SolrCloud 分布式集群部署步骤
- 推荐 0 推荐
- 收藏 5 收藏,6.7k 浏览
安装软件包准备
- apache-tomcat-7.0.54
- jdk1.7
- solr-4.8.1
- zookeeper-3.4.5
注:以上软件都是基于 Linux 环境的 64位 软件,以上软件请到各自的官网下载。
服务器准备
为搭建这个集群,准备三台服务器,分别为
192.168.0.2 -- master 角色
192.168.0.3 -- slave 角色
192.168.0.4 -- slave 角色
搭建基础环境
安装 jdk1.7 - 这个大家都会安装,就不费键盘了。
配置主机
/etc/hosts文件 - 当然,如果内部有内部DNS解析,就不需要配置hosts文件了。在 3 台服务器的/etc/hosts中添加以下记录
192.168.0.2 SOLR-CLOUD-001
192.168.0.3 SOLR-CLOUD-002
192.168.0.4 SOLR-CLOUD-003
zookeeper 部署
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
注:Zookeeper集群的机器个数推荐是奇数台,半数机器挂掉,服务是可以正常提供的
首先以 192.168.0.2 为例来搭建 zookeeper:
在软件部署目录下面部署 zookeeper,把下载的 zookeeper-3.4.5 解压到软件部署目录
/apps/svr注:为了统一部署,以及以后自动化方便,必须统一软件部署目录,目前我这边是以 ``/apps/svr``` 为软件部署主目录
建立 zookeeper 的数据、日志以及配置文件目录
mkdir -p /apps/data/zookeeper-data/
mkdir -p /apps/data/zookeeper-data/logs/
mkdir -p /apps/svr/zookeeper-3.4.5/conf
注:
/apps/data是定义的统一存放数据的目录
- 把
zookeeper的 conf 目录下面的zoo_sample.cfg修改成zoo.cfg,并且对其内容做修改
cp -av /apps/svr/zookeeper-3.4.5/conf/zoo_sample.cfg /apps/svr/zookeeper-3.4.5/conf/zoo.cfg
修改 zoo.cfg 的内容,主要是修改 dataDir 、dataLogDir 和 server.1-3
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/apps/data/zookeeper-data
dataLogDir=/apps/data/zookeeper-data/logs
server.1=SOLR-CLOUD-001:2888:3888
server.2=SOLR-CLOUD-002:2888:3888
server.3=SOLR-CLOUD-003:2888:3888
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
注:
tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是52000=10秒。
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 22000=4 秒
dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
dataLogDir: Zookeeper的日志文件位置。
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
- 同步 zookeeper 的配置以及相关目录到其他两台服务中
scp -r /apps/svr/zookeeper-3.4.5 solr@192.168.0.3:/apps/svr
scp -r /apps/data/zookeeper-data solr@192.168.0.3:/apps/data
scp -r /apps/svr/zookeeper-3.4.5 solr@192.168.0.4:/apps/svr
scp -r /apps/data/zookeeper-data solr@192.168.0.4:/apps/data
- 创建 myid 文件存储该机器的标识码,比如 server.1 的标识码就是 “1”,myid文件的内容就一行: 1
192.168.0.2
echo "1" >> /apps/data/zookeeper-data/myid
192.168.0.3
echo "2" >> /apps/data/zookeeper-data/myid
192.168.3
echo "3" >> /apps/data/zookeeper-data/myid
- 分别启动三台服务器的 zookeeper
cd /apps/svr/zookeeper-3.4.5/bin
./zkServer.sh start
查看 zookeeper 的状态
[solr@SOLR-CLOUD-001 bin]$ ./zkServer.sh status
JMX enabled by default
Using config: /apps/svr/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader
[solr@SOLR-CLOUD-002 bin]$ ./zkServer.sh status
JMX enabled by default
Using config: /apps/svr/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
[solr@SOLR-CLOUD-003 bin]$ ./zkServer.sh status
JMX enabled by default
Using config: /apps/svr/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
Solrcloud分布式集群搭建
- 解压部署 tomcat - 解压部署后的目录为
/apps/svr/apache-tomcat-7.0.54 - 解压 solr-4.8.1 的压缩包,并且把 solr-4.8.1/example/webapps/solr.war 解压至 /apps/svr/solr 目录下
