caffe中softmax源码阅读
(1) softmax函数
 (1)
(1)
其中,zj 是softmax层的bottom输入, f(zj)是softmax层的top输出,C为该层的channel数。
(2) softmax_layer.cpp中的Reshape函数:
template <typename Dtype>
void SoftmaxLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom, //bottom blob为softmax层的输入,top blob为该层输出。
const vector<Blob<Dtype>*>& top) {
softmax_axis_ = //softmax_axis_为1
bottom[]->CanonicalAxisIndex(this->layer_param_.softmax_param().axis());
top[]->ReshapeLike(*bottom[]); //使用bttom[0]的shape和值去初始化top[0],后面所有的操作基于top[0]
//bottom[0]的shape为[N, C, H, W], bottom[0]->shape(softmax_axis_)的值为C
vector<int> mult_dims(, bottom[]->shape(softmax_axis_));
//Blob<Dtype> sum_multipiler、Blob<Dtype> scale_、int outer_num_、int inner_num_变量定义在softmax_layer.hpp中
//初始化sum_multiplier, mult_dims的值为C
sum_multiplier_.Reshape(mult_dims);
Dtype* multiplier_data = sum_multiplier_.mutable_cpu_data();
//设置sum_multiplier的所有元素值为1
caffe_set(sum_multiplier_.count(), Dtype(), multiplier_data);
//blob的shape为[N, C, H, W], 形象点说就是blob->shape[0] = N, blob->shape[1] = C
//blob的count为N*C*H*W,形象点说就是blob->count() = N*C*H*W
//blob->count(0, 2)中的(0, 2)是左闭右开区间,返回的是N*C
//所以就有outer_num_ = bottom[0]->count(0, softmax_axis_) = N
// inner_num_ = bottom[0]->count(softmax_axis_) = H*W
outer_num_ = bottom[]->count(, softmax_axis_);
inner_num_ = bottom[]->count(softmax_axis_ + );
//下面两行scale_dims的shape为[N, 1, H, W]
vector<int> scale_dims = bottom[]->shape();
scale_dims[softmax_axis_] = ;
//scale_ blob的shape为[N, 1, H, W]
scale_.Reshape(scale_dims);
}
(3) softmax_layer.cpp中的Forward_cpu函数:
template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[]->cpu_data();
Dtype* top_data = top[]->mutable_cpu_data();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = bottom[]->shape(softmax_axis_); //channels = C
int dim = bottom[]->count() / outer_num_; //dim = N*C*H*W / N = C*H*W
caffe_copy(bottom[]->count(), bottom_data, top_data); //将bottom_data的blob数据复制给top_data的blob.
// We need to subtract the max to avoid numerical issues, compute the exp,
// and then normalize.
//求channel最大值,存放在scale_ blob中。
for (int i = ; i < outer_num_; ++i) {
// initialize scale_data to the first plane
caffe_copy(inner_num_, bottom_data + i * dim, scale_data);
for (int j = ; j < channels; j++) {
for (int k = ; k < inner_num_; k++) {
scale_data[k] = std::max(scale_data[k],
bottom_data[i * dim + j * inner_num_ + k]);
}
}
// subtraction
//bottom blob数据减去对应channel的最大值
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_,
, -., sum_multiplier_.cpu_data(), scale_data, ., top_data);
// exponentiation
//对每个样本的每个channel数据取e.
caffe_exp<Dtype>(dim, top_data, top_data);
// sum after exp
// 下面的代码实现的是公式(1)
caffe_cpu_gemv<Dtype>(CblasTrans, channels, inner_num_, .,
top_data, sum_multiplier_.cpu_data(), ., scale_data);
// division
for (int j = ; j < channels; j++) {
caffe_div(inner_num_, top_data, scale_data, top_data);
//指针指向下一个数据
top_data += inner_num_;
}
}
}
该函数分为下面几个步骤:
<1> 求每个样本channel的最大值;
<2> softmax的每个输入减去其所在channel的最大值,即caffe_cpu_gemm函数的功能,该函数的原型为:
void caffe_cpu_gemm<float>(const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const float alpha, const float *A, const float *B, const float beta, float *C){
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_sgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B, ldb, beta, C, N);
}
cblas_sgemm函数作用为实现矩阵间的乘法,原型为:
//该函数实现的运算为:C = alpha*A*B + beta*C
//cblasTrans/cblasNoTrans表示对输入矩阵是否转置
//M为矩阵A,C的行数,若转置,则表示转置后的行数
//N为矩阵B、C的列数,若转置,则表示转置后的列数
//K为矩阵A的列数,或B的行数,若转置,则为转置后的列数和行数
//alpha, beta为系数
//A'cols为矩阵A的列数,与是否转置无关
//B'cols为矩阵B的列数,与是否转置无关
1 cblas_sgemm(cblasRowMajor, cblasNoTrans cblasNoTrans, M, N, K, alpha, A, A'cols, B, B'cols, beta, C, C'cols)
形象点说,caffe_cpu_gemm实现的功能为:
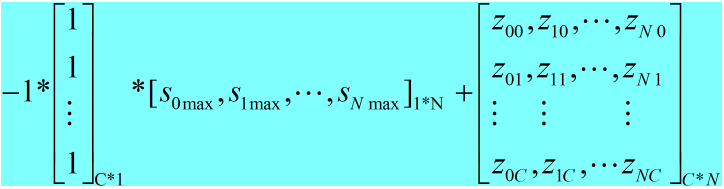
<3> 对top blob中的每个数据取e.
