【zookeeper】4、利用zookeeper,借助观察模式,判断服务器的上下线
首先什么是观察者模式,可以看看我之前的设计模式的文章
https://www.cnblogs.com/cutter-point/p/5249780.html
确定一下,要有观察者,要有被观察者,然后要被观察者触发事件,事件发生之后,观察者触发相应的事件发生
了解了基本概念,我们来看看zookeeper是什么情况
zookeeper也是类似观察者一样,我们先把本机信息注册进入服务器,然后设置一个watch方法,这个在zookeeper节点发生变化的时候通知对应的客户端,触发对应的方法
这里先注册服务,如何向zookeeper进行注册呢
package cn.cutter.demo.hadoop.zookeeper; import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat; /**
* @ProjectName: cutter-point
* @Package: cn.cutter.demo.hadoop.zookeeper
* @ClassName: TimeQueryServer
* @Author: xiaof
* @Description: 利用zookeeper来进行分布式时间查询
* @Date: 2019/4/2 19:37
* @Version: 1.0
*/
public class TimeQueryServer { private ZooKeeper zooKeeper; // 构造zk客户端连接
public void connectZK() throws Exception{
zooKeeper = new ZooKeeper("192.168.1.4:2181,192.168.1.4:2182,192.168.1.4:2183", 2000, null);
} // 注册服务器信息
public void registerServerInfo(String hostname,String port) throws Exception{ /**
* 先判断注册节点的父节点是否存在,如果不存在,则创建
*/
Stat stat = zooKeeper.exists("/servers", false);
if(stat==null){
zooKeeper.create("/servers", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} // 注册服务器数据到zk的约定注册节点下
String create = zooKeeper.create("/servers/server", (hostname+":"+port).getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); System.out.println(hostname+" 服务器向zk注册信息成功,注册的节点为:" + create); } }
如果注入了服务,那么我们为了监控这个服务的存在,那么是不是应该也模拟一个服务?
好,这里我们就做一个时钟同步的服务,用消费线程不断请求服务,并获取当前时间
package cn.cutter.demo.hadoop.zookeeper; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory; import java.io.IOException;
import java.io.InputStream;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Date;
import java.util.Iterator; /**
* @ProjectName: cutter-point
* @Package: cn.cutter.demo.hadoop.zookeeper
* @ClassName: TimeQueryService
* @Author: xiaof
* @Description: ${description}
* @Date: 2019/4/2 19:43
* @Version: 1.0
*/
public class TimeQueryService extends Thread { private static final Log log = LogFactory.getLog(TimeQueryService.class); int port = 0; public TimeQueryService(int port) {
this.port = port;
} @Override
public void run() { //1.创建信道选择器
Selector selector = null;
//不断读取字符,只有读到换行我们才进行输出
// StringBuffer stringBuffer = new StringBuffer();
try {
selector = Selector.open();
//2.创建对应端口的监听
//2.1 创建通道
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
//2.2 socket 对象绑定端口 socket() 获取与此通道关联的服务器套接字
serverSocketChannel.socket().bind(new InetSocketAddress(port));
//2.3 设置为非阻塞
serverSocketChannel.configureBlocking(false);
//注册到对应的选择器,读取信息
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
//3.轮询获取信息
while (true) {
//获取socket对象
//获取准备好的信道总数
if (!selector.isOpen()) {
System.out.println("is close over");
break;
} try {
if (selector.select(3000) == 0) {
continue; //下一次循环
}
} catch (IOException e) {
e.printStackTrace();
} //获取信道
Iterator<SelectionKey> keyIterable = selector.selectedKeys().iterator();
while (keyIterable.hasNext()) {
//6.遍历键集,判断键类型,执行相应的操作
SelectionKey selectionKey = keyIterable.next();
//判断键类型,执行相应操作
if (selectionKey.isAcceptable()) {
try {
