Python爬虫的学习经历
在准备学习人工智能之前呢,我看了一下大体的学习纲领。发现排在前面的是PYTHON的基础知识和爬虫相关的知识,再者就是相关的数学算法与金融分析。不过想来也是,如果想进行大量的数据运算与分析,宏大的基础数据是必不可少的。有了海量的基础数据,才可以支撑我们进行分析与抽取样本,进行深度的学习。
看到这个爬虫的介绍,突然想起来2012年左右在微软亚洲院做外派时做的一个项目。当时在亚洲研究院有一个试验性质的项目叫“O Project", 这里面的第一个字符是字母O。在真正的进入项目之后才知道为什么叫“O”:在IPAD上面使用safari浏览器浏览一个网站,激活插件后,使用手指画圈圈,而圈圈内的词组就会向Bing和Google发出查询请求,在查询请求完成后,返回相应的结果。这个主要是应用在页面级,类似于现在页面上的单词翻译一样。
当时在做这个项目的时候,还没有爬虫的概念与理念。所以我是通过这样的方式来实现这个需求的:
1. 创建一个服务,这个服务主要是接收前台页面回传的圈圈词句;
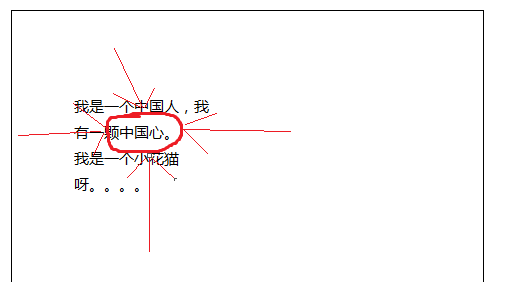
2. 在页面当中激活绘图功能(主要是safari),根据绘制的圈圈,取出页面当中的词句。取出词语的方式也很简单,例如下面的图画:
所画的圈圈的四个最上、下、左、右的元素的X和Y坐标,然后再根据页面当中的文字对应出其所在页面当中的坐标值,如果字符串在这四个坐标内,就认为其为圈中的字符串。
如果像图当中的“颗”这个字,其左坐标没有包含在左箭头的X和Y的范围内,则不将“颗”统计的字符串内,但是“中”满足这样的条件。
3. 在取得圈内的字符串后,回传回后台的服务。
4. 后台的服务向BING和GOOGLE发出查询请求。当时因为没有现在的Python和Scrapy这些流行的框架及组件,我只能通过C#来进行解析:创建一个流程器对象,设置其URL为BING或者GOOGLE的查询字符串。在接收完回传信息后,截取其内容也就是HTML字符串,摘取其中的搜索结果、引用地址及相应的简介。
5. 将所收集到的内容存放到数据库当中进行备案查询或者其他的用处。
6. 当时要对于可能感兴趣的内容进行推荐,就需要人工去点击或者匹配相应的词汇来完成更深入的查询与匹配。现在想想真是太落后了。
随着学习的深入,目前完成了Python的基础使用、工具的使用、第三方工具的初步使用等。在接下来的文章当中我一步步的向大家进行共享吧。
Python爬虫的学习经历的更多相关文章
- Python爬虫系统化学习(2)
Python爬虫系统学习(2) 动态网页爬取 当网页使用Javascript时候,很多内容不会出现在HTML源代码中,所以爬取静态页面的技术可能无法使用.因此我们需要用动态网页抓取的两种技术:通过浏览 ...
- Python爬虫系统学习(1)
Python爬虫系统化学习(1) 前言:爬虫的学习对生活中很多事情都很有帮助,比如买房的时候爬取房价,爬取影评之类的,学习爬虫也是在提升对Python的掌握,所以我准备用2-3周的晚上时间,提升自己对 ...
- Python爬虫系统化学习(4)
Python爬虫系统化学习(4) 在之前的学习过程中,我们学习了如何爬取页面,对页面进行解析并且提取我们需要的数据. 在通过解析得到我们想要的数据后,最重要的步骤就是保存数据. 一般的数据存储方式有两 ...
