字体反爬--css+svg反爬
地址:http://www.dianping.com/shop/9964442
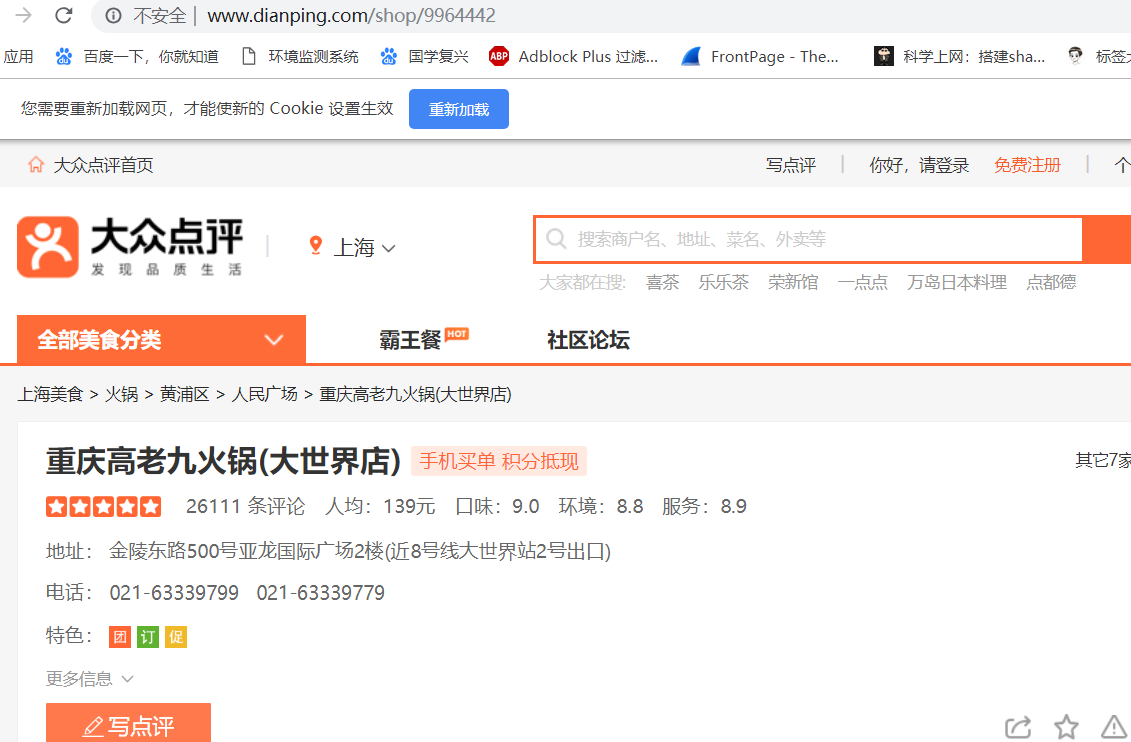
好多字没了,替代的是<x class="xxx"></x>这种css标签
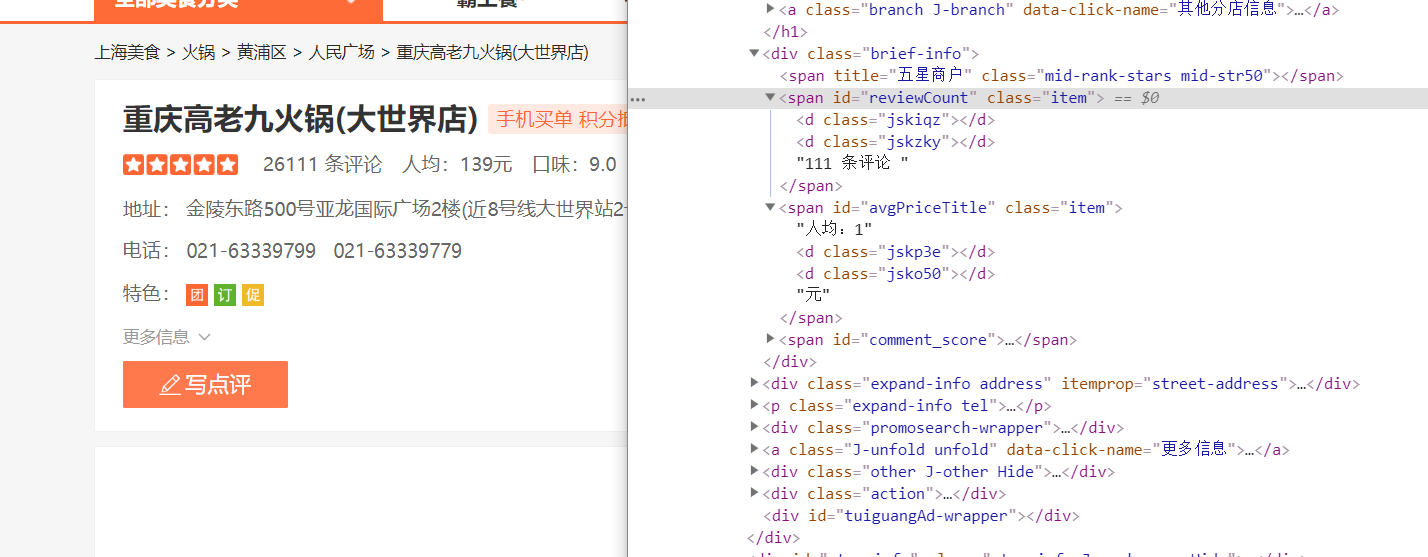
定位到位置

找到文字

SVG

svg可以写字,xy是相对svg标签的坐标,单位px

textPath
用xlink:href标记文字路径,就是文字排列方向,文字按方向对齐
<path id="my_path" d="M 20,20 C 40,40 80,40 100,20" fill="transparent" />
<text>
<textPath xlink:href="#my_path">This text follows a curve.</textPath>
</text>
d内的参数:
M = moveto
L = lineto
H = horizontal lineto
V = vertical lineto
C = curveto
S = smooth curveto
Q = quadratic Bézier curve
T = smooth quadratic Bézier curveto
A = elliptical Arc
Z = closepath
用了M和H,M是xy坐标,H是水平线表示文字方向水平方向。
参考:https://cloud.tencent.com/developer/section/1423872
1.找css
2.找svg
3.得到css的坐标,在svg里找到字
4.用字替换标签
代码:
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}
r=requests.get("http://www.dianping.com/shop/9964442",headers=headers)
css_url="http:"+re.findall('href="(//s3plus.meituan.net.*?svgtextcss.*?.css)',r.text)[0]
