PHP 3种方法实现采集网站数据
什么叫采集?
就是使用PHP程序,把其他网站中的信息抓取到我们自己的数据库中、网站中。
PHP制作采集的技术:
从底层的socket到高层的文件操作函数,一共有3种方法可以实现采集。
1. 使用socket技术采集:
socket采集是最底层的,它只是建立了一个长连接,然后我们要自己构造http协议字符串去发送请求。
例如要想获取这个页面的内容,http://tv.youku.com/?spm=a2hww.20023042.topNav.5~1~3!2~A,用socket写如下:
- <?php
- //连接,$error错误编号,$errstr错误的字符串,30s是连接超时时间
- $fp=fsockopen("www.youku.com",80,$errno,$errstr,30);
- if(!$fp) die("连接失败".$errstr);
- //构造http协议字符串,因为socket编程是最底层的,它还没有使用http协议
- $http="GET /?spm=a2hww.20023042.topNav.5~1~3!2~A HTTP/1.1\r\n"; // \r\n表示前面的是一个命令
- $http.="Host:www.youku.com\r\n"; //请求的主机
- $http.="Connection:close\r\n\r\n"; // 连接关闭,最后一行要两个\r\n
- //发送这个字符串到服务器
- fwrite($fp,$http,strlen($http));
- //接收服务器返回的数据
- $data='';
- while (!feof($fp)) {
- $data.=fread($fp,4096); //fread读取返回的数据,一次读取4096字节
- }
- //关闭连接
- fclose($fp);
- var_dump($data);
- ?>
打印出的结果如下,包含了返回的头信息及页面的源码:

2. 使用curl_一套函数
curl把HTTP协议都封装成了很多函数,直接传相应参数即可,降低了编写HTTP协议字符串的难度。
前提:在php.ini中要开启curl扩展。
- //生成一个curl对象
- $curl=curl_init();
- //设置URL和相应的选项
- curl_setopt($curl, CURLOPT_URL, "http://www.youku.com");
- curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以字符串返回,而不是直接输出。
- //执行curl操作
- $data=curl_exec($curl);
- var_dump($data);
打印出的结果如下,只包含页面的源码:

3. 直接使用file_get_contents(最顶层的)
前提:在php.ini中设置允许打开一个网络的url地址。

- //使用file_get_contents()
- $data=file_get_contents("http://www.youku.com");
- var_dump($data);

