进入到Hive外壳环境中,利用add jar /home/hadoop/Hivefirst.jar 注册该jar文件。
第四步:为该类起一个别名,create temporary function mylength as 'com.whut.StringLength';这里注意UDF只是为这个Hive会话临时定义的。
第五步:在select中使用mylength()。
自定义UDF
package whut;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.Hive.ql.exec.UDF;
import org.apache.hadoop.io.Text; //UDF是作用于单个数据行,产生一个数据行
//用户必须要继承UDF,且必须至少实现一个evalute方法,该方法并不在UDF中
//但是Hive会检查用户的UDF是否拥有一个evalute方法
public class Strip extends UDF{
private Text result=new Text();
//自定义方法
public Text evaluate(Text str)
{
if(str==null)
return null;
result.set(StringUtils.strip(str.toString()));
return result;
} public Text evaluate(Text str,String stripChars)
{
if(str==null)
return null;
result.set(StringUtils.strip(str.toString(),stripChars));
return result;
}
}
1、一个用户UDF必须继承org.apache.hadoop.Hive.ql.exec.UDF;
2、一个UDF必须要包含有evaluate()方法,但是该方法并不存在于UDF中。evaluate的参数个数以及类型都是用户自己定义的。在使用的时候,Hive会调用UDF的evaluate()方法。
自定义UDAF找到最大值
package whut;
import org.apache.hadoop.Hive.ql.exec.UDAF;
import org.apache.hadoop.Hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable; //UDAF是输入多个数据行,产生一个数据行
//用户自定义的UDAF必须是继承了UDAF,且内部包含多个实现了exec的静态类
public class MaxiNumber extends UDAF{
public static class MaxiNumberIntUDAFEvaluator implements UDAFEvaluator{
//最终结果
private IntWritable result;
//负责初始化计算函数并设置它的内部状态,result是存放最终结果的
@Override
public void init() {
result=null;
} //每次对一个新值进行聚集计算都会调用iterate方法
public boolean iterate(IntWritable value)
{
if(value==null)
return false;
if(result==null)
result=new IntWritable(value.get());
else
result.set(Math.max(result.get(), value.get()));
return true;
} //Hive需要部分聚集结果的时候会调用该方法
//会返回一个封装了聚集计算当前状态的对象
public IntWritable terminatePartial()
{
return result;
}
//合并两个部分聚集值会调用这个方法
public boolean merge(IntWritable other)
{
return iterate(other);
} //Hive需要最终聚集结果时候会调用该方法
public IntWritable terminate()
{
return result;
}
} }
注意事项:
1、用户的UDAF必须继承了org.apache.hadoop.Hive.ql.exec.UDAF。
2、用户的UDAF必须包含至少一个实现了org.apache.hadoop.Hive.ql.exec的静态类,诸如常见的实现了 UDAFEvaluator。
3、一个计算函数必须实现的5个方法的具体含义如下:
init():主要是负责初始化计算函数并且重设其内部状态,一般就是重设其内部字段。一般在静态类中定义一个内部字段来存放最终的结果。
iterate():每一次对一个新值进行聚集计算时候都会调用该方法,计算函数会根据聚集计算结果更新内部状态。当输入值合法或者正确计算了,则就返回true。
terminatePartial():Hive需要部分聚集结果的时候会调用该方法,必须要返回一个封装了聚集计算当前状态的对象。
