R语言计算IV值
更多大数据分析、建模等内容请关注公众号《bigdatamodeling》
在对变量分箱后,需要计算变量的重要性,IV是评估变量区分度或重要性的统计量之一,R语言计算IV值的代码如下:
CalcIV <- function(df_bin, key_var, y_var){
N_0<-table(df_bin[, y_var])[1]
N_1<-table(df_bin[, y_var])[2]
iv_c<-NULL
var_c<-NULL
for (col in colnames(df_bin)){
if (col != key_var && col != y_var) {
frq<-as.data.frame(table(df_bin[, col], df_bin[, y_var]))
len<-length(unique(frq$Var1))
iv<-0
for (i in 1:len){
N_i_0<-frq$Freq[frq$Var1==i & frq$Var2==0]
N_i_1<-frq$Freq[frq$Var1==i & frq$Var2==1]
iv<-iv+(N_i_0/N_0- N_i_1/N_1)*log((N_i_0/N_0)/(N_i_1/N_1))
}
iv_c<-c(iv_c, iv)
var_c<-c(var_c, col)
}
}
iv_df<-data.frame(var=var_c, iv=iv_c, stringsAsFactors = FALSE)
return(iv_df)
}
其中,df_bin是分箱后的数据集,key_var是主键,y_var是y变量(0是好,1是坏)。代码运行结果如下:
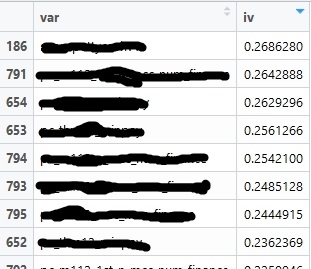
R语言计算IV值的更多相关文章
- R语言计算moran‘I
R语言计算moran‘I install.packages("maptools")#画地图的包 install.packages("spdep")#空间统计,m ...
- R语言计算相关矩阵然后将计算结果输出到CSV文件
R语言计算出一个N个属性的相关矩阵(),然后再将相关矩阵输出到CSV文件. 读入的数据文件格式如下图所示: R程序采用如下语句: data<-read.csv("I:\\SB\land ...
- Python计算IV值
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> 在对变量分箱后,需要计算变量的重要性,IV是评估变量区分度或重要性的统计量之一,python计算IV值的代码如下: ...
- 使用R语言-计算均值,方差等
R语言对于数值计算很方便,最近用到了计算方差,标准差的功能,特记录. 数据准备 height <- c(6.00, 5.92, 5.58, 5.92) 1 计算均值 mean(height) [ ...
- R语言查看栅格值
有这么一个需求,知道栅格上的坐标,想看看这个坐标上的栅格值是多少.坐标长这个样子 那么这样的坐标下的栅格值该怎么看 cellFromXY(the.stack$t1,c( -1505000,683500 ...
- [R语言]R语言计算unix timestamp的坑
R+mongo的组合真是各种坑等着踩 由于mongo中的时间戳普遍使用的是unix timestamp的格式,因此需要对每天的数据进行计算的时候,很容易就想到对timestamp + gap对方式来实 ...
- Windows中使用OpenBLAS加速R语言计算速度
在使用R的时候会发现R对CPU的利用率并不是很高,反正当我在使用R的时候,无论R做何种运算R的CPU利用率都只有百分子几,这就导致一旦计算量大的时候计算时间非常长,会给人一种错觉(R真的在计算吗?会不 ...
- R语言填充空缺值
在R语言中, imputeMissings包的特点是,如果空值是数值型,则使用median代替,如果使用的是character类型,则使用mode值代替. imputeMissing中,需要的包是im ...
- R语言分析(一)-----基本语法
一, R语言所处理的工作层: 解释一下: 最下面的一层为数据源,往上是数据仓库层,往上是数据探索层,包括统计分析,统计查询,还有就是报告 再往上的三层,分别是数据挖掘,数据展现和数据决策. 由上图 ...
随机推荐
- Maven和Gradle中配置单元测试框架Spock
Maven Maven本身不支持其他JVM语言(例如Groovy或Scala).要在Maven项目中使用它,需要使用第三方插件.对于Groovy而言,最好的选择似乎是GMavenPlus(重写不再维护 ...
- JS、JQ相关小技巧积攒
JS.JQ相关小技巧积攒,以备不时之需. 1.js 获取时间差:时间戳相减.new Date().getTime() 获得毫秒数,除以(1000*60*60*24) 获得天数. 2.重定向操作:页面 ...
- gitbook 入门教程之一招彻底解决 favicon 图标失效问题
favicon-absolute 项目 favicon-absolute 插件采用绝对路径设置网站 favicon 图标,相对于相对路径来说更加简单方便.
- 力扣(LeetCode)验证回文串 个人题解(C++)
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写. 说明:本题中,我们将空字符串定义为有效的回文串. 示例 1: 输入: "A man, a plan, a c ...
- Hadoop2.8.2 运行wordcount
1 例子jar位置 [hadoop@hadoop02 mapreduce]$ pwd /hadoop/hadoop-2.8.2/share/hadoop/mapreduce [hadoop@hadoo ...
- opencv 2 Opencv数据结构与基本绘图
基础图像容器Mat Mat 是一个类,又两个数据部分组成:矩阵头(包含矩阵尺寸,存储方法,存储地址等信息)和一个指向存储所有像素值的矩阵(根据所选存储方法不同,矩阵可以是不同的维数)的指针.矩阵头的尺 ...
- 爬虫json文件存储形式
json的表现形式和python中的字典是没有很大区别的,唯一的区别是dict的键是可hash对象,而json只能是字符串. 对于json的操作可以分为两类 一是对字符串的操作: 当需要将python ...
- Few-shot Object Detection via Feature Reweighting (ICCV2019)
论文:https://arxiv.org/abs/1812.01866 代码:https://github.com/bingykang/Fewshot_Detection 1.研究背景 深度卷积神经网 ...
- php+redis实现注册、删除、编辑、分页、登录、关注等功能
本文实例讲述了php+redis实现注册.删除.编辑.分页.登录.关注等功能.分享给大家供大家参考,具体如下: 主要界面 连接redis redis.php <?php //实例化 $red ...
- 迁移桌面程序到MS Store(13)——动态检查Win10 API是否可用
假设我们现有一个WPF程序,需要支持1903以前的Windows 10版本.同时在1903以后的版本上,额外多出一个Ink的功能.那么我们就可以通过ApiInformation.IsApiContra ...