MySQL字符集与排序规则总结
字符集与排序规则概念
在数据库当中都有字符集和排序规则的概念, 很多开发人员甚至包括有些DBA都会将这个混淆,当然这个情况也有一些情有可原的原因。一来两者本来就是相辅相成,相互依赖关联; 另外一方面, 有些数据库并没有清晰的区分开两者。例如,SQL Server中字符集和排序规则就是合在一起的,创建一个新的数据库,只有一个Collation给你选择,并没有字符集选项概念,实际上你在选择一个Collatin时,就选定了数据库的字符集和排序规则,例如Chinese_PRC_CI_AS。在MySQL中,字符集和排序规则是区分开来的,你需要单独设置字符集和排序规则。当然MySQL字符集和排序规则也是相关联的。除非特殊需求,只要设置其一即可。设置字符集,即设置了默认的排序规则。
我们先来搞清楚字符、字符集与字符编码的概念。相信很多人都在这些概念上犯过迷糊。什么是字符呢? 什么是字符集呢,什么有是字符编码呢?
字符(Charcter)是文字与符号的总称,包括文字、图形符号、数学符号等。26个英文字母属于字符,每个汉字也属于一个字符。
字符集是一组抽象的字符(Charcter)组合的集合。举一个例子,所有的汉字就算一个“字符集合”, 所有的英语字母也算一个“字符集合”。 注意,我这里说它们是字符集合,而且还有双引号。是因为字符集并不简单的是字符的集合, 准确概述来说,字符集是一套符号和编码的规则。 字符集需要以某种字符编码方式来表示、存储字符。我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态。而如果用不同的0和1组合表示不同的字符就是编码。
关于字符编码,我们知道字符最终是以二进制形式存储在磁盘的,这也是为什么要有字符编码的原因,因为计算机最终都要以二进制形式存储,那么编码规则就是用什么样的二进制来代表这个字符。例如,我们所熟知的ASCII码表中,01000011这个二进制对应的十进制是67,它代表的就是英语字母C。准确概述来说,字符编码方式是用一个或多个字节的二进制形式表示字符集中的一个字符。每种字符集都有自己特有的编码方式,因此同一个字符,在不同字符集的编码方式下,可能会产生不同的二进制形式。
另外,字符集合只是指定了一个集合中有哪些字符,而字符编码,是为这个集合中所有字符定义相关编号,而字符集(注意与字符集合的区别)是字符和集合与编码规则的混合体,这也是有时候编码方案代表字符集的原因。
说了这么多,相信有些人不能区分UTF8 与 Unicode,例如我们连接MySQL的字符串,这里面就会包含字符编码与字符集。
<string value="jdbc:mysql://192.168.xxx.xxx/TEST?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull"/>
那么Unicode与UTF-8 、UTF-16 、UTF-32是什么关系?
