pytorch torch.Storage学习
tensor分为头信息区(Tensor)和存储区(Storage)
信息区主要保存着tensor的形状(size)、步长(stride)、数据类型(type)等信息,而真正的数据则保存成连续数组,存储在存储区
因为数据动辄成千上万,因此信息区元素占用内存较少,主要内存占用取决于tensor中元素的数目,即存储区的大小
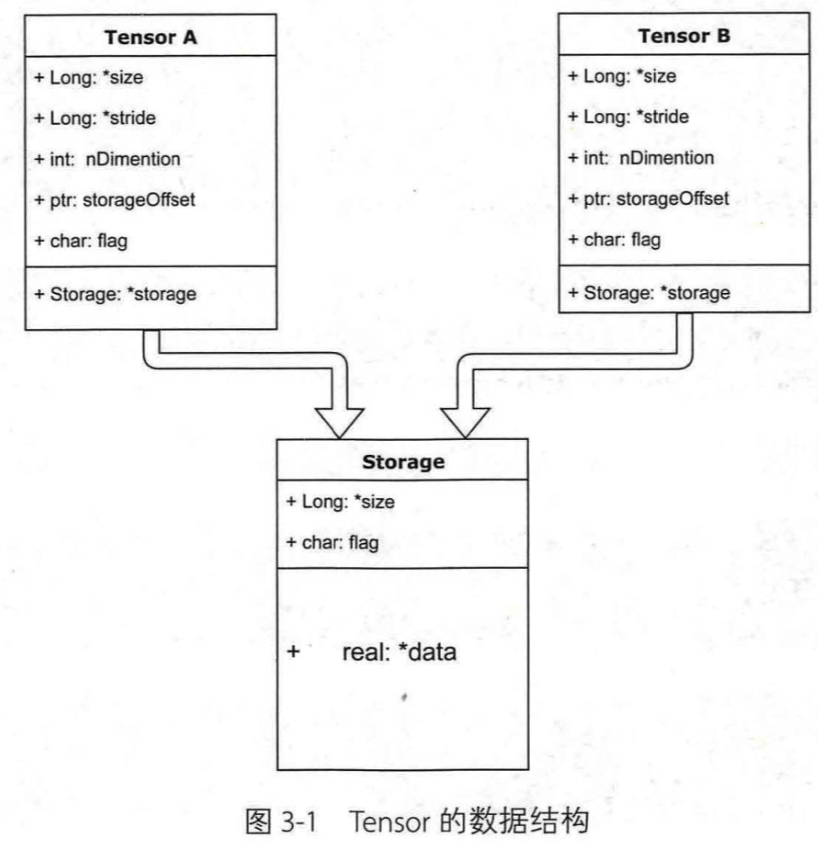
一般来说,一个tensor有着与之相对应的storage,storage是在data之上封装的接口,便于使用
不同的tensor的头信息一般不同,但是可能使用相同的storage
生成a:
a = t.arange(0,6)
a.storage()
⚠️将这里改成a = t.arange(0,6).float(),用来保证得到的值的类型为FloatTensor
这跟下面遇见的一个问题相关,可以看到下面了解一下,然后再跟着操作
所以你的下面内容的值的类型应该为FloatTensor类型,我的仍是LongTensor,因为我没有改过来
返回:
0
1
2
3
4
5
[torch.LongStorage of size 6]
生成b:
b = a.view(2,3)
b.storage()
返回:
0
1
2
3
4
5
[torch.LongStorage of size 6]
对比两者内存地址:
#一个对象的id值可以看作她的内存空间
#a,b storage的内存地址一样,即是同一个storage
id(a.storage()) == id(b.storage())
返回:
True
改变某个值查看是否共享内存:
#a改变,b也随之改变,因为他们共享storage,即内存
a[1] = 100
b
返回:
tensor([[ 0, 100, 2],
[ 3, 4, 5]])
生成c:
#c从a的后两个元素取起
c = a[2:]
c.storage()#指向相同
返回:
0
100
2
3
4
5
[torch.LongStorage of size 6]
查看其首元素内存地址:
c.data_ptr(), a.data_ptr() #data_ptr返回tensor首元素的内存地址
#从结果可以看出两者的地址相差16
#因为c是从a第二个元素选起的,每个元素占8个字节,因为a的值的类型是int64
返回:
(140707162378192, 140707162378176)
因为查看后a的类型为int64:
a.dtype
返回:
torch.int64
更改c:
c[0] = -100 #a,c也共享内存空间,c[0]的内存地址对应的是a[2]的内存地址
a
返回:
tensor([ 0, 100, -100, 3, 4, 5])
使用storage来生成新tensor:
d = t.Tensor(c.storage())#这样a,b,c,d共享同样的内存空间
d[0] = 6666
b
⚠️报错:
RuntimeError: Expected object of data type 6 but got data type 4 for argument #2 'source'
这是因为Tensor期待得到的值的类型是FloatTensor(类型6),而不是其他类型LongTensor(data type 4)
因为如果生成:
dtypea = t.FloatTensor([[1, 2, 3], [4, 5, 6]])
dtypea.storage()
返回:
1.0
2.0
3.0
4.0
5.0
6.0
[torch.FloatStorage of size 6]
再运行就成功了:
d = t.Tensor(dtypea.storage())#这样a,b,c,d共享同样的内存空间
d[0] = 6666
dtypea
返回:
tensor([[6.6660e+03, 2.0000e+00, 3.0000e+00],
[4.0000e+00, 5.0000e+00, 6.0000e+00]])
如果使用的是IntTensor(data type 3),也会报错:
RuntimeError: Expected object of data type 6 but got data type 3 for argument #2 'source'
ShortTensor(data type 2),CharTensor(data type 1),ByteTensor(data type 0),DoubleTensor(data type 7)
下面的操作会在将上面的值改成FloatTensor的基础上进行,即在a = t.arange(0,6)后面添加.float(),然后从头执行了一遍
