MYSQL之查询篇
2. 数据库操作
数据库在创建以后最常见的操作便是查询
2.1 查询
为了便于学习和理解,我们预先准备了两个表分别是stduents表和classes表两个表的内容和结构如下所示
students表的内容:
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小红 | F | 95 |
| 3 | 1 | 小军 | M | 88 |
| 4 | 1 | 小米 | F | 73 |
| 5 | 2 | 小白 | F | 81 |
| 6 | 2 | 小兵 | M | 55 |
| 7 | 2 | 小林 | M | 85 |
| 8 | 3 | 小新 | F | 91 |
| 9 | 3 | 小王 | M | 89 |
| 10 | 3 | 小丽 | F | 85 |
创建students表的SQL命令:
/*创建表的sql语句*/
CREATE TABLE students (
`id` int(11) NOT NULL AUTO_INCREMENT,
`class_id` int(11) DEFAULT NULL,
`name` varchar(10) DEFAULT NULL,
`gender` char(1) DEFAULT NULL,
`score` int(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*插入测试数据*/
INSERT INTO `students` VALUES ('1', '1', '小明', 'M', '90');
INSERT INTO `students` VALUES ('2', '1', '小红', 'F', '95');
INSERT INTO `students` VALUES ('3', '1', '小军', 'M', '88');
INSERT INTO `students` VALUES ('4', '1', '小米', 'F', '73');
INSERT INTO `students` VALUES ('5', '2', '小白', 'F', '81');
INSERT INTO `students` VALUES ('6', '2', '小兵', 'M', '55');
INSERT INTO `students` VALUES ('7', '2', '小林', 'M', '85');
INSERT INTO `students` VALUES ('8', '3', '小新', 'F', '91');
INSERT INTO `students` VALUES ('9', '3', '小王', 'M', '89');
INSERT INTO `students` VALUES ('10', '3', '小丽', 'F', '85');
classes表的内容和结构:
| id | name |
|---|---|
| 1 | 一班 |
| 2 | 二班 |
| 3 | 三班 |
| 4 | 四班 |
创建classes表的SQL命令:
/*创建表的sql语句*/
CREATE TABLE `classes` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(5) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
/*插入测试数据*/
2.1.1基本查询
查询数据库中某个表的所有内容:
SELECT * FORM <table_name>
例如查询students表中的所有内容
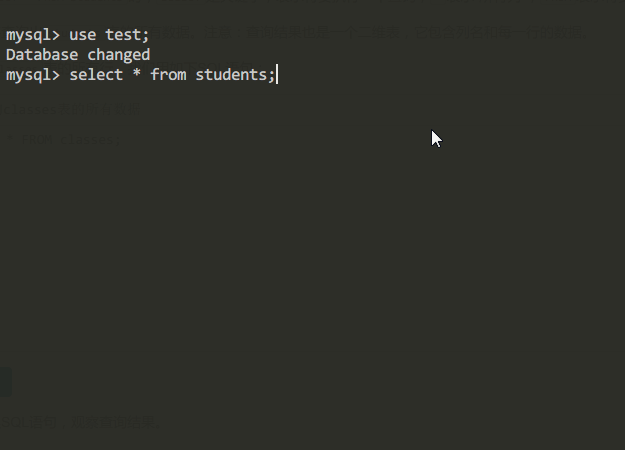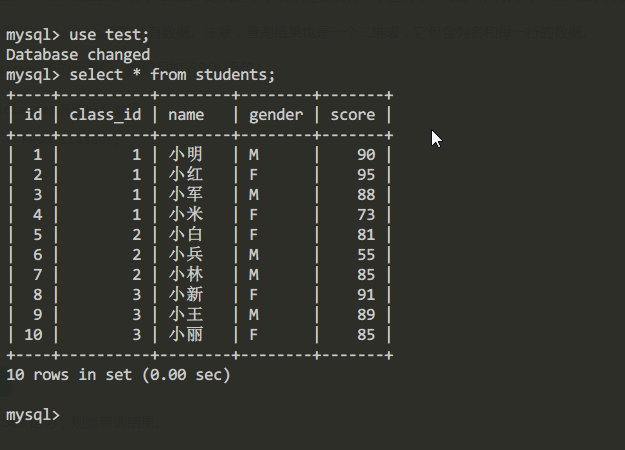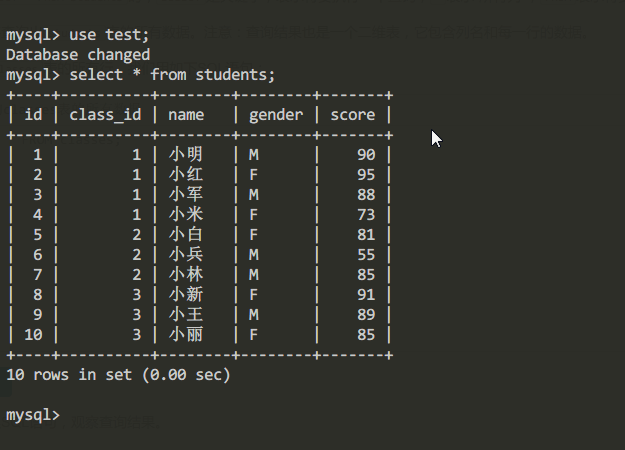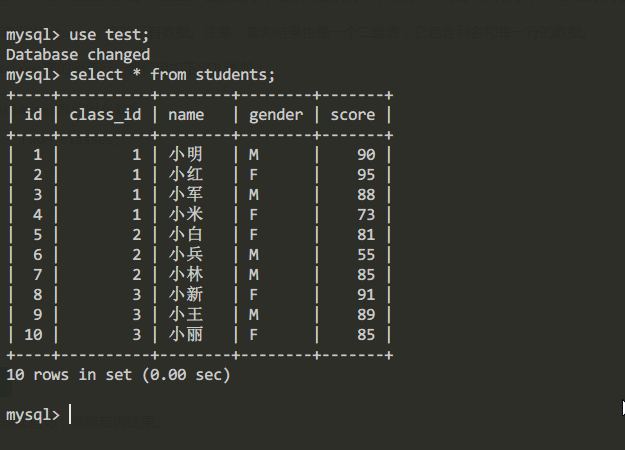
注意:
对于select语句来说,并不一定非要有from子句,例如如下语句