Unicode(统一码、万国码、单一码)是一种字符集,Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。.在Unicode中:汉字“中”对应的数字是20013。我们可以用:UTF-8、UTF-16、UTF-32表示这个数字,将数字20013存储在计算机中。UTF-8对应是:E4B8AD,UTF-16对应是:FEFF4E2D,UTF-32对应是:0000FEFF00004E2D。简单来说,UTF-8、UTF-16、UTF-32是Unicode码一种实现形式,都是属于Unicode编码。
在MySQL中,常见的几个字符集有latin1、GBK、GB2312、BIG5、UTF8、UTF8MB4、UTF16、UTF32等。
而MySQl的排序规则(collation),一般指对字符集中字符串之间的比较、排序制定的规则, MySLQ排序规则特征:
o 两个不同的字符集不能有相同的校对规则;
o 每个字符集有一个默认校对规则;
o 存在校对规则命名约定:以其相关的字符集名开始,中间包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束。
其实对于排序规则的细节问题,我们关注较少,反而对排序规则中是否涉及大小写敏感关注较多。 例如,系统使用utf8字符集,若使用utf8_bin校对规则执行SQL查询时区分大小写,使用utf8_general_ci不区分大小写(默认的utf8字符集对应的校对规则是utf8_general_ci)。
MySQL字符集的分类
MySQL数据库的相关字符集设置相当灵活和复杂(灵活性太高,就会引起复杂性),要搞清、弄懂这些概念还真需要花一点时间。这个也是很多人遭遇中文乱码的真正原因。具体来说,MySQL的字符集有分层的、灵活的特点。如果没有指定字段的字符集,那么就默认使用当前表的字符集,如果没有指定当前表的字符集,那么就会默认使用当前数据库的字符集.... 要了解不同字符集的分类,我们先从MySQL的系统变量(字符集相关的系统变量)开始
mysql> show variables like 'character_set%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
character_set_client 客户端数据使用的字符集
MySQL Client发送给mysqld的语句或数据使用字符集。
The character set for statements that arrive from the client. The session value of this variable is set using the character set requested by the client when the client connects to the server. (Many clients support a --default-character-set option to enable this character set to be specified explicitly. See also Section 10.1.4, “Connection Character Sets and Collations”.) The global value of the variable is used to set the session value in cases when the client-requested value is unknown or not available, or the server is configured to ignore client requests:
The client is from a version of MySQL older than MySQL 4.1, and thus does not request a character set.
The client requests a character set not known to the server. For example, a Japanese-enabled client requests sjis when connecting to a server not configured with sjis support.
mysqld was started with the --skip-character-set-client-handshake option, which causes it to ignore client character set configuration. This reproduces MySQL 4.0 behavior and is useful should you wish to upgrade the server without upgrading all the clients.
ucs2, utf16, utf16le, and utf32 cannot be used as a client character set, which means that they also do not work for SET NAMES or SET CHARACTER SET.
character_set_connection 连接层字符集
其实很多人对这个字符集一脸懵逼,这个字符集与character_set_client有啥区别呢? 这个字符集用于没有introducer修饰的字符串和数字到字符串的转换。
由introducer修饰的文本字符串在请求过程中不经过多余的转码,直接转换为内部字符集处理。
The character set used for literals that do not have a character set introducer and for number-to-string conversion. For information about introducers, seeSection 10.1.3.8, “Character Set Introducers”.
character_set_database 数据库字符集
MySQL可以给实例下不同数据库单独设置各自的字符集。这个跟SQL Server是类似的。
The character set used by the default database. The server sets this variable whenever the default database changes. If there is no default database, the variable has the same value as character_set_server.
character_set_filesystem
The file system character set. This variable is used to interpret string literals that refer to file names, such as in the LOAD DATA INFILE and SELECT ... INTO OUTFILE statements and the LOAD_FILE() function. Such file names are converted from character_set_client to character_set_filesystem before the file opening attempt occurs. The default value is binary, which means that no conversion occurs. For systems on which multibyte file names are permitted, a different value may be more appropriate. For example, if the system represents file names using UTF-8, set character_set_filesystem to 'utf8'.
文件系统字符集。 该变量用于解释引用文件名的字符串文字,例如在LOAD DATA INFILE和SELECT ... INTO OUTFILE语句和LOAD_FILE()函数中。 在文件打开尝试发生之前,这样的文件名将从character_set_client转换为character_set_filesystem。 默认值为二进制,这意味着不会发生转换。 对于允许多字节文件名的系统,不同的值可能更合适。例如,如果系统使用UTF-8表示文件名,则将character_set_filesystem设置为“utf8”。
character_set_results 查询结果字符集
mysqld 在返回查询结果集或者错误信息到客户端时,使用的编码字符集
The character set used for returning query results such as result sets or error messages to the client.
character_set_server 服务器字符集,默认的字符集。
服务器级别(实例级别) 的字符集。如果创建数据库时,不指定字符集,那么就会默认使用服务器的编码字符集。
The server's default character set.
character_set_system 系统元数据字符集
它是系统元数据(表名、字段名等)存储时使用的编码字符集,该字段和具体存储的数据无关。总是固定不变的UTF8字符集。
The character set used by the server for storing identifiers. The value is always utf8.
