MySQL主从1205报错【转】
主从报错1205 Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable
Last_Errno: 1205
Last_Error: Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable

解决办法:
stop slave;
start slave;
show slave status\G;
大家都知道DBA就像是消(背)防(锅)员(侠),因为前端应用还有开发上线的新版本都会影响到位于最底层的数据库,前方稍微有些风吹草动,就能反应在数据库的性能上。但是有的时候SQL不仅能决定数据库的性能,还能决定数据库的生死,今天的案例是开发的一条SQL,引起的MySQL数据库主从复制报错,vip漂移问题。
今天下午有客户反馈发消息有点慢,手机收到几条报警:
nagios报警如下大致意思就是
14:39分 vip发生了漂移
**** Nagios *****
Notification Type: PROBLEM
Service: check_ha_mysqld
Host: prod-bjuc-mysql1-vip
Address: 192.168.87.74
State: CRITICAL
Date/Time: Wed Mar 28 14:39:27 CST 2018
Additional Info:
CRITICAL: HA Failover from 192.168.87.72 to 192.168.87.123,
192.168.87.123 result:PROCS OK: 1 processes with command name /usr/sbin/mysqld,
args VIP=192.168.87.74, 192.168.87.72:PROCS OK: 1 processes with command name /usr/sbin/mysqld14:46分主从复制中断
***** Nagios *****
Notification Type: PROBLEM
Service: check_mysql_health_slave-sql-running
Host: bjuc-mysql1
Address: 192.168.87.72
State: CRITICAL
Date/Time: Wed Mar 28 14:46:06 CST 2018
Additional Info:
CRITICAL - Slave sql is not running登录数据库服务器查看主从复制的状态,发现报错1205错
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.87.123
Master_User: zhu
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000481
Read_Master_Log_Pos: 218802975
Relay_Log_File: mysql-relay-bin.000428
Relay_Log_Pos: 2428110
Relay_Master_Log_File: mysql-bin.000481
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB: performance_schema,information_schema,test,mysql
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table: %.%
Replicate_Wild_Ignore_Table:
Last_Errno: 1205
Last_Error: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)'
Skip_Counter: 0
Exec_Master_Log_Pos: 182088298
Relay_Log_Space: 39142986
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1205
Last_SQL_Error: Error 'Lock wait timeout exceeded; try restarting transaction' on query.
Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)'
Replicate_Ignore_Server_Ids:
Master_Server_Id: 6
1 row in set (0.00 sec)查看错误日志有一下报错信息:
错误日志中给出了报错原因和解决方法
tail -70 error.log
180328 14:36:05 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:36:21 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:36:38 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:36:56 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:37:15 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:37:35 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:37:56 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:38:17 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:38:38 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:38:59 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:39:20 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:39:20 [ERROR] Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable.
180328 14:39:20 [Warning] Slave: Lock wait timeout exceeded; try restarting transaction Error_code: 1205
180328 14:39:20 [ERROR] Error running query, slave SQL thread aborted. Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'mysql-bin.000481' position 182088298查看参数结合着两个参数可以知道主从复制报错的原因为:
180328 14:39:20 [ERROR] Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable.
180328 14:39:20 [Warning] Slave: Lock wait timeout exceeded; try restarting transaction Error_code: 1205
180328 14:39:20 [ERROR] Error running query, slave SQL thread aborted,Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'mysql-bin.000481' position 182088298
因为表notice_status_new产生了锁,阻塞了这条update语句
参数innodb_lock_wait_time 设置的为15秒,单个事务在等待15秒后开始报1025错:因为锁执行超时并重启事务
参数slave_transaction_retries 设置的为10次,如果事务重试次数超过10次,复制中断。(但是错误日志中尝试了11次)
mysql> show variables like '%innodb_lock_wait_timeout%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 15 |
+--------------------------+-------+
1 row in set (0.01 sec)
mysql> show variables like '%slave_transaction_retries%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| slave_transaction_retries | 10 |
+---------------------------+-------+
1 row in set (0.00 sec)解决方法:重启slave后主从复制恢复,并开始追日志
mysql> stop slave;
Query OK, 0 rows affected (0.02 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
1 row in set (0.00 sec)vip的问题等到晚上在切回来,
---------------------------------我是分割线--------------------------
这次问题虽然解决了,但是发现问题我们一定要找到根音,这样问题才能算是闭环。
为什么会产生这个锁呢,因为记录锁信息的表都是实时的,现在查不出当时的锁信息,但是从存储引擎的运行状态中还是能发现一些问题,数据库出现了死锁!!显然在update这张表一定会等待的!!