//从key中获取对应信道
//接受数据
SocketChannel socketChannel = ((ServerSocketChannel) selectionKey.channel()).accept();
//并设置成非阻塞
socketChannel.configureBlocking(false);
//从新注册,修改状态
socketChannel.register(selectionKey.selector(), SelectionKey.OP_READ, ByteBuffer.allocate(1024));
} catch (IOException e) {
e.printStackTrace();
}
} if (selectionKey.isReadable()) {
//读取数据
SocketChannel socketChannel = (SocketChannel) selectionKey.channel();
//获取当前的附加对象。
ByteBuffer byteBuffer = (ByteBuffer) selectionKey.attachment(); //判断是是否断开连接
int count = 0;
while (true) {
try {
if (!((count = socketChannel.read(byteBuffer)) != 0 && count != -1 && selectionKey.isValid())) {
if(count == -1) {
//关闭通道
socketChannel.close();
}
break;
}
} catch (IOException e) {
// e.printStackTrace();
try {
//如果读取数据会抛出异常,那么就断定通道已经被客户端关闭
socketChannel.close();
} catch (IOException e1) {
e1.printStackTrace();
}
System.out.println("无法读取数据!");
break;
}
//判断是否有换行
// byteBuffer.flip();
byte msg[] = byteBuffer.array();
boolean isOver = false;
int i = byteBuffer.position() - count;
for (; i < byteBuffer.position(); ++i) {
//判断是否有换行
if (byteBuffer.get(i) == '\r' || byteBuffer.get(i) == '\n') {
//输出
//先压缩数据
byteBuffer.flip();
byte out[] = new byte[byteBuffer.limit()];
byteBuffer.get(out, 0, out.length);
log.info(new String(out));
//设置成可以读和可写状态
byteBuffer.compact();
byteBuffer.clear();
isOver = true;
}
}
if (isOver == true) {
// interestOps(SelectionKey.OP_READ);的意思其实就是用同一个KEY重新注册
selectionKey.interestOps(SelectionKey.OP_READ | SelectionKey.OP_WRITE);
break;
}
} if (count == -1) {
//如果是-1 ,那么就关闭客户端
try {
socketChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
} else {
// selectionKey.interestOps(SelectionKey.OP_READ | SelectionKey.OP_WRITE);
}
} //告知此键是否有效。
if (selectionKey.isValid() && selectionKey.isWritable()) {
//获取当前的附加对象。
// ByteBuffer byteBuffer = (ByteBuffer) selectionKey.attachment();
// 清空,并写入数据
// byteBuffer.clear();
byte smsBytes[] = (new Date().toString() + "\n").getBytes();
ByteBuffer byteBuffer = ByteBuffer.wrap(smsBytes);
// byteBuffer.put(smsBytes);
SocketChannel socketChannel = (SocketChannel) selectionKey.channel();
//写入数据
// System.out.println(new String(byteBuffer.array()));
while (byteBuffer.hasRemaining()) {
//输出数据
try {
socketChannel.write(byteBuffer);
} catch (IOException e) {
e.printStackTrace();
}
}
//判断是否判断是否有待处理数据
if (!byteBuffer.hasRemaining()) {
//数据清理干净
selectionKey.interestOps(SelectionKey.OP_READ);
}
//压缩此缓冲区将缓冲区的当前位置和界限之间的字节(如果有)复制到缓冲区的开始处。
// 即将索引 p = position() 处的字节复制到索引 0 处,将索引 p + 1 处的字节复制到索引 1 处,依此类推,直到将索引 limit() - 1 处的字节复制到索引
// n = limit() - 1 - p 处。然后将缓冲区的位置设置为 n+1,并将其界限设置为其容量。如果已定义了标记,则丢弃它。
//将缓冲区的位置设置为复制的字节数,而不是零,以便调用此方法后可以紧接着调用另一个相对 put 方法。
//从缓冲区写入数据之后调用此方法,以防写入不完整。例如,以下循环语句通过 buf 缓冲区将字节从一个信道复制到另一个信道:
byteBuffer.compact();
} //执行操作的时候,移除避免下一次循环干扰
// 原因是Selector不会自己从已选择键集中移除SelectionKey实例。必须在处理完通道时自己移除。下次该通道变成就绪时,Selector会再次将其放入已选择键集中
keyIterable.remove(); } } }
}
说实话,这个服务端当时花了好大的力气写完的,mmp,因为客户端进行可以不关闭通道直接kill,导致服务端并不知道对端已经离线,到时候服务端不断再进行空轮训,一旦进行read就抛出io异常!!