select 1+2;
上述查询会直接计算出表达式的结果。虽然SELECT可以用作计算,但它并不是SQL的强项。但是,不带FROM子句的SELECT语句有一个有用的用途,就是用来判断当前到数据库的连接是否有效。许多检测工具会执行一条SELECT 1;来测试数据库连接。
2.1.2 条件查询
定义:
大部分情况下,我们查询一张表的时候并不想获取一张表中的所有内容,而是想从所有记录筛选出我们所需要,此时便需要我们在查询过程中对查询条件进行限制,这边是条件查询
条件查询的语法:
SELECT * FROM <表名> WHERE <条件表达式>
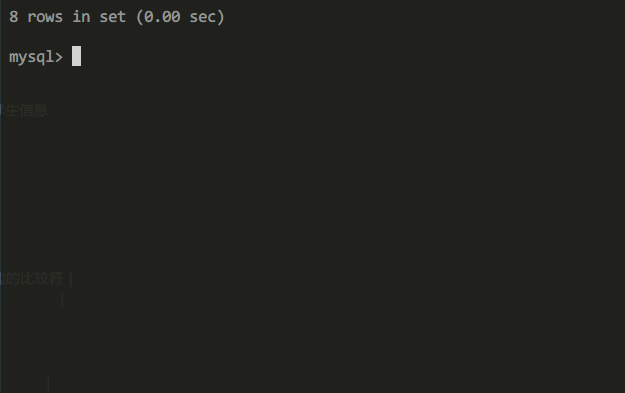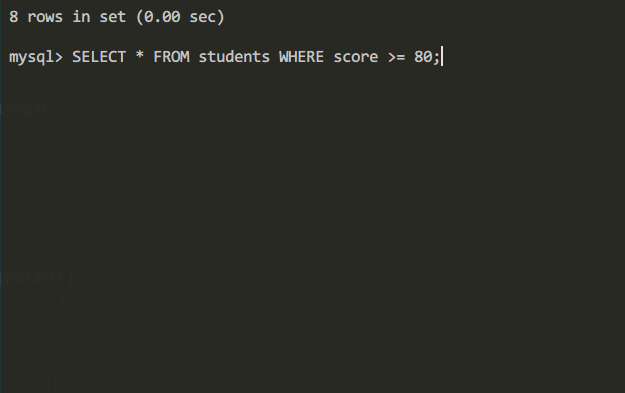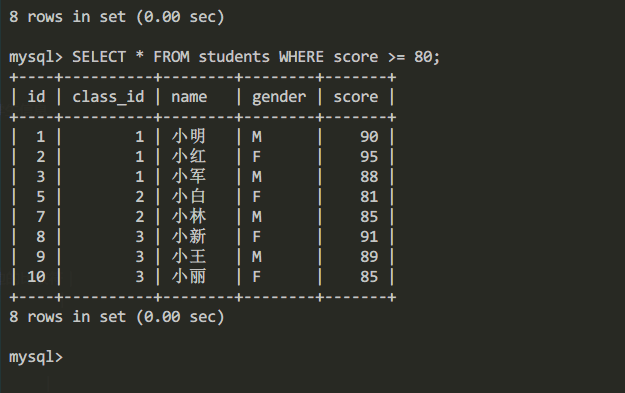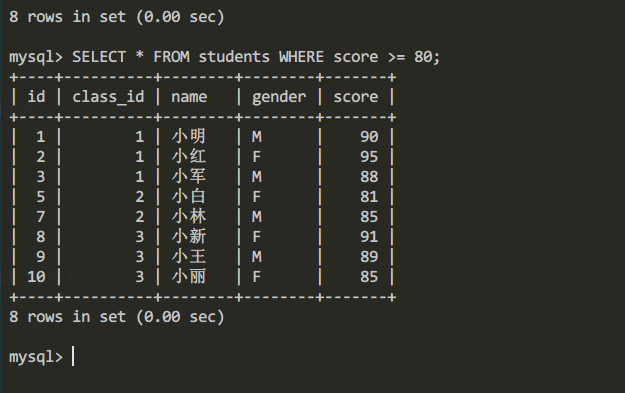
例如查询students表中分数大于等于80 (score>=80)的学生信息
查询分数大于等于80的学生信息sql命令
SELECT * FROM students WHERE score >= 80;
查询结果
条件表达式中常用的查询条件有如下这些
| 查询条件 | 谓词 |
|---|---|
| 比较 | =,>,<,>=,<=,!=,<>,!>,!<;NOT+前边的比较符 |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE,NOT LIKE |
| 空值 | IS NULL,IS NOT NULL |
| 多重条件(逻辑运算) | AND,OR,NOT |
2.1.3 多重条件查询
在实际生产过程中我们查询一个表可能查询条件并不仅仅只有一个,此时我们便需要AND、OR和NOT来进行连接和限定。
<条件一> AND <条件二>:查询结果既需要满足<条件一>同时也需要满足<条件二>。
例如查询分数大于等于60且小于80的学生信息:
SELECT * FROM students WHERE score >=60 and score < 80;
查询结果:

<条件一> OR <条件二>:查询结果需要满足条件一或者条件二。
例如查询分数小于60或者大于等于80的学生信息:
select * from students where score <60 or score >= 80;
查询结果:

select * from students where score = 90;
select * from students where NOT score = 90;
查询结果:


2.2 投影查询
有时我们在查询一个表时,可能并不需要所有表的信息,而只是需要一个表的部分列,此时我们便可以通过SELECT 列1, 列2, 列3 FROM ...,让结果集仅包含指定列。这种操作称为投影查询。
eg:查询所有学生的姓名和班级信息
select name,class_id from students;
查询结果:

同时在查询过程中我们可以对查询后的属性名称设计别名,并且也可以指定结果列的顺序(可以和原表的顺序不同)。
使用SELECT 列1, 列2, 列3 FROM ...时,还可以给每一列起个别名,这样,结果集的列名就可以与原表的列名不同。它的语法是SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM ...。
eg:将插叙结果中属性名name改成student_name
select name student_name,class_id from students;
查询结果:

2.3查询结果排序
细心的读者可能已经发现:我们在之前所做的查询最终的查询结果都是按照id(或者class_id)的升序排列的,那么我们如何来改变查询结果的排序顺序那?
其实我们可以通过ORDER BY语句来进行查询结果出顺序的控制。
eg:按照score从小到大对结果进行排序
