论文阅读之:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
2016.10.23
摘要:本文针对传统超分辨方法中存在的结果过于平滑的问题,提出了结合最新的对抗网络的方法,得到了不错的效果。并且针对此网络结构,构建了自己的感知损失函数。先上一张图,展示下强大的结果:

Contributions:
GANs 提供了强大的框架来产生高质量的 plausible-looking natural images。本文提供了一个 very deep ResNet architure,利用 GANs 的概念,来形成一个 perceptual loss function 来靠近 human perception 来做 photo-realistic SISR。
主要贡献在于:
1. 对于 image SR 来说,我们取得了新的顶尖效果,降低 4倍的分辨率,衡量标准为:PSNR 和 structure similarity (SSIM)。具体的来说,我们首先采用 fast feature learning in LR space and batch-normalization 来进行训练残差网络。
2. 提出了结合 content loss 和 adversarial loss 作为我们的 perceptual loss。
Method:
首先是几个概念:
super solved image $I_{SR}$: W * H * C ; low-resolution input image $I_{LR}$: rW * rH * C ; high-resolution image $I_{HR}$ : rW * rH * C.
我们的终极目标是:训练一个产生式函数 G 能够预测给定的输入图像 LR input image 的 HR 部分。我们达到这个目的,我们训练一个 generator network 作为一个 feed-forward CNN $G_{\theta_{G}}$ 参数为 $\theta_{G}$ , 此处的 $\theta_{G} = {W_{1:L} ; b_{1:L}}$ 表示一个 L 层 deep network 的 weights 和 biases,并且是通过优化一个 SR-specific loss function $l^{SR}$ 得到的。对于一个给定的 训练图像 $I^{HR_{n}}$ ,n = 1,...,N 对应的低分辨率图像为:$I^{LR}_n$ ,我们优化下面这个问题:

1. Adversarial Network Architecture
产生式对抗网络的训练学习目标是一个 minmax problem :

作者也将图像超分辨看作是这么一个过程。通过 generator 产生一张超分辨图像,使得 discriminator 难以区分。

上图就是本文所涉及的大致流程。
2. Perceptual Loss Function
本文所设计的感知损失函数 是本文算法性能的保证。
2.1. Content Loss
像素级 MSE Loss 的计算为:
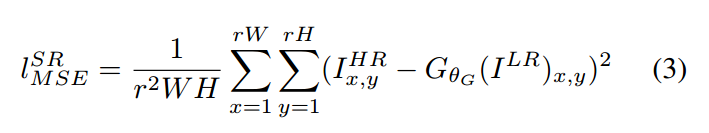
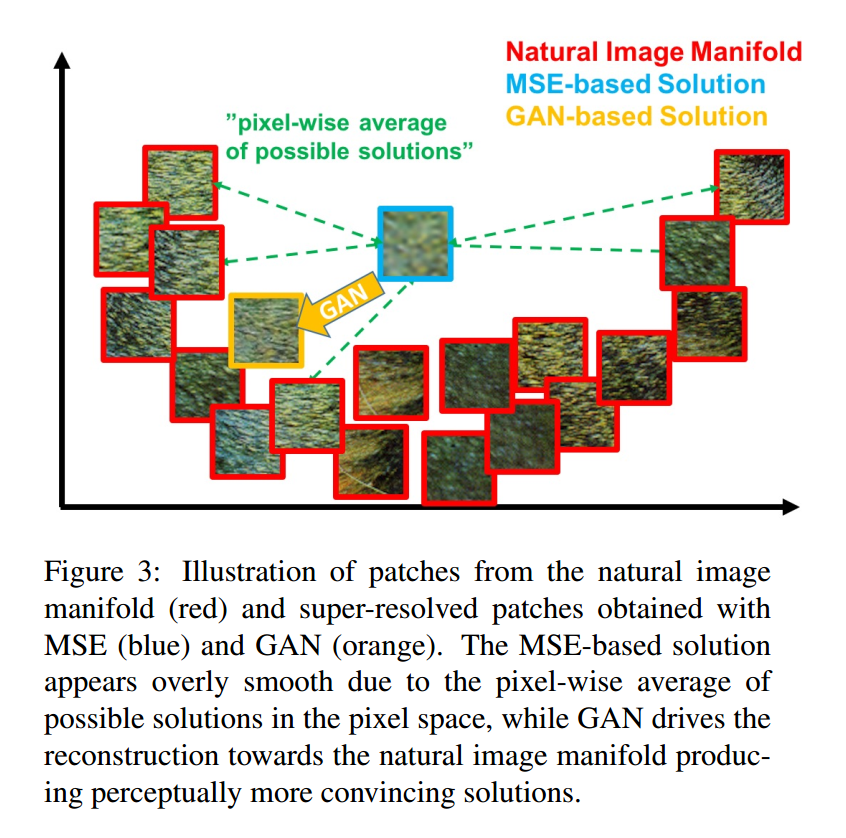
这个是最经常使用的优化目标。但是,这种方式当取得较高的 PSNR的同时,MSE 优化问题导致缺乏 high-frequency content,这就会使得结果太过于平滑(overly smooth solutions)。如图2 所示:

我们对此做了改进,在 pre-trained 19-layer VGG network 的 ReLU activation layers 的基础上,定义了 VGG loss 。
我们用 $\phi_{i,j}$ 表示 VGG19 network 当中,第 i-th max pooling layer 后的 第 j-th 卷积得到的 feature map。然后定义 the VGG loss 作为重构图像 和 参考图像之间的欧氏距离 :
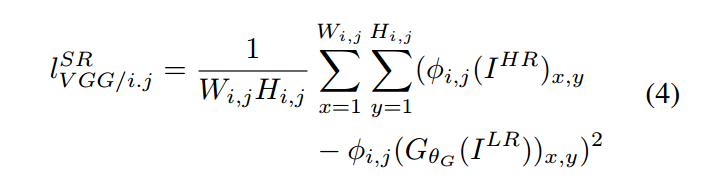
其中,$W_{i, j}$ and $H_{i, j}$ 表示了 VGG network 当中相应的 feature maps 的维度。
2.2. Adversarial Loss
在所有训练样本上,基于判别器的概率定义 generative loss :
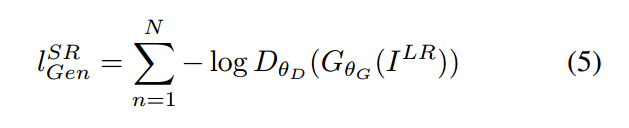
此处,D 是重构图像是 natural HR image 的概率。
2.3. Regulatization Loss
我们进一步的采用 基于 total variation 的正则化项 来鼓励 spatially coherent solutions。正则化损失的定义为:
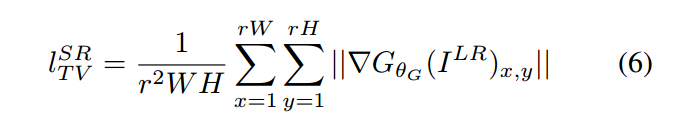
3. Experiments



总结 : 本文给出了一种比较直观的利用 产生式对抗网络的方法,结合 GANs 的比较好的应用到 Super-Resolution 上。
主要是利用了 GANs 可以创造新的图像的能力。