d = t.Tensor(c.storage())#这样a,b,c,d共享同样的内存空间
d[0] = 6666
b
返回:
tensor([[ 6.6660e+03, 1.0000e+02, -1.0000e+02],
[ 3.0000e+00, 4.0000e+00, 5.0000e+00]])
判断是否共享内存:
#因此a,b,c,d这4个tensor共享storage
id(a.storage()) ==id(b.storage()) ==id(c.storage()) ==id(d.storage())#返回True
偏移量:
#获取首元素相对于storage地址的偏移量
a.storage_offset(), c.storage_offset(), d.storage_offset()
返回:
(0, 2, 0)
即使使用索引只获得一部分值,指向仍是storage:
#隔两行/列取元素来生成e
e = b[::2,::2]
print(e)
print(e.storage_offset())
id(e.storage()) ==id(a.storage()) #虽然值不相同,但是得到的storage是相同的
返回:
tensor([[6666., -100.]])
0
Out[44]:
True
步长信息:是有层次结构的步长
#获得步长信息
b.stride(), e.stride()
返回:
((3, 1), (6, 2))
查看空间是否连续:
#查看其值的内存空间是否连续
#因为e只取得了storage中的部分值,因此其是不连续的
b.is_contiguous(), e.is_contiguous()
返回:
(True, False)
从上面的操作中我们可以看出绝大多数的操作并不修改tensor的数据,即存储区的内容,只是修改了头信息区的内容
这种做法更节省内存,同时提升了处理速度
但是我们可以看见e的操作导致其不连续,这时候可以调用tensor.contiguous()方法将他们变成连续的数据。该方法是复制数据到新的内存中,不再与原来的数据共享storage,如:
e.contiguous().is_contiguous() #返回True
生成f:
print(e.data_ptr())
f = e.contiguous()
print(f.data_ptr()) #可见为f新分配了内存空间
print(f)
print(f.storage())#内存空间中只有两个值
print(f.size())
print(e.data_ptr()) #e指向的内存没有改变
f.is_contiguous() #这里的f的内存空间是连续的
返回:
140707203003760
140707160267104
tensor([[6666., -100.]])
6666.0
-100.0
[torch.FloatStorage of size 2]
torch.Size([1, 2])
140707203003760
Out[56]:
True
是否为连续内存空间有什么影响?
比如当你想要使用.view()转换tensor的形状时,如果该tensor的内存空间不是连续的则会报错:
k = t.arange(0,6).view(2,3).float().t()#进行转置,转置后的k内存是不连续的
k.is_contiguous()
k.view(-1)
报错:
RuntimeError: invalid argument 2: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Call .contiguous() before .view(). at /Users/soumith/mc3build/conda-bld/pytorch_1549593514549/work/aten/src/TH/generic/THTensor.cpp:213
报错的意思也是要求在.view()之前调用.contiguous(),改后为:
k = t.arange(0,6).view(2,3).float().t()#进行转置,转置后的k内存是不连续的
k.is_contiguous()
k.contiguous().view(-1)
成功返回:
tensor([0., 3., 1., 4., 2., 5.])
pytorch torch.Storage学习的更多相关文章
- PyTorch : torch.nn.xxx 和 torch.nn.functional.xxx
PyTorch : torch.nn.xxx 和 torch.nn.functional.xxx 在写 PyTorch 代码时,我们会发现一些功能重复的操作,比如卷积.激活.池化等操作.这些操作分别可 ...
