高斯混合模型的EM算法
高斯混合模型的EM算法
混合高斯模型
高斯混合模型的概率分布可以写成多个高斯分布的线形叠加,即
\]
引入一个\(K\)维的二值随机变量\(\mathbf z\), 采用“\(1\)-of-\(K\)”编码,其中一个特定的元素\(z_k\)等于\(1\),其余所有的元素都等于\(0\)。 于是\(z_k\)的值满足\(z_k \in \{0, 1\}\)且\(\sum_k z_k = 1\),并且我们看到根据哪个元素非零,向量\(\mathbf z\)有\(K\)个可能的状态。\(\mathbf z\)的边缘概率分布可以根据混合系数\(\pi_k\)进行赋值,即
\]
其中参数\(\{\pi_k\}\)必须满足
\]
以及
\]
由于\(\mathbf z\)使用了“\(1\)-of-\(K\)”编码,也可以将这个概率分布写成
\]
对于\(\mathbf z\)给定的一个值, \(\mathbf x\)的条件概率分布是一个高斯分布
\]
类似的也可以写成
\]
\(\mathbf x\)的边缘概率分布可以通过将联合概率分布对所有可能的\(\mathbf z\)求和的方式得到,即
\]
于是我们找到了一个将隐变量\(\mathbf z\)显示写出的一个高斯混合分布等价公式。对联合概率分布\(p(\mathbf x, \mathbf z)\)而不是对\(p(\mathbf x)\)进行操作,会产生计算上极大的简化。
另一个有重要作用的量是给定\(\mathbf x\)的情况下,\(\mathbf z\)的后验概率\(p(\mathbf z\ |\ \mathbf x)\)。用\(\gamma(z_k)\)表示\(p(z_k=1\ |\ \mathbf x)\),其值可由贝叶斯定理给出
\gamma(z_k) = p(z_k=1\ |\ \mathbf x) &= \frac{p(z_k=1)p(\mathbf x\ |\ z_k=1)}{\sum_{j=1}^{K}p(z_j=1)p(\mathbf x\ |\ z_j=1)} \notag \\
&= \frac{\pi_k p(\mathbf x\ |\ z_k=1)}{\sum_{j=1}^{K}\pi_j p(\mathbf x\ |\ z_j=1)} \notag
\end{align}
\]
可以将\(\pi_k\)看成是\(z_k=1\)的先验概率,将\(\gamma(z_k)\)看成是观测到\(\mathbf x\)之后,对应的后验概率。
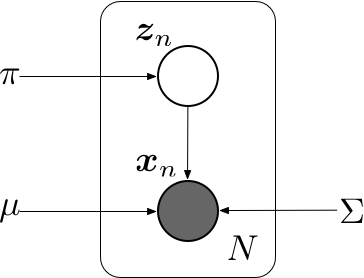
假设我们有观测数据集\(\{\mathbf x_1, \mathbf x_2, \ldots, \mathbf x_N\}\),我们希望使用混合高斯来对数据建模。可以将这个数据集标示为\(N\times D\)的矩阵\(\mathbf X\),其中第\(n\)行为\(\mathbf x_n^\top\)。类似的,对应的隐变量被表示为一个\(N\times K\)的矩阵\(\mathbf Z\),它的行为\(\mathbf z_n^\top\),可以使用上图所示的图模型来表示独立同分布数据集的高斯混合模型。\(\mathbf X\)的对数似然函数为
\]
最大化高斯混合模型的对数似然函数比单一的高斯分布的情形更加复杂。因为对\(k\)的求和出现在了对数内部;如果令导数等于零,不会得到一个解析解。