发现了一条奇葩SQL,被锁的那张表也是notice_status_new
UPDATE notice_status_new SET count = count + 1, push_count = push_count + 1 WHERE conversation = 2609759 AND user_id != 7384662 AND user_id IN(7359498)
show engine innodb status\G
截取死锁的这部分
------------------------
LATEST DETECTED DEADLOCK
------------------------
180328 14:33:52
*** (1) TRANSACTION:
TRANSACTION 1B285E9F9, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 4 lock struct(s), heap size 1248, 3 row lock(s), undo log entries 1
MySQL thread id 3972036, OS thread handle 0x7fc0c3464700, query id 2525495433 192.168.87.42 dstatusnet Updating
UPDATE notice_status_new SET count = count + 1, push_count = push_count + 1 WHERE conversation = 2609759 AND user_id != 7384662 AND user_id IN(7359498)
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3535 page no 65360 n bits 448 index `conv_user` of table `statusnet`.`notice_status_new` trx id 1B285E9F9 lock_mode X locks rec but not gap waiting
Record lock, heap no 241 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 8; hex 000000000027d25f; asc ' _;;
1: len 4; hex 80704c0a; asc pL ;;
2: len 4; hex 80b1a0fe; asc ;;
*** (2) TRANSACTION:
TRANSACTION 1B285E9FD, ACTIVE 0 sec starting index read, thread declared inside InnoDB 500
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1248, 3 row lock(s), undo log entries 1
MySQL thread id 3867908, OS thread handle 0x7fbfc6d4f700, query id 2525495437 192.168.87.42 dstatusnet Updating
UPDATE notice_status_new SET count = count + 1, push_count = push_count + 1 WHERE conversation = 2609759 AND user_id != 7359498 AND user_id IN(7384662)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 3535 page no 65360 n bits 448 index `conv_user` of table `statusnet`.`notice_status_new` trx id 1B285E9FD lock_mode X locks rec but not gap
Record lock, heap no 241 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 8; hex 000000000027d25f; asc ' _;;