另外,之前的版本还有default-character-set,MySQL 5.5版本开始,移除了参数default_character_set 取而代之的是参数character_set_server。
character_set_client、character_set_connection、character_set_results这3个参数值是由客户端每次连接进来设置的,和服务器端没关系。MySQL会存在不同字符集的转换过程,
MySQL支持的字符集
MySQL不同版本支持的字符集有所不同,你可以使用命令show charset或show character set来查看当前MySQL版本支持的字符集。
mysql> show charset;
+----------+-----------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+-----------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
+----------+-----------------------------+---------------------+--------+
40 rows in set (0.00 sec)
第一列表示字符集、 第二列表示字符集描述、第三列表示默认排序规则、第四列表示字符集的一个字符占用的最大字节数。当然你也可以使用下面SQL语句查询,效果是一样的。
mysql> select * from information_schema.character_sets;
MySQL字符集的查看
查看MySQL当前字符集
可以使用show variables like '%character%'查看相关字符集。
mysql> show variables like '%character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
查看客户端使用的字符集
mysql> show variables like '%character_set_client%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| character_set_client | utf8 |
+----------------------+-------+
1 row in set (0.00 sec)
查看连接层字符集
mysql> show variables like 'character_set_connection';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| character_set_connection | utf8 |
+--------------------------+-------+
1 row in set (0.00 sec)
查看MySQL查询结果字符集
mysql> show variables like 'character_set_results';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| character_set_results | utf8 |
+-----------------------+-------+
1 row in set (0.01 sec)
查看MySQL服务器字符集
mysql> show variables like 'character_set_server';
+----------------------+--------+
| Variable_name | Value |
+----------------------+--------+
| character_set_server | latin1 |
+----------------------+--------+
1 row in set (0.00 sec)
mysql> status;
查看MySQL数据库的字符集
mysql> use YourDB;
mysql> show variables like 'character_set_database'
&
mysql> status;
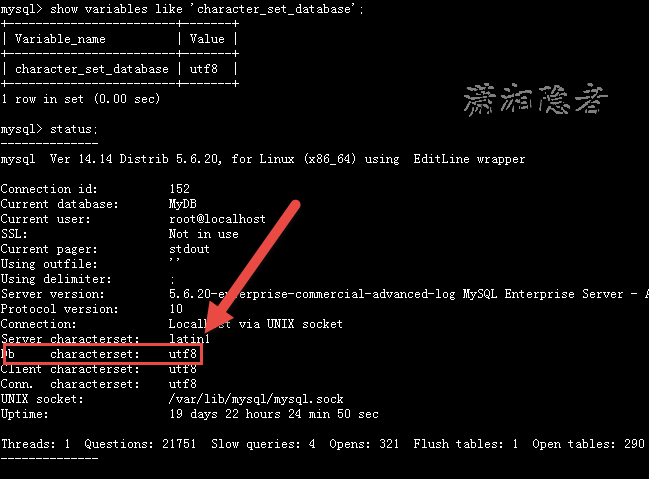
注意:上面这些命令是查看当前数据库的字符集。
mysql>show create database dbname --dbname为你要查看的数据库。
mysql> show create database MyDB;
+----------+-----------------------------------------------------------------+
| Database | Create Database |
+----------+-----------------------------------------------------------------+