使用基于梯度的优化方法可以得到解,但现在考虑另一种可行方法,称为EM算法。
EM 算法
期望最大化算法,也叫EM算法,是寻找潜在变量的概率模型的最大似然解的一种通用方法。考虑一个概率模型,其中所有的观测变量记作\(\mathbf X\),所有隐含变量记作\(\mathbf Z\)。联合概率分布\(p(\mathbf X, \mathbf Z\ |\ \mathbf \theta)\)由一组参数$\mathbf \theta $控制,目标是最大化似然函数
\]
这里,假设\(\mathbf Z\)是离散的。直接优化\(p(\mathbf X\ |\ \mathbf\theta)\)比较困难,但是最优化完整数据似然函数\(p(\mathbf X, \mathbf Z\ |\ \mathbf \theta)\)就容易得很多。接下来,引入一个定义在隐变量\(\mathbf Z\)上的分布\(p(\mathbf Z)\)。对任意\(p(\mathbf Z)\),如下分解成立
\]
其中
\]
\]
\(\mathcal L(q, \mathbf\theta)\)是概率分布\(q(\mathbf Z)\)的一个范函,并且是一个参数\(\mathbf\theta\)的函数。因为\(\mathrm{KL}(p\ \|\ q) \geqslant 0\),当且仅当\(q(\mathbf Z) = p(\mathbf Z\ |\ \mathbf X, \mathbf\theta)\)时取得等号。因此,\(\mathcal L(q, \mathbf\theta) \leqslant \log p(\mathbf X\ |\ \mathbf\theta)\),即\(\mathcal L(q, \mathbf\theta)\)是\(\log p(\mathbf X\ |\ \mathbf\theta)\)是的一个下界。
EM算法是一个两阶段迭代优化算法。
假设当前的参数\(\mathbf\theta^{\mathrm{old}}\),在E步骤中,下界\(\mathcal L(q, \mathbf\theta^{\mathrm{old}})\)关于\(q(\mathbf Z)\)最大化,而\(\mathbf\theta^{\mathrm{old}}\)保持固定。当KL散度为零时,即得到了最大化的解。换句话说,最大值出现在\(q(\mathbf Z)\)与后验概率分布\(p(\mathbf Z\ |\ \mathbf X, \mathbf\theta)\)相等时,KL散度等于零,此时,下界等于最大似然函数。
在接下来的M步骤中,分布\(q(\mathbf Z)\)保持固定,下界\(\mathcal L(q, \mathbf\theta)\)关于\(\mathbf\theta\)最大化,得到了某个新的值\(\mathbf\theta^{\mathrm{new}}\),这会使得下界\(\mathcal L\)增大。同时也会使得对数似然增大,因为概率分布\(q\)由旧的参数值确定,并且在M步骤保持固定,因此不会等于新的后验分布\(p(\mathbf Z\ |\ \mathbf X,\mathbf\theta^{\mathrm{new}})\),从而KL散度非零;而且对数似然的增加量大于下界\(\mathcal L(q, \mathbf\theta)\)的增加量。在E步骤之后,下界的形式为