merge():Hive进行合并一个部分聚集和另一个部分聚集的时候会调用该方法。 terminate():Hive最终聚集结果的时候就会调用该方法。计算函数需要把状态作为一个值返回给用户。
4、 部分聚集结果的数据类型和最终结果的数据类型可以不同。
12、Hive 查询优化
12.1 join优化
Join查找操作的基本原则:应该将条目少的表/子查询放在 Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出错误的几率。
Join查找操作中如果存在多个join,且所有参与join的表中其参与join的key都相同,则会将所有的join合并到一个mapred程序中。
案例:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) //在一个mapre程序中执行join
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) //在两个mapred程序中执行join
Map join的关键在于join操作中的某个表的数据量很小,案例:
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a join b on a.key = b.key
Mapjoin 的限制是无法执行a FULL/RIGHT OUTER JOIN b,和map join相关的Hive参数:
Hive.join.emit.interval
Hive.mapjoin.size.key
Hive.mapjoin.cache.numrows
由于join操作是在where操作之前执行,所以当你在执行join时,where条件并不能起到减少join数据的作用;案例:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key) WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
最好修改为:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')
在join操作的每一个mapred程序中,Hive都会把出现在join语句中相对靠后的表的数据stream化,相对靠前的变的数据缓存在内存中。当然,也可以手动指定stream化的表:
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
12.2 group by 优化
Map端聚合,首先在map端进行初步聚合,最后在reduce端得出最终结果,相关参数:
Hive.map.aggr = true //是否在 Map 端进行聚合,默认为 True
Hive.groupby.mapaggr.checkinterval = 100000 //在 Map 端进行聚合操作的条目数目
数据倾斜聚合优化,设置参数Hive.groupby.skewindata = true,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
12.3 合并小文件
文件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的结果文件来消除这样的影响:
Hive.merge.mapfiles = true //是否和并 Map 输出文件,默认为 True
Hive.merge.mapredfiles = false //是否合并 Reduce 输出文件,默认为 False
Hive.merge.size.per.task = 256*1000*1000 //合并文件的大小
12.4 Hive实现(not) in
通过left outer join进行查询,(假设B表中包含另外的一个字段 key1
select a.key from a left outer join b on a.key=b.key where b.key1 is null
通过left semi join 实现 in
SELECT a.key, a.val FROM a LEFT SEMI JOIN b on (a.key = b.key)
Left semi join 的限制:join条件中右边的表只能出现在join条件中。
12.5 排序优化
Order by 实现全局排序,一个reduce实现,效率低。
Sort by 实现部分有序,单个reduce输出的结果是有序的,效率高,通常和DISTRIBUTE BY关键字一起使用(DISTRIBUTE BY关键字 可以指定map 到 reduce端的分发key)。
CLUSTER BY col1 等价于DISTRIBUTE BY col1 SORT BY col1
12.6 使用分区
Hive中的每个分区都对应hdfs上的一个目录,分区列也不是表中的一个实际的字段,而是一个或者多个伪列,在表的数据文件中实际上并不保存分区列的信息与数据。Partition关键字中排在前面的为主分区(只有一个),后面的为副分区 静态分区:静态分区在加载数据和使用时都需要在sql语句中指定。
案例:(stat_date='20120625',province='hunan')