- 把 solr-4.8.1\example\lib\ext 下的 jar 包放到 solr\WEB-INF\lib 下
- 以 192.168.0.2 为例,创建以下目录
mkdir -p /apps/svr/solrcloud/config-files
mkdir -p /apps/svr/solrcloud/solr-lib
- 把 solr/WEB-INF/lib 下的所有 jar 包拷贝到 /apps/svr/solrcloud/solr-lib 目录
cp -av /apps/svr/solr/WEB-INF/lib/*.jar /apps/svr/solrcloud/solr-lib
- solr/example/solr/collection1/conf 下的所有文件拷贝到 /apps/svr/solrcloud/config-files 目录
cp -av /apps/svr/solr/example/solr/collection1/conf/* /apps/svr/solrcloud/config-files/
- 将 /apps/svr/solr 目录拷贝到 /apps/svr/apache-tomcat-7.0.54/webapps 目录下面
cp -av /apps/svr/solr /apps/svr/apache-tomcat-7.0.54/webapps
- 创建 solr 的数据目录
/apps/svr/solr-cores并在该目录下生成solr.xml, 这是solr的核心配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="true">
<logging enabled="true">
<watcher size="100" threshold="INFO" />
</logging>
<cores defaultCoreName="collection1" adminPath="/admin/cores" host="${host:}" hostPort="8080" hostContext="${hostContext:solr}" zkClientTimeout="${zkClientTimeout:15000}">
<core numShards="3" name="test_shard1_replica1" instanceDir="test_shard1_replica1" shard="shard1" collection="test" coreNodeName="192.168.0.2:8080_solr_test_shard1_replica1"/>
<core name="userinfo_shard1_replica3" instanceDir="userinfo_shard1_replica3" shard="shard1" collection="userinfo" coreNodeName="192.168.0.2:8080_solr_userinfo_shard1_replica3"/>
<core name="userinfo_shard2_replica3" instanceDir="userinfo_shard2_replica3" shard="shard2" collection="userinfo" coreNodeName="192.168.0.3:8080_solr_userinfo_shard2_replica3"/>
<core numShards="3" name="userinfo_shard3_replica1" instanceDir="userinfo_shard3_replica1" shard="shard3" collection="userinfo" coreNodeName="192.168.0.4:8080_solr_userinfo_shard3_replica1"/>
</cores>
</solr>
注:上面的配置文件中有 shard 的信息,那是因为我已经分片了自动生成的
原始的配置文件如下
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="true">
<logging enabled="true">
<watcher size="100" threshold="INFO" />
</logging>
<cores defaultCoreName="collection1" adminPath="/admin/cores" host="${host:}" hostPort="8080" hostContext="${hostContext:solr}" zkClientTimeout="${zkClientTimeout:15000}">
</cores>
</solr>
- 创建/apps/svr/apache-tomcat-7.0.54/conf/Catalina 目录 和 /apps/svr/apache-tomcat-7.0.54/conf/Catalina/localhost 目录
mkdir -p /apps/svr/apache-tomcat-7.0.54/conf/Catalina
mkdir -p /apps/svr/apache-tomcat-7.0.54/conf/Catalina/localhost
- 在 /apps/svr/apache-tomcat-7.0.54/conf/Catalina/localhost 下创建 solr.xml 文件,此文件为 Solr/home 的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<Context docBase="/apps/svr/tomcat-solr/webapps/solr" debug="0" crossContext="true">
<Environment name="solr/home" type="java.lang.String" value="/apps/svr/solr-cores" override="true"/>
</Context>
- 修改 tomcat/bin/cataina.sh ,加入以下内容
CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9060 -Djava.rmi.server.hostname=`/sbin/ifconfig bond0 |grep -a "inet addr:" |awk -F":" '{print $2}' |egrep -o '([0-9]{1,3}\.?){4}'`"
CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
JAVA_OPTS="$JAVA_OPTS -DzkHost=GD6-SOLR-CLOUD-001:2181,GD6-SOLR-CLOUD-002:2181,GD6-SOLR-CLOUD-003:2181"
JAVA_OPTS="$JAVA_OPTS -Xmx8192m -Xms8192m -Xmn4g -Xss256k -XX:ParallelGCThreads=24 -XX:+UseConcMarkSweepGC -XX:PermSize=256m -XX:MaxPermSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintHeapAtGC -Xloggc:/apps/logs/tomcat/gc`date +%Y%m%d%H%M%S`.log -XX:ErrorFile=\"/apps/logs/tomcat/java_error.log\""
- 将以上配置同步到其他两台服务器
scp -r /apps/svr/apache-tomcat-7.0.54 solr@192.168.0.3:/apps/svr
scp -r /apps/svr/solrcloud solr@192.168.0.3:/apps/svr
scp -r /apps/svr/solr-cores solr@192.168.0.3:/apps/svr
scp -r /apps/svr/apache-tomcat-7.0.54 solr@192.168.0.4:/apps/svr
scp -r /apps/svr/solrcloud solr@192.168.0.4:/apps/svr
scp -r /apps/svr/solr-cores solr@192.168.0.4:/apps/svr
- SolrCloud 是通过 ZooKeeper 集群来保证配置文件的变更及时同步到各个节点上,所以,需要将配置文件上传到 ZooKeeper 集群中:执行如下操作(以下ip均可使用域名进行操作)
java -classpath .:/apps/svr/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 192.168.0.2:2181,192.168.0.3:2181,192.168.0.4:2181 -confdir /apps/svr/solrcloud/config-files/ -confname myconf
- 校验 zookeeper 的配置文件
cd /apps/svr/zookeeper-3.4.5/bin
./zkCli.sh -server 192.168.0.2:2181
[zk: 192.168.01.2:2181(CONNECTED) 0] ls /
[configs, collections, zookeeper]
[zk: 192.168.01.2:2181(CONNECTED) 1] ls /configs
[myconf]
[zk: 192.168.01.2:2181(CONNECTED) 2] ls /configs/myconf
[admin-extra.menu-top.html, currency.xml, protwords.txt, mapping-FoldToASCII.txt, solrconfig.xml, lang, stopwords.txt, spellings.txt, mapping-ISOLatin1Accent.txt, admin-extra.html, xslt, scripts.conf, synonyms.txt, update-script.js, velocity, elevate.xml, admin-extra.menu-bottom.html, schema.xml]
[zk: 192.168.01.2:2181(CONNECTED) 3]
- 启动 tomcat ,首先启动 master 192.168.0.2 上面的 tomcat
cd /apps/svr/apache-tomcat-7.0.54/bin
./startup.sh
- 启动 192.168.0.3 和 192.168.0.4 的 tomcat
- 访问 http://192.168.0.2:8080/solr 可以看到下图
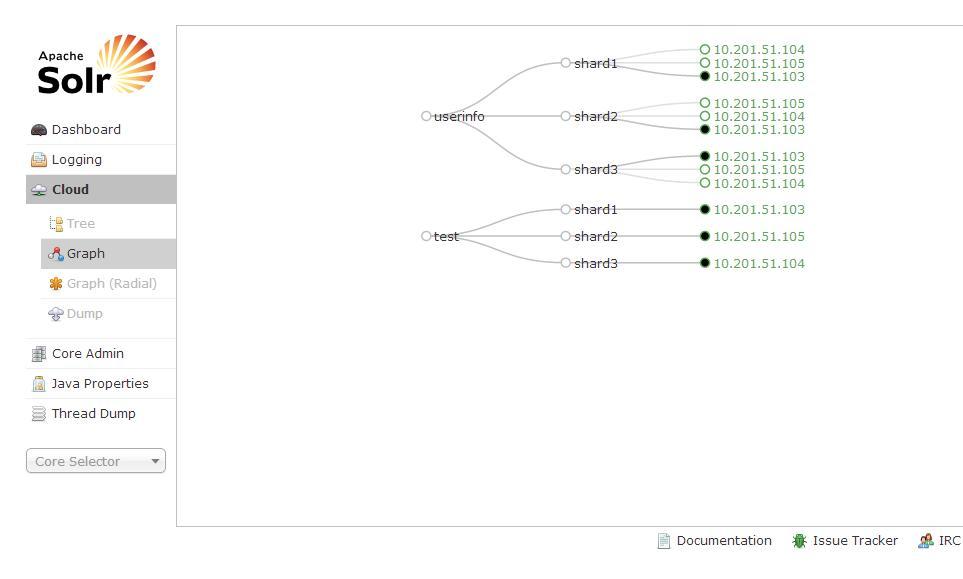
创建 Collection 及初始 Shard
curl 'http://192.168.0.2:8080/solr/admin/collections?action=CREATE&name=userinfo&numShards=3&replicationFactor=1'
curl 'http://192.168.0.2:8080/solr/admin/collections?action=CREATE&name=userinfo&numShards=3&replicationFactor=1'
curl 'http://192.168.0.2:8080/solr/admin/collections?action=CREATE&name=userinfo&numShards=3&replicationFactor=1'
对 solrcloud 做读写性能测试的 demo
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collection;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.CloudSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class SolrCloudTest {
public static final Log LOG = LogFactory.getLog(SolrCloudTest.class);
private static CloudSolrServer cloudSolrServer;
