高并发的socket的高性能设计【转】
转自:https://blog.csdn.net/quincyfang/article/details/44654351
高性能数据传输系统的框架设计
1 引言
随着互联网和物联网的高速发展,使用网络的人数和电子设备的数量急剧增长,其也对互联网后台服务程序提出了更高的性能和并发要求。本文的主要目的是阐述在单机上如何进行高并发、高性能消息传输系统的框架设计,以及该系统的常用技术,但不对其技术细节进行讨论。如您有更好的设计方案和思路,望共分享之![注:此篇用select来讲解,虽在大并发的情况下,epoll拥有更高的效率,但整体设计思路是一致的]
首先来看看课本和学习资料上关于处理并发网络编程的三种常用方案,以及对应的大体思路和优缺点:
1) IO多路复用模型
->思路:单进程(非多线程)调用select()函数来处理多个连接请求。
->优点:单进程(非多线程)可支持同时处理多个网络连接请求。
->缺点:最大并发为1024个,当并发数较大时,其处理性能很低。
2) 多进程模型
->思路:当连接请求过来时,主进程fork产生一个子进程,让子进程负责与客户端连接进行数据通信,当客户端主动关闭连接后,子进程结束运行。
->优点:模式简单,易于理解;连接请求很小时,效率较高。
->缺点:当连接请求过多时,系统资源很快被耗尽。比如:当连接请求达到10k时,难道要启动10k个进程吗?
3) 多线程模型
->思路:首先启动多个工作线程,而主线程负责接收客户端连接请求,工作线程负责与客户端通信;当连接请求过来时,ACCEPT线程将sckid放入一个数组中,工作线程中的空闲线程从数组中取走一个sckid,对应的工作线程再与客户端连接进行数据通信,当客户端主动关闭连接后,此工作线程又去从指定数组中取sckid,依次重复运行。
->优点:拥有方案2)的优点,且能够解决方案2)的缺点。
->缺点:不能支持并发量大的请求和量稍大的长连接请求。
通过对以上三种方案的分析,以上方案均不能满足高并发、高性能的服务器的处理要求。针对以上设计方案问题的存在,该如何设计才能做到高并发、高性能的处理要求呢?
2 设计方案
2.1 大体框架
1) 框架-1
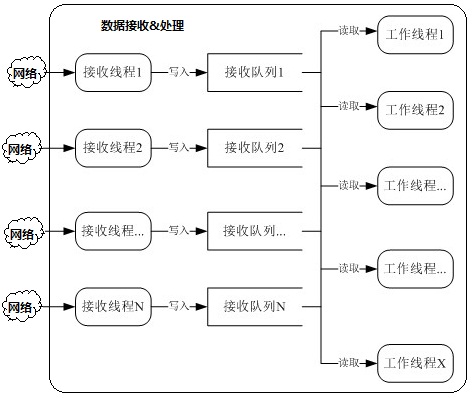
图1 大体框架-01
[注:接收线程数:接收队列数:工作线程数 = N:N:X]
优点:
1)、有效避免接收线程之间出现锁竞争的情况。
每个接收线程对应一个接收队列,每个接收线程将接收到的数据只放在自己对应的队列中;
2)、在数据量不是很大的情况下,此框架结构还是能够满足处理要求。
缺点:
1)、在连接数量很少、而数据量很大时,将会造成锁冲突严重,致使性能急剧下降。
假如:当前系统中只有1个TCP连接,由Recv线程2负责接收该连接中的所有数据。Recv线程2每收到一条数据,就将随机通知工作线程到该队列上取数据。在某个时刻,该连接的客户端发来大量数据,将造成所有工作线程同时到Recv队列2中来取数据。此时将会出现严重的锁冲突现象,性能急剧下降。
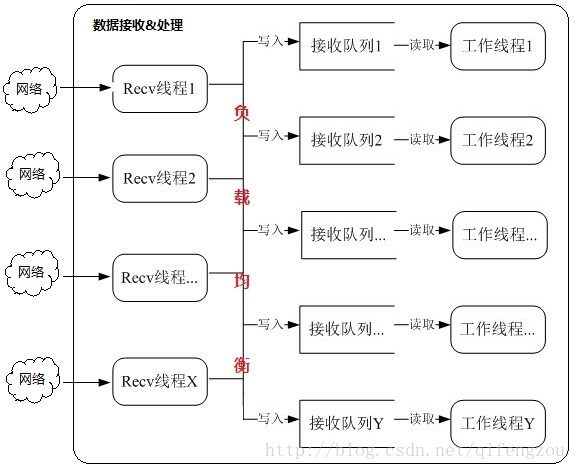
图2 大体框架-02
[注:接收线程数:接收队列数:工作线程数 = X:Y:Y]
优点:
1)、有效避免工作线程之间出现锁竞争的情况。
每个工作线程对应一个接收队列,每个接收线程将接收到的数据只放在自己对应的队列中;
2)、工作线程数 >= 2*接收线程数 时,能够有效的减少接收线程之间的锁竞争的情况
在这种情况下,我想你可以得到你想要的处理性能!
