使用Autoencoder进行降维
#coding=utf-8
import tensorflow as tf
import matplotlib.pyplot as plt from tensorflow.examples.tutorials.mnist import input_data
#需要自己从网上下载Mnist数据集
mnist = input_data.read_data_sets("D:/MNIST", one_hot=False) learning_rate = 0.01
training_epochs = 10
batch_size = 256
display_step = 1
n_input = 784
X = tf.placeholder("float", [None, n_input]) n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
weights = {
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1], )),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2], )),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3], )),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4], )),
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3], )),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2], )),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1], )),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input], )),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
} def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
# 为了便于编码层的输出,编码层随后一层不使用激活函数
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4 def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4 encoder_op = encoder(X)
decoder_op = decoder(encoder_op) y_pred = decoder_op
y_true = X
#使用平均误差最小化损失函数
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost) with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
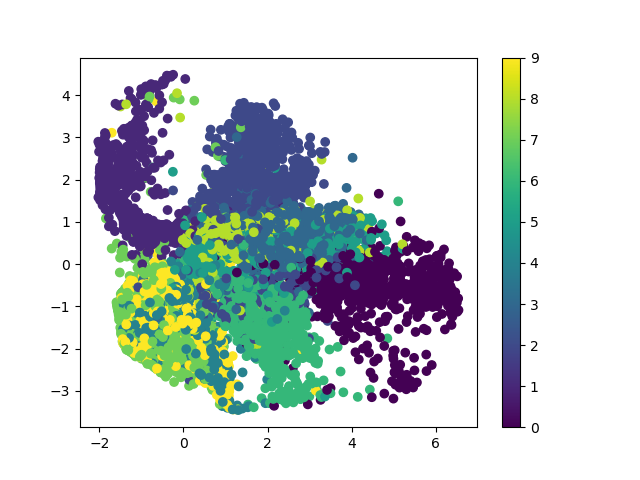
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)
plt.colorbar()
plt.show()
结果:每一种颜色代表一种数字,这里是为了可视化才降到2维的,但是实际降维的时候,肯定不会把维度降到这么低的水平。
使用Autoencoder进行降维的更多相关文章
- CNN autoencoder 先降维再使用kmeans进行图像聚类 是不是也可以降维以后进行iforest处理?
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers ...
- 论文阅读 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning
6 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning207 link:https ...
- keras使用AutoEncoder对mnist数据降维
import keras import matplotlib.pyplot as plt from keras.datasets import mnist (x_train, _), (x_test, ...
- PRML读书会第十二章 Continuous Latent Variables(PCA,Principal Component Analysis,PPCA,核PCA,Autoencoder,非线性流形)
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:00:49 我今天讲PRML的第十二章,连续隐变量.既然有连续隐变量,一定也有离散隐变量,那么离散隐变量是 ...
- 降噪自动编码器(Denoising Autoencoder)
起源:PCA.特征提取.... 随着一些奇怪的高维数据出现,比如图像.语音,传统的统计学-机器学习方法遇到了前所未有的挑战. 数据维度过高,数据单调,噪声分布广,传统方法的“数值游戏”很难奏效.数据挖 ...
- Deep Learning 16:用自编码器对数据进行降维_读论文“Reducing the Dimensionality of Data with Neural Networks”的笔记
前言 论文“Reducing the Dimensionality of Data with Neural Networks”是深度学习鼻祖hinton于2006年发表于<SCIENCE > ...
- Autoencoder
AutoencoderFrom Wikipedia An autoencoder, autoassociator or Diabolo network[1]:19 is an artificial n ...
- Deep learning:三十四(用NN实现数据的降维)
数据降维的重要性就不必说了,而用NN(神经网络)来对数据进行大量的降维是从2006开始的,这起源于2006年science上的一篇文章:reducing the dimensionality of d ...
- 一周总结:AutoEncoder、Inception 、模型搭建及下周计划
一周总结:AutoEncoder.Inception .模型搭建及下周计划 1.AutoEncoder: AutoEncoder: 自动编码器就是一种尽可能复现输入信号的神经网络:自动编码器必须捕 ...
随机推荐
- 2082 : Only choose one
题目描述 A想玩个游戏,游戏规则是,有n个人,编号从1-n,一字排开,站在奇数位置的人淘汰,剩下的人再一字排开,站在奇数位置的人淘汰,以此重复几次,最后只剩最后一个人,问最后一个人的编号是多少? 输入 ...
- 2.go的变量和常量
go的变量和常量 GO的变量: 变量的声明: 先对变量进行声明,在对其赋值 var variableName type variableName = typeValue var number int ...
- STM32L071CBTX操作ECC508
因为我是在stm32上面做的加密操作,所以我只对stm32的方案做总结. 1.ATECC508的底层接口是i2c的,工程中跟i2c相关的操作放在文件hal_stm32l0_ateccx08_i2c.c ...
- Networked Graphics: Building Networked Games and Virtual Environments (Anthony Steed / Manuel Fradinho Oliveira 著)
PART I GROUNDWORK CHAPTER 1 Introduction CHAPTER 2 One on One (101) CHAPTER 3 Overview of the Intern ...
- 宝塔linux面板 解决TP3.2 404
在配置文件中加入一下配置: location / { if (!-e $request_filename) { rewrite ^/(.*)$ /index.php/$1; } } location ...
- SQL语句整理
- 【爬虫综合作业】猫眼电影TOP100分析
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 一.爬虫对象 猫眼电影TOP100排行榜 二.代码如下 im ...
- java-使用Jacob实现office转换成pdf
参考路径: https://blog.csdn.net/csdnFlyFun/article/details/79523262#commentBox Jacob组件下载地址:https://sourc ...
- linux系统服务详解
下面现介绍一下运行次序和运行级别: 一个 Linux 系统的引导过程可以分为几个阶段.我们主要看看当内核加载后的那一个阶段.你可以运行runlevel 命令来确定您的系统当前的运行级,当内核被加载并开 ...
- python 将本地目录暴露为http服务
python3 nohup python3 -m http.server 8080 &