\mathcal L(q, \mathbf\theta) &= \sum_{\mathbf Z}p(\mathbf Z\ |\ \mathbf X, \mathbf\theta^{\mathrm{old}})\log p(\mathbf X, \mathbf Z\ |\ \mathbf\theta) \notag \\
& \ \ \ \ - \sum_{\mathbf Z}p(\mathbf Z\ |\ \mathbf X,\mathbf\theta^{\mathrm{old}})\log p(\mathbf Z\ |\ \mathbf X, \mathbf\theta^{\mathrm{old}}) \notag \notag \\
&= \mathcal Q(\mathbf\theta, \mathbf\theta^{\mathrm{old}}) + \text{常数} \notag
\end{align}
\]
其中常数是\(q\)的熵,与\(\mathbf \theta\)无关。从而,在M步骤中,最大化的量是完整数据对数似然函数的期望。完整的EM算法如下所示
Algorithm1: 用于含有隐变量最大似然函数参数估计的EM算法
- 选择参数的初始值 \(\mathbf\theta^{(t)}, t = 0\)
- REPEAT:
- E步骤: 计算\(p(\mathbf Z\ |\ \mathbf X, \mathbf\theta^{(t)})\)
- M步骤: 计算\(\mathbf\theta^{(t+1)}\),由下式给出
\]
其中
\]
- UNTIL: 对数似然函数收敛或者参数值收敛
高斯混合模型的EM算法
现在考虑将EM算法的隐变量观点用于一个具体的例子,即高斯混合模型。我们的目标是最大化对数似然函数\(\log p(\mathbf X\ |\ \mathbf \pi, \mathbf \mu, \mathbf \Sigma)\)这是使用观测数据集\(\mathbf X\)计算的。这种情况比单一的高斯困难,因为求和出现在了对数运算内部。假设除了观测数据集\(\mathbf X\),还有对应的离散变量\(\mathbf Z\)。现在考虑对完整数据\(\{\mathbf X, \mathbf Z\}\)最大化。完整数据集的似然函数的形式为
\]
其中\(z_{nk}\)表示\(\mathbf z_n\)的第\(k\)个分量。取对数,有
\]
现在将完全数据的对数似然对\(\mathbf Z\)的后验概率分布求期望。后验概率分布为
\]
在这个分布下, \(z_{nk}\)的期望为
\mathbb E_{\mathbf Z}[z_{nk}] & = \sum_{\mathbf z_1}\cdots\sum_{\mathbf z_N} z_{nk}p(\mathbf Z\ |\ \mathbf X, \mathbf \theta) \notag \\
& = \sum_{\mathbf z_1}p(\mathbf z_1\ |\ \mathbf x_n, \mathbf\theta) \cdots \sum_{\mathbf z_n}z_{nk}p(\mathbf z_n\ |\ \mathbf x_n, \mathbf\theta) \cdots \sum_{\mathbf z_N}p(\mathbf z_N\ |\ \mathbf x_n, \mathbf\theta) \notag \\
