ElasticSearch聚合
前言
说完了ES的索引与检索,接着再介绍一个ES高级功能API – 聚合(Aggregations),聚合功能为ES注入了统计分析的血统,使用户在面对大数据提取统计指标时变得游刃有余。同样的工作,你在Hadoop中可能需要写mapreduce或Hive,在mongo中你必须得用大段的mapreduce脚本,而在ES中仅仅调用一个API就能实现了。
开始之前,提醒老司机们注意,ES原有的聚合功能Facets在新版本中将被正式被移除,抓紧时间用Aggregations替换Facets吧。Facets真的很慢!
1 关于Aggregations
Aggregations的部分特性类似于SQL语言中的group by,avg,sum等函数。但Aggregations API还提供了更加复杂的统计分析接口。
掌握Aggregations需要理解两个概念:
- 桶(Buckets):符合条件的文档的集合,相当于SQL中的group by。比如,在users表中,按“地区”聚合,一个人将被分到北京桶或上海桶或其他桶里;按“性别”聚合,一个人将被分到男桶或女桶
- 指标(Metrics):基于Buckets的基础上进行统计分析,相当于SQL中的count,avg,sum等。比如,按“地区”聚合,计算每个地区的人数,平均年龄等
对照一条SQL来加深我们的理解:
SELECT COUNT(color) FROM table GROUP BY color
GROUP BY相当于做分桶的工作,COUNT是统计指标。
下面介绍一些常用的Aggregations API。
2 Metrics
2.1 AVG
2.2 Cardinality
2.3 Stats
2.4 Extended Stats
2.5 Percentiles
2.6 Percentile Ranks
3 Bucket
3.1 Filter
3.2 Range
3.3 Missing
3.4 Terms
3.5 Date Range
3.6 Global Aggregation
3.7 Histogram
3.8 Date Histogram
3.9 IPv4 range
3.10 Return only aggregation results
4 聚合缓存
ES中经常使用到的聚合结果集可以被缓存起来,以便更快速的系统响应。这些缓存的结果集和你掠过缓存直接查询的结果是一样的。因为,第一次聚合的条件与结果缓存起来后,ES会判断你后续使用的聚合条件,如果聚合条件不变,并且检索的数据块未增更新,ES会自动返回缓存的结果。
注意聚合结果的缓存只针对size=0的请求(参考3.10章节),还有在聚合请求中使用了动态参数的比如Date Range中的now(参考3.5章节),ES同样不会缓存结果,因为聚合条件是动态的,即使缓存了结果也没用了。
先加入几条index数据,如下:

curl -XPUT 'localhost:9200/testindex/orders/2?pretty' -d '{
"zone_id": "1",
"user_id": "100008",
"try_deliver_times": 102,
"trade_status": "TRADE_FINISHED",
"trade_no": "xiaomi.21142736250938334726",
"trade_currency": "CNY",
"total_fee": 100,
"status": "paid",
"sdk_user_id": "69272363",
"sdk": "xiaomi",
"price": 1,
"platform": "android",
"paid_channel": "unknown",
"paid_at": 1427370289,
"market": "unknown",
"location": "local",
"last_try_deliver_at": 1427856948,
"is_guest": 0,
"id": "fa6044d2fddb15681ea2637335f3ae6b7f8e76fef53bd805108a032cb3eb54cd",
"goods_name": "一小堆元宝",
"goods_id": "ID_001",
