EasyUI整合SpringBoot,Spring Data对数据的分页操作
EasyUI的用法可以看中文官网,看插件是如何使用的
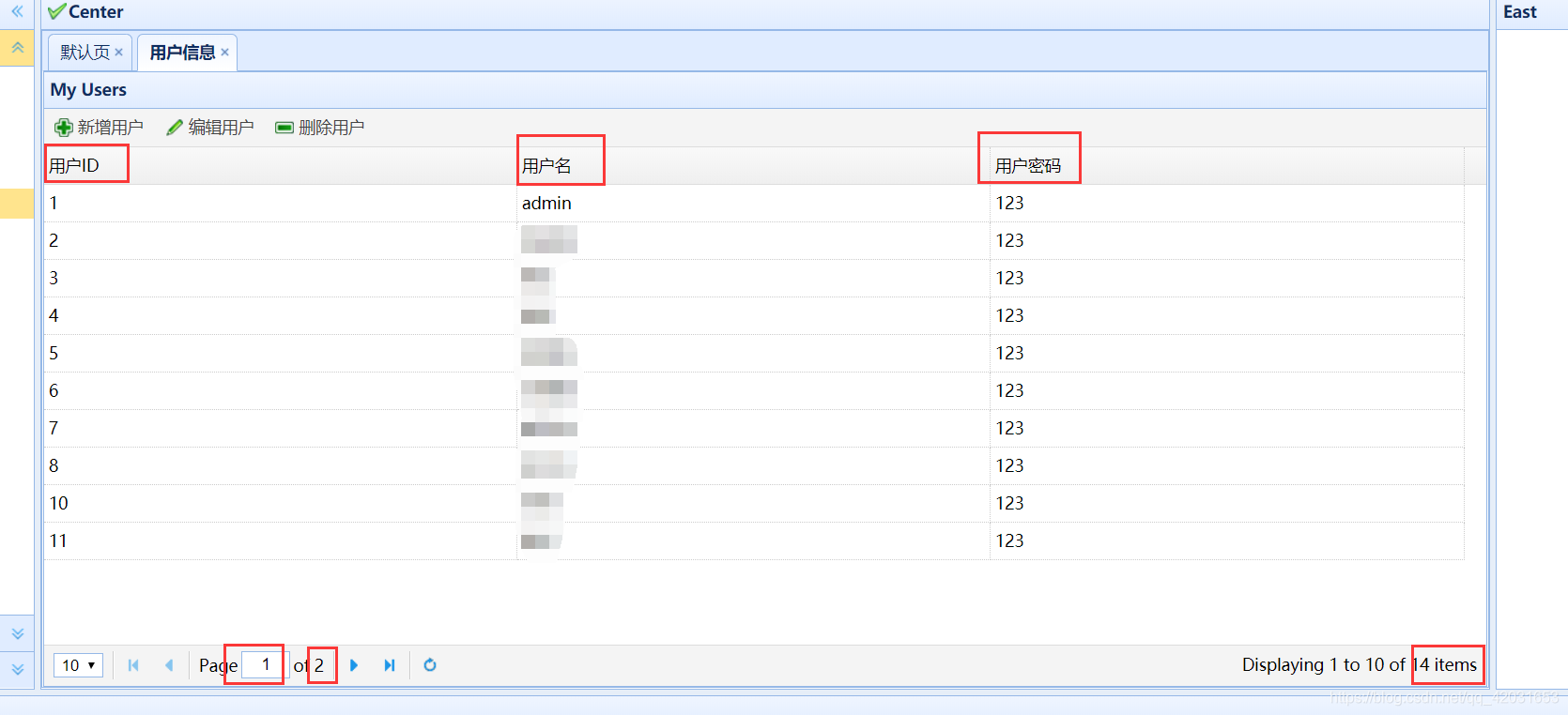
前端页面
<table id="dg" title="My Users" class="easyui-datagrid" style="width:700px;height:450px"
url="findall" data-options="fit:true"
toolbar="#toolbar" pagination="true"
rownumbers="false" fitColumns="true" singleSelect="true">
<thead>
<tr>
<th field="uid" width="350px">用户ID</th>
<th field="name" width="350px">用户名</th>
<th field="password" width="350px">用户密码</th>
</tr>
</thead>
</table>分页的请求数据有俩个
private List<T> rows;//每页有多少条数据
private Long total;//所有数据的统计先看俩个实体类
com.bjsxt.pojo.Users
package com.bjsxt.pojo;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
@Table(name = "t_user")
@Entity
@Data
public class Users implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "uid")
private int uid;
@Column(name = "name")
private String name;
@Column(name = "password")
private String password;
public Users(){}
public Users(String name, String password) {
this.name = name;
this.password = password;
}
}
com.bjsxt.pojo.Page
package com.bjsxt.pojo;
import lombok.Data;
import java.io.Serializable;
import java.util.List;
@Data
public class Page<T> implements Serializable {
private List<T> rows;//每页有多少条数据
private Long total;//所有数据的统计
public Page() {
}
public Page(List<T> rows, Long total) {
this.rows = rows;
this.total = total;
}
}
com.bjsxt.dao.UserDao
/**
* 处理分页操作
* @param page
* @param size
* @return
*/
@Query(value = "select * from t_user limit ?,?",nativeQuery = true)
public List<Users> findAll(int page,int size);
/**
* 统计操作
* @return
*/
@Query(value = "select count(*) from t_user ",nativeQuery = true)
public Long findUser();com.bjsxt.service.UserService
package com.bjsxt.service;
import com.bjsxt.pojo.Page;
import com.bjsxt.pojo.Users;
import java.util.List;
public interface UserService {
/**
* 登录业务
* @param name
* @param password
* @return
*/
public List<Users> selectOne(String name,String password);
/**
* 分页处理
* @param page
* @param size
* @return
*/
public Page<Users> findAll(int page, int size);
/**
* 添加用户
* @param users
*/
public int addUser(Users users);
/**
* 更新用户
* @param users
* @return
*/
public int updateUser(Users users);
/**
* 删除指定用户
* @param uid
* @return
*/
public int removeUser(int uid);
}
com.bjsxt.service.impl.UserServiceImpl
/**
* 处理分页
* @param page
* @param size
* @return
*/
@Override
public Page<Users> findAll(int page, int size) {
int start=(page-1)*size;
List<Users> users = userDao.findAll(start, size);
Long count = userDao.findUser();
Page<Users> page1=new Page<>(users,count);
return page1;
}在这里我们是真正的处理业务逻辑,将page,size转化成我们前端所需要接受的数据
com.bjsxt.controller.UserController
/**
* 分页查询所有
* @param page
* @param rows
* @return
*/
@RequestMapping("/findall")
@ResponseBody
public Page<Users> findAll(int page,int rows){
Page<Users> usAll = us.findAll(page, rows);
return usAll;
}
EasyUI整合SpringBoot,Spring Data对数据的分页操作的更多相关文章
- Springboot spring data jpa 多数据源的配置01
Springboot spring data jpa 多数据源的配置 (说明:这只是引入了多个数据源,他们各自管理各自的事务,并没有实现统一的事务控制) 例: user数据库 global 数据库 ...