好了,服务和注册写完了,那么我们注册一把呗
@Test
public void test1() throws Exception {
TimeQueryServer timeQueryServer = new TimeQueryServer(); // 构造zk客户端连接
timeQueryServer.connectZK(); // 注册服务器信息
timeQueryServer.registerServerInfo("192.168.1.7", "8888"); // 启动业务线程开始处理业务
new TimeQueryService(Integer.parseInt("8888")).start(); while(true) {
Thread.sleep(200000);
// System.out.println("..");
}
}
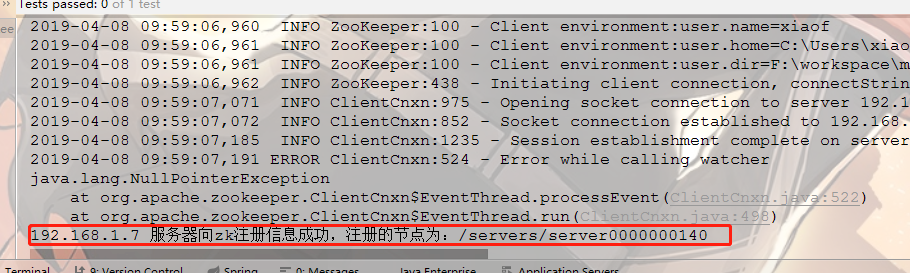
不要在意那个null异常,那是因为我爸watch设置为null的原因
服务端写完了,我们再考虑写一波客户端
package cn.cutter.demo.hadoop.zookeeper; import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper; import java.net.InetSocketAddress;
import java.net.SocketException;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import java.util.ArrayList;
import java.util.List;
import java.util.Random; /**
* @ProjectName: cutter-point
* @Package: cn.cutter.demo.hadoop.zookeeper
* @ClassName: Consumer
* @Author: xiaof
* @Description: ${description}
* @Date: 2019/4/3 14:11
* @Version: 1.0
*/
public class Consumer { // 定义一个list用于存放最新的在线服务器列表
private volatile ArrayList<String> onlineServers = new ArrayList<>(); // 构造zk连接对象
ZooKeeper zk = null; // 构造zk客户端连接
public void connectZK() throws Exception { zk = new ZooKeeper("192.168.1.4:2181,192.168.1.4:2182,192.168.1.4:2183", 2000, new Watcher() { @Override
public void process(WatchedEvent event) {
if (event.getState() == Event.KeeperState.SyncConnected && event.getType() == Event.EventType.NodeChildrenChanged) { try {
// 事件回调逻辑中,再次查询zk上的在线服务器节点即可,查询逻辑中又再次注册了子节点变化事件监听
getOnlineServers();
} catch (Exception e) {
e.printStackTrace();
} } }
}); } // 查询在线服务器列表
public void getOnlineServers() throws Exception { List<String> children = zk.getChildren("/servers", true);
ArrayList<String> servers = new ArrayList<>(); for (String child : children) {
byte[] data = zk.getData("/servers/" + child, false, null); String serverInfo = new String(data); servers.add(serverInfo);
} onlineServers = servers;
System.out.println("查询了一次zk,当前在线的服务器有:" + servers); } public void sendRequest() throws Exception {
Random random = new Random();
while (true) {
try {
// 挑选一台当前在线的服务器
int nextInt = random.nextInt(onlineServers.size());
String server = onlineServers.get(nextInt);
String hostname = server.split(":")[0];
int port = Integer.parseInt(server.split(":")[1]); System.out.println("本次请求挑选的服务器为:" + server); //2.打开socket信道,设置成非阻塞模式
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false); //3.尝试建立连接,然后轮询,判定,连接是否完全建立
int times = 0;
if(!socketChannel.connect(new InetSocketAddress(hostname, port))) {
while(!socketChannel.finishConnect()) {
// System.out.println(times++ + ". ");
}
} //4.创建相应的buffer缓冲
ByteBuffer writeBuffer = ByteBuffer.wrap("test\n".getBytes());
ByteBuffer readBuffer = ByteBuffer.allocate(1024);
int totalBytesRcvd = 0;
int bytesRcvd; //5.向socket信道发送数据,然后尝试读取数据
socketChannel.write(writeBuffer);
//读取数据
if((bytesRcvd = socketChannel.read(readBuffer)) == -1) {
//这种非阻塞模式,如果读取不到数据是会返回0的,如果是-1该通道已到达流的末尾
throw new SocketException("连接关闭??");
} //不停尝试获取数据,这是因为服务端数据反馈太慢了???