select * from students ORDER BY score;
查询结果:

默认的排序规则是ASC升序即从小到大,当然如果我们想要查询结果是降序排列,我们可以通过加上DESC来进行进行降序结果输出。
eg:将上边的查询结果按照score降序来进行输出

2.4 分页查询
有时在查询的过程中我们查询的到的结果集比较大,而程序在处理和显示这些数据时空间有限不能够一下子完全显示出来,此时便需要将查询到的结果集分成不同的页来进行显示,这边是分页查询。分页查询实际上也就是将大的数据集(比如几万条)进行拆分,分成若干页,比如1-100第一页、101-200第二页、201-300第三页,以次类推。具体使用分页查询时我们需要通过 LIMIT <M> OFFSET <N>子句对查询结果集的大小以及页数进行控制。我很还以students为例,首先查询到它所有的结果集
查询studnets表所有结果集的sql语句
select * from students;
查询结果:

现在我们将查询到数据集进行分页,
查询第一页的数据(每页3条数据):
select * from students limit 3 offset 0;
查询结果为:
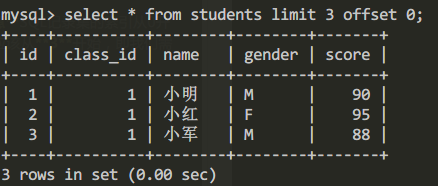
上述查询limit 3 offset 0表示,结果集从0号记录开始查询。注意SQL记录集的索引从0开始。如果需要查询第2页,我们需要跳过前边的三条记录,索引此时应该从3开始,即我们需要将offest设置为3。
查询第2页的结果集:
/*每页显示三条数据,获取其中的第2页*/
select * from students limit 3 offset 3;
查询结果:
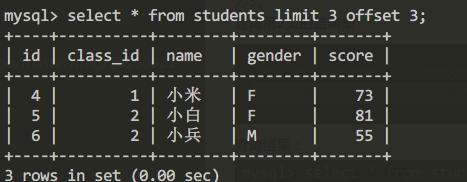
同样的查询第3页的结果集时应该讲offset设置为6;
查询第3页的结果集:
select * from students limit 3 offset 6;
查询结果:
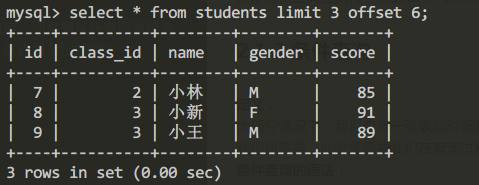
查询第4页的结果集:
select * from students limit 3 offset 9;
查询结果为:
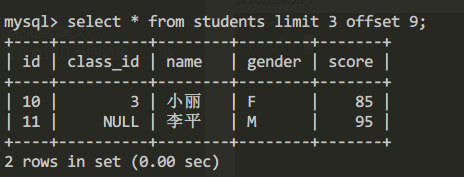
由于第4页只有一条记录所以查询结果只显示一条记录。limit 3表示每页最多“显示三条记录”。
由此可见我们在进行分页查询的时候最关键的问题是设计每页需要显示的结果集大小pageSize(这里设置的是3),然后根据当前页的索引pageIndex(需要查第几页的结果),确定limit以及offset的值:
limit一般设置为pageSizeoffset设置为pageSize*(pageIndex-1)
注意:
offset值的设置是可选的,如果只写limit 3,DBMS不会报错,而是默认认为是limit 3 offset 0。offset设置的值如果大于最大数量并不会报错,而只是得到一个空的结果集- 在
MYSQL中,limit 3 offset 6还可以写为limit 3,6 - 在使用
limit <m> offset <n>时随着n的值越来越大,查询的效率也会越来越低
2.5 聚集查询
在日常开发的某些应用场景中,我们并不需要获得具体数据集,而只是想要获得满足条件的数据集的条数(例如:查询班级表中男生的人数),此时便需要嵌套查询。对于统计总数、平均数这类查询来说,SQL已经为我们提供了专门的聚合函数,使用聚合函数进行查询,我们便称之为聚合查询,仍然以查询students表中男生的人数为例,我们可以通过SQL内置的count()函数来进行查询。
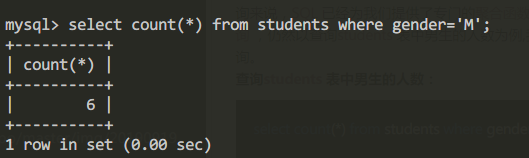
查询students表中男生的人数:
select count(*) from students where gender='M';
查询结果:
当然除了count()函数之外SQL还提供了如下的聚合函数
| 函数 | 说明 |
