python爬虫(8)--Xpath语法与lxml库
1.XPath语法
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
节点关系
(1)父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>family</title>
<year>2007</year>
<price>78</price>
</book>
(2)子(Children)
元素节点可有零个、一个或多个子。
在上面的例子中,title、author、year 以及 price 元素都是 book 元素的子
(3)同胞(Sibling)
拥有相同的父的节点
在上面的例子中,title、author、year 以及 price 元素都是同胞
(4)先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素
<bookstore>
<book>
<title>family</title>
<year>2007</year>
<price>78</price>
</book>
</bookstore>
(5)后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
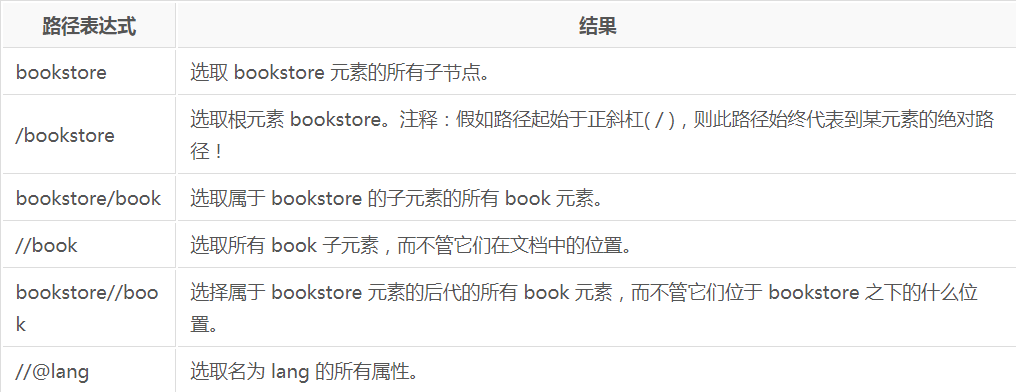
下面列出了最有用的路径表达式:

实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:

选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| – | 减法 | 6 – 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
2.lxml用法
初步使用
首先我们利用它来解析 HTML 代码,先来一个小例子来感受一下它的基本用法。
from lxml import etree text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print result
首先使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
其中,这里体现了 lxml 的一个非常实用的功能就是自动修正 html 代码,应该注意到了,最后一个 li 标签,其实把尾标签删掉了,是不闭合的。不过,lxml 因为继承了 libxml2 的特性,具有自动修正 HTML 代码的功能。
所以输出结果是这样的
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
不仅补全了 li 标签,还添加了 body,html 标签。
文件读取
除了直接读取字符串,还支持从文件读取内容。比如我们新建一个文件叫做 hello.html,内容为上面的text
html = etree.parse('hello.html')
result = etree.tostring(html)
print result
利用 parse 方法来读取文件,同样可以得到相同的结果。
XPath实例测试
依然以上一段程序为例
(1)获取所有的 <li> 标签
html = etree.parse('hello.html')
print type(html)
result = html.xpath('//li')
print result
print len(result)
print type(result)
print type(result[0])
运行结果
<type 'lxml.etree._ElementTree'>
[<Element li at 0x312d558>, <Element li at 0x312d530>, <Element li at 0x312d508>, <Element li at 0x312d2b0>, <Element li at 0x312d0d0>]
5
<type 'list'>
<type 'lxml.etree._Element'>
可见,etree.parse 的类型是 ElementTree,通过调用 xpath 以后,得到了一个列表,包含了 5 个 <li> 元素,每个元素都是 Element 类型
(2)获取 <li> 标签的所有 class
html = etree.parse('hello.html')
print type(html)
result = html.xpath('//li/@class')
print result
运行结果
<type 'lxml.etree._ElementTree'>
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
(3)获取 <li> 标签下 href 为 link1.html 的 <a> 标签
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print result
(4)获取 <li> 标签下的所有 <span> 标签
/ 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath('//li//span')
(5)获取 <li> 标签下的所有 class,不包括 <li>
result = html.xpath('//li/a//@class')
(6)获取最后一个 <li> 的 <a> 的 href
result = html.xpath('//li[last()]/a/@href')
#['link5.html']
(7)获取倒数第二个元素的内容
result = html.xpath('//li[last()-1]/a')
(8)获取 class 为 item-1 的标签名
result = html.xpath('//*[@class="item-1"]')
print result[0].tag
python爬虫(8)--Xpath语法与lxml库的更多相关文章
- python爬虫:XPath语法和使用示例
python爬虫:XPath语法和使用示例 XPath(XML Path Language)是一门在XML文档中查找信息的语言,可以用来在XML文档中对元素和属性进行遍历. 选取节点 XPath使用路 ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- 12.Python爬虫利器三之Xpath语法与lxml库的用法
LXML解析库使用的是Xpath语法: XPath 是一门语言 XPath可以在XML文档中查找信息 XPath支持HTML XPath通过元素和属性进行导航 XPath可以用来提取信息 XPath比 ...