动态分区:使用动态分区需要设置Hive.exec.dynamic.partition参数值为true,默认值为false,在默认情况下,Hive会假设主分区时静态分区,副分区使用动态分区;如果想都使用动态分区,需要设置set Hive.exec.dynamic.partition.mode=nostrick,默认为strick。
案例:(stat_date='20120625',province)
12.7 Distinct 使用
Hive支持在group by时对同一列进行多次distinct操作,却不支持在同一个语句中对多个列进行distinct操作。
12.8 Hql使用自定义的mapred脚本
注意事项:在使用自定义的mapred脚本时,关键字MAP REDUCE 是语句SELECT TRANSFORM ( ... )的语法转换,并不意味着使用MAP关键字时会强制产生一个新的map过程,使用REDUCE关键字时会产生一个red过程。
自定义的mapred脚本可以是hql语句完成更为复杂的功能,但是性能比hql语句差了一些,应该尽量避免使用,如有可能,使用UDTF函数来替换自定义的mapred脚本
12.9 UDTF
UDTF将单一输入行转化为多个输出行,并且在使用UDTF时,select语句中不能包含其他的列,UDTF不支持嵌套,也不支持group by 、sort by等语句。如果想避免上述限制,需要使用lateral view语法,案例:
select a.timestamp, get_json_object(a.appevents, '$.eventid'), get_json_object(a.appenvets, '$.eventname') from log a;
select a.timestamp, b.* from log a lateral view json_tuple(a.appevent, 'eventid', 'eventname') b as f1, f2;
其中,get_json_object为UDF函数,json_tuple为UDTF函数。UDTF函数在某些应用场景下可以大大提高hql语句的性能,如需要多次解析json或者xml数据的应用场景。
12.10 聚合函数count和sum
Count和sum函数可能是在hql语句中使用的最为频繁的两个聚合函数了,但是在Hive中count函数在计算distinct value时支持加入条件过滤。
13、Hive 的权限控制
Hive从0.10可以通过元数据控制权限。但是Hive的权限控制并不是完全安全的。基本的授权方案的目的是防止用户不小心做了不合适的事情。
为了使用Hive的授权机制,有两个参数必须在Hive-site.xml中设置:
< property>
< name>Hive.security.authorization.enabled< /name>
< value>true< /value>
< description>enable or disable the Hive client authorization< /description>
< /property> < property>
< name>Hive.security.authorization.createtable.owner.grants< /name>
< value>ALL< /value>
< description>the privileges automatically granted to the owner whenever a table gets created. An example like "select,drop" will grant select and drop privilege to the owner of the table< /description>
< /property>
Hive.security.authorization.enabled //参数是开启权限验证,默认为 false。
Hive.security.authorization.createtable.owner.grants //参数是指表的创建者对表拥有所有权限。
14、角色的创建和删除
Hive 中的角色定义与关系型数据库中角色的定义类似,它是一种机制,给予那些没有适当权限的用户分配一定的权限。
14.1 创建角色
语法:Hive> create role role_name;
示例:Hive> create role role_tes1;
14.2 删除角色。
语法:drop role role_name
示例:drop role role_test1;
15、角色的授权和撤销
15.1 把 role_test1 角色授权给 xiaojiang 用户,命令如下。
Hive> grant role role_test1 to user xiaojiang;
15.2 查看 xiaojiang 用户被授权的角色,命令如下。
Hive > show role grant user xiaojiang;
15.3 取消 xiaojiang 用户的 role_test1 角色,命令如下。
Hive> revoke role role_test1 from user xiaojiang;
