MySQL中的存储过程、函数与触发器
一.对待存储过程和函数的态度
在实际项目中应该尽量少用存储过程和函数,理由如下:
1.移植性差,在MySQL中的存储过程移植到sqlsever上就不一定可以用了。
2.调试麻烦,在db中报一个错误和在应用层报一个错误不是一个概念,那将是毁灭性打击,直接一个error:1045什么的更本毫无头绪。
3.扩展性不高。
所以在互联网时代大型项目应该尽量少使用(不使用)存储过程和函数。
二.创建存储过程
2.1什么是存储过程?
存储过程和存储函数都是一组sql语句的集合。这些语句集合被当做一个整体存入数据库中。
2.2创建存储过程的语法:
create procedure 存储过程名(参数列表)
sql语句
例子:
delimiter //
create procedure pro()
reads sql data
begin
select * from stu;
end
那么我们现在就有一个存储过程pro了,但是这个存储过程他是没有参数的,他只是执行一次查询操作。
我们现在来讲解一下这个存储过程的结构:
delimiter // 是将分号转化为// 因为在sql执行时当他遇到分号 ; 时他就讲停止所以我们必须将其转化为 //直到最后一行才会停止执行。
reads sql data 解释characteristic的状态在这里是只读模式,其他的模式还有:no sql 没有sql语句 , ins sql 不包含读和写的语句 , modifies sql data 包含写入数据的语句等等。
begin /***/ end 在存储过程中当有多条语句集合时我们必须使用begin和end
// 结束整个存储过程
2.3使用存储过程
在只是创建了一个存储过程,那么我们怎么来使用这个存储过程呢?
语法:call 存储过程名()
将上一个存储过程pro使用的例子:
call pro();
2.4创建一个带参数的存储过程
参数列表:存储过程的参数有三种类型:in,out,inout 分别表示传入参数和传出参数,和即传入也传出参数。
例子:首先我们来创建两张表:课程表是学生表的从表
create table stu(
stu_id bigint primary key auto_increment,#学号
stu_name varchar(10) not null,#姓名
stu_major int not null,#专业号
stu_sex char,#性别
stu_in date,#入学日期
stu_birth date,#出生日期
foreign key (stu_major) references major(ma_id)#专业外键设置
); create table major(
ma_id int primary key,
ma_name varchar(15),
ma_boss varchar(10)
);
insert into major values(1,"信管","张三");
insert into major values(2,"电子商务","李四");
insert into stu values(1,"小明",1,"男","2017-09-01","1998-12-23");
insert into stu values(2,"小高",1,"男","2017-09-01","1998-05-01");
insert into stu values(3,"小李",2,"男","2017-09-01","1999-04-01");
我们再来创建一个带有参数的存储过程找到学生的主修课的名字,代码如下:
delimiter //
create procedure pro1(in sname varchar(10),out ma varchar(10))
reads sql data
begin
select ma_name into ma from major where ma_id = (select stu_major from stu where stu_name=sname);
end
//
使用这个存储过程:代码如下:
set @ma="没查询之前";
call pro1("小李",@ma);
select @ma;
结果如下:
解释一下代码:首先使用set @ma 定义一个全局变量,然后在使用call 存储过程名 语法调用存储过程,同时全局变量ma的值也改变了。
三.创建一个存储函数
3.1存储过程和存储函数的不同。
1.在函数中必须要有return返回值
2.在存储过程中参数有in out inout三种,默认为in类型,但是在函数中只有一种in类型。
3.2创建一个函数
语法:create function 函数名()
return 返回类型
sql语句集合
例子:
delimiter //
create function fun1(num int)
returns int
begin
return num+1000;
end
//
显然函数与存储过程的最大的区别就是在于return
3.3调用函数
使用语法不在使用关键字call,而是关键字select ,select 函数名
例子:
select fun1(100);
结果: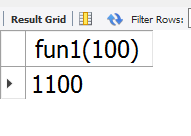
四.删除存储函数和存储过程
语法:drop procedure | function 存储过程名或者是函数名
例子:
drop procedure pro;
注意他是不带括号的
五.在存储过程和存储函数中使用游标
5.1为什么需要游标?