缺点:
1)、需要为更高的性能,付出更多的系统资源(主要:内存和CPU)。
2.2 如何提高并发量?
“并发量”是指系统可接受的TCP连接请求数。首先需要明确的是:"高并发"只是一个相对概念。如:有些系统1K并发就算是高并发,而有些系统100K并发也不能满足要求。因此,在此只给出提高并发量的设计思路。
众所周知,IO多路复用中1个select函数最多可管理FD_SETSIZE(该值一般为1024)个SOCKET套接字,而如果要求并发量达到100K时,显然已大大超过了1个select的管理能力,那该如何解决?
答案是:使用多个select可以有效的解决以上问题。100K约等于100 * 1024,故需大约100个select才能有效管理100k并发。那该如何调用100个select来管理100k的并发呢?
因FD的管理在进程之间是独立的,虽然子进程在创建之时,会继承父进程的FD,但后续连接产生的FD却无法让子进程继续继承,因此,要实现对100k并发的有效管理,使用多线程实现高并发是理想的选择。即:每个线程调用1个select,而每个select可以管理1024个并发。
在理想情况下,启动N个接收线程,系统便可处理N *1024的并发。如:启动100个接收线程,单机便可处理100 * 1024 = 100k的网络并发。但需要注意的是:线程越多,消耗的资源越多,操作系统调度的开销越大,如果调度开销超过多线程带来的性能提升,随着线程的增加,将导致系统性能越低。(如果要求处理5k以上的请求,我将毫不犹豫的选择"多线程+epoll"的方式)
2.3 如何提高处理性能?
为了提高Recv线程接收来自客户端的数据的性能,其处理过程需要使用到:IO多路复用技术,非阻塞IO技术、内存池技术、加锁技术、事件触发机制、负载均衡策略、UNINX-UDP技术、设计模式等,这需要研发人员对各技术有深刻的认识和理解。Recv线程的大体处理流程:
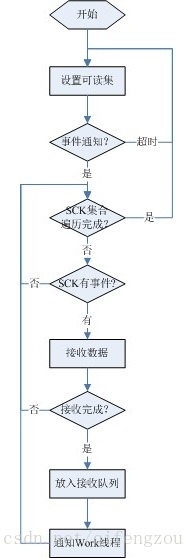
图2 Recv线程处理流程
为了减少数据的复制,可以在接收数据开始时,Recv线程就为将要接收的数据从接收队列中分配一块空间。当Recv线程接收到一条完整的客户端数据后,则通过UNINX-UDP发送消息,告知某一Work线程到指定接收队列中取走数据进行处理。Recv线程通知Work线程的过程需要采用负载均衡策略。
2) Work流程
在无处理消息到来之前,一直处在阻塞状态,当有Recv线程的处理通知时,则接收消息内容,对消息进行分析,再根据消息的内容到指定的接收队列中取数据,再对数据进行相应的处理。其大体流程如下图所示:
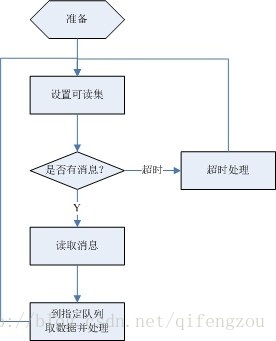
图3 Work线程处理流程
2.3 链路分发
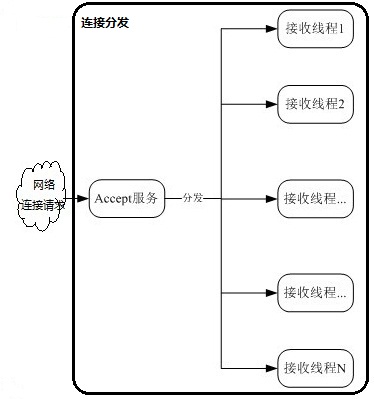
3 方案总结
以上设计方案适合客户端向服务端传输大量数据的场景,如果需要服务端反馈最终的处理结果,则需为Recv线程增加一个与之对应发送队列,在此不再赘述。总之,要做到高并发、高性能的网络通信系统,往往需要以下技术做支撑,这需要研发人员对以下技术拥有深刻的理解和认识,当然这还远远不够。
1)IO多路复用技术 2)非阻塞IO技术 3)事件驱动机制 4)线程池技术 5)负载均衡策略 6)内存池技术 7)缓存技术 8)锁技术 9)设计模式 10)高效算法和技巧的使用等等
以上转载自:"祁峰"的CSDN博客:http://blog.csdn.net/qifengzou/article/details/23912267
高并发网络编程之epoll详解
在linux 没有实现epoll事件驱动机制之前,我们一般选择用select或者poll等IO多路复用的方法来实现并发服务程序。在大数据、高并发、集群等一些名词唱得火热之年代,select和poll的用武之地越来越有限,风头已经被epoll占尽。
本文便来介绍epoll的实现机制,并附带讲解一下select和poll。通过对比其不同的实现机制,真正理解为何epoll能实现高并发。
select()和poll() IO多路复用模型
select的缺点:
- 单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;(在linux内核头文件中,有这样的定义:#define __FD_SETSIZE 1024)
- 内核 / 用户空间内存拷贝问题,select需要复制大量的句柄数据结构,产生巨大的开销;
- select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select调用还是会将这些文件描述符通知进程。
相比select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
因此,该epoll上场了。
epoll IO多路复用模型实现机制
由于epoll的实现机制与select/poll机制完全不同,上面所说的 select的缺点在epoll上不复存在。
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树)。把原先的select/poll调用分成了3个部分:
1)调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源)
2)调用epoll_ctl向epoll对象中添加这100万个连接的套接字
3)调用epoll_wait收集发生的事件的连接
如此一来,要实现上面说是的场景,只需要在进程启动时建立一个epoll对象,然后在需要的时候向这个epoll对象中添加或者删除连接。同时,epoll_wait的效率也非常高,因为调用epoll_wait时,并没有一股脑的向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接。
下面来看看Linux内核具体的epoll机制实现思路。