"goods_count": "1",
"expires_in": 2592000,
"delivered_at": 0,
"debug_mode": true,
"created_at": 1427362509,
"cp_result": "exception encountered",
"cp_order_id": "cp.order.id.test",
"client_id": "9c98152c6b42c7cb3f41b53f18a0d868",
"app_user_id": "fvu100006"
}'
1、单值聚合
Sum求和,dsl参考如下:
[sfapp@cmos1 ekfile]$ curl 'http://10.202.11.117:9200/testindex/orders/_search?pretty' -d '
> {
> "size": 0,
> "aggs": {
> "return_expires_in": {
> "sum": {
> "field": "expires_in"
> }
> }
> }
> }'
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_expires_in" : {
"value" : 5184000.0
}
}
}
[sfapp@cmos1 ekfile]$
返回expires_in之和,其中size=0 表示不需要返回参与查询的文档。
Min求最小值
[sfapp@cmos1 ekfile]$ curl 'http://10.202.11.117:9200/testindex/orders/_search?pretty' -d '
> {
> "size": 0,
> "aggs": {
> "return_min_expires_in": {
> "min": {
> "field": "expires_in"
> }
> }
> }
> }'
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_min_expires_in" : {
"value" : 2592000.0
}
}
}
[sfapp@cmos1 ekfile]$
Max求最大值
[sfapp@cmos1 ekfile]$ curl 'http://10.202.11.117:9200/testindex/orders/_search?pretty' -d '
> {
> "size": 0,
> "aggs": {
> "return_max_expires_in": {
> "max": {
> "field": "expires_in"
> }
> }
> }
> }'
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_max_expires_in" : {
"value" : 2592000.0
}
}
}
[sfapp@cmos1 ekfile]$
AVG求平均值
[sfapp@cmos1 ekfile]$ curl 'http://10.202.11.117:9200/testindex/orders/_search?pretty' -d '
> {
> "size": 0,
> "aggs": {
> "return_avg_expires_in": {
> "avg": {
> "field": "expires_in"
> }
> }
> }
> }'
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_avg_expires_in" : {
"value" : 2592000.0
}
}
}
[sfapp@cmos1 ekfile]$
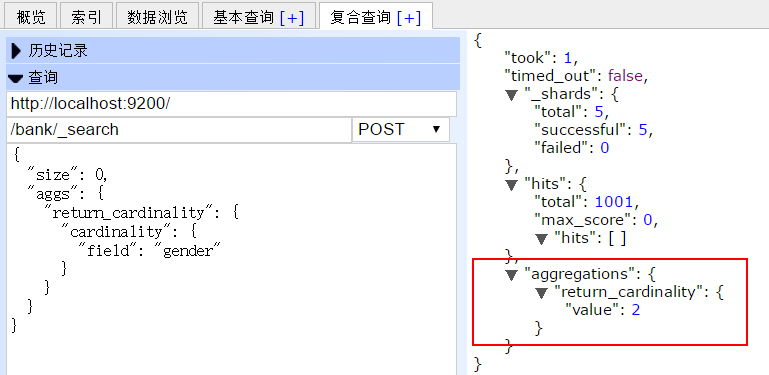
Cardinality 求基数(如下示例,查找性别的基数 M、F,共两个)
{
"size": 0,
"aggs": {
"return_cardinality": {
"cardinality": {
"field": "gender"
}
}
}
}
结果为:
2、多值聚合
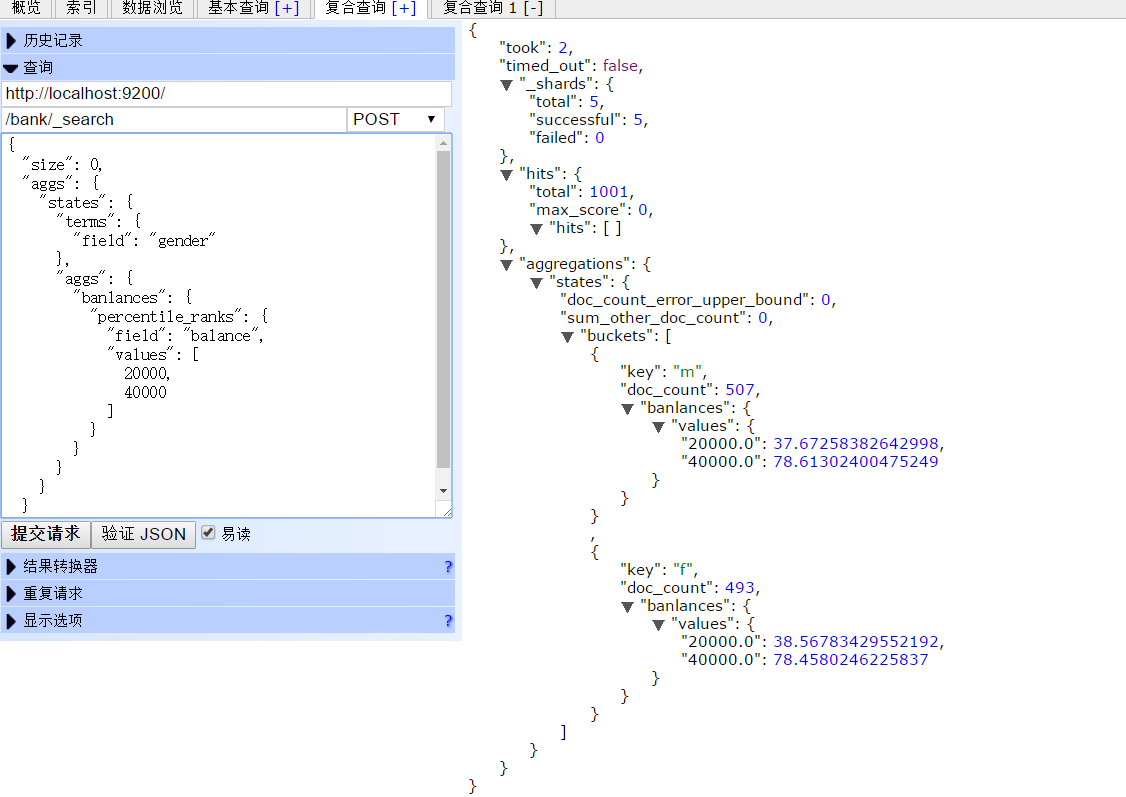