| MyDB | CREATE DATABASE `MyDB` /*!40100 DEFAULT CHARACTER SET utf8mb4*/ |
+----------+-----------------------------------------------------------------+
1 row in set (0.00 sec)
要查看当前MySQL实例下面所有数据库的字符集和排序规则,可以使用下面脚本
SELECT SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME,DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA ;
查看MySQL表的字符集
方式1: show create table xxxx;
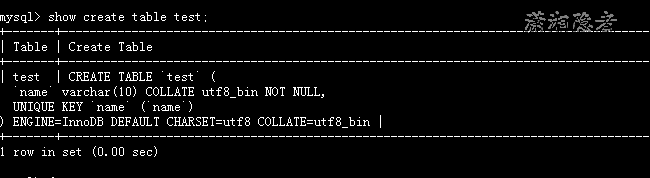
方式2: 查看INFORMATION_SCHEMA.TABLES下的TABLE_COLLATION,从而推断表的字符集
SELECT TABLE_SCHEMA, TABLE_NAME,TABLE_COLLATION FROM INFORMATION_SCHEMA.TABLES;
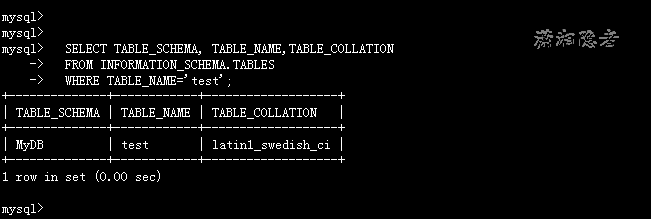
SELECT TABLE_SCHEMA, TABLE_NAME,TABLE_COLLATION
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME='TEST';
查看MySQL字段的字符集
如下所示,如果在创建表的时候已经指定了字段使用的字符集,那么show create table xxx 就能看到字段使用字符集,如果没有显示指定字段的字符集,show create table xxx 看不到其字符集,其实,这表示字段就会默认使用表的字符集。
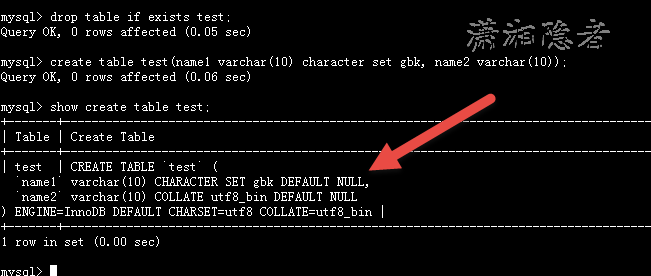
mysql> drop table if exists test;
Query OK, 0 rows affected (0.05 sec)
mysql> create table test(name1 varchar(10) character set gbk, name2 varchar(10));
Query OK, 0 rows affected (0.06 sec)
mysql> show create table test;
+-------+---------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------+
| test | CREATE TABLE `test` (
`name1` varchar(10) CHARACTER SET gbk DEFAULT NULL,
`name2` varchar(10) COLLATE utf8_bin DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin |
+-------+---------------------------------------------------+
1 row in set (0.00 sec)
mysql> drop table if exists test;
Query OK, 0 rows affected (0.01 sec)
mysql> create table test(name varchar(10));
Query OK, 0 rows affected (0.03 sec)
mysql> show create table test;
+-------+------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------------------------------------+
| test | CREATE TABLE `test` (
`name` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql>
mysql> show full columns from test;
+-------+-------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+-------+-------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| name | varchar(10) | utf8_general_ci | YES | | NULL | | select,insert,update,references | |