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
- structeventpoll{
- ....
- /*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
- structrb_root rbr;
- /*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
- structlist_headrdlist;
- ....
- };
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。
在epoll中,对于每一个事件,都会建立一个epitem结构体,如下所示:
- structepitem{
- structrb_node rbn;//红黑树节点
- structlist_head rdllink;//双向链表节点
- structepoll_filefd ffd; //事件句柄信息
- structeventpoll *ep; //指向其所属的eventpoll对象
- structepoll_eventevent;//期待发生的事件类型
- }
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。

epoll数据结构示意图
从上面的讲解可知:通过红黑树和双链表数据结构,并结合回调机制,造就了epoll的高效。
OK,讲解完了Epoll的机理,我们便能很容易掌握epoll的用法了。一句话描述就是:三步曲。
第一步:epoll_create()系统调用。此调用返回一个句柄,之后所有的使用都依靠这个句柄来标识。
第二步:epoll_ctl()系统调用。通过此调用向epoll对象中添加、删除、修改感兴趣的事件,返回0标识成功,返回-1表示失败。
第三部:epoll_wait()系统调用。通过此调用收集收集在epoll监控中已经发生的事件。
最后,附上一个epoll编程实例。(作者为sparkliang)
- //
- // a simple echo server using epoll in linux
- //
- // 2009-11-05
- // 2013-03-22:修改了几个问题,1是/n格式问题,2是去掉了原代码不小心加上的ET模式;
- // 本来只是简单的示意程序,决定还是加上 recv/send时的buffer偏移
- // by sparkling
- //
- #include <sys/socket.h>
- #include <sys/epoll.h>
- #include <netinet/in.h>
- #include <arpa/inet.h>
- #include <fcntl.h>
- #include <unistd.h>
- #include <stdio.h>
- #include <errno.h>
- #include <iostream>
- using namespace std;
- #define MAX_EVENTS 500
- struct myevent_s
- {
- int fd;
- void (*call_back)(int fd, int events, void *arg);
- int events;
- void *arg;
- int status; // 1: in epoll wait list, 0 not in
- char buff[128]; // recv data buffer
- int len, s_offset;
- long last_active; // last active time
- };
- // set event
- void EventSet(myevent_s *ev, int fd, void (*call_back)(int, int, void*), void *arg)
- {
- ev->fd = fd;
- ev->call_back = call_back;
- ev->events = 0;
- ev->arg = arg;
- ev->status = 0;
- bzero(ev->buff, sizeof(ev->buff));
- ev->s_offset = 0;
- ev->len = 0;
- ev->last_active = time(NULL);
- }
- // add/mod an event to epoll
- void EventAdd(int epollFd, int events, myevent_s *ev)
- {
- struct epoll_event epv = {0, {0}};
- int op;
- epv.data.ptr = ev;
- epv.events = ev->events = events;
- if(ev->status == 1){
- op = EPOLL_CTL_MOD;
- }
- else{
- op = EPOLL_CTL_ADD;
- ev->status = 1;
- }
- if(epoll_ctl(epollFd, op, ev->fd, &epv) < 0)
- printf("Event Add failed[fd=%d], evnets[%d]\n", ev->fd, events);
- else
- printf("Event Add OK[fd=%d], op=%d, evnets[%0X]\n", ev->fd, op, events);
- }
- // delete an event from epoll
- void EventDel(int epollFd, myevent_s *ev)
- {
- struct epoll_event epv = {0, {0}};