3种方式的选择
网络之间通信主要使用的是以上三种。其中后两种用的较多:如果要批量采集大量的数据时使用第二种【CURL】,性能好、稳定。
偶尔发几个请求发的频繁不密集时使用第三种。
扩展:图片的防盗链如何破?
比如7060网站上的图片做了防盗链:在他的网站中可以看到图片,把图片拿到站外就无法访问。
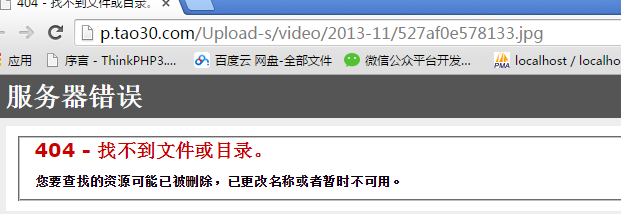
原理:在HTTP协议中有一个referer项,代表发这个请求的来源地址,服务器会判断如果这个请求不是这个网站发来的就会过滤掉这个请求:
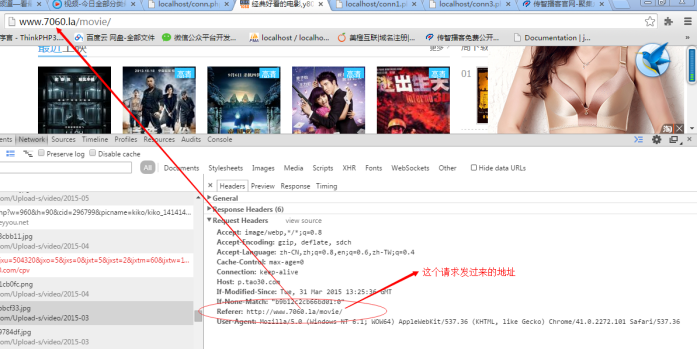
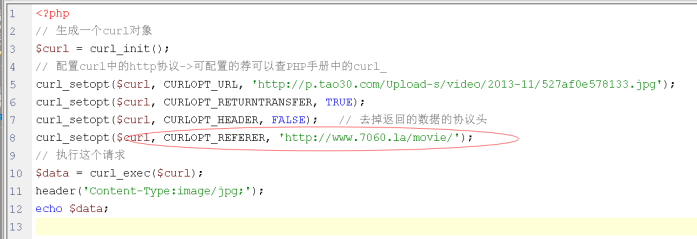
解决办法:发HTTP时自己模拟referer即可:
扩展:有些要采集数据时时必须先登录,可以使用模拟的试模拟在登录状态下的采集:
a. 先用浏览登录一下,登录完,浏览器的COOKIE中就会有SESSIONID
b. 发PHP发HTTP协议时,把浏览器中的SESSIONID放到PHP的HTTP协议请求里,这样就在以登录的状态发请求。
总结:所有客户端发过来的数据都可以被模拟,所以服务器上的程序必须要必要的地方过滤客户端的数据。
什么时候用以上东西?接口开发时、采集时。
二、数据采集
例如我要采集这个url里的所有美国电影的信息,
http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html
则先要知道电影所在的节点的结构,我们使用firebug查看。
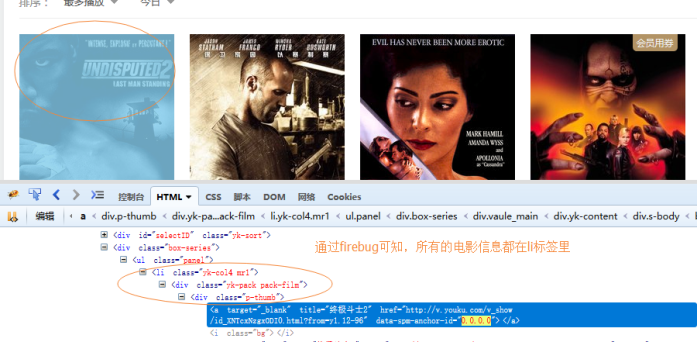
然后开始写代码:完整代码如下
- /**
- * 发一个GET请求获取数据
- */
- function get($url)
- {
- global $curl;
- // 配置curl中的http协议->可配置的荐可以查PHP手册中的curl_
- curl_setopt($curl, CURLOPT_URL, $url);
- curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE);
- curl_setopt($curl, CURLOPT_HEADER, FALSE);
- // 执行这个请求
- return curl_exec($curl);
- }
- // 生成一个curl对象
- $curl = curl_init();
- $url='http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html';
- $data=get($url);
- // 匹配电影所在位置
- $list_preg = '/<li class="yk-col4 mr1">.+<\/li>/Us';
- // 匹配img标签上的src和alt
- $img_preg = '/<img class="quic" _src="(.*)" src="(.*)" alt="(.*)" \/>/U';
- //匹配电影的url
- $video_preg='/<a href="(.*)" title="(.*)" target="(.*)"><\/a>/U';
- //把所有的li存到$list里,$list是个二维数组
- preg_match_all($list_preg,$data,$list);
- //var_dump($list);
- foreach ($list[0] as $k => $v) { //这里$v就是每一个li标签
- /* 获取图片及电影名称
- preg_match($img_preg,$v,$img); //把匹配到的图片的信息存到$img里
- var_dump($img);
- */
- /*获取电影地址
- preg_match($video_preg,$v,$video); //把匹配到的电影的信息存到$video里
- var_dump($video);
- */
- preg_match($img_preg,$v,$img);
- preg_match($video_preg,$v,$video);
- echo $img[0].'<a href="'.$video[1].'">'.$video[2].'</a>';
- }
测试:
打印$list;

