Mysql加锁过程详解(6)-数据库隔离级别(2)-通过例子理解事务的4种隔离级别
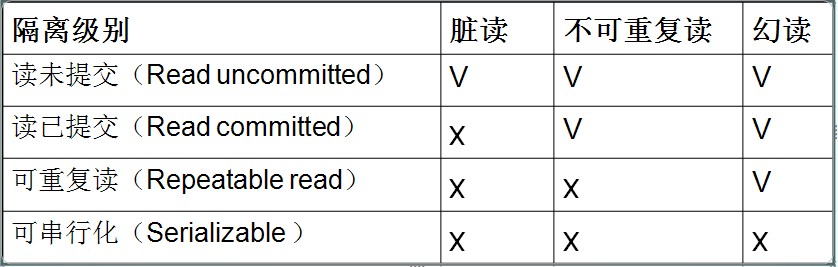
SQL标准定义了4种隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。
低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
首先,我们使用 test 数据库,新建 tx 表,并且如图所示打开两个窗口来操作同一个数据库:

第1级别:Read Uncommitted(读取未提交内容)
(1)所有事务都可以看到其他未提交事务的执行结果
(2)本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少
(3)该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据
#首先,修改隔离级别
set tx_isolation='READ-UNCOMMITTED';
select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:也启动一个事务(那么两个事务交叉了)
在事务B中执行更新语句,且不提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:那么这时候事务A能看到这个更新了的数据吗?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 | --->可以看到!说明我们读到了事务B还没有提交的数据
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:事务B回滚,仍然未提交
rollback;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:在事务A里面看到的也是B没有提交的数据
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->脏读意味着我在这个事务中(A中),事务B虽然没有提交,但它任何一条数据变化,我都可以看到!
| 2 | 2 |
| 3 | 3 |
+------+------+
第2级别:Read Committed(读取提交内容)
(1)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
(2)它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变
(3)这种隔离级别出现的问题是——不可重复读(Nonrepeatable Read):不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。
|——>导致这种情况的原因可能有:(1)有一个交叉的事务有新的commit,导致了数据的改变;(2)一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的commit
#首先修改隔离级别
set tx_isolation='read-committed';
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:也启动一个事务(那么两个事务交叉了)
在这事务中更新数据,且未提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:这个时候我们在事务A中能看到数据的变化吗?
select * from tx; --------------->
+------+------+ |
| id | num | |
+------+------+ |
| 1 | 1 |--->并不能看到! |
| 2 | 2 | |
| 3 | 3 | |
+------+------+ |——>相同的select语句,结果却不一样
|
#事务B:如果提交了事务B呢? |
commit; |
|
#事务A: |
select * from tx; --------------->
+------+------+
| id | num |
+------+------+
| 1 | 10 |--->因为事务B已经提交了,所以在A中我们看到了数据变化
| 2 | 2 |
| 3 | 3 |
+------+------+
第3级别:Repeatable Read(可重读)
(1)这是MySQL的默认事务隔离级别
(2)它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
(3)此级别可能出现的问题——幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行
(4)InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了幻读
#首先,更改隔离级别
set tx_isolation='repeatable-read';
select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:开启一个新事务(那么这两个事务交叉了)
在事务B中更新数据,并提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
commit; #事务A:这时候即使事务B已经提交了,但A能不能看到数据变化?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->还是看不到的!(这个级别2不一样,也说明级别3解决了不可重复读问题)
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:只有当事务A也提交了,它才能够看到数据变化
commit;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
第4级别:Serializable(可串行化)
(1)这是最高的隔离级别
(2)它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
(3)在这个级别,可能导致大量的超时现象和锁竞争
#首先修改隔离界别
set tx_isolation='serializable';
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| SERIALIZABLE |
+----------------+ #事务A:开启一个新事务
start transaction; #事务B:在A没有commit之前,这个交叉事务是不能更改数据的
start transaction;
insert tx values('4','4');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
update tx set num=10 where id=1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
参考文章
http://www.cnblogs.com/snsdzjlz320/p/5761387.html
在MYSQL的事务引擎中,INNODB是使用范围最广的。它默认的事务隔离级别是REPEATABLE READ(可重复读),在标准的事务隔离级别定义下,REPEATABLE READ是不能防止幻读产生的。INNODB使用了2种技术手段(MVCC AND GAP LOCK)实现了防止幻读的发生。
以上的iso定义的数据库隔离级别,mysql实现了基本定义,但和他有点不一样,比如mysql重复读避免的幻读
Mysql加锁过程详解(6)-数据库隔离级别(2)-通过例子理解事务的4种隔离级别的更多相关文章
- Mysql加锁过程详解(6)-数据库隔离级别(1)
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(8)-理解innodb的锁(record,gap,Next-Key lock)
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(9)-innodb下的记录锁,间隙锁,next-key锁
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(1)-基本知识
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(2)-关于mysql 幻读理解
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(3)-关于mysql 幻读理解
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(4)-select for update/lock in share mode 对事务并发性影响
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(5)-innodb 多版本并发控制原理详解
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(7)-初步理解MySQL的gap锁
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
随机推荐
- 【慕课网实战】二、以慕课网日志分析为例 进入大数据 Spark SQL 的世界
MapReduce的局限性: 1)代码繁琐: 2)只能够支持map和reduce方法: 3)执行效率低下: 4)不适合迭代多次.交互式.流式的处理: 框架多样化: 1)批处理(离线):MapRed ...
- Elasticsearch System Call Filters Failed to Install
Elasticsearch starts to run, error occurs: : system call filters failed to install; check the logs a ...
- python data science handbook1
import numpy as np import matplotlib.pyplot as plt import seaborn; seaborn.set() rand = np.random.Ra ...
- JMS Cluster modules
是GeoServer实现集群还是在数据库实现集群? Hadoop.Spark.HBase与Redis的适用性见解:https://blog.csdn.net/cuiyaonan2000/article ...
- HTML5中input标签有用的新属性
HTML5对input增加了一些新标签,个人觉得比较常用有效的以下几个 placeholder=“请输入” 常见用于默认提示 autofocus 自动聚焦到当前输入框 maxlength=" ...
- _ZNote_Qt_QDialog_修改button名称
#include <QPushButton> ui->buttonBox->button(QDialogButtonBox::Ok)->setText("Run ...
- CDN随笔
CDN的理解:(1)CDN (内容分发网络)加速用户获取数据的 系统(2)部署在离用户最近的网络节点上(3)命中CDN 不需要访问后端服务器(4)互联网公司自己搭建或租用
- 疑难杂症:Java中Scanner连续获取int和String型发生错误.
使用Scanner类获取输入,连续获取int类型和String类型数据时候,发生错误. Scanner sc = new Scanner(System.in); System.out.println( ...
- docker zabbix
1.zabbix-mysql 数据库 sudo docker pull zabbix/zabbix-server-mysql sudo docker run --name some-zabbix-se ...
- 探讨npm依赖管理之peerDependencies
引言 想必前端同学对npm的devDependencies和dependencies都比较熟悉,但是对peerDependencies可能就有点陌生,尤其是没有写过npm包插件的同学,比如之前使用gr ...