当我们在使用存储过程的时候可能用到多条数据,那么我们就需要用到游标来存放多条数据。
5.2使用游标的注意点
游标不能单独存在,必须在存储过程或者是存储函数中使用。
5.3使用游标
语法:
1.创建游标:declare 游标名 cursor for select语句
2.打开游标:open 游标名
3.使用游标:fetch 游标名 into 变量名
4.关闭光标:close 游标名
5.4例子
delimiter //
create function fun3(id int)
returns int
reads sql data
begin
declare cur cursor for select stu_id from stu;
open cur;
fetch cur into id;
close cur;
return id;
end
//
使用
set @id=0;
select fun3(@id);
结果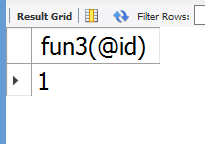
可以发现游标只是将第一个值给了变量。
六、什么是触发器
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性。
举个例子,比如你现在有两个表【用户表】和【日志表】,当一个用户被创建的时候,就需要在日志表中插入创建的log日志,如果在不使用触发器的情况下,你需要编写程序语言逻辑才能实现,但是如果你定义了一个触发器,触发器的作用就是当你在用户表中插入一条数据的之后帮你在日志表中插入一条日志信息。当然触发器并不是只能进行插入操作,还能执行修改,删除。
创建触发器
创建触发器的语法如下:

CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW trigger_stmt
trigger_name:触发器的名称
tirgger_time:触发时机,为BEFORE或者AFTER
trigger_event:触发事件,为INSERT、DELETE或者UPDATE
tb_name:表示建立触发器的表明,就是在哪张表上建立触发器
trigger_stmt:触发器的程序体,可以是一条SQL语句或者是用BEGIN和END包含的多条语句
所以可以说MySQL创建以下六种触发器:
BEFORE INSERT,BEFORE DELETE,BEFORE UPDATE
AFTER INSERT,AFTER DELETE,AFTER UPDATE
其中,触发器名参数指要创建的触发器的名字
BEFORE和AFTER参数指定了触发执行的时间,在事件之前或是之后
FOR EACH ROW表示任何一条记录上的操作满足触发事件都会触发该触发器
创建有多个执行语句的触发器
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN
执行语句列表
END
其中,BEGIN与END之间的执行语句列表参数表示需要执行的多个语句,不同语句用分号隔开
tips:一般情况下,mysql默认是以 ; 作为结束执行语句,与触发器中需要的分行起冲突
为解决此问题可用DELIMITER,如:DELIMITER ||,可以将结束符号变成||
当触发器创建完成后,可以用DELIMITER ;来将结束符号变成;
mysql> DELIMITER ||
mysql> CREATE TRIGGER demo BEFORE DELETE
-> ON users FOR EACH ROW
-> BEGIN
-> INSERT INTO logs VALUES(NOW());
-> INSERT INTO logs VALUES(NOW());
-> END
-> ||
Query OK, 0 rows affected (0.06 sec) mysql> DELIMITER ;
上面的语句中,开头将结束符号定义为||,中间定义一个触发器,一旦有满足条件的删除操作
就会执行BEGIN和END中的语句,接着使用||结束
最后使用DELIMITER ; 将结束符号还原
tigger_event:

load data语句是将文件的内容插入到表中,相当于是insert语句,而replace语句在一般的情况下和insert差不多,但是如果表中存在primary 或者unique索引的时候,如果插入的数据和原来的primary key或者unique相同的时候,会删除原来的数据,然后增加一条新的数据,所以有的时候执行一条replace语句相当于执行了一条delete和insert语句。
触发器可以是一条SQL语句,也可以是多条SQL代码块,那如何创建呢?
DELIMITER $ #将语句的分隔符改为$
BEGIN
sql1;
sql2;
...
sqln
END $
DELIMITER ; #将语句的分隔符改回原来的分号";"
在BEGIN...END语句中也可以定义变量,但是只能在BEGIN...END内部使用:
DECLARE var_name var_type [DEFAULT value] #定义变量,可指定默认值
SET var_name = value #给变量赋值
NEW和OLD的使用:

根据以上的表格,可以使用一下格式来使用相应的数据:
NEW.columnname:新增行的某列数据
OLD.columnname:删除行的某列数据
说了这么多现在我们来创建一个触发器吧!