1: len 4; hex 80704c0a; asc pL ;;
2: len 4; hex 80b1a0fe; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3535 page no 65360 n bits 448 index `conv_user` of table `statusnet`.`notice_status_new` trx id 1B285E9FD lock_mode X locks rec but not gap waiting
Record lock, heap no 242 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 8; hex 000000000027d25f; asc ' _;;
1: len 4; hex 8070ae56; asc p V;;
2: len 4; hex 80b1a0fc; asc ;;
*** WE ROLL BACK TRANSACTION (2)问题找到了,找对该业务的开发,沟通后决定在周六上线新版本,彻底解决问题。
可以写一个实时监控锁的脚本,把内容输出打印,这样方便以后定位问题!
-----------------------------------------------
后面想了想可能是由于vip漂移导致的主从复制报错
线上架构为MM+heartbeat
vip漂移的原因待定,vip漂移后,数据库开始在192.168.87.123服务器上写入数据库,72数据库作为备份库,但是还会同步123数据库的数据,由于192.168.87.72数据库表notice_status_new还存在死锁,所以在slave SQL thread应用来自123服务器的中继日志时,执行到该SQL时,发生了锁等待,等待15秒后超时并重新尝试该事务,尝试10后,还是在锁表状态,slave SQL thread 线程停止工作,主从同步中断。
----------------------------------------
3月29日和开发复盘
因为报警时间不是很准确,实际时间还是以heartbeat日志和mysql日志为准,通过查看日志确定是heartbeat首先发生漂移,然后才是主从复制报错
主要是讨论的问题有两个
① Heartbeat为什么会发生漂移
通过查看heartbeat日志,72和123存在心跳检测,在72ping123的时候发生了丢包,
在123ping72的时候正常,72节点以为自己死掉?在14:35:26发生vip漂移,从72漂移到123。
Mar 28 14:35:26 bjuc-mysql1 pengine: [14176]: notice: LogActions: Move VIP_192_168_87_74 (Started bjuc-mysql1 -> prod-uc-yewu-db-slave2)
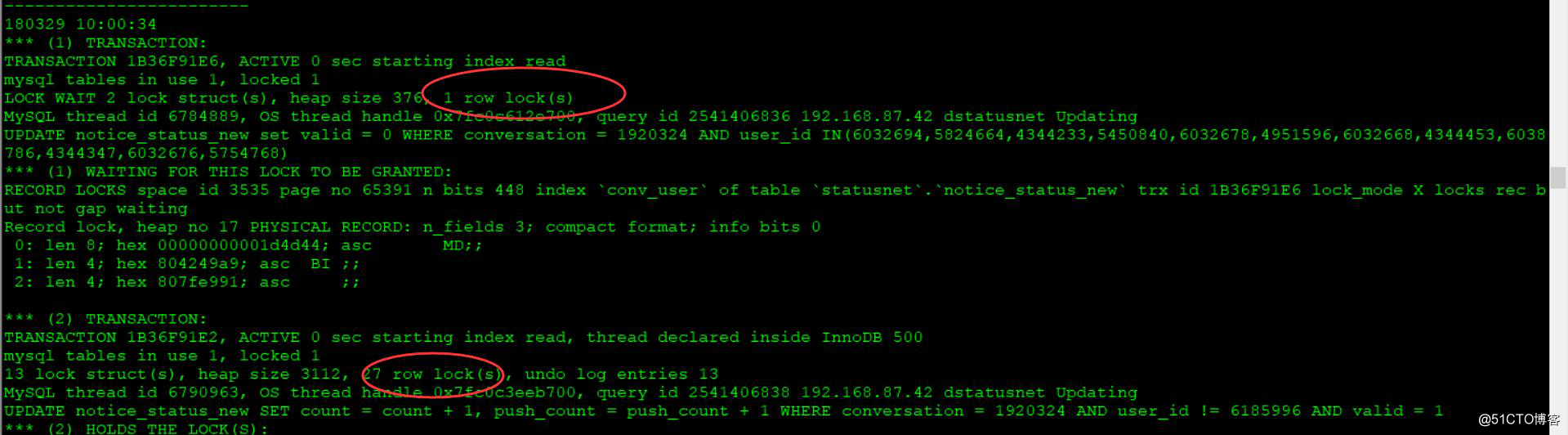
② 为什么会出现死锁
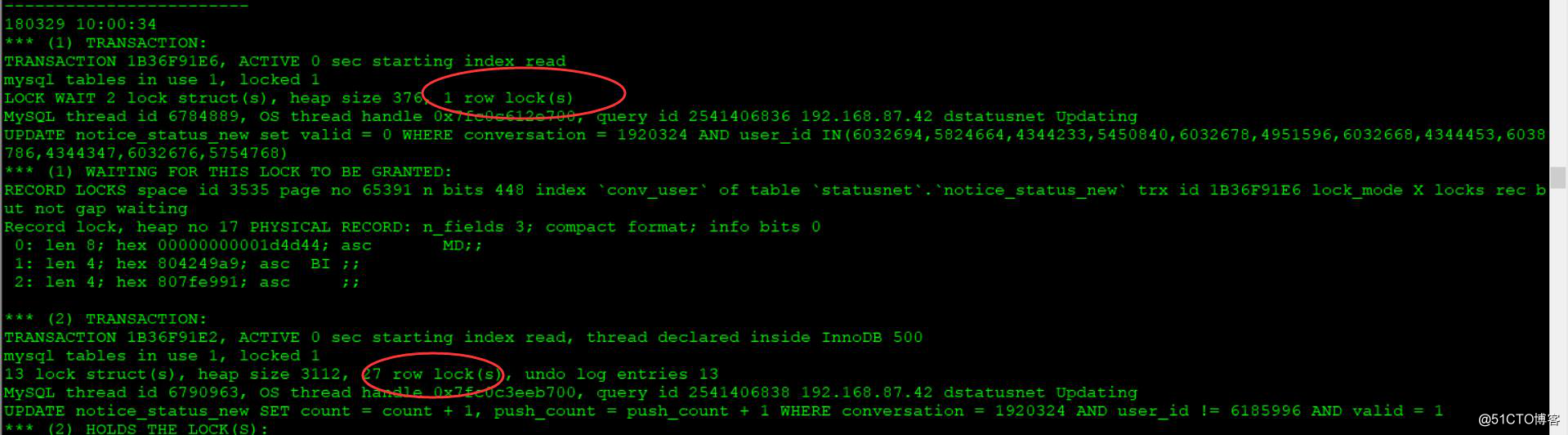
从存储引擎的运行状态中查看,如果这两条SQL的请求同时到达数据库,因为innodb支持到行锁的粒度,第二条SQL会锁住很多行,如果和第一条SQL中锁住有重复的,就会发生相互等待的状况,所以出现死锁。
这两条SQL的where条件如下:
user_id IN(6032694,5824664,4344233,5450840,6032678,4951596,6032668,4344453,6038786,4344347,6032676,5754768);
user_id != 6185996
这两个条件可能发生逻辑上的冲突,然后导致死锁
转自
MySQL主从复制报错 Errno 1205-11774929-51CTO博客 http://blog.51cto.com/11784929/2092097
MySQL主从1205报错【转】的更多相关文章
- mysql主从同步报错
主从不同步,经查看发现如下报错 Last_Errno: 1666 Last_Error: Error executing row event: 'Cannot execute statement: ...