16、Hive 支持的权限控制
16.1 把 select 权限授权给 xiaojiang 用户,命令如下。
Hive> grant select on database default to user xiaojiang;
16.2 查看 xiaojiang 被授予那些操作权限,命令如下。
Hive> show grant user xiaojiang on database default;
16.3 收回 xiaojiang 的 select 权限,操作如下。
Hive> revoke select on database default from user xiaojiang;
16.4 查看 xiaojiang 用户拥有哪些权限,命令如下。
Hive> show grant user xiaojiang on database default;
17、超级管理权限
Hive本身有权限管理功能,需要通过配置开启。
< property>
< name>Hive.metastore.authorization.storage.checks< /name>
< value>true< /value>
< /property> < property>
< name>Hive.metastore.execute.setugi< /name>
< value>false< /value>
< /property> < property>
< name>Hive.security.authorization.enabled< /name>
< value>true< /value>
< /property> < property>
< name>Hive.security.authorization.createtable.owner.grants< /name>
< value>ALL< /value>
< /property>
其中Hive.security.authorization.createtable.owner.grants设置成ALL表示用户对自己创建的表是有所有权限的(这样是比较合理地)。
开启权限控制有Hive的权限功能还有一个需要完善的地方,那就是“超级管理员”。 Hive中没有超级管理员,任何用户都可以进行Grant/Revoke操作,为了完善“超级管理员”,必须添加Hive.semantic.analyzer.hook配置,并实现自己的权限控制类。
编写权限控制类,代码如下所示。
package com.xxx.Hive;
import org.apache.hadoop.Hive.ql.parse.ASTNode;
import org.apache.hadoop.Hive.ql.parse.AbstractSemanticAnalyzerHook;
import org.apache.hadoop.Hive.ql.parse.HiveParser;
import org.apache.hadoop.Hive.ql.parse.HiveSemanticAnalyzerHookContext;
import org.apache.hadoop.Hive.ql.parse.SemanticException;
import org.apache.hadoop.Hive.ql.session.SessionState; /**
* 设置Hive超级管理员 *
* @author
* @version $Id: AuthHook.java,v 0.1 2013-6-13 下午3:32:12 yinxiu Exp $
*/
public class AuthHook extends AbstractSemanticAnalyzerHook {
private static String admin = "admin";
@Override 27 public ASTNode preAnalyze(HiveSemanticAnalyzerHookContext context, 28 ASTNode ast) throws SemanticException {
switch (ast.getToken().getType()) {
case HiveParser.TOK_CREATEDATABASE:
case HiveParser.TOK_DROPDATABASE:
case HiveParser.TOK_CREATEROLE:
case HiveParser.TOK_DROPROLE:
case HiveParser.TOK_GRANT:
case HiveParser.TOK_REVOKE:
case HiveParser.TOK_GRANT_ROLE:
case HiveParser.TOK_REVOKE_ROLE:
String userName = null;
if (SessionState.get() != null && SessionState.get().getAuthenticator() != null) {
userName = SessionState.get().getAuthenticator().getUserName();
}
if (!admin.equalsIgnoreCase(userName)) {