- Note | PyTorch官方教程学习笔记
目录 1. 快速入门PYTORCH 1.1. 什么是PyTorch 1.1.1. 基础概念 1.1.2. 与NumPy之间的桥梁 1.2. Autograd: Automatic Differenti ...
- pytorch torch.Stroage();torch.cuda()
转自:https://ptorch.com/news/52.html torch.Storage是单个数据类型的连续的一维数组,每个torch.Tensor都具有相同数据类型的相应存储.他是torch ...
- 使用PyTorch进行迁移学习
概述 迁移学习可以改变你建立机器学习和深度学习模型的方式 了解如何使用PyTorch进行迁移学习,以及如何将其与使用预训练的模型联系起来 我们将使用真实世界的数据集,并比较使用卷积神经网络(CNNs) ...
- Pytorch线性规划模型 学习笔记(一)
Pytorch线性规划模型 学习笔记(一) Pytorch视频学习资料参考:<PyTorch深度学习实践>完结合集 Pytorch搭建神经网络的四大部分 1. 准备数据 Prepare d ...
- pytorch 测试 迁移学习
训练源码: 源码仓库:https://github.com/pytorch/tutorials 迁移学习测试代码:tutorials/beginner_source/transfer_learning ...
- torch Tensor学习:切片操作
torch Tensor学习:切片操作 torch Tensor Slice 一直使用的是matlab处理矩阵,想从matlab转到lua+torch上,然而在matrix处理上遇到了好多类型不匹配问 ...
- torch 深度学习(5)
torch 深度学习(5) mnist torch siamese deep-learning 这篇文章主要是想使用torch学习并理解如何构建siamese network. siamese net ...
- torch 深度学习(4)
torch 深度学习(4) test doall files 经过数据的预处理.模型创建.损失函数定义以及模型的训练,现在可以使用训练好的模型对测试集进行测试了.测试模块比训练模块简单的多,只需调用模 ...
随机推荐
- navicate 远程无法链接linux上mysql数据库问题
1. 先确认阿里云是否放开了3306权限 (开启阿里云服务器端口) 2. 连接linux,登录数据库:mysql -uroot -p 修改root用户远程登录权限: 想myuser使用mypasswo ...
- react-router 嵌套路由 内层route找不到
今天在做嵌套路由的时候,没有报错,但是页面显示为空,搜索了一下资料,有两个原因: 1.exact精确匹配 <Route component={xxx} path="/" /& ...
- vue从入门到进阶:计算属性computed与侦听器watch(三)
计算属性computed 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护.例如: <div id="example" ...
- 纯CSS+HTML实现checkbox的思路与实例
checkbox应该是一个比较常用的html功能了,不过浏览器自带的checkbox往往样式不怎么好看,而且不同浏览器效果也不一样.出于美化和统一视觉效果的需求,checkbox的自定义就被提出来了. ...
- (后端)JackSon将java对象转换为JSON字符串(转)
转载小金金金丶园友: JackSon可以将java对象转换为JSON字符串,步骤如下: 1.导入JackSon 的jar包 2.创建ObjectMapper对象 3.使用ObjectMapper对象的 ...
- Django 配置文件settings注解(含静态文件和上传文件配置)
基于Django1.11配置文件settings.py import os import sys # Build paths inside the project like this: os.path ...
- PhantomJs浏览器下载
下载地址: http://phantomjs.org/download.html 链接:https://pan.baidu.com/s/1g9ZHLm0Fg56LN30CsDu-CA 密码:qhar
- WARNING: Re-reading the partition table failed with error 22: Invalid argument
在划分磁盘分区时,遇到错误"WARNING: Re-reading the partition table failed with error 22: Invalid argument&qu ...
- django 下载文件
方法一. from django.http import StreamingHttpResponse def big_file_download(request): # do something... ...
- 前后端分离djangorestframework——视图组件
CBV与FBV CBV之前说过就是在view.py里写视图类,在序列化时用过,FBV就是常用的视图函数,两者的功能都可以实现功能,但是在restful规范方面的话,CBV更方便,FBV还要用reque ...