- if(ev->status != 1) return;
- epv.data.ptr = ev;
- ev->status = 0;
- epoll_ctl(epollFd, EPOLL_CTL_DEL, ev->fd, &epv);
- }
- int g_epollFd;
- myevent_s g_Events[MAX_EVENTS+1]; // g_Events[MAX_EVENTS] is used by listen fd
- void RecvData(int fd, int events, void *arg);
- void SendData(int fd, int events, void *arg);
- // accept new connections from clients
- void AcceptConn(int fd, int events, void *arg)
- {
- struct sockaddr_in sin;
- socklen_t len = sizeof(struct sockaddr_in);
- int nfd, i;
- // accept
- if((nfd = accept(fd, (struct sockaddr*)&sin, &len)) == -1)
- {
- if(errno != EAGAIN && errno != EINTR)
- {
- }
- printf("%s: accept, %d", __func__, errno);
- return;
- }
- do
- {
- for(i = 0; i < MAX_EVENTS; i++)
- {
- if(g_Events[i].status == 0)
- {
- break;
- }
- }
- if(i == MAX_EVENTS)
- {
- printf("%s:max connection limit[%d].", __func__, MAX_EVENTS);
- break;
- }
- // set nonblocking
- int iret = 0;
- if((iret = fcntl(nfd, F_SETFL, O_NONBLOCK)) < 0)
- {
- printf("%s: fcntl nonblocking failed:%d", __func__, iret);
- break;
- }
- // add a read event for receive data
- EventSet(&g_Events[i], nfd, RecvData, &g_Events[i]);
- EventAdd(g_epollFd, EPOLLIN, &g_Events[i]);
- }while(0);
- printf("new conn[%s:%d][time:%d], pos[%d]\n", inet_ntoa(sin.sin_addr),
- ntohs(sin.sin_port), g_Events[i].last_active, i);
- }
- // receive data
- void RecvData(int fd, int events, void *arg)
- {
- struct myevent_s *ev = (struct myevent_s*)arg;
- int len;
- // receive data
- len = recv(fd, ev->buff+ev->len, sizeof(ev->buff)-1-ev->len, 0);
- EventDel(g_epollFd, ev);
- if(len > 0)
- {
- ev->len += len;
- ev->buff[len] = '\0';
- printf("C[%d]:%s\n", fd, ev->buff);
- // change to send event
- EventSet(ev, fd, SendData, ev);
- EventAdd(g_epollFd, EPOLLOUT, ev);
- }
- else if(len == 0)
- {
- close(ev->fd);
- printf("[fd=%d] pos[%d], closed gracefully.\n", fd, ev-g_Events);
- }
- else
- {
- close(ev->fd);
- printf("recv[fd=%d] error[%d]:%s\n", fd, errno, strerror(errno));
- }
- }
- // send data
- void SendData(int fd, int events, void *arg)
- {
- struct myevent_s *ev = (struct myevent_s*)arg;
- int len;
- // send data
- len = send(fd, ev->buff + ev->s_offset, ev->len - ev->s_offset, 0);
- if(len > 0)
- {
- printf("send[fd=%d], [%d<->%d]%s\n", fd, len, ev->len, ev->buff);
- ev->s_offset += len;
- if(ev->s_offset == ev->len)
- {
- // change to receive event
- EventDel(g_epollFd, ev);
- EventSet(ev, fd, RecvData, ev);
- EventAdd(g_epollFd, EPOLLIN, ev);
- }
- }
- else
- {
- close(ev->fd);
- EventDel(g_epollFd, ev);
- printf("send[fd=%d] error[%d]\n", fd, errno);