throw new SemanticException(userName + " can't use ADMIN options, except " + admin + ".");
}
break;
default:
break;
}
return ast;
}
}
添加了控制类之后还必须添加下面的配置:
< property>
< name>Hive.semantic.analyzer.hook< /name>
< value>com.xxx.AuthHook< /value>
< /property>
若有使用Hiveserver,Hiveserver必须重启。
至此,只有admin用户可以进行Grant/Revoke操作。
权限操作示例:
Hive > grant select on database default to user xiaojiang;
Hive > revoke all on database default from user xiaojiang;
Hive > show grant user xiaojiang on database default;
18、Hive与JDBC示例
在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口。使用下面命令进行开启。
Hive -service Hiveserver & //Hive低版本提供的服务是:Hiveserver
Hive --service Hiveserver2 & //Hive0.11.0以上版本提供了的服务是:Hiveserver2
我这里使用的Hive1.0版本,故我们使用Hiveserver2服务,下面我使用 Java 代码通过JDBC连接Hiveserver。

[hadoop@djt002 hive-1.0.0]$ pwd
/usr/local/hive/hive-1.0.0
[hadoop@djt002 hive-1.0.0]$ bin/hive --service hiveserver2 &
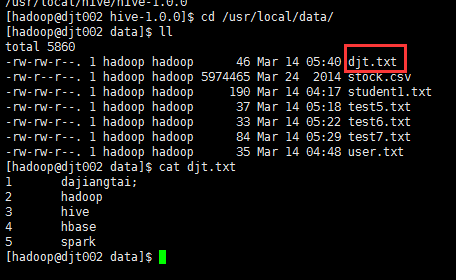
18.1 测试数据
本地目录/usr/local/data下的djt.txt文件内容(每行数据之间用tab键隔开)如下所示:
1 dajiangtai;
2 hadoop
3 hive
4 hbase
5 spark
18.2 程序代码
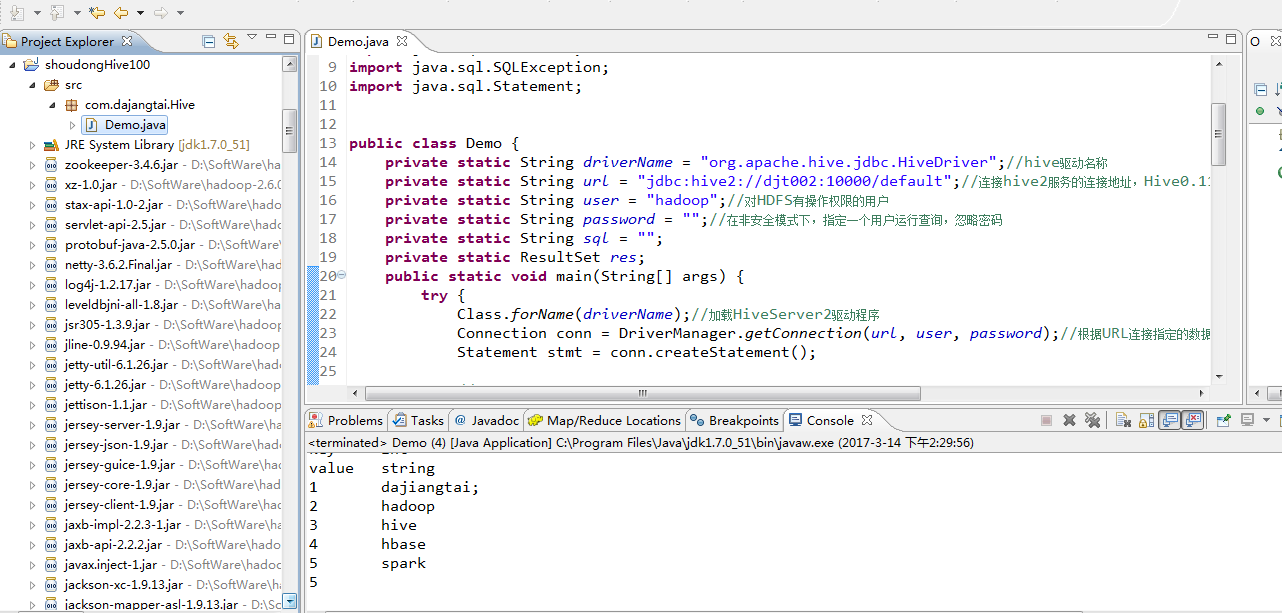
1 package com.dajangtai.Hive;
2
3
4
5
6 import java.sql.Connection;
7 import java.sql.DriverManager;
8 import java.sql.ResultSet;
9 import java.sql.SQLException;
10 import java.sql.Statement;
11
12
13 public class Demo {
14 private static String driverName = "org.apache.hive.jdbc.HiveDriver";//hive驱动名称
15 private static String url = "jdbc:hive2://djt002:10000/default";//连接hive2服务的连接地址,Hive0.11.0以上版本提供了一个全新的服务:HiveServer2
16 private static String user = "hadoop";//对HDFS有操作权限的用户
17 private static String password = "";//在非安全模式下,指定一个用户运行查询,忽略密码
18 private static String sql = "";
19 private static ResultSet res;
20 public static void main(String[] args) {
21 try {
22 Class.forName(driverName);//加载HiveServer2驱动程序
23 Connection conn = DriverManager.getConnection(url, user, password);//根据URL连接指定的数据库
24 Statement stmt = conn.createStatement();
25
26 //创建的表名
27 String tableName = "testHiveDriverTable";
28
29 /** 第一步:表存在就先删除 **/
30 sql = "drop table " + tableName;
31 stmt.execute(sql);
32
33 /** 第二步:表不存在就创建 **/
34 sql = "create table " + tableName + " (key int, value string) row format delimited fields terminated by '\t' STORED AS TEXTFILE";