- Python爬虫系统化学习(5)
Python爬虫系统化学习(5) 多线程爬虫,在之前的网络编程中,我学习过多线程socket进行单服务器对多客户端的连接,通过使用多线程编程,可以大大提升爬虫的效率. Python多线程爬虫主要由三部 ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- python爬虫专栏学习
知乎的一个讲python的专栏,其中爬虫的几篇文章,偏入门解释,快速看了一遍. 入门 爬虫基本原理:用最简单的代码抓取最基础的网页,展现爬虫的最基本思想,让读者知道爬虫其实是一件非常简单的事情. 爬虫 ...
- python爬虫scrapy学习之篇二
继上篇<python之urllib2简单解析HTML页面>之后学习使用Python比较有名的爬虫scrapy.网上搜到两篇相应的文档,一篇是较早版本的中文文档Scrapy 0.24 文档, ...
- 【Python爬虫案例学习】下载某图片网站的所有图集
前言 其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 基本环境配置 python 版本:2.7 ...
- Python爬虫系统化学习(3)
一般来说当我们爬取网页的整个源代码后,是需要对网页进行解析的. 正常的解析方法有三种 ①:正则匹配解析 ②:BeatuifulSoup解析 ③:lxml解析 正则匹配解析: 在之前的学习中,我们学习过 ...
随机推荐
- step_by_step_Angularjs-UI-Grid使用简介
了解 Angularjs UI-Grid 起因:项目需要一个可以固定列和表头的表格,因为表格要显示很多列,当水平滚动条拉至后边时可能无法看到前边的某些信息. 以前在angularjs 1.x 中一直都 ...
- Python设计模式 - UML - 组合结构图(Composite Structure Diagram)
简介 组合结构图用来显示组合结构或部分系统的内部构造,包括类.接口.包.组件.端口和连接器等元素,是UML2.0的新增图. 组合结构图侧重复合元素的方式展示系统内部结构,包括与其他系统的交互接口和通信 ...
- ES6学习笔记(数组)
1.扩展运算符:, 2, 3]) // 1 2 3 console.log(1, ...[2, 3, 4], 5) // 1 2 3 4 5 用于函数调用 function add(x, y) { r ...
- Laravel 5 速查表
Artisan // 在版本 5.1.11 新添加,见 http://d.laravel-china.org/docs/5.1/authorization#creating-policiesphp a ...
- PIL库学习及运用
了解PIL以及安装. 个方面的功能: (1) 图像归档:对图像进行批处理.生产图像预览.图像格式转换等. (2) 图像处理:图像基本处理.像素处理.颜色处理等. 安装PIL在cmd中输入 pip in ...
- 机器学习--k-means聚类原理
“物以类聚,人以群分”, 所谓聚类就是将相似的元素分到一"类"(有时也被称为"簇"或"集合"), 簇内元素相似程度高, 簇间元素相似程度低. ...
- CentOS7.2 1511部署RabbitMQ
一.安装RabbitMQ依赖的的Erlang最小支持包(当然也可以安装完整的Erlang) 1.下载RabbitMQ的Erlang最小支持包源文件 git clone https://github.c ...
- 阿里云SLB负载均衡与使用SSL域名证书
阿里云SLB负载均衡与使用SSL证书 1.购买两台ECS服务器,这就是后台服务器,在这两个服务器上面部署你的网站,注意网站的端口要一样:比如都是 88. 2.在阿里云控制台的菜单里找到 负载均衡,创建 ...
- py文件的运行
安装过程及配置 安装过程准备: 下载好Python的安装程序后,开始安装,在进入安装界面后一定确保勾选将Python加入到系统环境变量的路径里.如图所示: 2 如果没有选取,那么按照下面的步骤进行操作 ...
- mongodb的配置文件详解()
官方地址 https://docs.mongodb.com/manual/reference/configuration-options/#configuration-file 以下页面描述了Mon ...