css_cont=requests.get(css_url,headers=headers)
得到css
svg_url=re.findall('class\^="(\w+)".*?(//s3plus.*?\.svg)',css_cont.text)
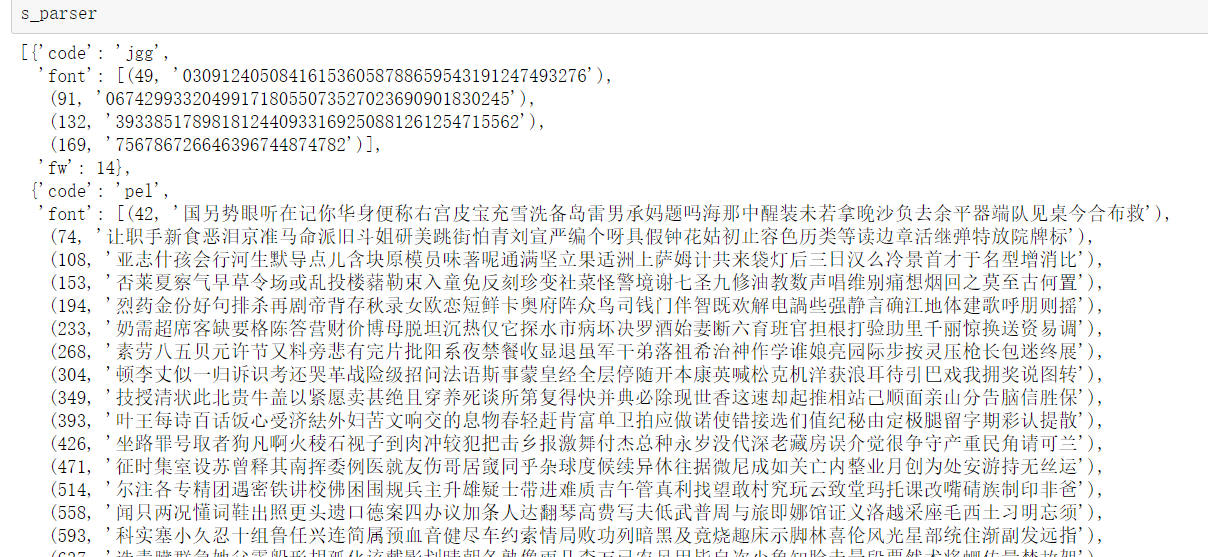
s_parser=[]
for c,u in svg_url:
f,w=svg_parser("http:"+u)
s_parser.append({"code":c,"font":f,"fw":w})
得到svg
解析svg结果
def svg_parser(url):
r=requests.get(url,headers=headers)
font=re.findall('" y="(\d+)">(\w+)</text>',r.text,re.M)
if not font:
font=[]
z=re.findall('" textLength.*?(\w+)</textPath>',r.text,re.M)
y=re.findall('id="\d+" d="\w+\s(\d+)\s\w+"',r.text,re.M)
for a,b in zip(y,z):
font.append((a,b))
width=re.findall("font-size:(\d+)px",r.text)[0]
new_font=[]
for i in font:
new_font.append((int(i[0]),i[1]))
return new_font,int(width)
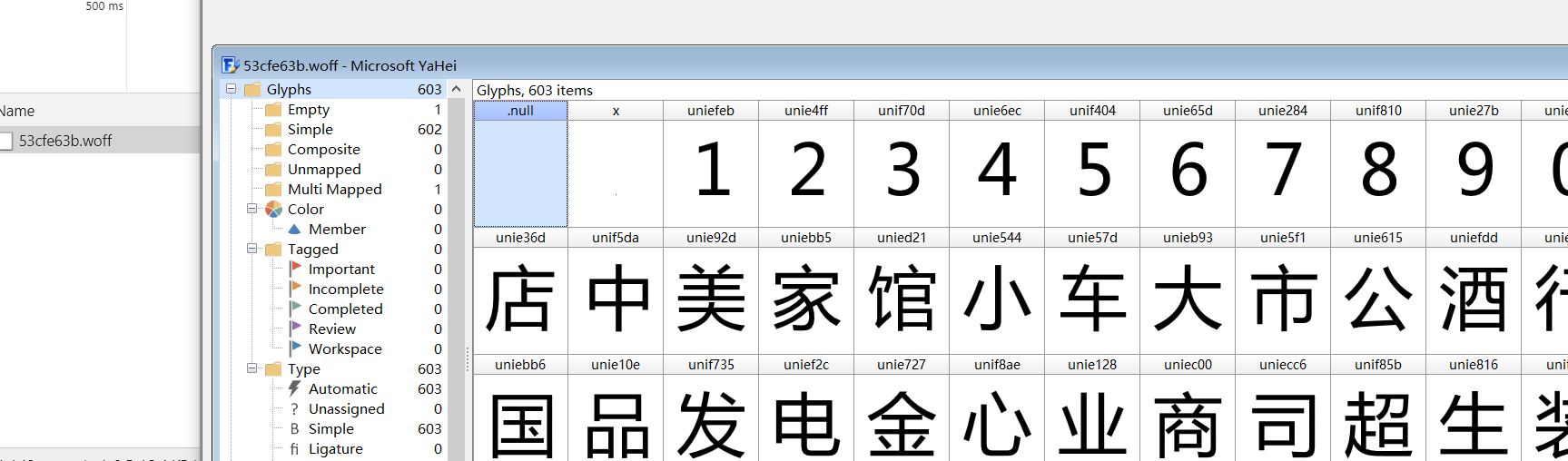
结果里有些字没解析出来,发现有两种文字形式
一种带路径的textPath,行数y在d=“xx”的M里
另一种text,行数在text标签里y的值,需要分别处理
返回一个元组包含y的参考值和字体内容,fw是字体宽度
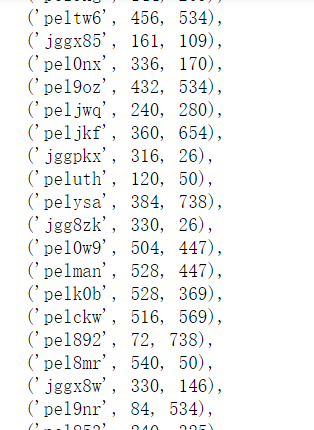