& = \sum_{\mathbf z_n}z_{nk}p(\mathbf z_n\ |\ \mathbf x_n, \mathbf\theta) \notag \\
& = p(z_{nk} = 1\ |\ \mathbf x_n, \mathbf\theta) \notag
\end{align}
\]
其中\(\mathbf\theta = (\mathbf\mu, \mathbf\Sigma, \mathbf\pi)\)。利用贝叶斯公式,有
p(z_{nk}=1\ |\ \mathbf x_n, \mathbf\theta) &= \frac{p(z_{nk}=1)p(\mathbf x_n\ |\ z_{nk}=1)}{\sum_{j=1}^{K}p(z_{nj}=1)p(\mathbf x_n \ |\ z_{nj}=1)} \notag \\
& = \frac{\pi_k \mathcal N(\mathbf x_n\ |\ \mathbf\mu_k, \mathbf\Sigma_k)}{\sum_{j=1}^{K}\pi_j\mathcal N(\mathbf x_n\ |\ \mathbf\mu_j, \mathbf\Sigma_j)}\notag \\
& \equiv \gamma(z_{nk}) \notag
\end{align}
\]
\(\gamma(z_{nk})\)被定义为数据点\(\mathbf x_n\)种含有来自于第\(k\)个高斯分布的“成分”。
于是,完整数据的对数似然的期望值为
\]
我们使用旧的参数\(\left\{ \mathbf\mu^{\mathrm{old}}, \mathbf\Sigma^{\mathrm{old}}, \mathbf\pi^{\mathrm{old}} \right\}\)计算\(\gamma(z_{nk})\)(E步骤);之后保持\(\gamma(z_{nk})\)不变,关于\(\mathbf \mu_k\),$ \mathbf\Sigma_k$, \(\pi_k\)最大化(M步骤),得到新的\(\left\{ \mathbf\mu^{\mathrm{new}}, \mathbf\Sigma^{\mathrm{new}}, \mathbf\pi^{\mathrm{new}} \right\}\)。
在进行M步骤之前,需要先参考一些关于矩阵求导数的运算,具体如下
\]
\]
\]
现在关于\(\pi_k\)最大化。注意到由于\(\sum_{k=1}^{K}\pi_k=1\)的限制,可以使用拉格朗日乘数法进行优化。构造拉格朗日函数为
\]
对\(\pi_k\)求导,并令其等于零,有
\]
又由\(\sum_{k=1}^{K}\pi_k=1\),得出\(\lambda=N\),所以更新后的\(\pi_k\)为
\]
其中\(N_k = \sum_{n=1}^N\gamma(z_{nk})\)。
关于\(\mathbf\mu_k\)最大化。注意到,完整数据的对数似然中包含\(\mathbf\mu_k\)的项是