- Python爬虫利器三之Xpath语法与lxml库的用法
前面我们介绍了 BeautifulSoup 的用法,这个已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法.如果大家对 Beau ...
- 芝麻HTTP:Python爬虫利器之Xpath语法与lxml库的用法
安装 pip install lxml 利用 pip 安装即可 XPath语法 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPat ...
- Xpath语法与lxml库的用法
BeautifulSoup 已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法. 1.安装 pip install lxml 2 ...
- Xpath语法与lxml库
1. Xpath 1 )什么是XPath? xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. 2) X ...
- 请求数据分析 xpath语法 与lxml库
前情提要: 上节学过从网上获取请求,获取返回内容,带理 获取内容之后,第二部就是获取请求的数据分析 一:xpath 语法 浏览器一般会自带xpatn 解析 这里大概讲述一下xpath 的基本操作 二: ...
- Python爬虫基础——XPath语法的学习与lxml模块的使用
XPath与正则都是用于数据的提取,二者的区别是: 正则:功能相对强大,写起来相对复杂: XPath:语法简单,可以满足绝大部分的需求: 所以,如果你可以根据自己的需要进行选择. 一.首先,我们需要为 ...
随机推荐
- js装饰者模式
装饰者模式是为已有的功能动态地添加更多功能的一种方式.当系统需要新功能的时候,是向旧的类中添加新的代码.这些新加的代码通常装饰了原有类的核心职责或主要行为,在主类中加入了新的字段,新的方法和新的逻辑, ...
- Tensorflow中的命名空间scope
1.name_scope 在tensorflow中有两种声明变量的方式,tf.get_variable()和tf.Variable(). name_scope对于tf.get_variable()无效 ...
- jquery自定义window事件
<body> <a href='https://www.baidu.com/'>百度</a> </body> <script type=" ...
- 185. Department Top Three Salaries
问题描述 解决方案 select b.name Department,a.name Employee,a.salary Salary from Employee a,Department b wher ...
- DH04-开放封闭原则
模式简介 定义:一个软件实体如类.模块和函数应该对扩展开放,对修改关闭. 无论模块是多么封闭,都会存在一些无法对之封闭的变化.对设计的模块预估可能发生变化种类,然后构造抽象来隔离变化. 解决:创建抽象 ...
- C#中的线程(二)线程同步
C#中的线程(二)线程同步 Keywords:C# 线程Source:http://www.albahari.com/threading/Author: Joe AlbahariTranslato ...
- Hadoop2.5.2+HA+zookeeper3.4.6详细配置过程
心血之作,在熟悉hadoop2架构的过程耽误了太长时间,在搭建环境过程遇到一些问题,这些问题一直卡在那儿,不得以解决,耽误了时间.最后,千寻万寻,把问题解决,多谢在过程提供帮助的大侠.这篇文章中,我也 ...
- 信息标记 以及信息提取--xml-json-yaml
1 信息标记的三种方式: XML: JSON: YAML: 1 缩进 表示所属关系: 2 - 表示并列关系: 3 | 表示整块数据: HTML----XML的一种形式: 2 信息提取的方法: ...
- 「2017 山东三轮集训 Day7」Easy
一棵带边权的树,多次询问 $x$ 到编号为 $[l,r]$ 的点最短距离是多少 $n \leq 100000$ sol: 动态点分治,每层重心维护到所有点的距离 查询的时候在管辖这个点的 log 层线 ...
- java多线程并发去调用一个类的静态方法安全性探讨
java多线程并发去调用一个类的静态方法安全性探讨 转自:http://blog.csdn.net/weibin_6388/article/details/50750035 这篇文章主要讲多线程对 ...