|---|---|
| SUM | 计算某一列的合计值,该列必须为数值类型 |
| AVG | 计算某一列的平均值,该列必须为数值类型 |
| MAX | 计算某一列的最大值 |
| MIN | 计算某一列的最小值 |
注意:
MAX()个MIN()函数并不仅限于数值类型。如果字符类型,MAX()和MIN()会返回排序在最后边和最前边的字符- 如果
聚合查询的结果没有匹配到任何行,count()会返回0,而sum()、avg()、max()和min()会返回null。
2.6 多表查询
select查询不仅可以从一张表中查询出结果,还可以同时在多张表中查询出结果,其语法为:select * form <table 1>,<table 2>。
例如,从同时从students表和classes表中查询出结果:
查询所用sql语句:
select * from students,classes;
查询结果为:
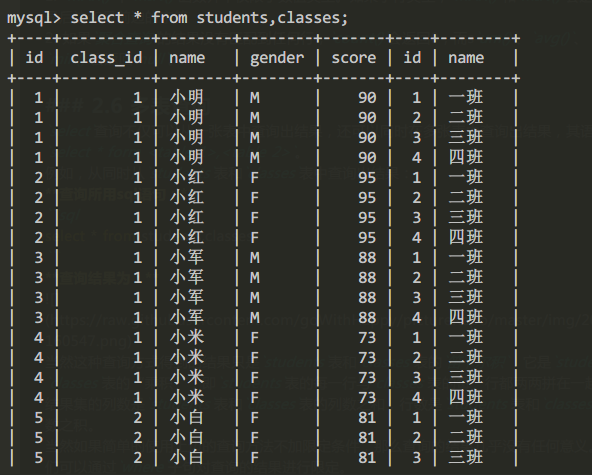
当然这种查询方式得到的结果只是students表和classes表的笛卡尔积,它是students表和classes表的“乘积”,即students表的每一行与classes表的每一行都两两拼在一起返回。结果集的列数是students表和classes表的列数之和,行数是students表和classes表的行数之积。
当然如果简单的使用上边的查询方法不加限定条件,那么查询的结果几乎没有任何意义。因此我们可以通过where子句对查询的结果进行限定。
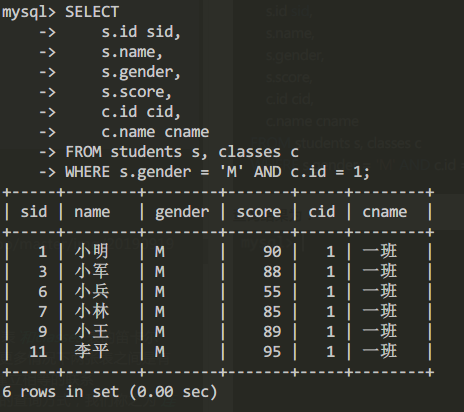
例如查询男生且位于一班的信息
SELECT
s.id sid,
s.name,
s.gender,
s.score,
c.id cid,
c.name cname
FROM students s, classes c
WHERE s.gender = 'M' AND c.id = 1;
查询结果为:
2.7 连接查询
在上一小结我们提到的连接查询,所得到的结果只是两个表stuents表和classes表的笛卡尔积,两个表直接没有任何的逻辑联系,而实际上我们进行多表查询时更多情况下两张表之间是有关系联系的,比如将students表中class_id和classes表中的id建立相等的联系stduents.class_id=classes.id,这种连接两个表进行JOIN运算的的查询方式,我们称之为连接查询。
连接查询是我们在实际开发过程最常用的查询方式,连接查询在查询过程中又分为自然连接查询、内连接查询、外连接查询等。
自然连接查询:在查询过程中,我们将目标列中重复的属性列去掉这一过程我们称之为自然连接查询。
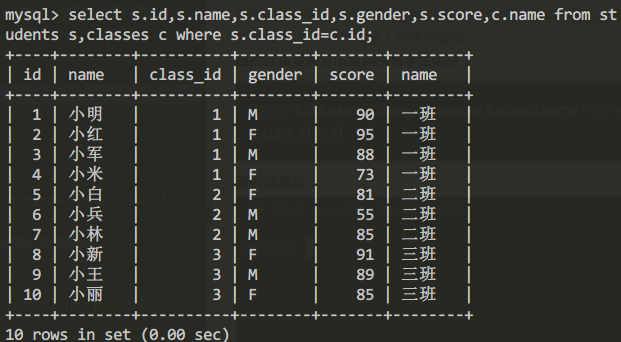
例如我们查询所有学生信息(包括班级信息),其中信息如姓名、性别、id等信息都在students表中,而班级信息却在classes表中,此时如果直接通过上一节的夺表查询的查询方法进行查询。这样查询的结果会有许多重复的结果值。此时我们便可以通过自然连接查询的方式(限定students表和classes表的属性关系)来进行查询。
自然连接查询方法查询所有学生信息:
select s.id,s.name,s.class_id,s.gender,s.score,c.name from students s,classes c where s.class_id=c.id
查询结果为:
当然我们在查询班级所有信息时我们也可以通过内连接查询来获取相同的查询结果。
内连接查询方式查询所有学生信息:
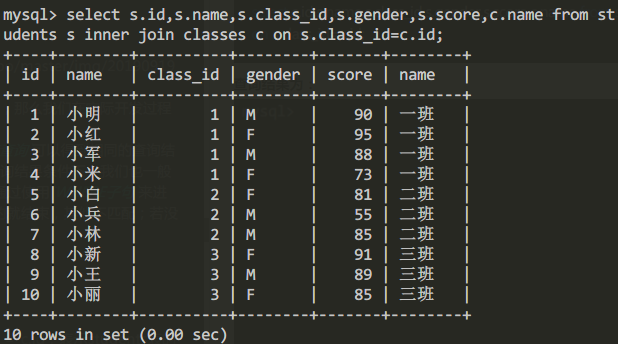
select s.id,s.name,s.class_id,s.gender,s.score,c.name from students s inner join classes c on s.class_id=c.id;
查询结果为:
此时可能有人要问了,既然自然连接查询和内连接查询可以相同结果,那么我们在实际开发过程中应该选择哪种查询方法?
