Paper | One-to-Many Network for Visually Pleasing Compression Artifacts Reduction
发表于2017年CVPR。
目标:JPEG图像去压缩失真。
主要内容:
同时使用感知损失、对抗损失和JPEG损失(已知量化间隔,惩罚落在间隔外的值),让恢复图像主客观质量都更好。
对像素进行平移-均值化处理,进一步抑制块效应。
亮点:解释了one-to-many的合理性:由于图像恢复是欠定问题,因此理应有多张潜在的高质量图像 可供选择。但是最终没有体现one-to-many啊摔!而是加权组合了这三个损失函数,没有多输出。
评分:⭐⭐
故事
有损压缩被广泛使用,但是带来伪影。 => 去除伪影(压缩失真)是很重要的,因为伪影会导致用户观感下降 和 视觉任务精度下降。 => 当前,深度学习已经展示了强大的性能,但普遍导致过度平滑。
JPEG压缩失真主要是由于每个块的独立量化导致的边缘不连续(块效应)。量化是一个多对一的映射,然而目前的网络大多是一对一映射。因此,对于一张有损图像,我们应该得到多张潜在的高质量图像,再挑选。因此,一对多映射是更好的学习方式。毕竟,一千个人心中有一千个哈姆雷特。
一对多映射,就涉及到多个衡量标准。 => 首先,per-pixel损失是不够的。很简单的例子:我们将图像平移一下,per-pixel损失就会特别大。但二者的本质是一样的。 => 因此,我们引入感知质量。感知质量可以衡量高层语义上的距离。 => 但是,感知质量也不够:它对粗糙纹理的辨别能力不强【这里的论证太弱】。因此我们引入对抗损失,可以将网络引向更逼真的纹理细节。 => 在像素域上也希望有约束,因此引入JPEG损失,对落在量化间隔外的样本进行惩罚(已知量化水平和量化表)。
最后,作者还引入了平移-均值化(shift-and-average)方法,进一步抑制块效应(grid-like artifacts)。
网络设计
网络前端
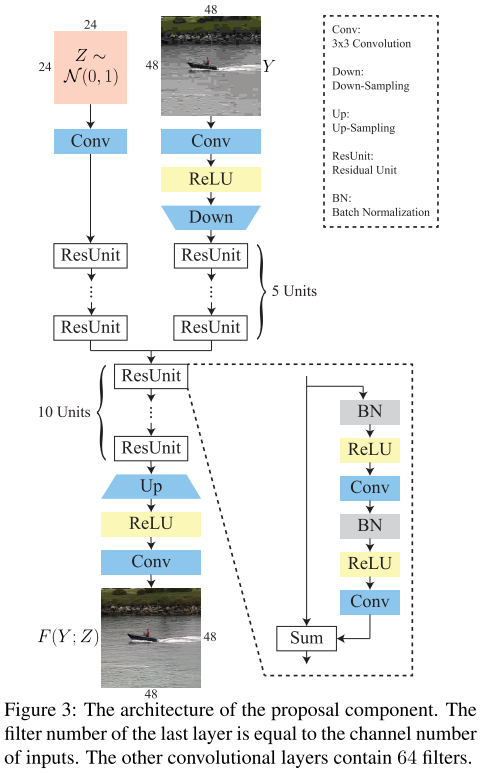
\(Z\)是AWGN,经过卷积后,会与 有损图像\(Y\)的卷积 相加,目的是让网络更健壮。有点意思。
一句话挺有意思:
As JPEG compression is not optimal, redundant information neglected by the JPEG encoder may still be found in a compressed image.
其中的降采样是步长为2的\(4 \times 4\)卷积,升采样是步长为2的\(4 \times 4\)反卷积。之所以降采样:(1)降低计算量;(2)增大感受野。
升采样中的平移-均值化
这里作者介绍了为什么要、如何做 平移-均值化。
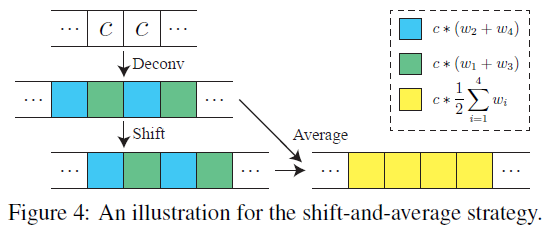
假设该信号中每一个值都是常数c。做步长为2的\(4 \times 4\)反卷积的步骤:首先插2个零,变成c00c,然后在卷积时就是平移取互相关。
作者发现,若我们平移一位再做反卷积,然后两个结果求平均,那么结果就是我们想要的常数结果。否则,结果非处处为常数。
当然,作者没有详细说明这样做的合理性。这不过是一个成功的例子。
网络度量
感知损失借助[39]的VGG-16,对抗损失借助[34]的DCGAN。
JPEG损失具体:计算有损图像\(Y\)和重建图像\(\hat{X}\)在每个像素点的距离。理想情况下,如果无损图像某个点的值是\(X\),那么其量化后的值\(Y\)不会超过其正负半个量化间隔。即,二者距离不会超过半个量化间隔。同理,计算出来的结果也应该在半个量化间隔内。
如果超过量化间隔的一半,就作为损失惩罚;若不大于一半,那么就为0。即取一个\(max(dis, 0)\)函数。
训练
果不其然,训练是综合三个损失函数,并非多输出。这怎么能叫one-to-many???