- Mysql主从架构报错-Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work...
在搭建Mysql主从架构过程中,由于从服务器是克隆的主服务器系统,导致主从mysql uuid相同, Slave_IO无法启动,报错如下: The slave I/O thread stops bec ...
- MySQL主从同步报错排错结果及修复过程之:Slave_SQL_Running: No
起因调查: 收到大量邮件报警想必事出有因,就问同事到底发生了什么?同事登录从库查看,发现出现如下报错提示,表示与主库同步失败,一直卡在哪里,看他弄了两个多小时,问题越来越多,解决一个恢复平静了一两分钟 ...
- MySQL主从同步报错故障处理集锦
前言 在发生故障切换后,经常遇到的问题就是同步报错,下面是最近收集的报错信息. 记录删除失败 在master上删除一条记录,而slave上找不到 Last_SQL_Error: Could not e ...
- MySQL主从同步报错1507
mysql 从库上手动删除partiton后,主库未做修改.后期主库上删除partiton后,出现问题. 故障现场 Last_Errno: 1507 Last_Error: Error 'Error ...
- MySQL主从同步报错故障处理记录
从库上记录删除失败,Error_code: 1032 问题描述:在master上删除一条记录,而slave上找不到,导致报错 Last_SQL_Error: Could not execute Del ...
- CentOS命令登录MySQL时,报错ERROR 1045 (28000):
CentOS命令登录MySQL时,报错ERROR 1045 (28000): Access denied for user root@localhost (using password: NO)错误解 ...
- mysql执行update报错1175解决方法
mysql执行update报错 update library set status=true where 1=1 Error Code: 1175. You are using safe update ...
- Mysql update in报错 [Err] 1093 - You can't specify target table 'company_info' for update in FROM clause
Mysql update in报错 解决方案: [Err] 1093 - You can't specify target table 'company_info' for update in FRO ...
随机推荐
- urllib 学习一
说明:Urllib 是一个python用于操作URL的模块 python2.x ----> Urillib/Urllib2 python3.x ----> Urllib ...
- Sqlserver中的索引
一.什么是索引及索引的优缺点 1.1 索引的基本概念 数据库索引,是数据库管理系统中一个排序的数据结构,用来协助快速查询数据库表中数据. 简单理解索引就是一个排好顺序的目录,设置了索引就意味着进行了 ...
- idea使用maven打包项目
第一步:打开maven Projects 第二步.找到package 第三步,运行.到路径下面去找打包的文件吧. 第二种方法: 使用命令 cmd进入项目目录,例如项目在D盘项目名poject 输入: ...
- web.xml之<context-param>与<init-param>的区别与作用【转】
引用自-->http://www.cnblogs.com/hzj-/articles/1689836.html <context-param>的作用:web.xml的配置中<c ...
- 阅读:ECMAScript 6 入门(1)
参考 ECMAScript 6 入门 ES6新特性概览 ES6 全套教程 ECMAScript6 (原著:阮一峰) JavaScript 教程 重新介绍 JavaScript(JS 教程) 前言 学了 ...
- 快速傅里叶变换(Fast Fourier Transform, FFT)和短时傅里叶变换(short-time Fourier transform,STFT )【资料整理】【自用】
1. 官方形象展示FFT:https://www.bilibili.com/video/av19141078/?spm_id_from=333.788.b_636f6d6d656e74.6 2. 讲解 ...
- Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度.TaskScheduler也可以看作 ...
- Linux 下装逼技巧
``` 1.下载cmatrix-1.2a.tar.gz文件 [root@localhost ~]# wget https://jaist.dl.sourceforge.net/project/cmat ...
- 四十、Linux 线程——互斥锁和读写锁
40.1 互斥锁 40.1.1 介绍 互斥锁(mutex)是一种简单的加锁的方法来控制对共享资源的访问. 在同一时刻只能有一个线程掌握某个互斥锁,拥有上锁状态的线程能够对共享资源进行访问. 若其他线程 ...
- 【noip 2016】提高组
D1T1.玩具谜题 题目链接 直接模拟就好了……water. #include<cstdio> int n,m,a,s,ans; ];]; int main() { scanf(" ...