+-------+-------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
1 row in set (0.00 sec)
如何修改MySQL字符集
1:修改MySQL字段的字符集
修改字段的字符集语法如下所示,当然,成功的修改字符集是有限制的,具体参考10.1.7 Column Character Set Conversion,修改前最好做好备份,充分测试。
ALTER TABLE xxx MODIFY xxx VARCHAR(50) CHARACTER SET UTF8;
2:修改MySQL表的字符集
mysql> create table test(name varchar(10));
Query OK, 0 rows affected (0.03 sec)
mysql> show create table test;
+------------------------------------------------------------------------------------+
| Table | Create Table |
+------------------------------------------------------------------------------------+
| test | CREATE TABLE `test` (
`name` varchar(10) COLLATE utf8_bin DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin |
+------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> alter table test charset=gbk;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table table_name character set xxx;
注意:上面命令只修改表的字符集,影响后续该表新增列的默认定义,已有列的字符集不受影响。
同时修改表字符集和已有列字符集,并将已有数据进行字符集编码转换。可以使用类似下面脚本。
mysql> alter table table_name convert to character set xxx;
3:修改MySQL数据库字符集
alter database database_name character set xxx;
注意:只修改库的字符集,影响后续创建的表的默认定义;对于已创建的表的字符集不受影响。
4:修改系统变量character_set_database
mysql> set character_set_database=utf8mb4;
Query OK, 0 rows affected (0.00 sec)
mysql> set global character_set_database=utf8mb4;
Query OK, 0 rows affected (0.00 sec)
5:修改MySQL服务器字符集
mysql> set global character_set_server=utf8mb4;
Query OK, 0 rows affected (0.00 sec)
mysql> show global variables like 'character_set_server';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| character_set_server | utf8mb4 |
+----------------------+---------+
1 row in set (0.00 sec)
注意,上述命令只对当前环境生效,如果没有在my.cnf设置系统变量character_set_server,那么MySQL服务重启后,就会失效。所以一般应该在my.cnf配置文件设置系统变量character_set_server。对于系统变量character_set_database也是如此。
6: 修改客户端字符集(character_set_client、character_set_results、character_set_connection)。
mysql> show variables like 'character_set_client';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| character_set_client | utf8 |
+----------------------+-------+
1 row in set (0.00 sec)
mysql> set character_set_client=latin1;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'character_set_client';
