【原创】大数据基础之Presto(1)简介、安装、使用
presto 0.217

官方:http://prestodb.github.io/
一 简介
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses while scaling to the size of organizations like Facebook.
presto是一个开源的分布式sql查询引擎,用于大规模(从GB到PB)数据源的交互式分析查询,并且达到商业数据仓库的查询速度;
Presto allows querying data where it lives, including Hive, Cassandra, relational databases or even proprietary data stores. A single Presto query can combine data from multiple sources, allowing for analytics across your entire organization.
Presto is targeted at analysts who expect response times ranging from sub-second to minutes. Presto breaks the false choice between having fast analytics using an expensive commercial solution or using a slow "free" solution that requires excessive hardware.
presto允许直接查询外部数据,包括hive、cassandra、rdbms以及文件系统比如hdfs;一个presto查询中可以同时使用多个数据源的数据来得到结果;presto在‘昂贵且快的商业解决方案’和‘免费且慢的开源解决方案’之间提供了一个新的选择;
Facebook uses Presto for interactive queries against several internal data stores, including their 300PB data warehouse. Over 1,000 Facebook employees use Presto daily to run more than 30,000 queries that in total scan over a petabyte each per day.
facebook使用presto来进行多个内部数据源的交互式查询,包括300PB的数据仓库;每天有超过1000个facebook员工在PB级数据上使用presto运行超过30000个查询;
Leading internet companies including Airbnb and Dropbox are using Presto.
业界领先的互联网公司包括airbnb和dropbox都在使用presto,下面是airbnb的评价:
Presto is amazing. Lead engineer Andy Kramolisch got it into production in just a few days. It's an order of magnitude faster than Hive in most our use cases. It reads directly from HDFS, so unlike Redshift, there isn't a lot of ETL before you can use it. It just works.
--Christopher Gutierrez, Manager of Online Analytics, Airbnb
架构
Presto is a distributed system that runs on a cluster of machines. A full installation includes a coordinator and multiple workers. Queries are submitted from a client such as the Presto CLI to the coordinator. The coordinator parses, analyzes and plans the query execution, then distributes the processing to the workers.
presto是一个运行在集群上的分布式系统,包括一个coordinator和多个worker,client(比如presto cli)提交查询到coordinator,然后coordinator解析、分析和计划查询如何执行,然后将任务分配给worker;
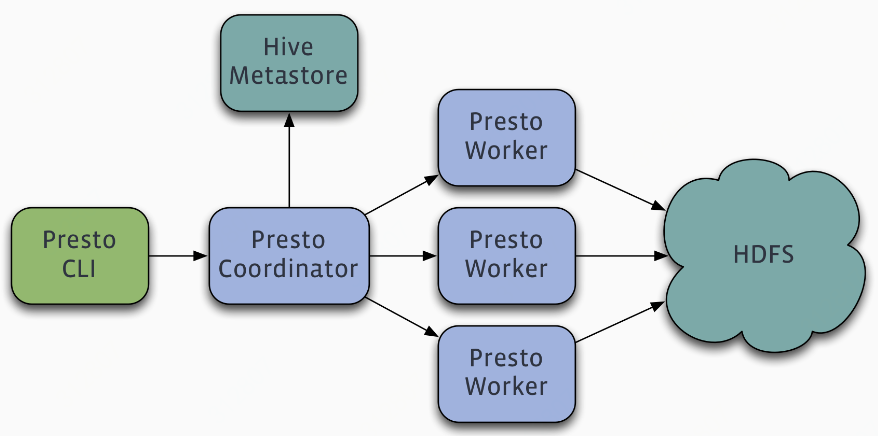
Presto supports pluggable connectors that provide data for queries. The requirements vary by connector.
presto提供插件化的connector来支持外部数据查询,原生支持hive、cassandra、elasticsearch、kafka、kudu、mongodb、mysql、redis等众多外部数据源;
详细参考:https://prestodb.github.io/docs/current/connector.html
二 安装
1 下载
# wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.217/presto-server-0.217.tar.gz
# tar xvf presto-server-0.217.tar.gz
# cd presto-server-0.217
2 准备数据目录
Presto needs a data directory for storing logs, etc. We recommend creating a data directory outside of the installation directory, which allows it to be easily preserved when upgrading Presto.
3 准备配置目录
Create an etc directory inside the installation directory. This will hold the following configuration:
- Node Properties: environmental configuration specific to each node
- JVM Config: command line options for the Java Virtual Machine
- Config Properties: configuration for the Presto server
- Catalog Properties: configuration for Connectors (data sources)
# mkdir etc # cat etc/node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/presto/data # cat etc/jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError # cat etc/config.properties # coordinator
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://example.net:8080 # worker
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery.uri=http://example.net:8080 # cat etc/log.properties
com.facebook.presto=INFO
注意:
1)coordinator和worker的config.properties不同,主要是coordinator上会开启discovery服务
discovery-server.enabled: Presto uses the Discovery service to find all the nodes in the cluster. Every Presto instance will register itself with the Discovery service on startup. In order to simplify deployment and avoid running an additional service, the Presto coordinator can run an embedded version of the Discovery service. It shares the HTTP server with Presto and thus uses the same port.
2)如果coordinator和worker位于不同机器,则设置
node-scheduler.include-coordinator=false
如果coordinator和worker位于相同机器,则设置
node-scheduler.include-coordinator=true
node-scheduler.include-coordinator: Allow scheduling work on the coordinator. For larger clusters, processing work on the coordinator can impact query performance because the machine’s resources are not available for the critical task of scheduling, managing and monitoring query execution.