percentiles 求百分比
查看官方文档时候,没看懂,下面是自己测试时的例子,按照性别(F,M)查看工资范围的百分比
{
"size": 0,
"aggs": {
"states": {
"terms": {
"field": "gender"
},
"aggs": {
"banlances": {
"percentile_ranks": {
"field": "balance",
"values": [
20000,
40000
]
}
}
}
}
}
结果:
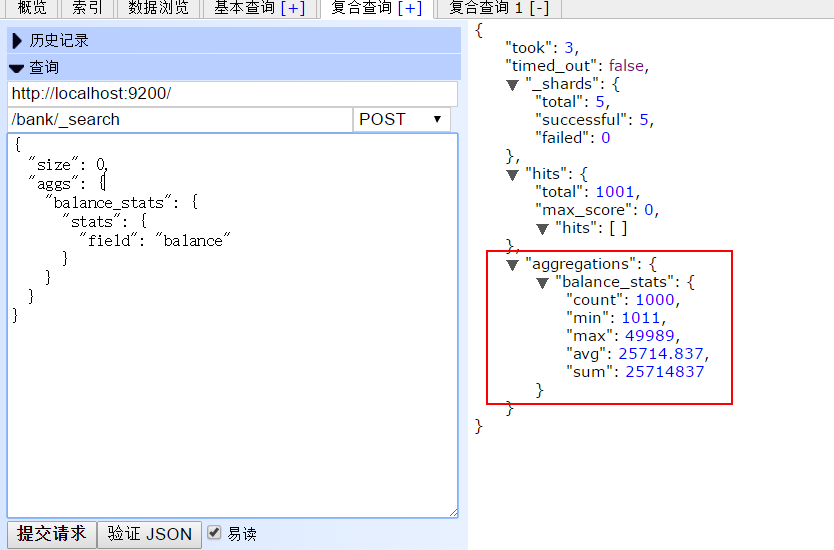
stats 统计
查看balance的统计情况:
{
"size": 0,
"aggs": {
"balance_stats": {
"stats": {
"field": "balance"
}
}
}
}
返回结果:
extended_stats 扩展统计
{
"size": 0,
"aggs": {
"balance_stats": {
"extended_stats": {
"field": "balance"
}
}
}
}
结果:

更加复杂的查询,后续慢慢在实践中道来。
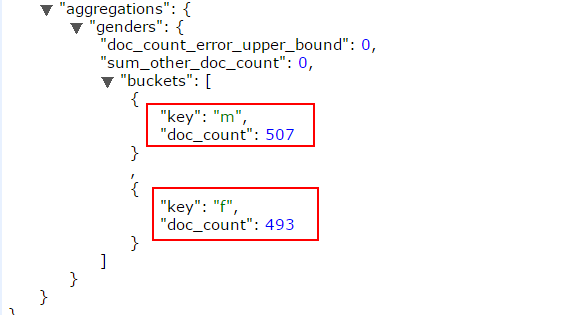
Terms聚合
记录有多少F,多少M
返回结果如下:m记录507条,f记录493条
数据的不确定性
使用terms聚合,结果可能带有一定的偏差与错误性。
比如:
我们想要获取name字段中出现频率最高的前5个。
此时,客户端向ES发送聚合请求,主节点接收到请求后,会向每个独立的分片发送该请求。
分片独立的计算自己分片上的前5个name,然后返回。当所有的分片结果都返回后,在主节点进行结果的合并,再求出频率最高的前5个,返回给客户端。
这样就会造成一定的误差,比如最后返回的前5个中,有一个叫A的,有50个文档;B有49。 但是由于每个分片独立的保存信息,信息的分布也是不确定的。 有可能第一个分片中B的信息有2个,但是没有排到前5,所以没有在最后合并的结果中出现。 这就导致B的总数少计算了2,本来可能排到第一位,却排到了A的后面。
size与shard_size
为了改善上面的问题,就可以使用size和shard_size参数。
- size参数规定了最后返回的term个数(默认是10个)
- shard_size参数规定了每个分片上返回的个数
- 如果shard_size小于size,那么分片也会按照size指定的个数计算
通过这两个参数,如果我们想要返回前5个,size=5;shard_size可以设置大于5,这样每个分片返回的词条信息就会增多,相应的误差几率也会减小。
order排序
order指定了最后返回结果的排序方式,默认是按照doc_count排序。
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "_count" : "asc" }
}
}
}
}
也可以按照字典方式排序:
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "_term" : "asc" }
}
}
}
}
当然也可以通过order指定一个单值聚合,来排序。
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "avg_balance" : "desc" }
},
"aggs" : {
"avg_balance" : { "avg" : { "field" : "balance" } }
}
}
}
}
同时也支持多值聚合,不过要指定使用的多值字段:
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "balance_stats.avg" : "desc" }
},
"aggs" : {
"balance_stats" : { "stats" : { "field" : "balance" } }
}
}
}
}
返回结果:

min_doc_count与shard_min_doc_count
聚合的字段可能存在一些频率很低的词条,如果这些词条数目比例很大,那么就会造成很多不必要的计算。
