HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言
首先先介绍一下Jsoup:(摘自官网)
jsoup is a Java library for working with real-world HTML. It provides a very convenient API for extracting and manipulating data, using the best of DOM, CSS, and jquery-like methods.
Jsoup俗称“大杀器”,具体的使用大家可以看 jsoup中文文档
代码编写
首先maven引包:
- <dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>- <dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.9</version>
</dependency>
- <dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
封装几个方法(思路大多都在注解里面,相信大家都看得懂):
- /**
- * 创建.txt文件
- *
- * @param fileName 文件名(小说名)
- * @return File对象
- */
- public static File createFile(String fileName) {
- //获取桌面路径
- String comPath = FileSystemView.getFileSystemView().getHomeDirectory().getPath();
- //创建空白文件夹:networkNovel
- File file = new File(comPath + "\\networkNovel\\" + fileName + ".txt");
- try {
- //获取父目录
- File fileParent = file.getParentFile();
- if (!fileParent.exists()) {
- fileParent.mkdirs();
- }
- //创建文件
- if (!file.exists()) {
- file.createNewFile();
- }
- } catch (Exception e) {
- file = null;
- System.err.println("新建文件操作出错");
- e.printStackTrace();
- }
- return file;
- }
- /**
- * 字符流写入文件
- *
- * @param file file对象
- * @param value 要写入的数据
- */
- public static void fileWriter(File file, String value) {
- //字符流
- try {
- FileWriter resultFile = new FileWriter(file, true);//true,则追加写入
- PrintWriter myFile = new PrintWriter(resultFile);
- //写入
- myFile.println(value);
- myFile.println("\n");
- myFile.close();
- resultFile.close();
- } catch (Exception e) {
- System.err.println("写入操作出错");
- e.printStackTrace();
- }
- }
- /**
- * 采集当前url完整response实体.toString()
- *
- * @param url url
- * @return response实体.toString()
- */
- public static String gather(String url,String refererUrl) {
- String result = null;
- try {
- //创建httpclient对象 (这里设置成全局变量,相对于同一个请求session、cookie会跟着携带过去)
- CloseableHttpClient httpClient = HttpClients.createDefault();
- //创建get方式请求对象
- HttpGet httpGet = new HttpGet(url);
- httpGet.addHeader("Content-type", "application/json");
- //包装一下
- httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36");
- httpGet.addHeader("Referer", refererUrl);
- httpGet.addHeader("Connection", "keep-alive");
- //通过请求对象获取响应对象
- CloseableHttpResponse response = httpClient.execute(httpGet);
- //获取结果实体
- if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
- result = EntityUtils.toString(response.getEntity(), "GBK");
- }
- //释放链接
- response.close();
- }
- //这里还可以捕获超时异常,重新连接抓取
- catch (Exception e) {
- result = null;
- System.err.println("采集操作出错");
- e.printStackTrace();
- }
- return result;
- }
- /**
- * 使用jsoup处理html字符串,根据规则,得到当前章节名以及完整内容跟下一章的链接地址
- * 每个站点的代码风格都不一样,所以规则要根据不同的站点去修改
* 比如这里的文章内容直接用一个div包起来,而有些站点是每个段落用p标签包起来- * @param html html字符串
- * @return Map<String,String>
- */
- public static Map<String, String> processor(String html) {
- HashMap<String, String> map = new HashMap<>();
- String chapterName;//章节名
- String chapter = null;//完整章节(包括章节名)
- String next = null;//下一章链接地址
- try {
- //解析html格式的字符串成一个Document
- Document doc = Jsoup.parse(html);
- //章节名称
- Elements bookname = doc.select("div.bookname > h1");
- chapterName = bookname.text().trim();
- chapter = chapterName +"\n";
- //文章内容
- Elements content = doc.select("div#content");
- String replaceText = content.text().replace(" ", "\n");
- chapter = chapter + replaceText;
- //下一章
- Elements nextText = doc.select("a:matches((?i)下一章)");