css_list = re.findall('(\w+){background:.*?(\d+).*?px.*?(\d+).*?px;', '\n'.join(css_cont.text.split('}')))
css_list = [(i[0],int(i[1]),int(i[2])) for i in css_list]
从css找到所有坐标
def font_parser(ft):
for i in s_parser:
if i["code"] in ft[0]:
font=sorted(i["font"])
if ft[2] < int(font[0][0]):
x=int(ft[1]/i["fw"])
return font[0][1][x]
for j in range(len(font)):
if (j+1) in range(len(font)):
if(ft[2]>=int(font[j][0]) and ft[2]< int(font[j+1][0])):
x=int(ft[1]/i["fw"])
return font[j+1][1][x]
根据class坐标在svg找到具体文字
y是文字所在行数,x字体宽度
replace_dic=[]
for i in css_list:
replace_dic.append({"code":i[0],"word":font_parser(i)})
根据坐标,找到映射关系

rep=r.text
for i in range(len(replace_dic)):
if replace_dic[i]["code"] in rep:
a=re.findall(f'<\w+\sclass="{replace_dic[i]["code"]}"><\/\w+>',rep)[0]
rep=rep.replace(a,replace_dic[i]["word"])
<x class="xxx"></x>标签全局替换
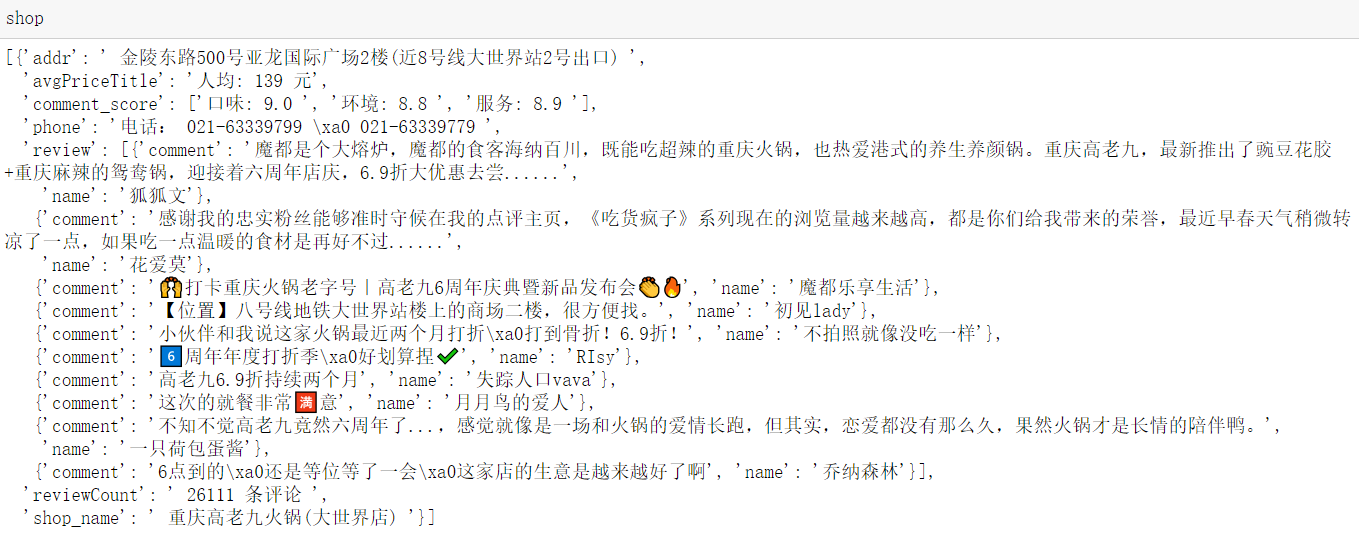
shop=[]