因此可以通过设置min_doc_count和shard_min_doc_count来规定最小的文档数目,只有满足这个参数要求的个数的词条才会被记录返回。
通过名字就可以看出:
- min_doc_count:规定了最终结果的筛选
- shard_min_doc_count:规定了分片中计算返回时的筛选
script
桶聚合也支持脚本的使用:
{
"aggs" : {
"genders" : {
"terms" : {
"script" : "doc['gender'].value"
}
}
}
}
以及外部脚本文件:
{
"aggs" : {
"genders" : {
"terms" : {
"script" : {
"file": "my_script",
"params": {
"field": "gender"
}
}
}
}
}
}
filter
filter字段提供了过滤的功能,使用两种方式:include可以匹配出包含该值的文档,exclude则排除包含该值的文档。
例如:
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"include" : ".*sport.*",
"exclude" : "water_.*"
}
}
}
}上面的例子中,最后的结果应该包含sport并且不包含water。
也支持数组的方式,定义包含与排除的信息:
{
"aggs" : {
"JapaneseCars" : {
"terms" : {
"field" : "make",
"include" : ["mazda", "honda"]
}
},
"ActiveCarManufacturers" : {
"terms" : {
"field" : "make",
"exclude" : ["rover", "jensen"]
}
}
}
}多字段聚合
通常情况,terms聚合都是仅针对于一个字段的聚合。因为该聚合是需要把词条放入一个哈希表中,如果多个字段就会造成n^2的内存消耗。
不过,对于多字段,ES也提供了下面两种方式:
- 1 使用脚本合并字段
- 2 使用copy_to方法,合并两个字段,创建出一个新的字段,对新字段执行单个字段的聚合。
collect模式
对于子聚合的计算,有两种方式:
- depth_first 直接进行子聚合的计算
- breadth_first 先计算出当前聚合的结果,针对这个结果在对子聚合进行计算。
默认情况下ES会使用深度优先,不过可以手动设置成广度优先,比如:
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10,
"collect_mode" : "breadth_first"
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}缺省值Missing value
缺省值指定了缺省的字段的处理方式:
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"missing": "N/A"
}
}
}
}
聚合的桶操作和度量的完整用法可以在 Elasticsearch 参考 中找到。本章中会涵盖其中很多内容,但在阅读完本章后查看它会有助于我们对它的整体能力有所了解。
所以让我们先看一个例子。我们将会创建一些对汽车经销商有用的聚合,数据是关于汽车交易的信息:车型、制造商、售价、何时被出售等。
首先我们批量索引一些数据:
POST /cars/transactions/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
有了数据,开始构建我们的第一个聚合。汽车经销商可能会想知道哪个颜色的汽车销量最好,用聚合可以轻易得到结果,用 terms 桶操作:
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
}
}
}
}
|
|
聚合操作被置于顶层参数 |
|
|
然后,可以为聚合指定一个我们想要名称,本例中是: |
|
|
最后,定义单个桶的类型 |
聚合是在特定搜索结果背景下执行的, 这也就是说它只是查询请求的另外一个顶层参数(例如,使用 /_search 端点)。 聚合可以与查询结对,但我们会晚些在 限定聚合的范围(Scoping Aggregations) 中来解决这个问题。