& \sum_{n=1}^{N}\gamma(z_{nk})\log\mathcal N(\mathbf x_n\ |\ \mathbf\mu_k, \mathbf\Sigma_k) \notag \\
& = \sum_{n=1}^{N}\gamma(z_{nk})\left\{-\frac{D}{2}\log(2\pi) + \frac{1}{2}\log|\mathbf\Sigma_k^{-1}| -\frac{1}{2} (\mathbf x_n-\mathbf \mu_k)^\top\mathbf\Sigma_k^{-1}\mathbf(\mathbf x_k-\mathbf\mu_k)\right\} \notag
\end{align}
\]
对\(\mathbf\mu_k\)求导,并令其等于零,得
\]
化简
\]
两边同乘\(\mathbf\Sigma_k\),得
\]
所以,得到新的\(\mathbf \mu_k^{\mathrm{new}}\)为
\]
关于\(\mathbf\Sigma_k\)最大化。将完整数据对数似然关于\(\mathbf Z\)后验概率的期望关于\(\mathbf\Sigma_k^{-1}\)求导,并令其导数等于零。具体过程如下
\mathbf\Sigma_k & = \frac{1}{N_k}\frac{\partial}{\partial \mathbf\Sigma_k^{-1}}\mathrm{Tr}\left(\mathbf\Sigma_k^{-1}\sum_{n=1}^N\gamma(z_{nk})(\mathbf x_n-\mathbf \mu_k)(\mathbf x_n-\mathbf\mu_k)^\top\right) \notag \\
& = \frac{1}{N_k}\sum_{n=1}^N\gamma(z_{nk})(\mathbf x_n-\mathbf \mu_k)(\mathbf x_n-\mathbf\mu_k)^\top \notag
\end{align}
\]
所以,新的\(\mathbf\Sigma_k^{\mathrm{new}} = \frac{1}{N_k}\sum_{n=1}^N\gamma(z_{nk})(\mathbf x_n-\mathbf \mu_k^{\mathrm{new}})(\mathbf x_n-\mathbf\mu_k^{\mathrm{new}})^\top\)。
总结一下,高斯混合分布的参数估计如下
- 初始化均值\(\mathbf \mu_k\),协方差\(\mathbf \Sigma_k\)和混合系数\(\mathbf\pi_k\),计算对数似然的初始值
- E步骤 使用当前参数,计算每个数据点的成分\(\gamma(z_{nk})\)
\[ \gamma(z_{nk}) = \frac{\pi_k\mathcal N(\mathbf x_n\ |\ \mathbf\mu_k,\mathbf\Sigma_k)}{\sum_{j=1}^K\pi_j\mathcal N(\mathbf x_n\ |\ \mathbf\mu_j,\mathbf\Sigma_j)}
\] - M步骤 使用当前的\(\gamma(z_{nk})\)重新估计参数。
\]
\]
\]
其中
\]
- 计算对数似然函数
\]
- 检查参数或者对数似然函数的收敛性。若没有满足收敛条件,返回E步骤。
实验
