C#利用phantomJS抓取AjAX动态页面
在C#中,一般常用的请求方式,就是利用HttpWebRequest创建请求,返回报文。但是有时候遇到到动态加载的页面,却只能抓取部分内容,无法抓取到动态加载的内容。
如果遇到这种的话,推荐使用phantomJS无头浏览器。
开发之前,先准备两样东西。
1. phantomJS-2.1.1 官方下载地址:http://phantomjs.org/download.html
2. JS脚本文件,本人命名为codes.js.内容如下。起初我并没有配置page的settings信息,导致在抓取有些异步页面卡死。主要原因是由于没有配置请求头部信息。
- var page = require('webpage').create(), system = require('system');
- var url = system.args[1];
- var interval = system.args[2];
- var settings = {
- timeout: interval,
- encoding: "gb2312",
- operation: "GET",
- headers: {
- "User-Agent": system.args[3],
- "Accept": system.args[4],
- "Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
- "Connection": "keep-alive",
- "Upgrade-Insecure-Requests": 1,
- "Connection": "keep-alive",
- "Pragma": "no-cache",
- "Cache-Control": "no-cache",
- "Referer": system.args[5]
- }
- }
- page.settings = settings;
- page.open(url, function (status) {
- phantom.outputEncoding = "gb2312";
- if (status !== 'success') {
- console.log('Unable to post!');
- phantom.exit();
- } else {
- setTimeout(function () {
- console.log(page.content);
- phantom.exit();
- }, interval);
- }
- });
准本完成之后,需要将这两份文件放到你的项目中。如下:
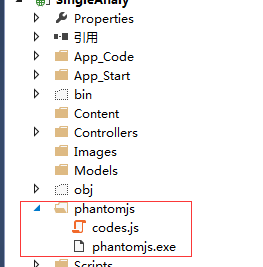
这些都没问题了,就可以开始写后台代码了。
- /// <summary>
- /// 利用phantomjs 爬取AJAX加载完成之后的页面
- /// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
- /// </summary>
- /// <param name="url"></param>
- /// <returns></returns>
- public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
- {
- try
- {
- string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
- ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
- start.WorkingDirectory = path + @"phantomjs\";
- ////设置命令参数
- string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
- start.Arguments = commond;
- StringBuilder sb = new StringBuilder();
- start.CreateNoWindow = true;//不显示dos命令行窗口
- start.RedirectStandardOutput = true;//
- start.RedirectStandardInput = true;//
- start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
- Process p = Process.Start(start);
- StreamReader reader = p.StandardOutput;//截取输出流
- string line = reader.ReadToEnd();//每次读取一行
- string strRet = line;// sb.ToString();
- p.WaitForExit();//等待程序执行完退出进程
- p.Close();//关闭进程
- reader.Close();//关闭流
- return strRet;
- }
- catch (Exception ex)
- {
- return ex.Message.ToString();
- }
- }
- public class HttpConfig
- {
- /// <summary>
- /// 网站cookie信息
- /// </summary>
- public string Cookie { get; set; }
- /// <summary>
- /// 页面Referer信息
- /// </summary>
- public string Referer { get; set; }
- /// <summary>
- /// 默认(text/html)
- /// </summary>
- public string ContentType { get; set; }
- public string Accept { get; set; }
- public string AcceptEncoding { get; set; }
- /// <summary>
- /// 超时时间(毫秒)默认100000
- /// </summary>
- public int Timeout { get; set; }
- public string UserAgent { get; set; }
- /// <summary>
- /// POST请求时,数据是否进行gzip压缩
- /// </summary>
- public bool GZipCompress { get; set; }
- public bool KeepAlive { get; set; }
- public string CharacterSet { get; set; }
- public HttpConfig()
- {
- this.Timeout = 100000;
- this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
- this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
- this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
- this.AcceptEncoding = "gzip,deflate";
- this.GZipCompress = false;
- this.KeepAlive = true;
- this.CharacterSet = "UTF-8";
- }
- }
这些也是本人今天才接触到的,整理下自己的想法。有错误之处还希望能够指出。
C#利用phantomJS抓取AjAX动态页面的更多相关文章
- scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):
一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析.本篇文章则是通过利用fiddler抓包获取j ...
- scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置 经过分析只有画线的page在变化 上代码: items.py import scrapy class ImoocItem(scrapy.It ...
- Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
1,引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第二部分,第一 ...
- C#抓取AJAX页面的内容
原文 C#抓取AJAX页面的内容 现在的网页有相当一部分是采用了AJAX技术,所谓的AJAX技术简单一点讲就是事件驱动吧(当然这种说法可能很不全面),在你提交了URL后,服务器发给你的并不是所有是页面 ...
- 利用selenium抓取网页的ajax请求
部门需要一个自动化脚本,完成web端界面功能的冒烟,并且需要抓取加载页面时的ajax请求,从接口层面判断请求是否成功.查阅了很多资料都没有人有过相关问题的处理经验,在处理过程中也踩了很多坑,所以如果你 ...
- CasperJS基于PhantomJS抓取页面
CasperJS基于PhantomJS抓取页面 Casperjs是基于Phantomjs的,而Phantom JS是一个服务器端的 JavaScript API 的 WebKit. CasperJS是 ...
- 抓取Js动态生成数据且以滚动页面方式分页的网页
代码也可以从我的开源项目HtmlExtractor中获取. 当我们在进行数据抓取的时候,如果目标网站是以Js的方式动态生成数据且以滚动页面的方式进行分页,那么我们该如何抓取呢? 如类似今日头条这样的网 ...
- [Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据
本篇主要是利用 pyquery来定位抓取数据,而不用xpath,通过和xpath比较,pyquery效率要高. 主要代码: # coding=utf-8 import os import re fro ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
随机推荐
- BZOJ3809:Gty的二逼妹子序列
浅谈莫队:https://www.cnblogs.com/AKMer/p/10374756.html 题目传送门:https://lydsy.com/JudgeOnline/problem.php?i ...
- 蓝桥杯 算法训练 ALGO-150 6-1 递归求二项式系数值
算法训练 6-1 递归求二项式系数值 时间限制:10.0s 内存限制:256.0MB 问题描述 样例输入 一个满足题目要求的输入范例.3 10 样例输出 与上面的样例输入对应的输出. 数据 ...
- hihoCoder#1121(二分图判定)
时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 大家好,我是小Hi和小Ho的小伙伴Nettle,从这个星期开始由我来完成我们的Weekly. 新年回家,又到了一年一度大龄 ...
- [转]ubuntu11.04配置nfs--解决mount.nfs: access denied问题
总算通过了nfs的localhost测试. 配置很简单,下面摘自网络,并且整理下: 1 安装nfs #apt-get install nfs-kernel-server #apt-get instal ...
- HTTP-Runoob:HTPP消息结构
ylbtech-HTTP-Runoob:HTPP消息结构 1.返回顶部 1. HTTP 消息结构 HTTP是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响 ...
- MFC鼠标键盘消息处理
void CMainWindow::OnKeyDown(UINT nChar, UINT nRepCnt, UINT nFlags ){ )&&(GetKeyState(VK_LBUT ...
- 问题:sqlserver 跨服务器连接;结果:Sql Server 跨服务器连接
Sql Server 跨服务器连接 用openrowset连接远程SQL或插入数据 --如果只是临时访问,可以直接用openrowset --查询示例 select * from openrowset ...
- 为Docker镜像添加SSH服务
一.基于commit命令创建 1. 首先下载镜像 $ docker run -it ubuntu:16.04 /bin/bash 2. 安装SSH服务 #更新apt缓存 root@5ef1d31632 ...
- 使用网络用户命令行工具的/passwordreq:yes
提示:"新建域时,本地administrator帐户将成为域administrator账户.无法新建域,因为本地administrator账户密码不符合要求.目前,本地administrat ...
- 关于android写入SD卡数据的学习代码
String path = "data/data/com.example.qqlogin/login.txt"; FileOutputStream fos = new FileOu ...