打印$img

打印$video

最终效果:
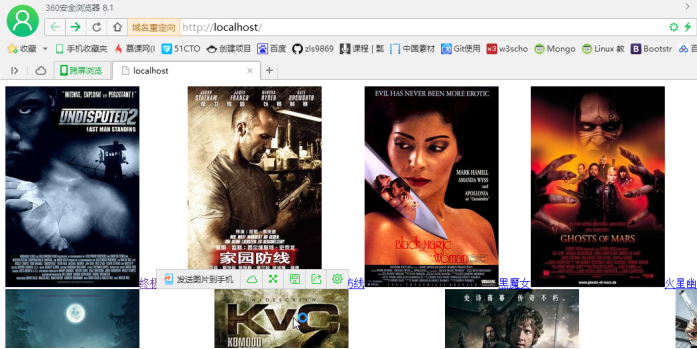
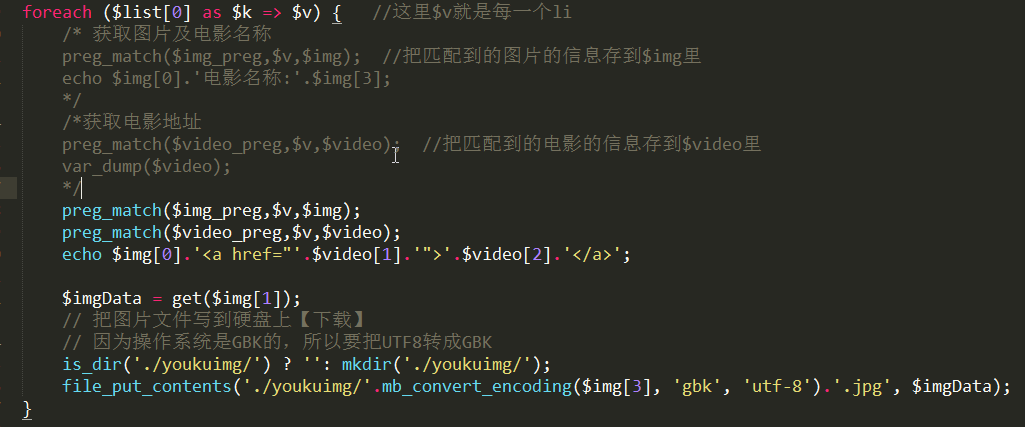
如果需要把图片拷贝到硬盘上,则在foreach循环里加上以下代码:
- $imgData = get($img[1]);
- // 把图片文件写到硬盘上【下载】
- // 因为操作系统是GBK的,所以要把UTF8转成GBK
- is_dir('./youkuimg/') ? '': mkdir('./youkuimg/');
- file_put_contents('./youkuimg/'.mb_convert_encoding($img[3], 'gbk', 'utf-8').'.jpg', $imgData);
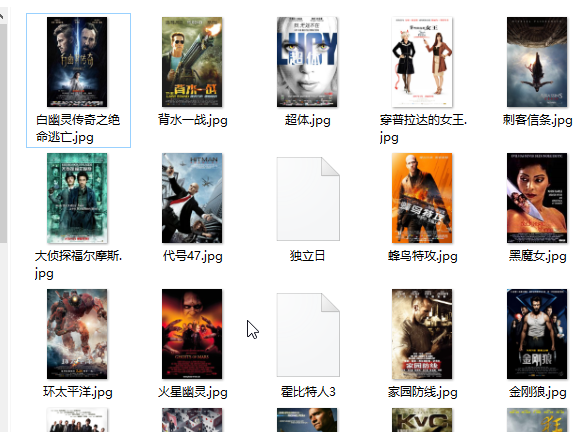
效果如下:在当前目录下的youkuimg目录下就会有下载好的图片。
PHP 3种方法实现采集网站数据的更多相关文章
- HTML5中两种方法实现客户端存储数据
HTML5 提供了两种在客户端存储数据的新方法: localStorage - 没有时间限制的数据存储 sessionStorage - 针对一个 session 的数据存储 之前,这些都是由 coo ...
- python爬虫采集网站数据
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- thinkphp实现采集功能的三种方法!
最近在做一些数据分析,由于上网找数据比较麻烦,所以写了一个采集网站数据的方法.具体方法如下: 方法一:QueryList 个人感觉比较好用,采集详情比较不错的选择,但是采集复杂一点的列表,不好用.具体 ...
- 用js采集网页数据并插入数据库最快的方法
今天教大家一个快速采集网站数据的方法,因为太晚了,直接上例子,这里以采集易车网的产品数据为例. 思路:利用js获取网页数据并生成sql命令,执行sql命令把采集的数据插入数据库. 1.用谷歌浏览器或者 ...
- 【转】asp.net导出数据到Excel的三种方法
来源:http://www.cnblogs.com/lishengpeng1982/archive/2008/04/03/1135490.html 原文出处:http://blog.csdn.net/ ...
- js清除浏览器缓存的几种方法
2014年9月24日 4692次浏览 关于浏览器缓存 浏览器缓存,有时候我们需要他,因为他可以提高网站性能和浏览器速度,提高网站性能.但是有时候我们又不得不清除缓存,因为缓存可能误事,出现一些错误的数 ...
- ASP.NET MVC上传文件的几种方法
1.Form表单提交 <p>Form提交</p> <form action="@Url.Action("SavePictureByForm" ...
- 31.网站数据监控-2(scrapy文件下载)
温州数据采集 这里采集网站数据是下载pdf:http://wzszjw.wenzhou.gov.cn/col/col1357901/index.html(涉及的问题就是scrapy 文件的下载设置,之 ...