可能会注意到我们将 size 设置成 0 。我们并不关心搜索结果的具体内容,所以将返回记录数设置为 0 来提高查询速度。 设置 size: 0 与 Elasticsearch 1.x 中使用 count 搜索类型等价。
然后我们为聚合定义一个名字,名字的选择取决于使用者,响应的结果会以我们定义的名字为标签,这样应用就可以解析得到的结果。
随后我们定义聚合本身,在本例中,我们定义了一个单 terms 桶。 这个 terms 桶会为每个碰到的唯一词项动态创建新的桶。 因为我们告诉它使用 color 字段,所以 terms 桶会为每个颜色动态创建新桶。
让我们运行聚合并查看结果:
{
...
"hits": {
"hits": []
},
"aggregations": {
"popular_colors": {
"buckets": [
{
"key": "red",
"doc_count": 4
},
{
"key": "blue",
"doc_count": 2
},
{
"key": "green",
"doc_count": 2
}
]
}
}
}
|
|
因为我们设置了 |
|
|
|
|
|
每个桶的 |
|
|
每个桶的数量代表该颜色的文档数量。 |
响应包含多个桶,每个对应一个唯一颜色(例如:红 或 绿)。每个桶也包括 聚合进 该桶的所有文档的数量。例如,有四辆红色的车。
前面的这个例子完全是实时执行的:一旦文档可以被搜到,它就能被聚合。这也就意味着我们可以直接将聚合的结果源源不断的传入图形库,然后生成实时的仪表盘。 不久,你又销售了一辆银色的车,我们的图形就会立即动态更新银色车的统计信息。
瞧!这就是我们的第一个聚合!
java代码实现:
①、实例化es
private static TransportClient client;
static {
try {
String esClusterName = "shopmall-es";
List<String> clusterNodes = Arrays.asList("http://172.16.32.69:9300","http://172.16.32.48:9300");
Settings settings = Settings.builder().put("cluster.name", esClusterName).build();
client = new PreBuiltTransportClient(settings);
for (String node : clusterNodes) {
URI host = URI.create(node);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(host.getHost()), host.getPort()));
}
} catch (Exception e) {
log.error("elasticsearchUtils init exception", e);
}
}
public static void close() {
client.close();
}
②、度量聚合实现
/**
* Description:指标聚合查询,COUNT(color) ,min ,max,sum等相当于指标
*
* @author wangweidong
* CreateTime: 2017年11月9日 上午10:43:18
*
* 数据格式:{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
*
* 1、可能会注意到我们将 size 设置成 0 。我们并不关心搜索结果的具体内容,所以将返回记录数设置为 0 来提高查询速度。 设置 size: 0 与 Elasticsearch 1.x 中使用 count 搜索类型等价。
*
* 2、对text 字段上的脚本进行排序,聚合或访问值时,出现Fielddata is disabled on text fields by default. Set fielddata=true on [color] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory.