更多参数:https://prestodb.github.io/docs/current/admin/properties.html
4 配置connector
Presto accesses data via connectors, which are mounted in catalogs. The connector provides all of the schemas and tables inside of the catalog. For example, the Hive connector maps each Hive database to a schema, so if the Hive connector is mounted as the hive catalog, and Hive contains a table clicks in database web, that table would be accessed in Presto as hive.web.clicks.
以hive为例
# mkdir etc/catalog # cat etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://example.net:9083
#hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
详细参考:https://prestodb.github.io/docs/current/connector.html
5 启动
调试启动
# bin/launcher run --verbose
Presto requires Java 8u151+ (found 1.8.0_141)
需要jdk1.8.151以上
正常之后,后台启动
# bin/launcher start
三 使用
1 下载cli
# wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.217/presto-cli-0.217-executable.jar
# mv presto-cli-0.217-executable.jar presto
# chmod +x presto
# ./presto --server localhost:8080 --catalog hive --schema default
presto> show schemas;
默认的分页是less,输入q退出
2 jdbc
# wget https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.217/presto-jdbc-0.217.jar
# export HIVE_AUX_JARS_PATH=/path/to/presto-jdbc-0.217.jar
# beeline -d com.facebook.presto.jdbc.PrestoDriver -u jdbc:presto://example.net:8080/hive/sales -n hadoop
jdbc url格式:
jdbc:presto://host:port/catalog/schema
问题
1 查询parquet格式数据报错:
Query 20190314_072428_00009_enu46 failed: Corrupted statistics for column "[test_column] BINARY" in Parquet file ...
On version 0.216 presto incorrectly assumes that a binary column statistic is corrupt due to wrong ordering of accented values.
可先将版本降到0.215
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.215/presto-server-0.215.tar.gz
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.215/presto-cli-0.215-executable.jar
https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.215/presto-jdbc-0.215.jar
详细参考:https://github.com/prestodb/presto/issues/12338
2 使用hive2.3.4的beeline连接presto报错
$ beeline -d com.facebook.presto.jdbc.PrestoDriver -u "jdbc:presto://localhost:8080/hive"
Error: Unrecognized connection property 'url' (state=,code=0)
问题详见:https://www.cnblogs.com/barneywill/p/10565750.html
参考:https://prestodb.github.io/overview.html
【原创】大数据基础之Presto(1)简介、安装、使用的更多相关文章
- 大数据基础环境--jdk1.8环境安装部署
1.环境说明 1.1.机器配置说明 本次集群环境为三台linux系统机器,具体信息如下: 主机名称 IP地址 操作系统 hadoop1 10.0.0.20 CentOS Linux release 7 ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
随机推荐
- java定时器实现总结
前言:Java定时器目前主要有3种实现方式:JDK组件,Spring Task,Quartz框架. 1. JDK组件(1) java.util.TimerTask MyTimerTask.java: ...
- linux 下shell脚本备份文件
以下是shell自动备份用的: 主要功能: 1)将pathSrc目录中的文件拷贝到pathDst目录中去. 具体步骤:先查询源目录和目标目录中的文件,分别存在fileSrc和fileDst中. -&g ...
- GCC编译器原理(一)------GCC 工具:addr2line、ar、as、c++filt和elfedit
1.3 GCC 工具 1.3.1 binutils 工具集 工具 描述 addr2line 给出一个可执行文件的内部地址,addr2line 使用文件中的调试信息将地址翻译成源代码文件名和行号. ar ...
- Debian Security Advisory(Debian安全报告) DSA-4414-1 libapache2-mod-auth-mellon security update
Debian Security Advisory(Debian安全报告) DSA-4414-1 libapache2-mod-auth-mellon security update Package:l ...
- [C++]数组处理相关函数(memcpy/memset等)
头文件:string.h或者memory.h [1]void *memcpy(void *dest, const void *src, size_t n);//数组元素拷贝 功能:从源src所指的内存 ...
- Kaldi中的L2正则化
steps/nnet3/train_dnn.py --l2-regularize-factor 影响模型参数的l2正则化强度的因子.要进行l2正则化,主要方法是在配置文件中使用'l2-regulari ...
- python之字典的增删改查
Python字典是另一种可变容器模型,且可存储任意类型对象,如字符串.数字.元组等其他容器模型.字典都是无序的,但查询速度快. 字典是一个key/value的集合,key可以是任意可被哈希(内部key ...
- Leetcode#53.Maximum Subarray(最大子序和)
题目描述 给定一个序列(至少含有 1 个数),从该序列中寻找一个连续的子序列,使得子序列的和最大. 例如,给定序列 [-2,1,-3,4,-1,2,1,-5,4], 连续子序列 [4,-1,2,1] ...
- G - Intersecting Rectangles Kattis - intersectingrectangles (扫描线)(判断多个矩形相交)
题目链接: G - Intersecting Rectangles Kattis - intersectingrectangles 题目大意:给你n个矩形,每一个矩形给你这个矩形的左下角的坐标和右上角 ...
- Django实战(一)-----用户登录与注册系统1(环境搭建)
一.背景 学了一段时间的语法,总感觉入不了门,所以找点小项目练练手,项目来自网络. 二.创建虚拟环境,并安装Django 使用Python中的virtualenv搭建一个mysite_env全新的环境 ...