- if (nextText.size() > 0) {
- next = nextText.attr("href");
- }
- map.put("chapterName", chapterName);//章节名称
- map.put("chapter", chapter);//完整章节内容
- map.put("next", next);//下一章链接地址
- } catch (Exception e) {
- map = null;
- System.err.println("处理数据操作出错");
- e.printStackTrace();
- }
- return map;
- }
- /**
- * 递归写入完整的一本书
- * @param file file
- * @param baseUrl 基础url
- * @param url 当前url
- * @param refererUrl refererUrl
- */
- public static void mergeBook(File file, String baseUrl, String url, String refererUrl) {
- String html = gather(baseUrl + url,baseUrl +refererUrl);
- Map<String, String> map = processor(html);
- //追加写入
- fileWriter(file, map.get("chapter"));
- System.out.println(map.get("chapterName") + " --100%");
- if (!StringUtils.isEmpty(map.get("next"))) {
//递归- mergeBook(file, baseUrl, map.get("next"),url);
- }
- }
main测试:
- public static void main(String[] args) {
- //需要提供的条件:站点;小说名;第一章的链接;refererUrl
- String baseUrl = "http://www.biquge.com.tw";
- File file = createFile("斗破苍穹");
- mergeBook(file, baseUrl, "/1_1999/1179371.html","/1_1999/");
- }
效果
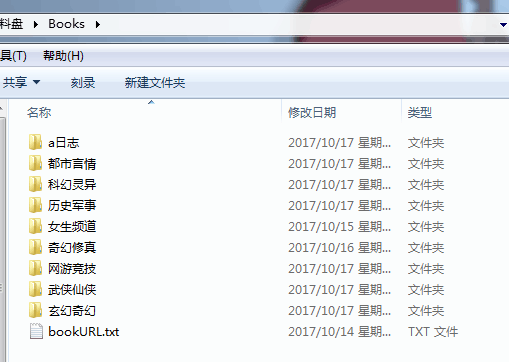
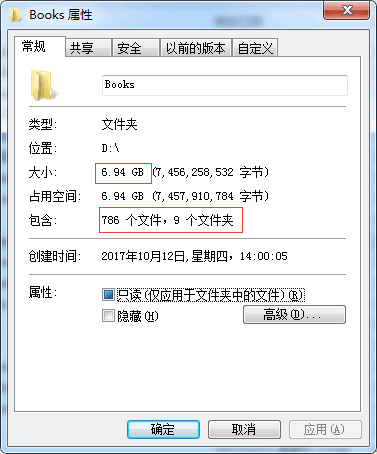
给大家看一下我之前爬取的数据,多开几个进程,挂机爬,差不多七个G,七百八十多部小说
代码开源
代码已经开源、托管到我的GitHub、码云:
GitHub:https://github.com/huanzi-qch/spider
码云:https://gitee.com/huanzi-qch/spider
HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件的更多相关文章
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 1. 首先导入相关的模块 import os import requests from ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- scrapycrawl 爬取笔趣阁小说
前言 第一次发到博客上..不太会排版见谅 最近在看一些爬虫教学的视频,有感而发,大学的时候看盗版小说网站觉得很能赚钱,心想自己也要搞个,正好想爬点小说能不能试试做个网站(网站搭建啥的都不会...) 站 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- 免app下载笔趣阁小说
第一次更新:发现一个问题,就是有时候网页排版有问题的话容易下载到多余章节,如下图所示: 网站抽风多了一个正文一栏,这样的话就会重复下载1603--1703章节. 解决办法: 于是在写入内容前加了一个章 ...
- 笔趣阁小说 selenium爬取
import re from time import sleep from lxml import etree from selenium import webdriver options = web ...
随机推荐
- 【慕课网实战】五、以慕课网日志分析为例 进入大数据 Spark SQL 的世界
提交Spark Application到环境中运行spark-submit \--name SQLContextApp \--class com.imooc.spark.SQLContextApp \ ...
- JSON.parse()——Uncaught SyntaxError: Unexpected token \ in JSON at position 1
背景:项目安全处理方面之一 ——对特殊字符进行编解码(后端编码,前端解码) 特殊字符: " %22 \ %5C / %2F & %26 % %25 ' ...
- B树/[oracle]connect BY语句
读大神的书,出现很多没有见过的函数和便捷操作,特此记录 connect by 之前没有接触过,为了学习这个语句,先了解一下B树数据类型是最好的方法. [本人摘自以下博客] https://www.cn ...
- Centos7 网络报错Job for iptables.service failed because the control process exited with error code.
今天在进行项目联系的时候,启动在待机的虚拟机,发现虚拟机的网络设置又出现了问题. 我以为像往常一样重启网卡服务就能成功,但是它却报了Job for iptables.service failed be ...
- UML顺序图知识点介绍(Sequence Diagram)
消息 调用消息 调用(procedure call)消息的发送者把控制传递给消息的接收者,然后停止活动,等待消息接受者放弃会返回控制 在Rational Rose(2016版本如图所示) 异步消息 异 ...
- 对js中闭包,作用域,原型的理解
前几天,和朋友聊天,聊到一些js的基础的时候,有一种‘好像知道,好像又不不知道怎么讲的感觉’...于是捡起书,自己理一理,欢迎拍砖. 闭包 理解闭包首先要理解,js垃圾回收机制,也就是当一个函数被执行 ...
- [Postman]拦截器扩展(15)
什么是拦截器 注意: Interceptor功能仅在我们的Postman Chrome应用程序中受支持,目前在Postman桌面应用程序中不可用.如果您希望我们的桌面应用程序中提供此功能,请在此处告知 ...
- 微信公众号接入之排序问题小记 Arrays.sort()
微信公众号作为强大的自媒体工具,对接一下是很正常的了.不过这不是本文的方向,本文的方向公众号接入的排序问题. 最近接了一个重构的小项目,需要将原有的php的公众号后台系统,转换为java系统.当然,也 ...
- MySQL 报错ERROR 1054 (42S22): Unknown column 'plugin' in 'mysql.user'
MySQL 我们在创建用户的时候,可能会遇到以下报错: ERROR 1054 (42S22): Unknown column 'plugin' in 'mysql.user' 说明mysq.user ...
- 寒假小软件开发记录06--apk生成
先在strings.xml中修改了软件名称,再修改软件图标. 在Android模式下,进入Image Asset,进行图标的修改: android studio中,build->generate ...