针对这个问题,首先我们要明白虽然通过自然连接查询以及内连接查询可以得到相同的查询结果,但是它们在底层的实现原理是不同的。一般来说能获得相同的查询结果条件下,我们也一般都是通过内连接来查询的,因为内连接使用ON,而自然连接是通过使用WHERE子句来进行限定,而WHERE的效率没有ON高(ON 指匹配到第一条成功的就结束,其他不匹配;若没有,不进行匹配,而WHERE会一直匹配,进行判断。)
注意: inner join查询的写法为:
- 先确定主表,仍然使用FROM <表1>的语法;
- 再确定需要连接的表,使用INNER JOIN <表2>的语法;
- 然后确定连接条件,使用ON <条件...>,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接;
- 可选:加上WHERE子句、ORDER BY等子句。
那可能又有人问了“既然有外连接,那么是否有内连接那?”答案是肯定的,我们暂且不说什么是外连接,我们先通过一个例子来看下内连接和外连接之间的区别,我们还是查询所有学生的信息,但是不同之处在于我们将内连接换成外连接。
通过外连接查询所有学生信息:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
RIGHT OUTER JOIN classes c
ON s.class_id = c.id;
查询结果为:
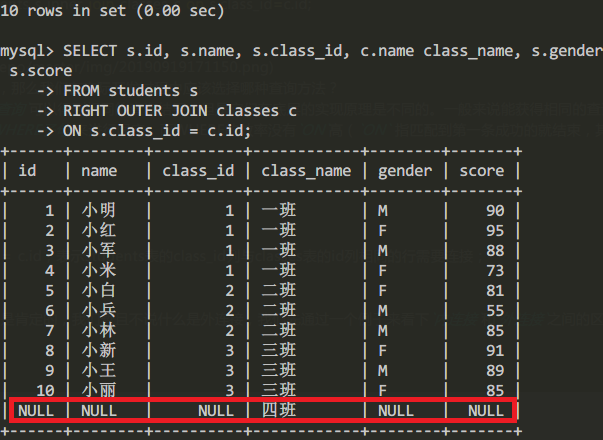
我们容易发现,此时的查询结果比内连接方式多了一行,多出来的一行是“四班”,但是,学生相关的列如name、gender、score都为NULL。这也容易理解,因为根据ON条件s.class_id = c.id,classes表的id=4的行正是“四班”,但是,students表中并不存在class_id=4的行。
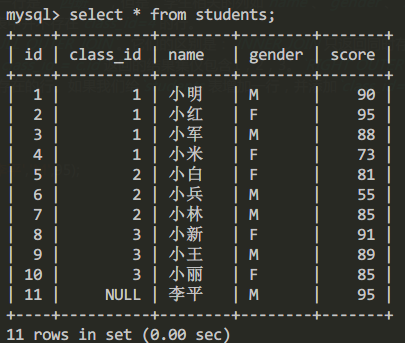
当然有RIGHT OUTER JOIN,就有LEFT OUTER JOIN,以及FULL OUTER JOIN。它们的区别是:INNER JOIN只返回同时存在于两张表的行数据,由于students表的class_id包含1,2,3,classes表的id包含1,2,3,4,所以,INNER JOIN根据条件s.class_id = c.id返回的结果集仅包含1,2,3。RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以NULL填充剩下的字段。LEFT OUTER JOIN则返回左表都存在的行。如果我们给students表增加一行,并添加class_id=5,由于classes1表并不存在id=5的行,所以,LEFT OUTER JOIN的结果会增加一行,对应的class_name是NULL:
先插入一个不含class_id的学生信息:
insert into stduents (id, name,gender,score) values(default,'李平','M',95);
select * from students;
通过外连接查询所有学生信息:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
LEFT OUTER JOIN classes c
ON s.class_id = c.id;
查询结果为:
最后,我们使用FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
FULL OUTER JOIN classes c
ON s.class_id = c.id;
查询结果:
| id | name | class_id | class_name | gender | score |
|---|---|---|---|---|---|
| 1 | 小明 | 1 | 一班 | M | 90 |
| 2 | 小红 | 1 | 一班 | F | 95 |