+----------------------+--------+
| Variable_name | Value |
+----------------------+--------+
| character_set_client | latin1 |
+----------------------+--------+
1 row in set (0.00 sec)
mysql>
set character_set_client = utf8;
set character_set_results = utf8;
set character_set_connection = utf8;
另外,SET NAMES 'charset_name' [COLLATE 'collation_name'] 相当于SET character_set_client = charset_name; SET character_set_results = charset_name; SET character_set_connection = charset_name;
mysql> show variables like 'character_set_client';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| character_set_client | utf8 |
+----------------------+-------+
1 row in set (0.01 sec)
mysql> show variables like 'character_set_results';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| character_set_results | utf8 |
+-----------------------+-------+
1 row in set (0.00 sec)
mysql> show variables like 'character_set_connection';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| character_set_connection | utf8 |
+--------------------------+-------+
1 row in set (0.00 sec)
mysql> set names 'utf8mb4';
Query OK, 0 rows affected (0.02 sec)
mysql> show variables like 'character_set%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
mysql>
MySQL字符集选择
一般而言,我们可能选择utf8mb4这个字符集,而不选择utf8. 这个是因为MySQL的utf8并不是真正的UTF8字符集,MySQL的utf8字符编码只有三个字节,节省空间但不能表达全部的UTF-8,只能支持“基本多文种平面”(Basic Multilingual Plane,BMP),而utf8mb4才是真正的支持UTF8编码,网上有篇文章专门介绍这个。 一般而言,我们会选择utf8mb4,而不会选择gb2312、gbk。 对于gb2312而言,有些偏僻字(例如:洺)不能保存。gbk是中文字符编码是双字节的。虽然节省空间,但是有可能带来一些其他问题。在当前环境下,相信存储空间对于绝大部分公司来说都不是什么问题。
MySQL的排序规则
MySQL排序规则的查看、设置比较简单,这里就不做展开介绍了。
mysql> show collation;
mysql> show variables like 'collation_%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | utf8_general_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
3 rows in set (0.00 sec)
MySQL出现乱码的原因
为什么会出现乱码呢? 这个是我们经常遇到的问题。要说清楚乱码产生的原因。如下图所示,我们简单的
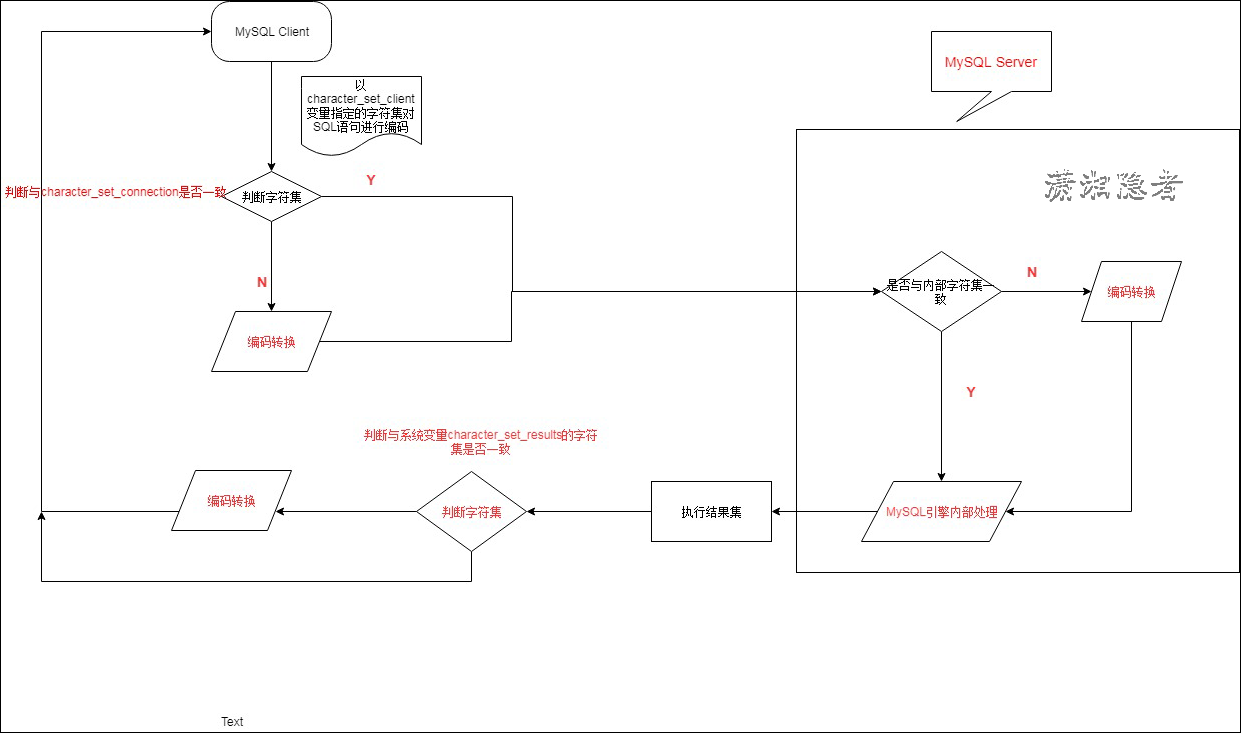
对于数据输入而言:
1. 在客户端对相关数据进行编码。
2. MySQL接收到请求时,它会询问客户端通过什么方式对字符编码:客户端通过character_set_client系统变量告知MySQL客户端的编码方式,当MySQL发现客户端的client所传输的字符集与自己的connection不一样时,它会将请求数据从character_set_client转换为character_set_connection;
3. 进行内部操作前会将请求数据从character_set_connection转换为内部操作字符集:在存储的时候会判断编码是否与内部存储字符集(按照优先级判断字符集类型,如下所示)上的编码一致,如果不一致需要转换,其流程如下:
• 使用每个数据字段的CHARACTER SET设定值;
• 若上述值不存在,则使用对应数据表的DEFAULT CHARACTER SET设定值(MySQL扩展,非SQL标准);
• 若上述值不存在,则使用对应数据库的DEFAULT CHARACTER SET设定值;
• 若上述值不存在,则使用character_set_server设定值。
对于数据输出而言:
客户端使用的字符集必须通过character_set_results来体现,服务器询问客户端字符集,通过character_set_results将结果转换为与客户端相同的字符集传递给客户端。(character_set_results默认等于character_set_client)
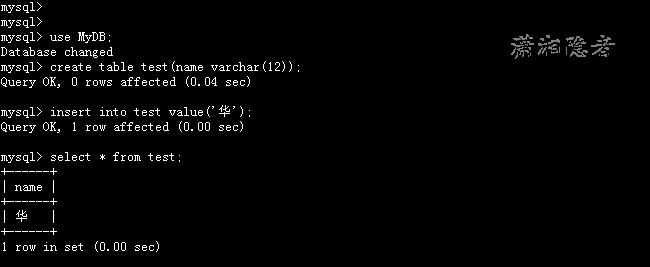
下面我们以某一个汉字来说明如何产生乱码的,例如“华”字,它的不同编码如下(http://mytju.com/classcode/tools/encode_gb2312.asp)
Unicode编码:0000534E 十进制:21326
UTF8编码 :E58D8E
UTF16编码:FEFF534E
UTF32编码:0000FEFF0000534E
GBK编码: BBAA
如果“华“字是以UTF8编码存储的,值为E58D8E, 占3个字节,但是转换为latin1编码的时候(latin1编码是1个字节一个字符),就会乱码了,如下所示:
mysql> show variables like '%character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.01 sec)
mysql> create database MyDB default character set utf8;
Query OK, 1 row affected (0.00 sec)
mysql> use MyDB;
Database changed
mysql> create table test(name varchar(12));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into test value('华');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test;
+------+
| name |
+------+
| 华 |
+------+
1 row in set (0.00 sec)
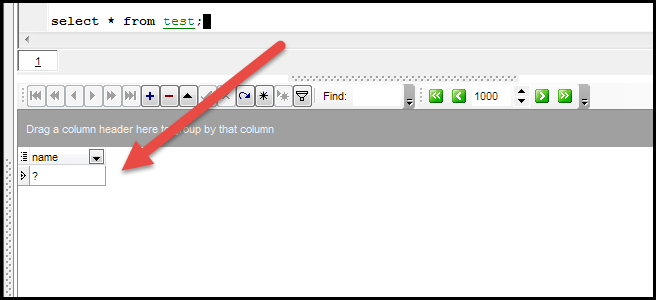
如果我使用客户端工具EMS MySQl连接数据库,如果系统变量character_set_results为latin1,此时,你会发现“华”字变成乱码。如下所示。
另外,关于编码引起的乱码、解码引起的乱码以及缺少某种字体库引起的乱码,可以参考“常见乱码问题分析和总结”
所以避免乱码的关键因素,就是避免不同层级之间的编码不一致,出现编码转换,从而导致出现乱码。所以统一各个层级的编码,就能很大程度避免乱码。
参考资料:
https://dev.mysql.com/doc/refman/5.7/en/charset-connection.html
https://dev.mysql.com/doc/refman/5.7/en/charset.html
https://dev.mysql.com/doc/refman/5.7/en/charset-introducer.html
https://dev.mysql.com/doc/refman/5.7/en/charset-collation-names.html
https://www.ibm.com/developerworks/cn/java/analysis-and-summary-of-common-random-code-problems/index.html
MySQL字符集与排序规则总结的更多相关文章
- MySql字符集与排序规则详解
前段时间往MySQL中存入emoji表情或生僻字.繁体字时,报错无法添加,研究后发现这是字符集编码的问题,今天就来分析一下各个字符集与排序规则 一.字符集 先说字符,字符是各种文字和符号的总称,包括各 ...
- Mysql 字符集及排序规则
一.字符集 字符集:就是用来定义字符在数据库中的编码的集合. 常见的字符集:utf8.Unicode.GBK.GB2312(支持中文).ASCCI(不支持中文) 二.字符集排序规则 作者本人用 ...
- 2021-2-18:请你说说MySQL的字符集与排序规则对开发有哪些影响?
任何计算机存储数据,都需要字符集,因为计算机存储的数据其实都是二进制编码,将一个个字符,映射到对应的二进制编码的这个映射就是字符编码(字符集).这些字符如何排序呢?决定字符排序的规则就是排序规则. 查 ...