- SQL Server中灾难时备份结尾日志(Tail of log)的两种方法
转自:http://www.cnblogs.com/CareySon/archive/2012/02/23/2365006.html SQL Server中灾难时备份结尾日志(Tail of log) ...
随机推荐
- <a>标签的特殊和文本的样式
a是特殊的,要改变a里面的颜色,必须直接给a设置,给a的父级设置不行 属性继承:明明是父级上的的设置样式,结果后代标签也跟着发生变化,这就叫做属性继承. Html 标记语言, 不是编程语言.说白了就是 ...
- Flask 系列之 Pagination
说明 操作系统:Windows 10 Python 版本:3.7x 虚拟环境管理器:virtualenv 代码编辑器:VS Code 实验目标 实现当前登录用户的事务浏览.添加.删除 操作 实现 首先 ...
- 3.类和接口_EJ
第13条: 使类和成员的可访问性最小化 良好的模块设计能隐藏其内部数据和其他实现细节,模块之间只通过它们的API进行通信.java语言提供了许多机制来协助隐藏信息.访问控制机制决定了类.接口和成员的可 ...
- linux 下修改mysql下root 权限来允许远程连接
MySQL默认只允许root帐户在本地登录,如果要在其它机器上连接mysql,必须修改root允许远程连接. 其操作简单,如下所示: 1. 进入mysql: /usr/local/mysql/bin/ ...
- angular post 带参数 导出excel
原文地址:http://www.cnblogs.com/xujanus/p/5985644.html html <button class="btn btn-info" ng ...
- canvas-9NonZeroAroundPrinciples2.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Html中的img标签 加载失败
在Http请求时,有时会遇到img图片标签加载失败,不显示的情况: 解决方法,在重新给src属性赋值时,先将onerror事件清除掉,再赋值,这样就不会存在循环调用问题了,代码如下; <img ...
- 【代码笔记】Web-JavaScript-JavaScript 条件语句
一,效果图. 二,代码. <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- [20180926]查询相似索引.txt
[20180926]查询相似索引.txt --//有时候在表上建立索引比如A,B字段,可能又建立B字段索引,甚至A字段索引以及B,A字段索引,或者还建立C,A字段索引,--//需要有1个脚本查询这些索 ...
- [20180914]oracle 12c 表 full_hash_value如何计算.txt
[20180914]oracle 12c 表 full_hash_value如何计算.txt --//昨天在12c下看表full_hash_value与11g的full_hash_value不同,不过 ...