使用python模拟混合高斯分布的参数估计。混合高斯分布也可以用来聚类,与K-Means相比,可以实现软聚类,即可以计算出给定数据点\(\mathbf x_n\)属于第\(k\)个聚类的成分:\(\gamma(z_{nk})\)
导入必要的软件包
import matplotlib.pyplot as plt
import numpy as np
from numpy.linalg import inv, det
定义高斯分布以及高斯混合分布
# 多维高斯分布
def gaussion(x, mu, Sigma):
dim = len(x)
constant = (2*np.pi)**(-dim/2) * det(Sigma)**(-0.5)
return constant * np.exp(-0.5*(x-mu).dot(inv(Sigma)).dot(x-mu))
# 高斯混合分布
def gaussion_mixture(x, Pi, mu, Sigma):
z = 0
for idx in range(len(Pi)):
z += Pi[idx]* gaussion(x, mu[idx], Sigma[idx])
return z
定义数据集生成函数(手动模拟数据集),从三个高斯分布中采样
# 权重
Pi = np.array([ 0.3, 0.3, 0.4 ])
# 均值
mu = np.array([
[-6, 3],
[3, 6],
[0, -6]
])
# 协方差矩阵
Sigma = np.array([
[[4,0], [0,4]],
[[4,1], [1,4]],
[[6,2], [2,6]]
])
def sampling(Pi, mean, cov, N):
samples = np.array([])
for idx in range(len(Pi)):
_sample = np.random.multivariate_normal(mean[idx], cov[idx], int(N*Pi[idx]))
samples = np.append(samples, _sample)
return samples.reshape((-1, mean[0].shape[0]))
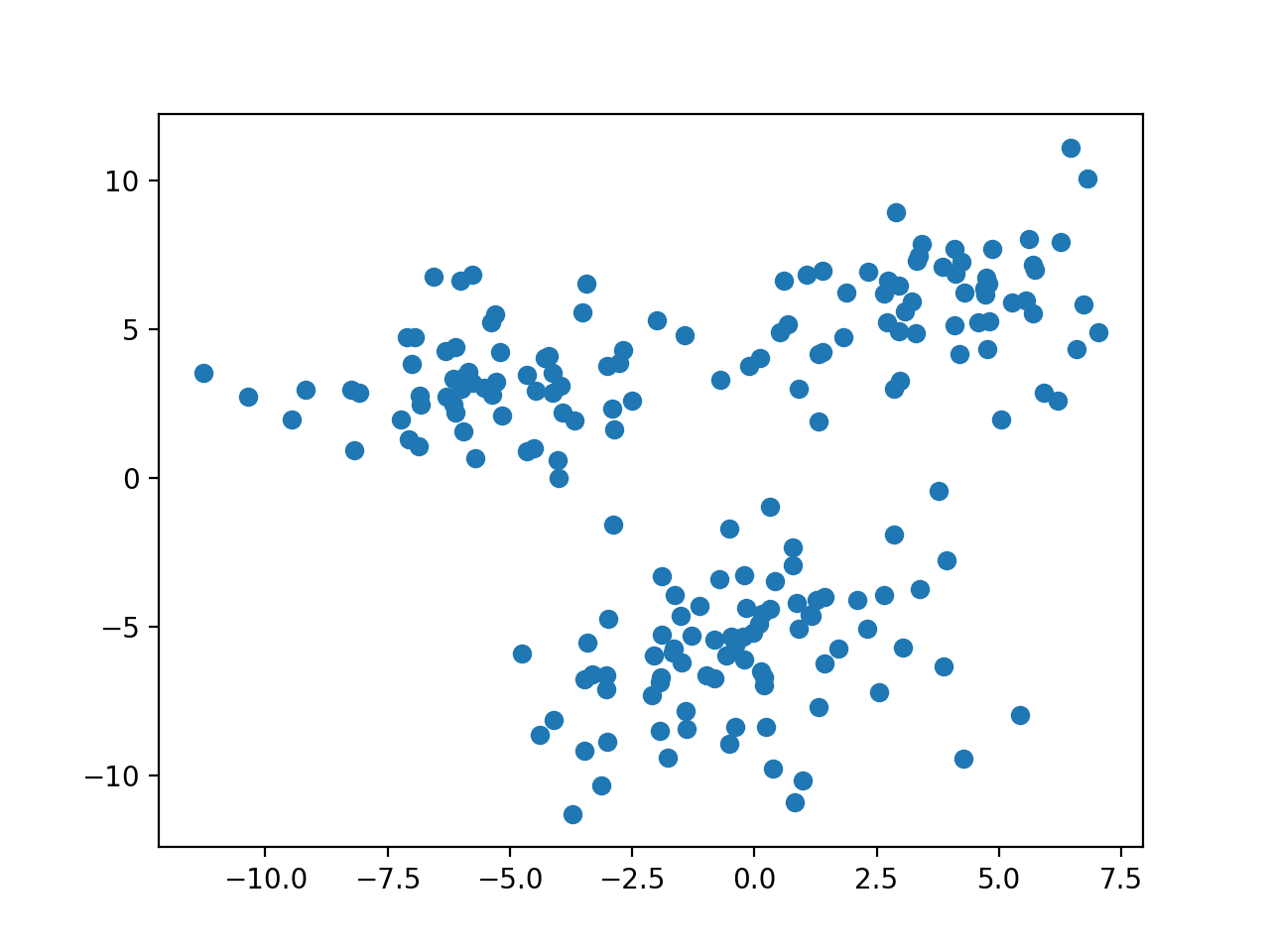
数据分布如下图
绘制高斯分布等高线图,用来展示拟合的高斯分布
# 绘制混合高斯分布等高线图
def plot_gaussion(Pi, mu, Sigma):
x = np.linspace(-10, 10, 100)
y = np.linspace(-10, 10, 100)
x, y = np.meshgrid(x, y)
X = np.array([x.ravel(), y.ravel()]).T
z = [ gaussion_mixture(x, Pi, mu, Sigma) for x in X ]
z = np.array(z).reshape(x.shape)
return plt.contour(x, y, z)
定义EM算法的一次迭代过程
def EM_step(X, Pi, mu, Sigma):
N = len(X); K = len(Pi)
gamma = np.zeros((N, K))
# E-step
for n in range(N):