35 stmt.execute(sql);
36
37 // 执行“show tables”操作
38 sql = "show tables '" + tableName + "'";
39 res = stmt.executeQuery(sql);
40 if (res.next()) {
41 System.out.println(res.getString(1));
42 }
43
44 // 执行“describe table”操作
45 sql = "describe " + tableName;
46 res = stmt.executeQuery(sql);
47 while (res.next()) {
48 System.out.println(res.getString(1) + "\t" + res.getString(2));
49 }
50
51 // 执行“load data into table”操作
52 String filepath = "/usr/local/data/djt.txt";//hive服务所在节点的本地文件路径
53 sql = "load data local inpath '" + filepath + "' into table " + tableName;
54 stmt.execute(sql);
55
56 // 执行“select * query”操作
57 sql = "select * from " + tableName;
58 res = stmt.executeQuery(sql);
59 while (res.next()) {
60 System.out.println(res.getInt(1) + "\t" + res.getString(2));
61 }
62
63 // 执行“regular hive query”操作,此查询会转换为MapReduce程序来处理
64 sql = "select count(*) from " + tableName;
65 res = stmt.executeQuery(sql);
66 while (res.next()) {
67 System.out.println(res.getString(1));
68 }
69 conn.close();
70 conn = null;
71 } catch (ClassNotFoundException e) {
72 e.printStackTrace();
73 System.exit(1);
74 } catch (SQLException e) {
75 e.printStackTrace();
76 System.exit(1);
77 }
78 }
79 }
18.3 运行结果(右击-->Run as-->Run on Hadoop)
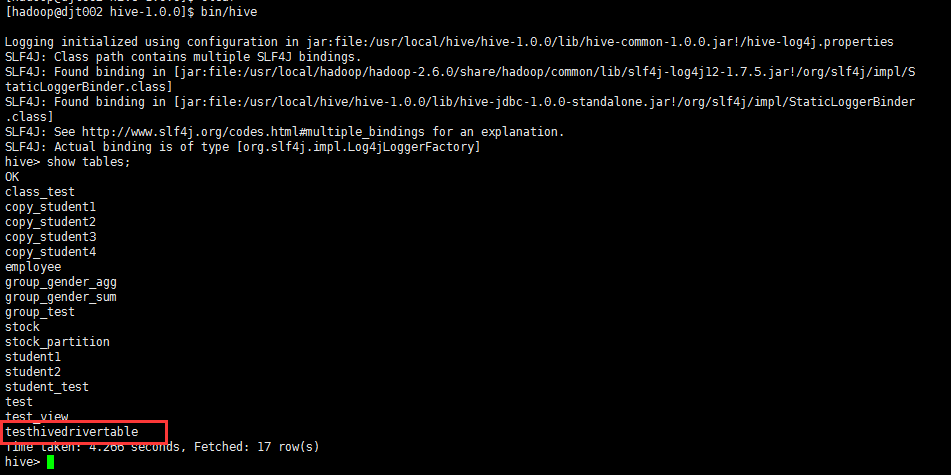
执行“show tables”运行结果:
testHivedrivertable
执行“describe table”运行结果:
key int
value string
执行“select * query”运行结果:
1 dajiangtai
2 hadoop
3 Hive
4 hbase
5 spark
执行“regular Hive query”运行结果:
5
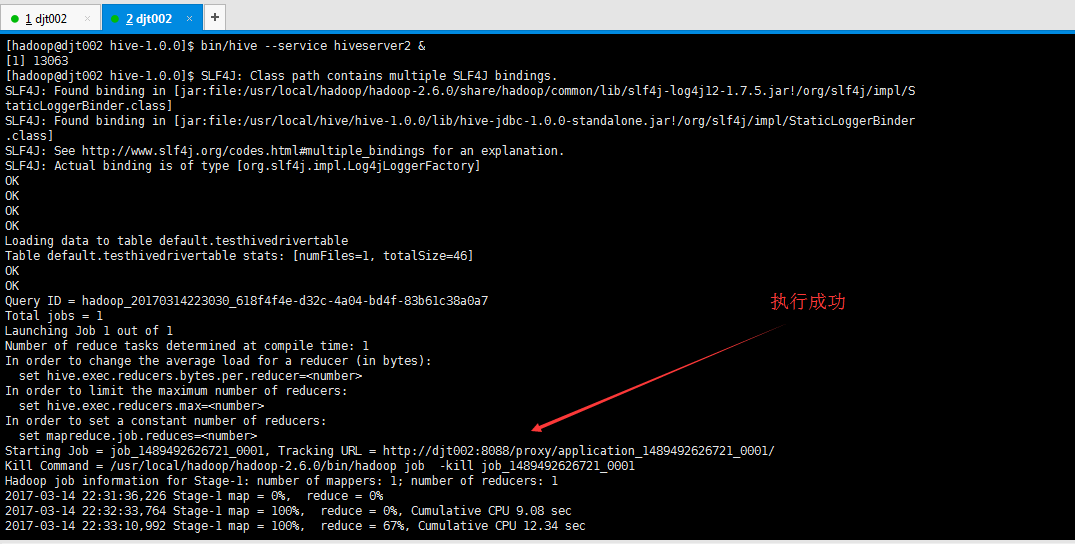
[hadoop@djt002 hive-1.0.0]$ bin/hive --service hiveserver2 &
[1] 13063
[hadoop@djt002 hive-1.0.0]$ SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hive/hive-1.0.0/lib/hive-jdbc-1.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
OK
OK
OK
OK Loading data to table default.testhivedrivertable
Table default.testhivedrivertable stats: [numFiles=1, totalSize=46]
OK
OK
Query ID = hadoop_20170314223030_618f4f4e-d32c-4a04-bd4f-83b61c38a0a7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1489492626721_0001, Tracking URL = http://djt002:8088/proxy/application_1489492626721_0001/
Kill Command = /usr/local/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1489492626721_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2017-03-14 22:31:36,226 Stage-1 map = 0%, reduce = 0%