- }
- }
- void InitListenSocket(int epollFd, short port)
- {
- int listenFd = socket(AF_INET, SOCK_STREAM, 0);
- fcntl(listenFd, F_SETFL, O_NONBLOCK); // set non-blocking
- printf("server listen fd=%d\n", listenFd);
- EventSet(&g_Events[MAX_EVENTS], listenFd, AcceptConn, &g_Events[MAX_EVENTS]);
- // add listen socket
- EventAdd(epollFd, EPOLLIN, &g_Events[MAX_EVENTS]);
- // bind & listen
- sockaddr_in sin;
- bzero(&sin, sizeof(sin));
- sin.sin_family = AF_INET;
- sin.sin_addr.s_addr = INADDR_ANY;
- sin.sin_port = htons(port);
- bind(listenFd, (const sockaddr*)&sin, sizeof(sin));
- listen(listenFd, 5);
- }
- int main(int argc, char **argv)
- {
- unsigned short port = 12345; // default port
- if(argc == 2){
- port = atoi(argv[1]);
- }
- // create epoll
- g_epollFd = epoll_create(MAX_EVENTS);
- if(g_epollFd <= 0) printf("create epoll failed.%d\n", g_epollFd);
- // create & bind listen socket, and add to epoll, set non-blocking
- InitListenSocket(g_epollFd, port);
- // event loop
- struct epoll_event events[MAX_EVENTS];
- printf("server running:port[%d]\n", port);
- int checkPos = 0;
- while(1){
- // a simple timeout check here, every time 100, better to use a mini-heap, and add timer event
- long now = time(NULL);
- for(int i = 0; i < 100; i++, checkPos++) // doesn't check listen fd
- {
- if(checkPos == MAX_EVENTS) checkPos = 0; // recycle
- if(g_Events[checkPos].status != 1) continue;
- long duration = now - g_Events[checkPos].last_active;
- if(duration >= 60) // 60s timeout
- {
- close(g_Events[checkPos].fd);
- printf("[fd=%d] timeout[%d--%d].\n", g_Events[checkPos].fd, g_Events[checkPos].last_active, now);
- EventDel(g_epollFd, &g_Events[checkPos]);
- }
- }
- // wait for events to happen
- int fds = epoll_wait(g_epollFd, events, MAX_EVENTS, 1000);
- if(fds < 0){
- printf("epoll_wait error, exit\n");
- break;
- }
- for(int i = 0; i < fds; i++){
- myevent_s *ev = (struct myevent_s*)events[i].data.ptr;
- if((events[i].events&EPOLLIN)&&(ev->events&EPOLLIN)) // read event
- {
- ev->call_back(ev->fd, events[i].events, ev->arg);
- }
- if((events[i].events&EPOLLOUT)&&(ev->events&EPOLLOUT)) // write event
- {
- ev->call_back(ev->fd, events[i].events, ev->arg);
- }
- }
- }
- // free resource
- return 0;
- }
上文转载自:http://www.cricode.com/3499.html
高并发的socket的高性能设计【转】的更多相关文章
- 2020重新出发,NOSQL,redis高并发系统的分析和设计
高并发系统的分析和设计 任何系统都不是独立于业务进行开发的,真正的系统是为了实现业务而开发的,所以开发高并发网站抢购时,都应该先分析业务需求和实际的场景,在完善这些需求之后才能进入系统开发阶段. 没有 ...
- 高并发非自增ID如何设计?
博友们一起来讨论下高并发非自增ID如何设计? 底层是很重要的,我最近设计底层,通用底层. 我想跟大家谈论下这个话题: 如何在高并发环境下设计出一套好用的非自增ID的添加操作的解决方案?更新的操作我随机 ...