现在有表如下:
用户users表
CREATE TABLE `users` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL,
`add_time` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`(250)) USING BTREE
) ENGINE=MyISAM AUTO_INCREMENT=1000001 DEFAULT CHARSET=latin1;
日志logs表:
CREATE TABLE `logs` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`log` varchar(255) DEFAULT NULL COMMENT '日志说明',
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='日志表';
需求是:当在users中插入一条数据,就会在logs中生成一条日志信息。
创建触发器:
DELIMITER $
CREATE TRIGGER user_log AFTER INSERT ON users FOR EACH ROW
BEGIN
DECLARE s1 VARCHAR(40)character set utf8;
DECLARE s2 VARCHAR(20) character set utf8;#后面发现中文字符编码出现乱码,这里设置字符集
SET s2 = " is created";
SET s1 = CONCAT(NEW.name,s2); #函数CONCAT可以将字符串连接
INSERT INTO logs(log) values(s1);
END $
DELIMITER ;
这里我用的navicat: 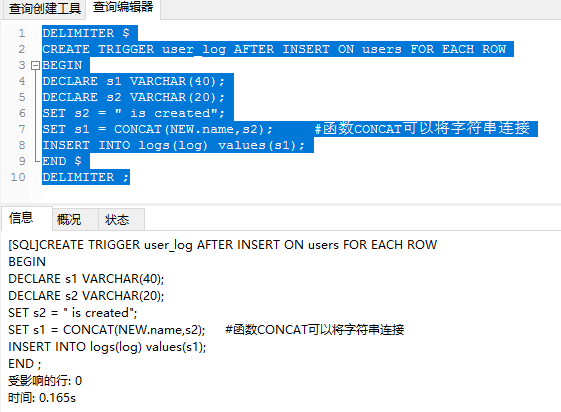
查看触发器
SHOW TRIGGERS语句查看触发器信息

Tip:
上面我用的navicat直接创建,如果大家用的mysql front,name这里会有个区别,我们删除刚才的触发器,在Mysql front中测试
drop trigger user_log;#删除触发器
打开Mysql Front:
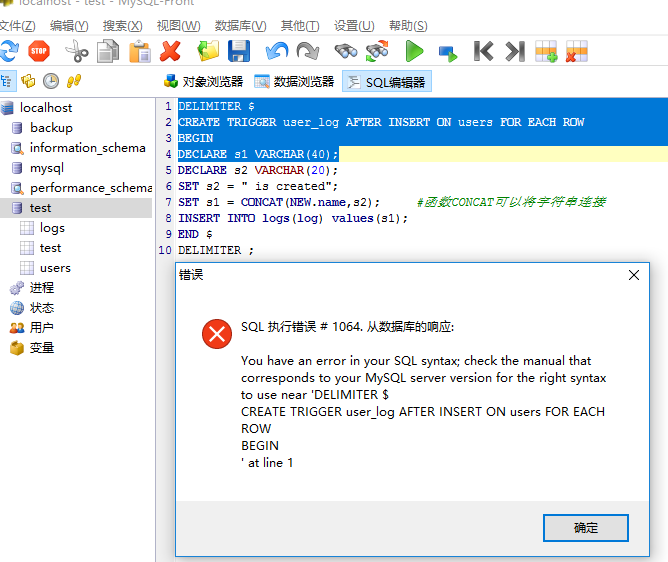
mysql front在编译sql时,不用定义结尾分隔符,修改后的sql直接这样既可:
#DELIMITER $
CREATE TRIGGER user_log AFTER INSERT ON users FOR EACH ROW
BEGIN
DECLARE s1 VARCHAR(40)character set utf8;
DECLARE s2 VARCHAR(20) character set utf8;
SET s2 = " is created";
SET s1 = CONCAT(NEW.name,s2); #函数CONCAT可以将字符串连接
INSERT INTO logs(log) values(s1);
END #$
#DELIMITER ;

这里再啰嗦几句:
tips:SHOW TRIGGERS语句无法查询指定的触发器
在triggers表中查看触发器信息
SELECT * FROM information_schema.triggers;

结果显示了所有触发器的详细信息,同时,该方法可以查询制定触发器的详细信息
SELECT * FROM information_schema.triggers WHERE TRIGGER_NAME='user_log';
tips:所有触发器信息都存储在information_schema数据库下的triggers表中
可以使用SELECT语句查询,如果触发器信息过多,最好通过TRIGGER_NAME字段指定查询
回到上面,我们创建好了触发器,继续在users中插入数据并查看数据:
insert into users(name,add_time) values('周伯通',now());
好吧,我们再来查看一下logs表吧!
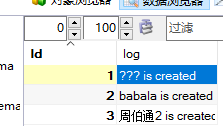
通过上面的例子,可以看到只需要在users中插入用户的信息,日志会自动记录到logs表中,这也许就是触发器给我带来的便捷吧!
限制和注意事项
触发器会有以下两种限制:
1.触发程序不能调用将数据返回客户端的存储程序,也不能使用采用CALL语句的动态SQL语句,但是允许存储程序通过参数将数据返回触发程序,也就是存储过程或者函数通过OUT或者INOUT类型的参数将数据返回触发器是可以的,但是不能调用直接返回数据的过程。
2.不能再触发器中使用以显示或隐式方式开始或结束事务的语句,如START TRANS-ACTION,COMMIT或ROLLBACK。
注意事项:MySQL的触发器是按照BEFORE触发器、行操作、AFTER触发器的顺序执行的,其中任何一步发生错误都不会继续执行剩下的操作,如果对事务表进行的操作,如果出现错误,那么将会被回滚,如果是对非事务表进行操作,那么就无法回滚了,数据可能会出错。
原文出处:
https://www.cnblogs.com/SAM-CJM/p/9711458.html
https://www.cnblogs.com/phpper/p/7587031.html
MySQL中的存储过程、函数与触发器的更多相关文章
- MySQL mysqldump 导入/导出 结构&数据&存储过程&函数&事件&触发器
———————————————-库操作———————————————-1.①导出一个库结构 mysqldump -d dbname -u root -p > xxx.sql ②导出多个库结构 m ...