while (bytesRcvd == 0) {
bytesRcvd = socketChannel.read(readBuffer);
} //6.输出
readBuffer.flip();
byte reads[] = new byte[readBuffer.limit()];
readBuffer.get(reads, 0, reads.length);
System.out.println("收到信息:" + new String(reads)); //7.关闭信道
socketChannel.close(); Thread.sleep(3000);
} catch (Exception e) {
e.printStackTrace();
} } } public static void main(String[] args) throws Exception { Consumer consumer = new Consumer();
// 构造zk连接对象
consumer.connectZK(); // 查询在线服务器列表
consumer.getOnlineServers(); // 处理业务(向一台服务器发送时间查询请求)
consumer.sendRequest(); } }
启动客户端:
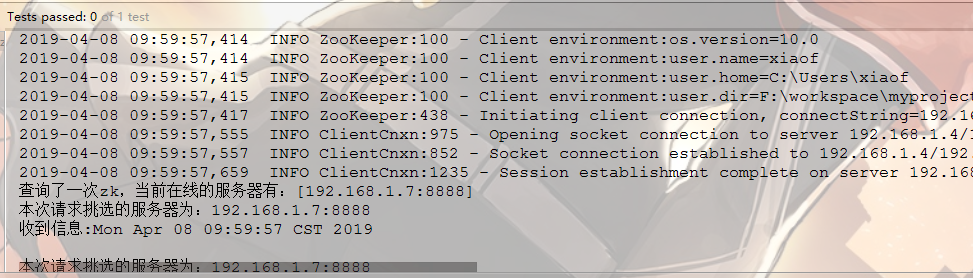
为了体现zookeeper监控服务是否在线的操作,我们多起几个服务端,然后监控客户端的信息展示

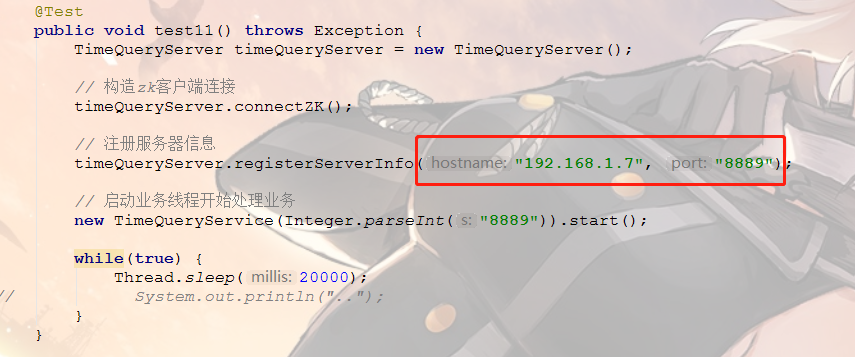
我们再起一个


接下来我们kill掉8888端口的进程

我们当前在线可以看到只有2个节点了,我们上zk看看,确实只有2个了
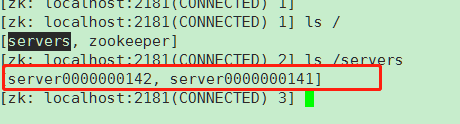
到这里zookeeper的上下线的判断已经完成,我最近再自学大数据的东西,想向大数据进军一波,欢迎大家一起探讨大数据的学习。
【zookeeper】4、利用zookeeper,借助观察模式,判断服务器的上下线的更多相关文章
- ZooKeeper之服务器动态上下线案例
需求 某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线. 需求分析 具体实现 先在集群上创建/servers节点 create /servers &q ...
- 【Zookeeper】利用zookeeper搭建Hdoop HA高可用
HA概述 所谓HA(high available),即高可用(7*24小时不中断服务). 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA. ...