private static synchronized CloudSolrServer getCloudSolrServer(final String zkHost) {
LOG.info("connect to :"+zkHost+"\n");
if(cloudSolrServer == null) {
try {
cloudSolrServer = new CloudSolrServer(zkHost);
}catch(Exception e) {
e.printStackTrace();
}
}
return cloudSolrServer;
}
private void addIndex(SolrServer solrServer) {
try {
Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
for (int i = 0;i<=200;i++){
SolrInputDocument doc = new SolrInputDocument();
String key = "";
key = String.valueOf(i);
doc.addField("id", key);
doc.addField("test_s", key+"value");
docs.add(doc);
}
LOG.info("docs info:"+docs+"\n");
solrServer.add(docs);
solrServer.commit();
}catch(SolrServerException e) {
System.out.println("Add docs Exception !!!");
e.printStackTrace();
}catch(IOException e){
e.printStackTrace();
}catch (Exception e) {
System.out.println("Unknowned Exception!!!!!");
e.printStackTrace();
}
}
public void search(SolrServer solrServer, String Str) {
SolrQuery query = new SolrQuery();
query.setRows(20);
query.setQuery(Str);
try {
LOG.info("query string: "+ Str);
System.out.println("query string: "+ Str);
QueryResponse response = solrServer.query(query);
SolrDocumentList docs = response.getResults();
System.out.println(docs);
System.out.println(docs.size());
System.out.println("doc num:" + docs.getNumFound());
System.out.println("elapse time:" + response.getQTime());
for (SolrDocument doc : docs) {
String area = (String) doc.getFieldValue("test_s");
String id = (String) doc.getFieldValue("id");
System.out.println("id: " + id);
System.out.println("tt_s: " + area);
System.out.println();
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch(Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
final String zkHost = "192.168.0.2:8080";
final String defaultCollection = "userinfo";
final int zkClientTimeout = 10000;
final int zkConnectTimeout = 10000;
CloudSolrServer cloudSolrServer = getCloudSolrServer(zkHost);
cloudSolrServer.setDefaultCollection(defaultCollection);
cloudSolrServer.setZkClientTimeout(zkClientTimeout);
cloudSolrServer.setZkConnectTimeout(zkConnectTimeout);
try{
cloudSolrServer.connect();
System.out.println("connect solr cloud zk sucess");
} catch (Exception e){
LOG.error("connect to collection "+defaultCollection+" error\n");
System.out.println("error message is:"+e);
e.printStackTrace();
System.exit(1);
}
SolrCloudTest solrt = new SolrCloudTest();
try{
solrt.addIndex(cloudSolrServer);
} catch(Exception e){
e.printStackTrace();
}
solrt.search(cloudSolrServer, "id:*"); ;
cloudSolrServer.shutdown();
}
}
总结
最后为了快速部署,其实这个过程可以使用 fabric 来进行部署,这样就不用每次进行重复操作,把上面的步骤整理成 fabric 脚本即可,这样不管是搭建多少台服务器的集群,只要几分钟即可搞定。
SolrCloud 分布式集群部署步骤的更多相关文章
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- SolrCloud分布式集群部署步骤
Solr及SolrCloud简介 Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成 ...
