自然语言处理之word2vec
在word2vec出现之前,自然语言处理经常把字词转为one-hot编码类型的词向量,这种方式虽然非常简单易懂,但是数据稀疏性非常高,维度很多,很容易造成维度灾难,尤其是在深度学习中;其次这种词向量中任意两个词之间都是孤立的,存在语义鸿沟(这样就不能体现词与词之间的关系)而有Hinton大神提出的Distributional Representation 很好的解决了one-hot编码的主要缺点。解决了语义之间的鸿沟,可以通过计算向量之间的距离来体现词与词之间的关系。Distributional Representation 词向量是密集的。word2vec是一个用来训练Distributional Representation 类型的词向量的一种工具。
1、CBOW与Skip-Gram模型
word2vec模型其实就是简单化的神经网络,主要包含两种词训练模型:CBOW模型和Skip-gram模型。模型的结构图如下(注意:这里只是模型结构,并不是神经网络的结构)
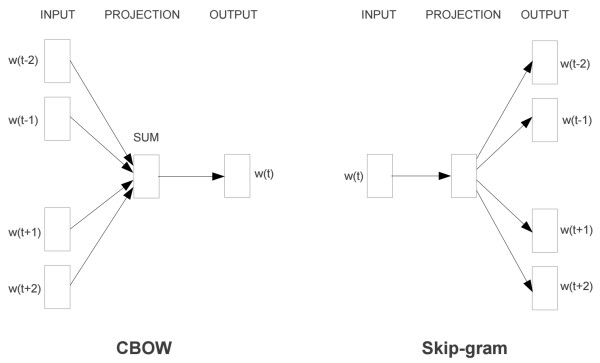
CBOW模型根据中心词W(t) 周围的词来预测中心词;Skip-gram模型则根据中心词W(t) 来预测周围的词。
1)CBOW模型的第一层是输入层,输入的值是周围每个词的one-hot编码形式,隐藏层只是对输出值做了权值加法,没有激活函数进行非线性的转换,输出值的维度和输入值的维度是一致的。
2)Skip-gram模型的第一层是输入层,输入值是中心词的one-hot编码形式,隐藏层只是做线性转换,输出的是输出值的softmax转换后的概率。
神经网络结构如下
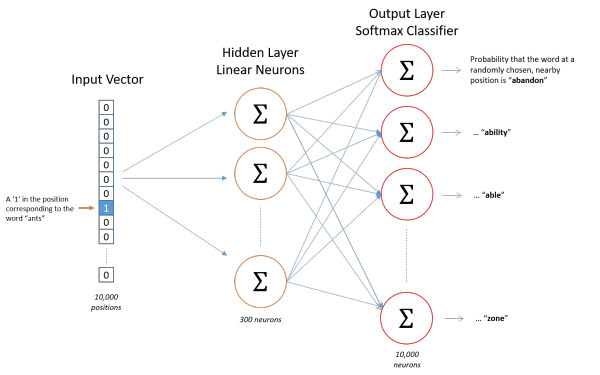
神经网络的训练是有监督的学习,因此要给定输入值和输出值来训练神经网络,而我们最终要获得的是隐藏层的权重矩阵。因为隐藏层的输出事实上是每个输入单词的 “嵌入词向量”。我们来看个图

上如中左边的式子是输入词向量和隐藏层权重矩阵的乘积,在做这个乘法时是不会进行矩阵的运算的,而是直接通过输入值中1的位置索引来寻找隐藏层中的权重矩阵中对应的索引的行。
词向量的两个优点:
1)降低输入的维度。词向量的维度一般取100-200,对于大样本时的one-hot向量甚至可能达到10000以上。
2)增加语义信息。两个语义相近的单词的词向量也是很相似的。
2、word2vec API讲解
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。算法需要注意的参数有:
1) sentences:我们要分析的语料,可以是一个列表,或者从文件中遍历读出(word2vec.LineSentence(filename) )。
2) size:词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
3) window:即词向量上下文最大距离,window越大,则和某一词较远的词也会产生上下文关系。默认值为5,在实际使用中,可以根据实际的需求来动态调整这个window的大小。
如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5;10]之间。
4) sg:即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型;是1则是Skip-Gram模型;默认是0即CBOW模型。
5) hs:即我们的word2vec两个解法的选择了。如果是0, 则是Negative Sampling;是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
6) negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
7) cbow_mean:仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示xw,默认值也是1,不推荐修改默认值。
8) min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
9) iter:随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
10) alpha:在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
11) min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。
对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
word2vec是可以进行增量式训练的,因此可以实现一:在输入输入值时可以将数据用生成器的形式导入到模型中;二:可以将数据一个磁盘中读取出来,然后训练完保存模型;之后加载模型再从其他的磁盘上读取数据进行模型的训练。初始化模型的相似度之后,模型就无法再进行增量式训练了,相当于锁定模型了。
3、三个最常见的应用
当训练完模型之后,我们就可以用模型来处理一些常见的问题了,主要包括以下三个方面:
1)找出某一个词向量最相近的集合
model.wv.similar_by_word()
从这里可以衍生出去寻找相似的句子,比如“北京下雨了”,可以先进行分词为{“北京”,“下雨了”},然后找出每个词的前5或者前10个相似的词,比如”北京“的前五个相似词是
{“上海”, “天津",”重庆“,”深圳“,”广州“}
"下雨了"的前五个相似词是
{”下雪了“,”刮风了“,”天晴了“,”阴天了“,”来台风了“}
然后将这两个集合随意组合,可以得到25组不同的组合,然后找到这25组中发生概率最大的句子输出。
2)查看两个词向量的相近程度
model.wv.similarity()
比如查看"北京"和”上海“之间的相似度
3)找出一组集合中不同的类别
model.wv.doesnt_match()
比如找出集合{“上海”, “天津",”重庆“,”深圳“,”北京“}中不同的类别,可能会输出”深圳“,当然也可能输出其他的
自然语言处理之word2vec的更多相关文章
- 基于skip-gram做推荐系统的想法
一.人工智能之自然语言处理 自然语言处理(Natural Language Processing, NLP),是人工智能的分支科学,意图是使计算机具备处理人类语言的能力. “处理人类语言的能力”要达到 ...