shop_name=tree.xpath('//h1[@class="shop-name"]//text()')[0]
reviewCount=tree.xpath('//span[@id="reviewCount"]//text()')[0]
avgPriceTitle=tree.xpath('//span[@id="avgPriceTitle"]//text()')[0]
comment_score=tree.xpath('//span[@id="comment_score"]//text()')
comment_score=[i for i in comment_score if i!=" "]
addr=tree.xpath('//span[@itemprop="street-address"]/text()')[0]
phone=tree.xpath('//p[@class="expand-info tel"]//text()')
phone=phone[1]+phone[2]
review=[]
for li in lis:
name=li.xpath('.//a[@class="name"]/text()')[0]
comment=li.xpath('.//p[@class="desc"]/text()')[0]
review.append({"name":name,"comment":comment})
shop.append({
"shop_name":shop_name,
"reviewCount":reviewCount,
"avgPriceTitle":avgPriceTitle,"addr":addr,
"phone":phone,
"review":review
})
替换后店名评论数评论评分电话地址等结果
用的库

后来发现不只使用一种反爬,还有自定义字体
字体反爬--css+svg反爬的更多相关文章
- 记一次svg反爬学习
网址:http://www.porters.vip/confusion/food.html 打开开发者工具后 页面源码并不是真实的数字,随便点一个d标签查看其样式 我们需要找到两个文件,food.cs ...