| 3 | 小军 | 1 | 一班 | M | 88 |
| 4 | 小米 | 1 | 一班 | F | 73 |
| 5 | 小白 | 2 | 二班 | F | 81 |
| 6 | 小兵 | 2 | 二班 | M | 55 |
| 7 | 小林 | 2 | 二班 | M | 85 |
| 8 | 小新 | 3 | 三班 | F | 91 |
| 9 | 小王 | 3 | 三班 | M | 89 |
| 10 | 小丽 | 3 | 三班 | F | 88 |
| 11 | 李平 | 5 | NULL | M | 95 |
注意:MYSQL是不支持FULL OUTER JOIN查询的。
为了便于大家理解JON查询,下边我们用图来表示各种查询的关系:
假设查询语句是:
SELECT ... FROM tableA ??? JOIN tableB ON tableA.column1 = tableB.column2;
我们把tableA看作左表,把tableB看成右表,那么INNER JOIN是选出两张表都存在的记录:
LEFT OUTER JOIN是选出左表存在的记录:
RIGHT OUTER JOIN是选出右表存在的记录:
FULL OUTER JOIN则是选出左右表都存在的记录:




2.7 嵌套查询
基于上边几节的描述常用的查询方法都已基本囊括,但是某些情况下我们需要将一个查询块(一个SELECT-FROM-WHERE子句称为查询块)嵌套在另一个查询块的 WHERE 子句或 HAVING 短语的条件中的查询称为嵌套查询。例如:
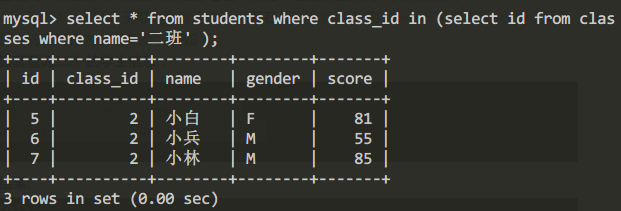
通过嵌套查询二班的学生信息:
select * from students where class_id in
(select id from classes where name='二班' );
查询结果:
嵌套查询可以使用户使用多个简单查询构成复杂的查询,从而增强SQL的查询能力。以层层嵌套的方式来构造程序正式SQL中“结构化”的含义所在。在使用嵌套查询的过程中根据子查询的方式不同,我们将查询分为下边三大类:
2.7.1 使用IN谓词的子查询
在嵌套查询中,子查询的结果往往是一个集合,所以谓词IN是嵌套查询中经常使用的谓词。比如我们要查询跟小丽同学考同样分数学生的信息我们可以通过如下步骤来构造嵌套查询。
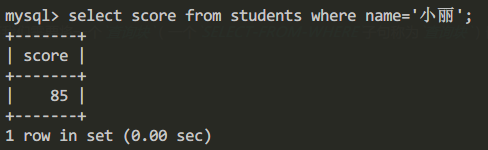
- 首先确定小丽同学所考的分数:
查询小丽同学所考的分数:
select score from students where name='小丽';
查询结果为:
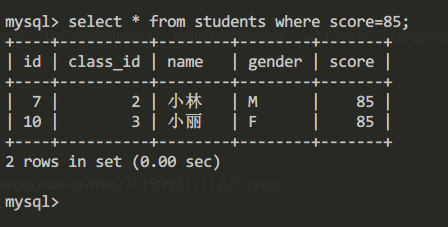
- 查询
students表中所有score=85的学生信息:
查询score=85的学生信息:
select * from students where score=85;
查询结果:
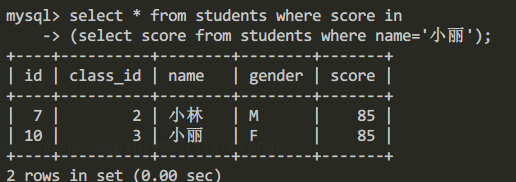
3. 将第一步构造的查询语句嵌套到第二句中构造嵌套查询。
查询语句为:
select * from students where score in
(select score from students where name='小丽');
查询结果为:
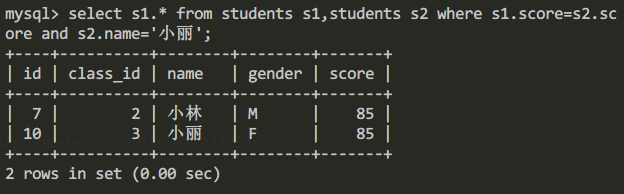
在这个例子程序中细心的同学会发现,子查询的查询条件是和父查询是相互独立的,对于此类查询我们称之为不相关子查询。对于此种查询我们实际上是可以通过连接查询来获取同样的查询结果的。例如上边“查询跟小丽同学考同样分数学生的信息”,我们可以通过如下的SQL语句进行替代:
select s1.* from students s1,students s2 where s1.score=s2.score and s2.name='小丽';
查询结果:
由此可见实现同一个结果的查询方式有很多种,但是不同方法查询的效率确实不同的。这就是数据编程人员需要掌握的数据性能调优技术,后续时间充裕,我会对常用的mysql查询的调优技术进行总结,此处便不进行详尽阐述了。
2.7.2 带有比较符号的子查询
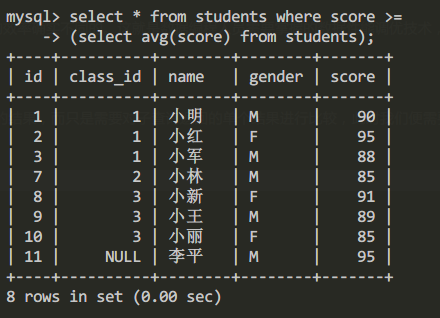
有时某些嵌套子查询中,我们并不需要通过IN详尽匹配子查询中的结果,而只是需要对子查询返回的单个结果进行比较,此时我们便需要使用比较运算符对查询结果进行限定。比如我们查询分数高于平均分的学生信息:
select id,class_id,name,gender,score from students s where score >=
(select avg(score) from students);
查询结果为:
注意:在使用比较符号时子查询的应当只有一个否则,查询结果是不正确的。
2.7.3 带有ANY(SOME) 或者ALL位于的子查询
子查询的结果有一个时可以使用比较运算符,但是当返回值有多个时我们需要通过ANY(SOME)或者ALL等谓语以及和比较符号一起连用来对结果进行限定,常见的用法以及含义如下表所示
| 限定符 | 作用 |
|---|---|
| >ANY | 大于子查询中的某个结果值 |
| >ALL | 大于子查询的所有结果值 |
| <ANY | 小于子查询结果中的某个值 |
| <ALL | 小于子查询结果中的所有值 |
| >=ANY | 大于等于子查询中的某个结果只 |
| >=ALL | 大于等于子查询中的所有结果只 |
| <=ANY | 小于等于子查询中的某个结果值 |
| <=ALL | 小于等于子查询的所有结果值 |
| =ANY | 等于子查询中的某个结果值 |
| =ALL | 等于子查询中的所有结果值(通常没有任何意义) |
| !=ANY | 不等于子查询中的某个结果值 |
| !=ALL | 不等于子查询中的所有结果值 |
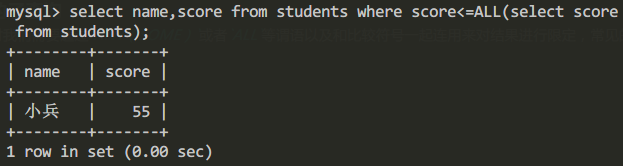
比如查询所有学生中分数最低的学生的姓名和成绩
select name,score from students where score<=ALL(select score from students);
查询结果为:
2.7.4 带EXISTS的子查询
EXISTS代表存在量词。带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真“true”和逻辑假“flase”。
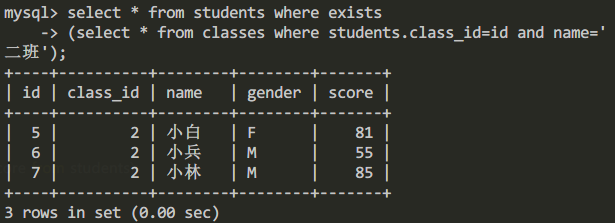
例如我们可以通过嵌套查询,查询二班所有学生的信息。
select * from students where exists
(select * from classes where students.class_id=id and name='二班');
查询结果:
注意:通过EXISTS引出的子查询,其目标表达式通常都是使用*,因为带有EXISTS的子查询只返回真值或者假值,给出列名没有任何意义。
2.8 基于派生表的查询
其实子查询有时候并不一定非要出现在WHERE子句中,还可以出现在FROM子句中,这是子查询产生的临时派生表成为朱查询的查询对象,这种查询方式我们称为基于派生表的查询。
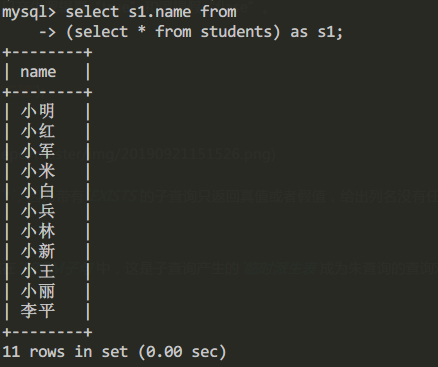
例如查询所有学生的姓名信息我们通过派生表查询方式实现:
select s1.name from
(select * from students) as s1
查询结果为:
当然我们在此处举例子可能意义不大,仅仅只是为了说明EXITS子句的用法。具体在开发过程中EXISTS的具体使用,需要读者自己去发掘和探索。
MYSQL之查询篇的更多相关文章
- MySQL之查询篇(三)
一:查询 1.创建数据库,数据表 -- 创建数据库 create database python_test_1 charset=utf8; -- 使用数据库 use python_test_1; -- ...