- unity--------------------四元数的旋转与原理
[Unity技巧]四元数(Quaternion)和旋转 原文:http://blog.csdn.net/candycat1992/article/details/41254799 四元数介绍 旋转,应 ...
- 论文解读(DeepWalk)《DeepWalk: Online Learning of Social Representations》
一.基本信息 论文题目:<DeepWalk: Online Learning of Social Representations>发表时间: KDD 2014论文作者: Bryan P ...
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 自然语言处理高手_相关资源_开源项目(比如:分词,word2vec等)
(1) 中科院自动化所的博士,用神经网络做自然语言处理:http://licstar.net (2) 分词项目:https://github.com/fxsjy/jieba(3) 清华大学搞的中文分词 ...
- word2vec 在 非 自然语言处理 (NLP) 领域的应用
word2vec 本来就是用来解决自然语言处理问题的,它在 NLP 中的应用是显然的. 比如,你可以直接用它来寻找相关词.发现新词.命名实体识别.信息索引.情感分析等:你也可以将词向量作为其他模型的输 ...
- 自然语言处理--Word2vec(二)
前一篇,word2vec(一)主要讲了word2vec一些表层概念,以及主要介绍CBOW方法来求解词向量模型,这里主要讲论文 Distributed Representations of Words ...
- 利用Tensorflow进行自然语言处理(NLP)系列之一Word2Vec
同步笔者CSDN博客(https://blog.csdn.net/qq_37608890/article/details/81513882). 一.概述 本文将要讨论NLP的一个重要话题:Word2V ...
- 自然语言处理工具:中文 word2vec 开源项目,教程,数据集
word2vec word2vec/glove/swivel binary file on chinese corpus word2vec: https://code.google.com/p/wor ...
随机推荐
- Golang 正则表达式Regex相关资料整理
Golang 支持的正在表达式是 https://github.com/google/re2/wiki/Syntax 注意这里提示 NOT SUPPORTED的。 工具 一些测试正则表达式的工具 推荐 ...
- SpringBoot 之Thymeleaf模板.
一.前言 Thymeleaf 的出现是为了取代 JSP,虽然 JSP 存在了很长时间,并在 Java Web 开发中无处不在,但是它也存在一些缺陷: 1.JSP 最明显的问题在于它看起来像HTML或X ...
- javascript中数组的常用算法深入分析
Array数组是Javascript构成的一个重要的部分,它可以用来存储字符串.对象.函数.Number,它是非常强大的.因此深入了解Array是前端必修的功课.本文将给大家详细介绍了javascri ...
- chartControl ViewType.Bar 用法测试
使用方法 一. Datatable : chartControl1.Series.Clear(); DataTable dt = new DataTable(); dt.Columns.Add(&qu ...
- CNN中,1X1卷积核到底有什么作用呢?
CNN中,1X1卷积核到底有什么作用呢? https://www.jianshu.com/p/ba51f8c6e348 Question: 从NIN 到Googlenet mrsa net 都是用了这 ...
- Mysql 常用数据类型
double:浮点型,double(5,2) 表示最多5位,必须包含两位小数,最大值是 999.99 char:定长字符串类型,char(10) 表示必须放 10 的字节,没有就用空格补充 varch ...
- Python笔记(十七):生成器
(一)生成器(Generator) Python生成器是创建迭代器的简单方法.简单来说,生成器是一个函数,它返回一个我们可以迭代的对象(迭代器)(一次一个值). 因为下面会用到列表生成式,这里先说明下 ...
- Spark SQL整体架构
0.整体架构 注意:Spark SQL是Spark Core之上的一个模块,所有SQL操作最终都通过Catalyst翻译成类似的Spark程序代码被Spark Core调度执行,其过程也有Job.St ...
- Cas 服务器 JDBC身份校验
之前的Cas服务器一直使用静态配置的账号密码进行身份认证,现在要让Cas服务器通过MySQL数据库中的用户信息进行身份认证. 一.添加数据库访问依赖 <!-- https://mvnreposi ...
- 探索SQL Server元数据(三):索引元数据
背景 在第一篇中我介绍了如何访问元数据,元数据为什么在数据库里面,以及如何使用元数据.介绍了如何查出各种数据库对象的在数据库里面的名字.第二篇,我选择了触发器的主题,因为它是一个能提供很好例子的数据库 ...