* Fielddata默认情况下禁用文本字段,因为Fielddata可以消耗大量的堆空间,特别是在加载高基数text字段时。一旦fielddata被加载到堆中,它将在该段的生命周期中保持在那里。此外,加载fielddata是一个昂贵的过程,可以导致用户体验延迟命中。
* 可以使用使用该my_field.keyword字段进行聚合,排序或脚本或者启用fielddata(不建议使用)
*/
@Test
public void metricsAggregation() {
try {
String index = "cars";
String type = "transactions";
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index).setTypes(type);
// MaxAggregationBuilder field = AggregationBuilders.max("max_price").field("price");
//MinAggregationBuilder 统计最小值
// MinAggregationBuilder field = AggregationBuilders.min("min_price").field("price");
//SumAggregationBuilder 统计合计
// SumAggregationBuilder field = AggregationBuilders.sum("sum_price").field("price");
//StatsAggregationBuilder 统计聚合即一次性获取最小值、最小值、平均值、求和、统计聚合的集合。
StatsAggregationBuilder field = AggregationBuilders.stats("stats_price").field("price");
searchRequestBuilder.addAggregation(field);
searchRequestBuilder.setSize(0);
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
System.out.println(searchResponse.toString());
Aggregations agg = searchResponse.getAggregations();
if(agg == null) {
return;
}
// Max max = agg.get("max_price");
// System.out.println(max.getValue());
// Min min = agg.get("min_price");
// System.out.println(min.getValue());
// Sum sum = agg.get("sum_price");
// System.out.println(sum.getValue());
Stats stats = agg.get("stats_price");
System.out.println("最大值:"+stats.getMax());
System.out.println("最小值:"+stats.getMin());
System.out.println("平均值:"+stats.getAvg());
System.out.println("合计:"+stats.getSum());
System.out.println("总条数:"+stats.getCount());
} catch (Exception e) {
e.printStackTrace();
}
}
③、桶聚合实现
/**
* Description:桶聚合查询,GROUP BY相当于桶
*
* @author wangweidong
* CreateTime: 2017年11月9日 下午3:47:54
*
*/
@Test
public void bucketsAggregation() {
String index = "cars";
String type = "transactions";
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index).setTypes(type);
TermsAggregationBuilder field = AggregationBuilders.terms("popular_colors").field("color.keyword");
searchRequestBuilder.addAggregation(field);
searchRequestBuilder.setSize(0);
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
System.out.println(searchResponse.toString());
Terms genders = searchResponse.getAggregations().get("popular_colors");
for (Terms.Bucket entry : genders.getBuckets()) {
Object key = entry.getKey(); // Term
Long count = entry.getDocCount(); // Doc count
System.out.println(key);
System.out.println(count);
}
}
ElasticSearch聚合的更多相关文章
- ElasticSearch聚合(转)
ES之五:ElasticSearch聚合 前言 说完了ES的索引与检索,接着再介绍一个ES高级功能API – 聚合(Aggregations),聚合功能为ES注入了统计分析的血统,使用户在面对大数据提 ...
- ElasticSearch聚合分析
聚合用于分析查询结果集的统计指标,我们以观看日志分析为例,介绍各种常用的ElasticSearch聚合操作. 目录: 查询用户观看视频数和观看时长 聚合分页器 查询视频uv 单个视频uv 批量查询视频 ...
- Elasticsearch聚合问题
在测试Elasticsearch聚合的时候报了一个错误.具体如下: GET /megacorp/employee/_search { "aggs": { "all_int ...
- Elasticsearch聚合初探——metric篇
Elasticsearch是一款提供检索以及相关度排序的开源框架,同时,也支持对存储的文档进行复杂的统计--聚合. 前言 ES中的聚合被分为两大类:Metric度量和bucket桶(原谅我英语差,找不 ...