Paper | One-to-Many Network for Visually Pleasing Compression Artifacts Reduction的更多相关文章
- Paper | Compression artifacts reduction by a deep convolutional network
目录 1. 故事 2. 方法 3. 实验 这是继SRCNN(超分辨)之后,作者将CNN的战火又烧到了去压缩失真上.我们看看这篇文章有什么至今仍有启发的故事. 贡献: ARCNN. 讨论了low-lev ...
- 【Paper】Deep & Cross Network for Ad Click Predictions
目录 背景 相关工作 主要贡献 核心思想 Embedding和Stacking层 交叉网络(Cross Network) 深度网络(Deep Network) 组合层(Combination Laye ...
- 读paper:Deep Convolutional Neural Network using Triplets of Faces, Deep Ensemble, andScore-level Fusion for Face Recognition
今天给大家带来一篇来自CVPR 2017关于人脸识别的文章. 文章题目:Deep Convolutional Neural Network using Triplets of Faces, Deep ...
- Paper | Dynamic Residual Dense Network for Image Denoising
目录 1. 故事 2. 动机 3. 做法 3.1 DRDB 3.2 训练方法 4. 实验 发表于2019 Sensors.这篇文章的思想可能来源于2018 ECCV的SkipNet[11]. 没开源, ...
- Paper | A Pseudo-Blind Convolutional Neural Network for the Reduction of Compression Artifacts
目录 非盲增强网络结构 训练目标 压缩系数预测子网络 网络结构 根据块QP判决结果得到帧QP预测结果 保持时序连续性 实验 发表在2019年TCSVT. 本文提出了一个兼具 预测压缩系数 和 非盲去压 ...
- Paper | Non-Local ConvLSTM for Video Compression Artifact Reduction
目录 1. 方法 1.1 框图 1.2 NL流程 1.3 加速版NL 2. 实验 3. 总结 [这是MFQE 2.0的第一篇引用,也是博主学术生涯的第一篇引用.最重要的是,这篇文章确实抓住了MFQE方 ...
- CVPR 2017 Paper list
CVPR2017 paper list Machine Learning 1 Spotlight 1-1A Exclusivity-Consistency Regularized Multi-View ...
- Deep Learning-Based Video Coding: A Review and A Case Study
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 1.Abstract: 本文主要介绍的是2015年以来关于深度图像/视频编码的代表性工作,主要可以分为两类:深度编码方案以及基于传统编码方 ...
- DeepCoder: A Deep Neural Network Based Video Compression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract: 在深度学习的最新进展的启发下,我们提出了一种基于卷积神经网络(CNN)的视频压缩框架DeepCoder.我们分别对预测 ...
随机推荐
- 数据库导出--Oracle-dmp格式
expdp 数据库名/数据库密码@orcl directory=backdir dumpfile=导出文件名称.dmp 例: expdp bedManager_nt/123456@orcl direc ...
- Python进阶小结
目录 一.异常TODO 二.深浅拷贝 2.1 拷贝 2.2 浅拷贝 2.3 深拷贝 三.数据类型内置方法 3.1 数字类型内置方法 3.1.1 整型 3.1.2 浮点型 3.2 字符串类型内置方法 3 ...
- C语言程序设计100例之(9):生理周期
例9 生理周期 问题描述 人生来就有三个生理周期,分别为体力.感情和智力周期,它们的周期长度为 23 天.28 天和33 天.每一个周期中有一天是高峰.在高峰这天,人会在相应的方面表现出色.例如 ...
- @Transactional什么情况才生效
只有runtimeexception并且没有被try catch处理的异常才会回滚. 想要回滚,不要去try 还有一个坑时逻辑上的问题,之前总以为插入,更新后,返回值为0,@Transactional ...
- Nginx反向代理及负载均衡介绍
Nginx的产生 没有听过Nginx?那么一定听过它的"同行"Apache吧!Nginx同Apache一样都是一种WEB服务器.基于REST架构风格,以统一资源描述符(Unifor ...
- Spring Cloud Alibaba基础教程:Sentinel Dashboard同步Apollo存储规则
在之前的两篇教程中我们分别介绍了如何将Sentinel的限流规则存储到Nacos和Apollo中.同时,在文末的思考中,我都指出了这两套整合方案都存在一个不足之处:不论采用什么配置中心,限流规则都只能 ...
- KeContextToKframes函数逆向
在逆向_KiRaiseException(之后紧接着就是派发KiDispatchException)函数时,遇到一个 KeContextToKframes 函数,表面意思将CONTEXT转换为 TRA ...
- 前端之jquery1
jquery介绍 jQuery是目前使用最广泛的javascript函数库.据统计,全世界排名前100万的网站,有46%使用jQuery,远远超过其他库.微软公司甚至把jQuery作为他们的官方库. ...
- excel 知识备忘
public void UpdateShapesColor(string value) { foreach (Microsoft.Office.Interop.Excel.Shape chart in ...
- python基础(8):基本数据类型三(dict)、is和==、编码和解码
1. 字典 1.1 字典的介绍 字典(dict)是python中唯一的一个映射数据类型,它是以{}括起来的键值对组成.在dict中key是唯一的,在保存的时候,根据key来计算出一个内存地址,然后将k ...