p_xn = 0
for k in range(K):
t = Pi[k]*gaussion(X[n], mu[k], Sigma[k])
p_xn += t
gamma[n, k] = t
gamma[n] /= p_xn
# M-step
for k in range(K):
_mu = np.zeros(mu[k].shape)
_Sigma = np.zeros(Sigma[k].shape)
N_k = np.sum(gamma[:,k])
# 更新均值
for n in range(N):
_mu += gamma[n,k]*X[n]
mu[k] = _mu / N_k
# 更新方差
for n in range(N):
delta = np.matrix(X[n]- mu[k]).T
_Sigma += gamma[n, k]*np.array( delta.dot(delta.T) )
Sigma[k] = _Sigma / N_k
# 更新权重
Pi[k] = N_k / N
return Pi, mu, Sigma
开始EM算法迭代过程,并显示每次迭代过程
if __name__ == '__main__':
# 参数初始值
_Pi = np.array([
0.33,
0.33,
0.34
])
_mu = np.array([
[0, -1],
[1, 0],
[-1, 0]
])
_Sigma = np.array([
[[1,0], [0,1]],
[[1,0], [0,1]],
[[1,0], [0,1]]
])
n_iter = 3
samples = sampling(Pi, mu, Sigma, 200)
# 绘制初始状态
plt.subplot(2, 2, 1)
plt.title('Initialization')
plt.scatter(*samples.T)
plot_gaussion(_Pi, _mu, _Sigma)
for i in range(n_iter):
# EM算法迭代
_Pi, _mu, _Sigma = EM_step(samples, _Pi, _mu, _Sigma)
# 绘制每轮迭代结果
plt.subplot(2, 2, i+2)
plt.title('Iteration = $%d$' % (i+1))
plt.scatter(*samples.T)
plot_gaussion(_Pi, _mu, _Sigma)
plt.show()
实验结果
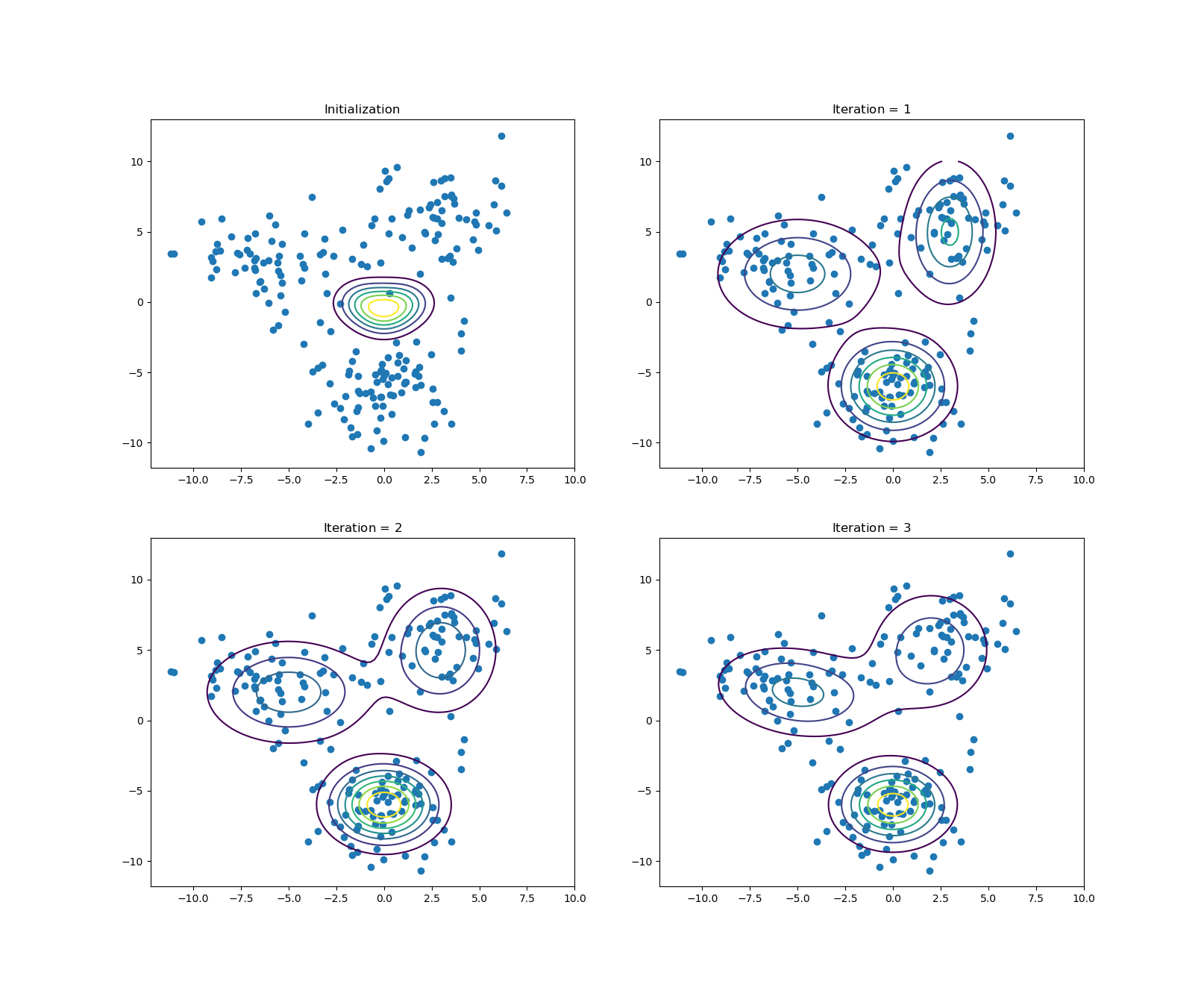
选取隐变量\(\mathbf z\)的状态有三种,经过\(3\)轮迭代之后的实验结果如下图:
高斯混合模型的EM算法的更多相关文章
- SIGAI机器学习第二十三集 高斯混合模型与EM算法
讲授高斯混合模型的基本概念,训练算法面临的问题,EM算法的核心思想,算法的实现,实际应用. 大纲: 高斯混合模型简介实际例子训练算法面临的困难EM算法应用-视频背景建模总结 高斯混合模型简写GMM,期 ...
- 高斯混合模型与EM算法
对于高斯混合模型是干什么的呢?它解决什么样的问题呢?它常用在非监督学习中,意思就是我们的训练样本集合只有数据,没有标签. 它用来解决这样的问题:我们有一堆的训练样本,这些样本可以一共分为K类,用z(i ...