2017-03-14 22:32:33,764 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 9.08 sec
2017-03-14 22:33:10,992 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 12.34 sec
2017-03-14 22:33:14,485 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 14.51 sec
MapReduce Total cumulative CPU time: 14 seconds 510 msec
Ended Job = job_1489492626721_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 14.51 sec HDFS Read: 266 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 14 seconds 510 msec
OK
19、Hive 案例分析
这里我们以机顶盒产生的用户收视数据为例,来具体分析如何使用Hive。
1、机顶盒产生的用户原始数据都有一定的格式,包含机顶盒号、收看的频道、收看的节目、收看的时间等信息。
2、用户的原始数据通常不直接交给Hive处理,而是需要经过一个清洗和转化的过程。这个过程一般是通过Hadoop 作业来实现,转化成与Hive表对应的格式。
这个案例的具体步骤如下:
步骤1:用户数据预处理
通过MapReduce作业将日志转化为固定的格式。
用户的原始数据如下所示。
< GHApp>< WIC cardNum="1370695139" stbNum="03111108020232488" date="2012-09-21" pageWidgetVersion="1.0">< A e="13:55:11" s="13:50:10" n="104" t="1" pi="789" p="%E5%86%8D%E5%9B%9E%E9%A6%96(21)" sn="BTV影视" />< /WIC>< /GHApp>
转化之后的数据如下所示,每个字段我们使用"@"分割符号。
1370695139@03111108020232488@2012-09-21@BTV影视@再回首@13:50:10@13:55:11@301
上面的字段分别代表:机顶盒号、用户编号、收看日期、频道、栏目、起始时间、结束时间、收视时长。
步骤2:创建Hive表
我们根据对应字段,使用Hive创建表。
create table tvdata(cardnum string,stbnum string,date string,sn string,p string ,s string,e string,duration int) row format delimited fields terminated by '@' stored as textfile;
步骤3:将hdfs中的数据导入表中
我们使用以下命令,将hdfs中的数据导入表中。
load data inpath '/media/tvdata/part-r-00000' into table tvdata;
步骤4:编写HQL,分析数据
使用HQL语句,统计每个的频道的人均收视时长。
select sn,sum(duration)/count(*) from tvdata group by sn;
这里我们使用HQL只是从一个角度分析数据,大家可以尝试从多个角度来分析数据。
Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)的更多相关文章
- MySQL:记录的增删改查、单表查询、约束条件、多表查询、连表、子查询、pymysql模块、MySQL内置功能
数据操作 插入数据(记录): 用insert: 补充:插入查询结果: insert into 表名(字段1,字段2,...字段n) select (字段1,字段2,...字段n) where ...; ...
- [Hive - Tutorial] Built In Operators and Functions 内置操作符与内置函数
Built-in Operators Relational Operators The following operators compare the passed operands and gene ...
- Vue基础(环境配置、内部指令、全局API、选项、内置组件)
1.环境配置 安装VsCode 安装包管理工具:直接下载 NodeJS 进行安装即可,NodeJS自带 Npm 包管理工具,下载地址:https://nodejs.org/en/download/安装 ...
- perl 内置操作符 $^O -判断操作系统环境
今天看bowtie2的源代码的时候,发现有这样一段用法: my $os_is_nix = $^O ne "MSWin32"; my $align_bin_s = $os_is_ni ...