- 170825、SolrCloud 分布式集群部署步骤
安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux 环境的 64位 软件,以上软件请到各自的 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- 基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势)
基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势) 前言 前几天对Apollo配置中心的demo进行一个部署试用,现公司已决定使用,这两天进行分布式部署的时候 ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- hadoop分布式集群部署①
Linux系统的安装和配置.(在VM虚拟机上) 一:安装虚拟机VMware Workstation 14 Pro 以上,虚拟机软件安装完成. 二:创建虚拟机. 三:安装CentOS系统 (1)上面步 ...
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
随机推荐
- bootstrap图标乱码问题-解决方案
楼主在使用bootstrap时,出现了图标乱码问题,经过多次查找,才解决了问题(最后发现真的是很好解决的问题(^^)) 如果出现乱码 请直接在自己写的CSS中重新引入一下font文件中的字体就好了 @ ...
- Windows开发小问题集
ON_BN_KILLFOCUS无效,因为需要BS_NOTIFY
- 挂载硬盘,提示 mount: unknown filesystem type 'LVM2_member'的解决方案
问题现象:由于重装linux,并且加了固态硬盘,直接将系统装在固态硬盘中.启动服务器的时候, 便看不到原来机械硬盘的挂载目录了,不知如何访问机械硬盘了.直接用命令 mount /dev/sda3 /s ...
- Go 时间相关
>获取当前时间: t := time.Now() >获取当天开始.结束时间: tm1 := time.Date(t.Year(), t.Month(), t.Day(), 0, 0, 0, ...
- js post一个对象 在C#中怎么接收? 未解决
这个在C#中怎么接收?
- Windows如何正确的修改administrator用户名
无论是服务器还是电脑.修改默认的administrator的用户总是好的.话不多少.直接上图 1.win+r 输入:gpedit.msc 2.按照我下图的圈圈找到重命名系统管理员账户并自定义 3.重 ...
- mt_rand()和rand()两者的区别
在随机读取中使用了mt_rand(),而不适用rand(),他们两者的区别: mt_rand()是更好地随机数生成器,因为它跟rand()相比播下了一个更好地随机数种子:而且性能上比rand()快4倍 ...
- 基于fpga的256m的SDRAM控制器
2018/7/26 受教于邓堪文老师,开始真真学习控制sdram 由于自己买的sdram模块是256的,原来老师的是128,所以边学边改,不知道最后好不好使,但是我有信心 一.sdram的初始化 sd ...
- 【Apache Kafka】一、Kafka简介及其基本原理
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如Flume),然后对于收集到的数据如何存储(典型的分布式文件系统HDFS.分布式数据库HBase.NoSQL数据库Redis),其次存储 ...
- Oracle query that count connections by minute with start and end times provided
数据结构类似 SQL> select * from t; B E N ----------------- ------------ ...