- python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题
python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题 一丶爬虫概述 通过编写程序'模拟浏览器'上网,然后通 ...
- 常见的反爬措施:UA反爬和Cookie反爬
摘要:为了屏蔽这些垃圾流量,或者为了降低自己服务器压力,避免被爬虫程序影响到正常人类的使用,开发者会研究各种各样的手段,去反爬虫. 本文分享自华为云社区<Python爬虫反爬,你应该从这篇博客开 ...
- 如何制作图标字体(如何将svg转换为css可用的图标字体)
转自: 如何制作图标字体(如何将svg转换为css可用的图标字体) 具体描述 在项目开发当中,我们常常遇到需要将获取到的svg转换为,css可用的图标字体,那么具体该如何进行操作呢 具体操作 登录ic ...
- 爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider)
爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider),这之间的斗争恢宏壮阔... Day 1小莫想要某站上所有的电影,写了标准的爬虫(基于HttpCli ...
- (转)unity3D 如何提取游戏资源 (反编译)+代码反编译
原帖:http://bbs.9ria.com/thread-401140-1-1.html 首先感谢 雨松MOMO 的一篇帖子 教我们怎么提取 .ipa 中的游戏资源.教我们初步的破解unity3d资 ...
- Android反编译(二)之反编译XML资源文件
Android反编译(二) 之反编译XML资源文件 [目录] 1.工具 2.反编译步骤 3.重新编译APK 4.实例 5.装X技巧 6.学习总结 1.工具 1).反编译工具 apktool http ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
- 转 谈谈android反编译和防止反编译的方法
谈谈android反编译和防止反编译的方法 android基于java的,而java反编译工具很强悍,所以对正常apk应用程序基本上可以做到100%反编译还原. 因此开发人员如果不准备开源自己的项 ...
随机推荐
- 软件光栅器实现(四、OBJ文件加载)
本节介绍软件光栅器的OBJ和MTL文件加载,转载请注明出处. 在管线的应用程序阶段,我们需要设置光栅器所渲染的模型数据.这些模型数据包括模型顶点的坐标.纹理.法线和材质等等,可以由我们手动编写,也可以 ...
- 模板层template
继续之前的views,你可 能已经注意到我们例子中视图中返回的的方式有点特别.也就是说.HTML被直接硬编码在Python代码之中 def current_datetime(request): now ...
- C++ boost.python折腾笔记
为了让当年研究生时写的图像处理系统重出江湖起到更大的作用,应研究生导师的意见,对原有的c++框架做了python扩展处理,为了避免遗忘,备注如下: 一.boost 编译 下载boost源码,这里使用b ...
- Redhat 6.7 x64升级SSH到OpenSSH_7.4p1完整文档
原文链接:https://www.cnblogs.com/xshrim/p/6472679.html 导语 Redhat企业级系统的6.7版自带SSH版本为OpenSSH_5.3p1, 基于审计和安全 ...
- linux(Redhat7)安装Apache
1.下载apache安装包以及安装依赖的包(apr.apr-util.pcre)wget https://mirrors.cnnic.cn/apache/httpd/httpd-2.4.37.tar. ...
- HTML5元素标记释义
HTML5元素标记释义 标记 类型 意义 介绍 文件标记 <html> ● 根文件标记 让浏览器知道这是HTML 文件 META标记 <head> ● 开头 提供文件整体信息 ...
- linux 值安装yum包
1. 创建文件,挂载 rhel7-repo-iso [root@rhel7 ~]# mkdir /media/rhel7-repo-iso [root@rhel7 ~]# mount /dev/cd ...
- VSCode插件开发全攻略(一)概览
文章索引 VSCode插件开发全攻略(一)概览 VSCode插件开发全攻略(二)HelloWord VSCode插件开发全攻略(三)package.json详解 VSCode插件开发全攻略(四)命令. ...
- Jenkins常见REST API(便于将Jenkins集成到其他系统)
1.运行job a.无参任务 curl -XPOST http://IP:8080/jenkins/job/plugin%20demo/build --user admin:admin b.含参任务 ...
- 微信小程序wx.request接口
微信小程序wx.request接口 wx.request是小程序客户端与服务器端交互的接口 HTTPS 请求 一个微信小程序,只能同时(同时不能大于5个)有5个网络请求 wx.request(OBJE ...