- springboot集成Spring Data JPA数据查询
1.JPA介绍 JPA(Java Persistence API)是Sun官方提出的Java持久化规范.它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据.它的出现主要是为 ...
- springboot:spring data jpa介绍
转载自:https://www.cnblogs.com/ityouknow/p/5891443.html 在上篇文章springboot(二):web综合开发中简单介绍了一下spring data j ...
- javaweb各种框架组合案例(六):springboot+spring data jpa(hibernate)+restful
一.介绍 1.springboot是spring项目的总结+整合 当我们搭smm,ssh,ssjdbc等组合框架时,各种配置不胜其烦,不仅是配置问题,在添加各种依赖时也是让人头疼,关键有些jar包之间 ...
- EasyUi+Spring Data 实现按条件分页查询
Spring data 介绍 Spring data 出现目的 为了简化.统一 持久层 各种实现技术 API ,所以 spring data 提供一套标准 API 和 不同持久层整合技术实现 . 自己 ...
- R语言Data Frame数据框常用操作
Data Frame一般被翻译为数据框,感觉就像是R中的表,由行和列组成,与Matrix不同的是,每个列可以是不同的数据类型,而Matrix是必须相同的. Data Frame每一列有列名,每一行也可 ...
- 转载:R语言Data Frame数据框常用操作
Data Frame一般被翻译为数据框,感觉就像是R中的表,由行和列组成,与Matrix不同的是,每个列可以是不同的数据类型,而Matrix是必须相同的. Data Frame每一列有列名,每一行也可 ...
- Spring Data JPA:关联映射操作
1.一对一的关系关联 需求:用户和角色一对一关联 package com.example.jpa.pojo; import javax.persistence.*; @Entity @Table(na ...
- SpringBoot第九篇:整合Spring Data JPA
作者:追梦1819 原文:https://www.cnblogs.com/yanfei1819/p/10910059.html 版权声明:本文为博主原创文章,转载请附上博文链接! 前言 前面几章, ...
随机推荐
- layui多级弹框去掉遮罩
var index = layer.open({ type:1, title:'请选择费用代码', area:['1050px','650px'], content:$('#selectFee'), ...
- Scrapy简单上手 —— 安装与流程
一.安装scrapy 由于scrapy依赖较多,建议使用虚拟环境 windows下pip安装(不推荐) 1.安装virtualenv pip install virtualenv 2.在你开始项目的文 ...
- pxe批量部署
功能: 批量全自动安装操作系统方法: dhcp 自动分配IP tftp 微系统 用来安装系统 httpd 网络源 操作流程: #检查环境 getenforce #检查selinux systemctl ...
- Linux 部署Nginx反向代理服务 使用openssl自生成证书并配置https
1.安装Nginx编译所依赖的包 正常centos中可以使用yum安装一下依赖包: yum install -y gcc gcc-c++ pcre pcre-devel zlib zlib-devel ...
- 【集合系列】- 深入浅出分析LinkedHashMap
一.摘要 在集合系列的第一章,咱们了解到,Map的实现类有HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.Pro ...
- tornado的使用-参数篇
tornado的使用-参数篇
- 南开大学校徽及手写字的Tikz源码
话不多说,直接上内容. % ---------------------------------- % !TeX enginee = pdfLaTeX/XeLaTeX % !TeX encoding = ...
- 理解Spark运行模式(二)(Yarn Cluster)
上一篇说到Spark的yarn client运行模式,它与yarn cluster模式的主要区别就是前者Driver是运行在客户端,后者Driver是运行在yarn集群中.yarn client模式一 ...
- 100天搞定机器学习|Day56 随机森林工作原理及调参实战(信用卡欺诈预测)
本文是对100天搞定机器学习|Day33-34 随机森林的补充 前文对随机森林的概念.工作原理.使用方法做了简单介绍,并提供了分类和回归的实例. 本期我们重点讲一下: 1.集成学习.Bagging和随 ...
- 领扣(LeetCode)交替位二进制数 个人题解
给定一个正整数,检查他是否为交替位二进制数:换句话说,就是他的二进制数相邻的两个位数永不相等. 示例 1: 输入: 5 输出: True 解释: 5的二进制数是: 101 示例 2: 输入: 7 输出 ...