- 机器学习基础知识笔记(一)-- 极大似然估计、高斯混合模型与EM算法
似然函数 常说的概率是指给定参数后,预测即将发生的事件的可能性.拿硬币这个例子来说,我们已知一枚均匀硬币的正反面概率分别是0.5,要预测抛两次硬币,硬币都朝上的概率: H代表Head,表示头朝上 p( ...
- 机器学习 : 高斯混合模型及EM算法
Mixtures of Gaussian 这一讲,我们讨论利用EM (Expectation-Maximization)做概率密度的估计.假设我们有一组训练样本x(1),x(2),...x(m),因为 ...
- 聚类之高斯混合模型与EM算法
一.高斯混合模型概述 1.公式 高斯混合模型是指具有如下形式的概率分布模型: 其中,αk≥0,且∑αk=1,是每一个高斯分布的权重.Ø(y|θk)是第k个高斯分布的概率密度,被称为第k个分模型,参数为 ...
- 机器学习之高斯混合模型及EM算法
第一部分: 这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类 ...
- 高斯混合和EM算法
首先介绍高斯混合模型: 高斯混合模型是指具有以下形式的概率分布模型: 一般其他分布的混合模型用相应的概率密度代替(1)式中的高斯分布密度即可. 给定训练集,我们希望构建该数据联合分布 这里,其中是概率 ...
- 混合高斯模型和EM算法
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类别标签用表示 ...
- 统计学习方法c++实现之八 EM算法与高斯混合模型
EM算法与高斯混合模型 前言 EM算法是一种用于含有隐变量的概率模型参数的极大似然估计的迭代算法.如果给定的概率模型的变量都是可观测变量,那么给定观测数据后,就可以根据极大似然估计来求出模型的参数,比 ...
随机推荐
- Django系列之web应用与http协议
第一节:最简单的web应用程序 web应用程序指供浏览器访问的程序,通常也简称为web应用.应用程序有两种模式C/S,B/S.C/S是客户端/服务器程序.也就是说这类程序一般独立运行.而B/S就是浏览 ...
- 认识border
标签(空格分隔): border border的认识: border:边框的意思,描述盒子的边框,边框有三个要素: 粗细, 线性样式 ,颜色: <!DOCTYPE html> <ht ...
- Presto集群部署和配置
参考文档:1.https://blog.csdn.net/zzq900503/article/details/79403949 prosto部署与连接hive使用 2. ...
- 【练习】Python第三次
对函数,内置函数的用法,递归,程序运行顺序的考试 1.列举布尔值为 False 的值 0 False '' [] () {} None 经常使用的场景是 if object 如果object有值就执行 ...
- PhoenixFD插件流体模拟——UI布局【Dynamics】详解
流体动力学 本文主要讲解Dynamics折叠栏中的内容.原文地址:https://docs.chaosgroup.com/display/PHX3MAX/Liquid+Dynamics 主要内容 Ov ...
- 内网主机使用yum安装软件
经常遇到这样的情况:有一台内网linux主机需要安装软件,但是主机又无法连接外网,通常情况下可以使用rpm包或者使用源码编译安装.但常常会遇到依赖缺少的情况,这就麻烦了,要一一找到缺少的软件包. 这种 ...
- nginx多域名、多证书
环境: 一台nginx服务器 192.168.10.251 两台windowsserver2012 IIS服务器 (192.168.10.252.192.168.10.253) 从阿里云上下载ssl证 ...
- vue踩坑(二):跨域以及携带cookie
最近后台需求要在请求的时候传cooki给后台,正常情况下拿到cookie后存在cookie里,同域名下是会自己带到请求头里的,但是因为要在本地调试,那么问题就来了,localhost:8080下面的c ...
- Ubuntu16.04 藍牙連上,但是聲音裏面找不到設備
解決辦法: 1. sudo apt-get install blueman bluez* 2. sudo vim /etc/pulse/default.pa 注釋掉下面的代碼: #.ifexists ...
- POJ-1860.CurrencyExchange(Spfa判断负环模版题)
本题思路:每完成一次交换之后交换余额多于原钱数则存在正环,输出YES即可. 参考代码: #include <cstdio> #include <cstring> #includ ...