- mysql第四篇:数据操作之多表查询
mysql第四篇:数据操作之多表查询 一.多表联合查询 #创建部门 CREATE TABLE IF NOT EXISTS dept ( did int not null auto_increment ...
- mysql第四篇--SQL逻辑查询语句执行顺序
mysql第四篇--SQL逻辑查询语句执行顺序 一.SQL语句定义顺序 SELECT DISTINCT <select_list> FROM <left_table> < ...
- mysql 开发进阶篇系列 23 应用层优化与查询缓存
一.概述 前面章节介绍了很多数据库的优化措施,但在实际生产环境中,由于数据库服务器本身的性能局限,就必须要对前台的应用来进行优化,使得前台访问数据库的压力能够减到最小. 1. 使用连接池 对于访问数据 ...
- Mysql慢查询 [第二篇]
一.简介 pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog.General log.slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdu ...
- Mysql慢查询操作梳理
Mysql慢查询解释MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询 ...
- 查询MYSQL和查询HBASE速度比较
上一篇文章:我要上谷歌 Mysql,关系型数据库: HBase,NoSql数据库. 查询Mysql和查询HBase,到底哪个速度快呢? 与一些真正的大牛讨论时,他们说HBase写入速度,可以达到每秒1 ...
- MySQL慢查询(二) - pt-query-digest详解慢查询日志
一.简介 pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog.General log.slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdu ...
- MySQL慢查询(一) - 开启慢查询
一.简介 开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能. 二.参数说明 slow_query_log 慢查询开启状态slow_q ...
随机推荐
- spring-boot-plus项目打包(七)
spring-boot-plus项目打包 项目打包 spring-boot-plus项目使用maven assembly插件进行打包 根据不同环境进行打包部署 包含启动.重启命令,配置文件提取到外部c ...
- 在github上搭建个人博客并在线更新
换博客比更博还勤的我终于决定写一篇博客搭建教程了.. FAQ Q:\(hexo\)需要本地编译.\(jekyll\)虽然可以直接上传\(md\)..但是如果在github上直接编译也太难受了叭,毕竟不 ...
- 2019强网杯babybank wp及浅析
前言 2019强网杯CTF智能合约题目--babybank wp及浅析 ps:本文最先写在我的新博客上,后面会以新博客为主,看心情会把文章同步过来 分析 反编译 使用OnlineSolidityDec ...
- Go 面试每天一篇(第 1 天)
下面这段代码输出的内容 package main import ( "fmt" ) func main() { defer_call() } func defer_call() { ...
- sql查询技巧指南
传送门(牛客网我做过的每到题目答案以及解析) sql定义: 结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用 ...
- redis desktop manager安装及连接方式
1.下载安装包 官网下载地址:https://redisdesktop.com/pricing 官网下载需要付费使用 再此附上一个免费的破解版本,绿色安全可用 链接:https://pan.baidu ...
- WebApi使用OAuth2认证
本篇文章实现了四种认证方式中的客户端模式和密码模式,未实现token持久化 未介绍OAuth2的相关概念,全部是干货,可自己在网上搜索OAuth2相关知识,在这不做过多阐述 一.引用OAuth2所需的 ...
- CodeForces gym Nasta Rabbara lct
Nasta Rabbara 题意:简单来说就是, 现在有 n个点, m条边, 每次询问一个区间[ l , r ], 将这个区间的所有边都连上, 如果现在的图中有奇数环, 就输出 “Impossibl ...
- HDU 5126 stars 4维偏序, CDQ套CDQ
题目传送门 题意:在一个星空中,按着时间会出现一些点,现在john想知道,在某个时间内有多少个星星是的坐标是满足条件的.(x1<=x<=x2, y1 <= y <= y2, z ...
- lightoj 1140 - How Many Zeroes?(数位dp)
Jimmy writes down the decimal representations of all natural numbers between and including m and n, ...