- 高并发秒杀系统--Service接口设计与实现
[DAO编写之后的总结] DAO层 --> 接口设计 + SQL编写 DAO拼接等逻辑 --> 统一在Service层完成 [Service层的接口设计] 1.接口 ...
- ql Server 高频,高并发访问中的键查找死锁解析
死锁对于DBA或是数据库开发人员而言并不陌生,它的引发多种多样,一般而言,数据库应用的开发者在设计时都会有一定的考量进而尽量避免死锁的产生.但有时因为一些特殊应用场景如高频查询,高并发查询下由于数据库 ...
- Sql Server 高频,高并发访问中的键查找死锁解析
死锁对于DBA或是数据库开发人员而言并不陌生,它的引发多种多样,一般而言,数据库应用的开发者在设计时都会有一定的考量进而尽量避免死锁的产生.但有时因为一些特殊应用场景如高频查询,高并发查询下由于数据库 ...
- 高并发高可、O2O、微服务架构用学习网站
高并发高可.O2O.微服务架构用学习网站 https://www.itkc8.com 非常感谢http://www.cnblogs.com/skyblog/p/5044486.html 关于架构,笔者 ...
- 【高并发】Redis如何助力高并发秒杀系统,看完这篇我彻底懂了!!
写在前面 之前,我们在<[高并发]高并发秒杀系统架构解密,不是所有的秒杀都是秒杀!>一文中,详细讲解了高并发秒杀系统的架构设计,其中,我们介绍了可以使用Redis存储秒杀商品的库存数量.很 ...
- 高性能高并发服务器架构设计探究——以flamigo服务器代码为例
这篇文章我们将介绍服务器的开发,并从多个方面探究如何开发一款高性能高并发的服务器程序. 所谓高性能就是服务器能流畅地处理各个客户端的连接并尽量低延迟地应答客户端的请求:所谓高并发,指的是服务器可以同时 ...
- Java高并发高性能分布式框架从无到有微服务架构设计
微服务架构模式(Microservice Architect Pattern).近两年在服务的疯狂增长与云计算技术的进步,让微服务架构受到重点关注 微服务架构是一种架构模式,它提倡将单一应用程序划分成 ...
随机推荐
- C++回顾day01---<C++对C的增强>
一:命名空间 二:三目运算符 (一)C语言三目运算符返回值(不可修改) (二)C++中三目运算符直接返回变量本身(可以直接进行修改) 三:C++要求所有函数必须有类型(不重要) (一)C语言允许函数无 ...
- sql递归查询 根据Id查所有子结点
Declare @Id Int Set @Id = 0; ---在此修改父节点 With RootNodeCTE(D_ID,D_FatherID,D_Name,lv) As ( Select D_ID ...
- HDU - 5073 Galaxy(数学)
题目 题意:n个点,运行移动k个点到任何位置,允许多个点在同一位置上.求移动k个点后,所有点到整体中心的距离的平方和最小. 分析:这题题目真的有点迷...一开始看不懂.得知最后是选取一个中心,于是看出 ...
- Spark Submitting Applications浅析
Submitting Applications提交应用程序 在spark的bin目录下spark-submit脚本被用于在集群中启动应用程序.它可以通过一个统一的接口来使用Spark支持的所有集群管理 ...
- js 数组拷贝与深拷贝
1.对于普通数组(数组元素为数字或者字符串) var _testCopy = [1,2,3].concat();//拷贝数组(浅拷贝) 2.对于对象数组 (深拷贝) //形如var _objArr=[ ...
- jquery判断对象是否存在
if($("#abc").length >0) { ... } if($("#abc").html() != "") { ... }
- html取消回车刷新提交
<form class="weui-search-bar__form" onsubmit="return false;"> <form cla ...
- ASP.NET MVC 3 笔记
1. MVC设计模式 Ø Model:是指要处理的业务代码和数据操作代码. Ø View:主要用于跟用户打交道,并能够展示数据. Ø Controller:可以看作是 Model 和 Vie ...
- Javaweb学习笔记——(十八)——————事务、DBCP、C3P0、装饰者模式
事务 什么是事务? 转账: 1.给张三账户减1000元 2.给李四账户加1000元 当给张三账户减1000元之后,抛出了异常,这 ...
- STLINK V2安装使用详解
1. 解压st-link_v2_usb driver.zip文件. 2. 运行解压后的st-link_v2_usbdriver.exe文件,安装STLINK V2驱动程序.安装路 ...