- Elasticsearch聚合 之 Histogram 直方图聚合
Elasticsearch支持最直方图聚合,它在数字字段自动创建桶,并会扫描全部文档,把文档放入相应的桶中.这个数字字段既可以是文档中的某个字段,也可以通过脚本创建得出的. 桶的筛选规则 举个例子,有 ...
- Elasticsearch聚合 之 Date Histogram聚合
Elasticsearch的聚合主要分成两大类:metric和bucket,2.0中新增了pipeline还没有研究.本篇还是来介绍Bucket聚合中的常用聚合--date histogram.参考: ...
- Elasticsearch聚合 之 Range区间聚合
Elasticsearch提供了多种聚合方式,能帮助用户快速的进行信息统计与分类,本篇主要讲解下如何使用Range区间聚合. 最简单的例子,想要统计一个班级考试60分以下.60到80分.80到100分 ...
- Elasticsearch聚合——aggregation
聚合提供了分组并统计数据的能力.理解聚合的最简单的方式是将其粗略地等同为SQL的GROUP BY和SQL聚合函数.在Elasticsearch中,你可以在一个响应中同时返回命中的数据和聚合结果.你可以 ...
- 2018/2/13 ElasticSearch学习笔记三 自动映射以及创建自动映射模版,ElasticSearch聚合查询
终于把这些命令全敲了一遍,话说ELK技术栈L和K我今天花了一下午全部搞定,学完后还都是花式玩那种...E却学了四天(当然主要是因为之前上班一直没时间学,还有安装服务时出现的各种error真是让我扎心了 ...
- elasticsearch聚合操作——本质就是针对搜索后的结果使用桶bucket(允许嵌套)进行group by,统计下分组结果,包括min/max/avg
分析 Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计.它很像SQL中的GROUP BY但是功能更强大. 举个例子,让我们找到所有职员中最大 ...
随机推荐
- C#编辑EXE使用的appSettings节点的Config文件
/// <summary> /// 保存配置文件的设定 /// </summary> /// <param name="Key"></pa ...
- python3+xlwt 读取txt信息并写入到excel中
# coding = utf-8 import os import xlwt import re def readTxt_toExcel(valueList, Pathlist): workbook ...
- Linux下完全删除用户
实验环境:Centos7虚拟机 首先创建一个普通用户gubeiqing. [root@localhost ~]# useradd gubeiqing [root@localhost ~]# passw ...
- 【转】10条你不可不知的css规则
10条你不可不知的css规则 Posted on 2006-12-20 10:33 雨中太阳 阅读(343) 评论(1) 编辑 收藏 :[译]10条你不可不知的css规则正文: Published D ...
- docker pull下载镜像报错Get https://registry-1.docker.io/v2/library/centos/manifests/latest:..... timeout
使用docker pull从镜像仓库拉取镜像时报错如下:[root@docker-registry ~]# docker pull centosUsing default tag: latestTry ...
- mabatis insert into on duplicate key
一.mabatis实现saveOrUpdate功能 <insert id="insert" parameterType="hystrixconfigdo" ...
- jvm运行时内存模式
jvm内存模型 内存模型粗略划分为:堆和栈 详细划分为:堆,虚拟机栈,方法区,本地方法区,程序计数器 程序计数器: 为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程 ...
- CSAPP:信息的表和处理1
CSAPP:信息的表和处理1 关键点:寻址.内存.磁盘.虚拟地址.物理地址.整型数组. 信息存储中的几个概念整型数据类型无符号数有符号数几个概念有符号数与无符号数之间转换基于栈与基于寄存器的区别 信息 ...
- P1024 一元三次方程求解(二分答案)
思路: 求这个根,然后有一个关键的条件|x1-x2|>=1,然后就是从-100,枚举到+100,每次二分(i, i+1)注意如果f(i)*f(i+1)>0则不进行二分,如果,你觉得这样的值 ...
- 域名打开没有加上“http://”,导致报错{"code":-32603,"message":"Cannot navigate to invalid URL"}
1.在robotframework中写用例 Open Browser 192.168.4.110:8880/jwzh Chrome 2.没有写http:// 3.导致报错 4.正确写法应该是 Op ...