- 学习笔记:Zookeeper 应用案例(上下线动态感知)
1.Zookeeper 应用案例(上下线动态感知) 8.1 案例1--服务器上下线动态感知 8.1.1 需求描述 某分布式系统中,主节点可以有多台,可以动态上下线 任意一台客户端都能实时感知到主节点服 ...
- php利用zookeeper作dispatcher服务器
===== https://blog.eood.cn/php_share_memory 最常见的apc 可以缓存php的opcode提高应用的性能,可以在同个php-fpm进程池间共享数据 常见功能: ...
- Zookeeper实战之单机集群模式
前一篇文章介绍了Zookeeper的单机模式的安装及应用,但是Zookeeper是为了解决分布式应用场景的,所以通常都会运行在集群模式下.今天由于手头机器不足,所以今天打算在一台机器上部署三个Zook ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- Zookeeper学习(八):Zookeeper的数据发布与订阅模式
http://blog.csdn.net/ZuoAnYinXiang/article/category/6104448 1.发布订阅的基本概念 1.发布订阅模式可以看成一对多的关系:多 ...
- Zookeeper安装,Zookeeper单机模式安装
http://zookeeper.apache.org/releases.html#download 下载解压到(我自己的)解压到 /usr/local 下 把名字改成 zookeeper 进入zoo ...
- 【Hadoop 分布式部署 八:分布式协作框架Zookeeper架构功能讲解 及本地模式安装部署和命令使用 】
What is Zookeeper 是一个开源的分布式的,为分布式应用提供协作服务的Apache项目 提供一个简单的原语集合,以便与分布式应用可以在他之上构建更高层次的同步服务 设计非常简单易于编 ...
随机推荐
- Firefox 调试 JavaScript 代码
第一步 新建 html 或者 jsp 文件 文件内容 <!DOCTYPE html> <html> <head> <meta charset="u ...
- ArrayList增加扩容问题 源码分析
public class ArrayList<E>{ private static final int DEFAULT_CAPACITY = 10;//默认的容量是10 private s ...
- 使用signalr实现网页和微信公众号实时聊天(上)
最近项目中需要实现客户在公众号中和客服(客服使用后台网站系统)进行实时聊天的功能.折腾了一段时间,实现了这个功能.现在将过程记录下,以便有相同需求的同行可以参考,也是自己做个总结.这篇是上,用手机编辑 ...
- 偏差(Bias)和方差(Variance)——机器学习中的模型选择zz
模型性能的度量 在监督学习中,已知样本 ,要求拟合出一个模型(函数),其预测值与样本实际值的误差最小. 考虑到样本数据其实是采样,并不是真实值本身,假设真实模型(函数)是,则采样值,其中代表噪音,其均 ...
- Java基础之一
移位操作符 移位操作符只可用来处理整数类型. <<:左移位操作符,按照操作符右侧指定的位数将操作符左边的操作数向左移动,在低位补0. >>:“有符号”右移位操作符,按照操作符右 ...
- 关闭iptables服务及命令行连接wifi及locale设置
Ubuntu系统启动时都会自动启动iptables服务.如果想关闭该服务的自动启动,可以执行: sudo ufw disable 命令行方式连接某个SSID: sudo nmcli d wifi co ...
- CentOS 6下升级Python版本
CentOS6.8默认的python版本是2.6,而现在好多python组件开始只支持2.7以上的版本,比如说我今天遇到的pip install pysqlite,升级python版本是一个痛苦但又常 ...
- npm Error: Cannot find module './auth.js'
Mac 下升级 npm 到 v6.8.0 翻车. 提示: Error: Cannot find module './auth.js' 根据回显的报错路径,定位到这个文件中: npm/node_modu ...
- Ubuntu14.04下中文输入法拼音不正常问题 输入nihao会变成niha o
1. 打开输入法首选项,选择拼音模式,选择全拼 2. 在终端中输入ibus-daemon –drx
- sublime text3如何在浏览器预览?
插件: view-in-browser CTRL + ALT + V 打开浏览器 默认打开firefox,settings里面可修改. Sublime Text - View In Browser V ...