- 数据库字符集与排序规则(Character Set And Collation)
数据库需要适应各种语言和字符就需要支持不同的字符集(Character Set),每种字符集也有各自的排序规则(Collation). (注意:Collation原意为校对,校勘,但是根据实际使用场景 ...
- MySQL 字符集与比较规则
MySQL 字符集与比较规则 由于 MySQL 客户端与服务端之间通信时需要将字符串编码传输,所以不可避免会产生编码转换 字符集 MySQL 中 utf8 就是 utf8mb3,只使用 1-3 个字节 ...
- Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题
Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题 表更描述: 将mysql数据库中的worktask表添加ishaspic字段. 具体操作:(1)数据库worktask表新添是否有图片字 ...
- MySql数据库字段排序规则不一致产生的一个问题
最近项目向MySql迁移,迁移完毕后,在获取用户权限时产生了一个异常,跟踪进去获取执行的语句如下, SELECT PermissionId FROM spysxtPermission WHERE (R ...
- Mysql中的排序规则utf8_unicode_ci、utf8_general_ci总结
Mysql中utf8_general_ci与utf8_unicode_ci有什么区别呢?在编程语言中,通常用unicode对中文字符做处理,防止出现乱码,那么在MySQL里,为什么大家都使用utf8_ ...
- MySQL 查看编码 排序规则
查看数据库的排序规则 mysql> show variables like 'collation%'; +----------------------+-------------------+ ...
随机推荐
- MySql一个生产死锁案例分析
接到上级一个生产环境MySQL死锁日志信息文件,需要找出原因并解决问题.我将死锁日志部分贴出如下: 在mysql中使用命令:SHOW ENGINE INNODB STATUS;总能获取到最近一些问题信 ...
- 初次接触python时,整理的一些基础操作
1.window下python简单使用 (1).使用工具网址 https://jingyan.baidu.com/article/9f7e7ec0ec2e676f2915545f.html (2).各 ...
- d3.js 绘制北京市地铁线路状况图(部分)
地铁线路图的可视化一直都是路网公司的重点,今天来和大家一起绘制线路图.先上图. 点击线路按钮,显示相应的线路.点击线路图下面的站间按钮(图上未显示),上报站间故障. 首先就是制作json文件,这个文件 ...
- 安装Office Visio 提示Office 16 Click-to-Run Extensibility Component
今天在安装 Office Visio 2016 时,点击安装程序,出现以下错误: 出现这个问题的原因就是你的电脑以前安装过32位的office,卸载时,注册表没有清理干净. 解决方案: 在win1 ...
- Hbase入门(五)——客户端(Java,Shell,Thrift,Rest,MR,WebUI)
Hbase的客户端有原生java客户端,Hbase Shell,Thrift,Rest,Mapreduce,WebUI等等. 下面是这几种客户端的常见用法. 一.原生Java客户端 原生java客户端 ...
- 纯CSS焦点轮播效果-功能可扩展
个人博客: http://mcchen.club 纯CSS3实现模拟焦点轮播效果,支持JQ等扩展各项功能.废话少说,直接贴代码. <!DOCTYPE html> <html> ...
- 包名targetPackage和目录名targetProject
generatorConfig.xml中的 <javaModelGenerator targetPackage="edu.cn.pojo" targetProject=&qu ...
- kali系统
打开终端分别输入下面两条命令: update-alternatives --install /usr/bin/python python /usr/bin/python2 100 update-alt ...
- Windows 10 更新后VMware Workstation pro无法运行 (无需卸载原版本VM)
问题 描述:当前Windows版本是win10-1903,VMware版本比较老旧是VMware Workstation Pro 15.0.4:国庆节后微软推送了一个新的更新补丁,10月10日更新之后 ...
- ubuntu14.04 安装tensorflow始末
基于ubuntu14.04 干净的系统一步步遇到的坑记录下来: 怀着平静学习的心情,问题总的能解决的! 1. 首先看了下当前python版本 python --version Python 2.7.6 ...