论文阅读之:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network的更多相关文章
- 论文阅读:Single Image Dehazing via Conditional Generative Adversarial Network
Single Image Dehazing via Conditional Generative Adversarial Network Runde Li∗ Jinshan Pan∗ Zechao L ...
- ASRWGAN: Wasserstein Generative Adversarial Network for Audio Super Resolution
ASEGAN:WGAN音频超分辨率 这篇文章并不具有权威性,因为没有发表,说不定是外国的某个大学的毕业设计,或者课程结束后的作业.或者实验报告. CS230: Deep Learning, Sprin ...
- Speech Super Resolution Generative Adversarial Network
博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never/p/10874993.html 论文作者:Sefik Emre Eskimez , Kazuhito K ...
- Face Aging with Conditional Generative Adversarial Network 论文笔记
Face Aging with Conditional Generative Adversarial Network 论文笔记 2017.02.28 Motivation: 本文是要根据最新的条件产 ...
- 【论文学习】A Fuzzy-Rule-Based Approach for Single Frame Super Resolution
加尔各答印度统计研究所,作者: Pulak Purkait (pulak_r@isical.ac.in) 2013 年 代码:CodeForge.cn http://www.codeforge.cn/ ...
- 《MIDINET: A CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORK FOR SYMBOLIC-DOMAIN MUSIC GENERATION》论文阅读笔记
出处 arXiv.org (引用量暂时只有3,too new)2017.7 SourceCode:https://github.com/RichardYang40148/MidiNet Abstrac ...
- CSAGAN:LinesToFacePhoto: Face Photo Generation from Lines with Conditional Self-Attention Generative Adversarial Network - 1 - 论文学习
ABSTRACT 在本文中,我们探讨了从线条生成逼真的人脸图像的任务.先前的基于条件生成对抗网络(cGANs)的方法已经证明,当条件图像和输出图像共享对齐良好的结构时,它们能够生成视觉上可信的图像.然 ...
- 生成对抗网络(Generative Adversarial Network)阅读笔记
笔记持续更新中,请大家耐心等待 首先需要大概了解什么是生成对抗网络,参考维基百科给出的定义(https://zh.wikipedia.org/wiki/生成对抗网络): 生成对抗网络(英语:Gener ...
- DeepPrivacy: A Generative Adversarial Network for Face Anonymization阅读笔记
DeepPrivacy: A Generative Adversarial Network for Face Anonymization ISVC 2019 https://arxiv.org/pdf ...
随机推荐
- python的ujson与simplejson
一.使用了simplejson import simplejson as json 二.使用ujson import ujson as json 参考链接:下载win下的:ujson
- Ajax中return false无效 怎么解决?
var flag=0; $.ajax({ url:"widget?type=member_register&ajax=yes&action=checkname&use ...
- Spring4.1.0 整合quartz1.8.2 时 : class not found : org.springframework.scheduling.quartz.JobDetailBean
最近做一个 Spring4.1.0 集成 quartz1.8.2 定时器功能,一直报 class not found : org.springframework.scheduling.quartz.J ...
- ANSI C与GNU C
GNU计划,又称革奴计划,是由Richard Stallman在1983年9月27日公开发起的.它的目标是创建一套完全自由的操作系统.它在编写linux的时候自己制作了一个标准成为 GNU C标准.A ...
- Physx入门
[疑问] 1.Physx中的场景有大小的概念么?如果有大小,那么场景中的刚体超出场景边界之后, 如何定义之后的行为. 2.如何给一个刚体增加动量?目前的接口只看到设置速度或者增加作用力.
- jconsole的使用
1.首先添加java运行参数: -Xms256m -Xmx1024 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port ...
- link和@import的区别
link属于XHTML标签,而@import完全是css提供的一种方式:标签和css样式的区别就不说了,他们起到的作用区别不大,一般建议用link因为简单,@import会对页面载入有影响,影响性能l ...
- Technology Remarks
-----------------------分隔符-----12.10.2016------ 抓视频 关键字补充: Base64编码/解码 出现这样的情况怎么办呢? 网址: abook-hep ...
- SPSS数据分析—重复测量差分析
多因素方差分析中,每个被试者仅接受一种实验处理,通过随机分配的方式抵消个体间差异所带来的误差,但是这种误差并没有被排除.而重复测量设计则是让每个被试接受所有的实验处理,这样我们就可以分离出个体差异所带 ...
- NOIP系列复习及题目集合
首先是我的酱油记了啦~: Xs的NOIP2014酱油记,持续更新中 知识点方面: noip知识点总结之--贪心 noip知识点总结之--线性筛法及其拓展 noip知识点总结之--欧几里得算法和扩展欧几 ...