- 一起学Hive——创建内部表、外部表、分区表和分桶表及导入数据
Hive本身并不存储数据,而是将数据存储在Hadoop的HDFS中,表名对应HDFS中的目录/文件.根据数据的不同存储方式,将Hive表分为外部表.内部表.分区表和分桶表四种数据模型.每种数据模型各有 ...
- hive内部表、外部表、分区
hive内部表.外部表.分区 内部表(managed table) 默认创建的是内部表(managed table),存储位置在hive.metastore.warehouse.dir设置,默认位置是 ...
- hadoop笔记之Hive的数据存储(内部表)
Hive的数据存储(内部表) Hive的数据存储(内部表) 基于HDFS 可使用hadoop给我们提供的web管理工具查看数据.打开管理工具localhost:9000–>Utilities下的 ...
- 使用impala操作kudu之创建kudu表(内部表和外部表)
依次启动HDFS.mysql.hive.kudu.impala 登录impala的shell控制端: Impala-shell 1:使用该impala-shell命令启动Impala Shell .默 ...
- Hive 数据类型及操作数据库
3. Hive 数据类型 3.1 基本数据类型 Hive 数据类型 Java 数据类型 长度 TINYINT byte 1 byte 有符号整数 SMALINT short 2 byte 有符号整数 ...
随机推荐
- 夜色的 cocos2d-x 开发笔记 03
本章添加敌人,首先我们在.h文件里添加新的方法 之后进入.cpp文件,写出方法内容 当然还要调用一次,我把这个方法添加在了这里,也就是和发子弹是同步的,当然想要多久调用一次大家可以自己调整 运行一下 ...
- 使用fn_dblog函数查看事务日志和恢复数据
基本语法 SqlServer中有一个未在文档中公开的函数sys.fn_dblog,提供查询当前数据库事务日志的功能.通过这个函数,可以简单了解下数据库事务日志的机制 使用方法如下: select * ...
- Python基础学习之语句和语法
语句和语法 python语句中有一些基本规则和特殊字符: 井号键“#”表示之后的字符为python注释: 三引号(‘‘‘ ’’’)可以多行注释 换行“\n”是标准的行分隔符(通常一个语句一行): 反斜 ...
- 笨办法学Python(三十一)
习题 31: 作出决定 这本书的上半部分你打印了一些东西,而且调用了函数,不过一切都是直线式进行的.你的脚本从最上面一行开始,一路运行到结束,但其中并没有决定程序流向的分支点.现在你已经学了 if, ...
- 10大炫酷的HTML5文字动画特效欣赏
文字是网页中最基本的元素,在CSS2.0时代,我们只能在网页上展示静态的文字,只能改变他的大小和颜色,显得枯燥无味.随着HTML5的发展,现在网页中的文字样式变得越来越丰富了,甚至出现了文字动画,HT ...
- 寄生构造函数模式 js
有一点需要说明:首先返回的对象与构造函数或者构造函数的原型属性之间没有关系,也就是说构造函数返回的对象与在构造函数外部创建的对象没有什么不同,为此不能依赖 instanceof 操作符来确定对象类型. ...
- Android(java)学习笔记71:Tab标签的使用
1. 案例1---TabProject (1)首先是main.xml文件: <?xml version="1.0" encoding="utf-8"?&g ...
- MapReduce执行jar练习
1.用程序生成输入文件1.txt和2.txt 生成程序源码如下: https://www.cnblogs.com/jonban/p/10555364.html 2. 上传文件到hdfs文件系统 创建 ...
- Scrivener 中文语言包
Scrivener 中文语言包 随着OS X EI Capitan的发布,Scrivener 也升级到了2.7,程序没有大的变化,主要是为了兼容10.11并更新了图标. 原来的2.6的中文语言包无法在 ...
- 第50章 读写内部FLASH—零死角玩转STM32-F429系列
第50章 读写内部FLASH 全套200集视频教程和1000页PDF教程请到秉火论坛下载:www.firebbs.cn 野火视频教程优酷观看网址:http://i.youku.com/fire ...