- MySQL中的存储过程和函数使用详解
一.对待存储过程和函数的态度 在实际项目中应该尽量少用存储过程和函数,理由如下: 1.移植性差,在MySQL中的存储过程移植到sqlsever上就不一定可以用了. 2.调试麻烦,在db中报一个错误和在 ...
- MySQL中的存储过程、游标和存储函数
MySQL中的存储过程首先来看两个问题: 1.什么是存储过程? 存储过程(Stored Procedure)是在数据库系统中,一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存 ...
- mysql 中创建存储过程
mysql中创建存储过程和存储函数虽相对其他的sql语言相对复杂,但却功能强大,存储过程和存储函数更像是一种sql语句中特定功能的一种封装,这种封装可以大大简化外围调用语句的复杂程度. 首先以表emp ...
- Mysql中使用find_in_set函数查找字符串
mysql有个表的字段的存储是以逗号分隔的,如domain字段login.s01.yy.com,s01.yy.com,s02.yy.com.现在要查找s01.yy.com这个.我们用like查找好像不 ...
- mysql中的group_concat函数的用法
本文通过实例介绍了MySQL中的group_concat函数的使用方法,比如select group_concat(name) . MySQL中group_concat函数 完整的语法如下: grou ...
- SQLServer 中实现类似MySQL中的group_concat函数的功能
SQLServer中没有MySQL中的group_concat函数,可以把分组的数据连接在一起. 后在网上查找,找到了可以实现此功能的方法,特此记录下. SELECT a, stuff((SELECT ...
- mysql中的substr()函数
mysql中的substr()函数和hibernate的substr()参数都一样,就是含义有所不同. 用法: substr(string string,num start,num length); ...
- Mysql中常用的函数汇总
Mysql中常用的函数汇总: 一.数学函数abs(x) 返回x的绝对值bin(x) 返回x的二进制(oct返回八进制,hex返回十六进制)ceiling(x) 返回大于x的最小整数值exp(x) 返回 ...
随机推荐
- Net Core 3.0 尝鲜指南
swagger .Net Core 3.0中的swagger,必须引用5.0.0 及以上版本.可以在Nuget官网查看版本.目前最新版本(2019-9-25) 5.0.0rc3 Install-Pac ...
- IT兄弟连 HTML5教程 HTML5的基本语法 如何选择开发工具
如何选择开发工具 有许多可以编辑网页的软件,事实上你不需要用任何专门的软件来建立HTML页面,你所需要的只是一个文本编辑器(或字处理器),如Office Word.记事本.写字板等.制作页面初学者通常 ...
- 【Oracle命令 】使用的sql语句之分组查询(group by)
由于本人并未对oracle数据库进行深入了解,但是工作中又需要知道一些基础的sql,所以记录下操作的sql语句.方便日后查看 1.将序列号作为分组查询的条件,再将查询出来的结果进行筛选. select ...
- (四)初识NumPy(函数和图像的数组表示)
本章节主要介绍NumPy中的三个主要的函数,分别是随机函数.统计函数和梯度函数,以及一个较经典的用数组来表示图像的栗子!,希望大家能有新的收货,共同进步! 一.np.random的随机函数(1) ra ...
- ajax运行原理
Ajax应用程序的加载过程与传统的Web应用程序类似.某个用户操作引发浏览器的一次HTTP请求.服务器接收请求并处理这个请求,生成合适的执行结果发送至客户端.客户端浏览器经过处理将数据(HTML+CS ...
- HashMap中 工具方法tableSizeFor的作用
[转] https://blog.csdn.net/fan2012huan/article/details/51097331 首先看下该方法的定义以及被使用的地方 static final int t ...
- 来认识一下venus-init——一个让你仅需一个命令开始Java开发的命令行工具
源代码地址: Github仓库地址 个人网站:个人网站地址 前言 不知道你是否有过这样的经历.不管你是什么岗位,前端也好,后端也罢,想去了解一下Java开发到底是什么样的,它是不是真的跟传说中的一样. ...
- 朋友想玩下百度的ORC我鼓捣鼓捣thinkphp3集成百度sdk
他想玩的是文字识别 那就玩下 咱们开始 1 先到百度文字识别 添加个应用 这样就有了APPID API KEY SECRET KEY https://console.bce.baidu.com ...
- frigate_TUNNEL
#coding=utf-8 Result=open('result.txt',"w") FileTunnel = open('tunnel.txt').readlines() Ne ...
- pycharm2019.2一个奇怪的bugger,执行后输出内容被莫名处理
2019-08-20 07:45:07 python爬虫是一直来大家都用的多的,我也是常常用到. requests做请求方便的很,但是今天却遇到requests的bug.text内容不可信. pych ...