<4> 对每个样本的channel求和,与caffe_cpu_gemm不同的是,caffe_cpu_gemv实现的是矩阵与向量的乘法,具体的相乘过程和上面<2>中一样;
<5> 对每个样本而言,其channel的每个值除以该channel的和,也就是caffe_div完成的功能。
(4) softmax_layer.cpp中的Backward_cpu函数:
因为该函数在实际中没有用到,所以没有作过多阅读。
template <typename Dtype>
void SoftmaxLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
const Dtype* top_diff = top[]->cpu_diff();
const Dtype* top_data = top[]->cpu_data();
Dtype* bottom_diff = bottom[]->mutable_cpu_diff();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = top[]->shape(softmax_axis_);
int dim = top[]->count() / outer_num_;
caffe_copy(top[]->count(), top_diff, bottom_diff);
for (int i = ; i < outer_num_; ++i) {
// compute dot(top_diff, top_data) and subtract them from the bottom diff
for (int k = ; k < inner_num_; ++k) {
scale_data[k] = caffe_cpu_strided_dot<Dtype>(channels,
bottom_diff + i * dim + k, inner_num_,
top_data + i * dim + k, inner_num_);
}
// subtraction
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_, ,
-., sum_multiplier_.cpu_data(), scale_data, ., bottom_diff + i * dim);
}
// elementwise multiplication
caffe_mul(top[]->count(), bottom_diff, top_data, bottom_diff);
}
caffe中softmax源码阅读的更多相关文章
- go 中 select 源码阅读
深入了解下 go 中的 select 前言 1.栗子一 2.栗子二 3.栗子三 看下源码实现 1.不存在 case 2.select 中仅存在一个 case 3.select 中存在两个 case,其 ...
- vue中$watch源码阅读笔记
项目中使用了vue,一直在比较computed和$watch的使用场景,今天周末抽时间看了下vue中$watch的源码部分,也查阅了一些别人的文章,暂时把自己的笔记记录于此,供以后查阅: 实现一个简单 ...
- 【tensorflow使用笔记三】:tensorflow tutorial中的源码阅读
https://blog.csdn.net/victoriaw/article/details/61195620#t0 input_data 没用的另一种解决方法:tensorflow1.8版本及以上 ...
- caffe中batch norm源码阅读
1. batch norm 输入batch norm层的数据为[N, C, H, W], 该层计算得到均值为C个,方差为C个,输出数据为[N, C, H, W]. <1> 形象点说,均值的 ...
- Caffe源码阅读(1) 全连接层
Caffe源码阅读(1) 全连接层 发表于 2014-09-15 | 今天看全连接层的实现.主要看的是https://github.com/BVLC/caffe/blob/master/src ...
- caffe-windows中classification.cpp的源码阅读
caffe-windows中classification.cpp的源码阅读 命令格式: usage: classification string(模型描述文件net.prototxt) string( ...
- 源码阅读笔记 - 1 MSVC2015中的std::sort
大约寒假开始的时候我就已经把std::sort的源码阅读完毕并理解其中的做法了,到了寒假结尾,姑且把它写出来 这是我的第一篇源码阅读笔记,以后会发更多的,包括算法和库实现,源码会按照我自己的代码风格格 ...
- 源码阅读经验谈-slim,darknet,labelimg,caffe(1)
本文首先谈自己的源码阅读体验,然后给几个案例解读,选的例子都是比较简单.重在说明我琢磨的点线面源码阅读方法.我不是专业架构师,是从一个深度学习算法工程师的角度来谈的,不专业的地方请大家轻拍. 经常看别 ...
- SpringMVC源码阅读:Controller中参数解析
1.前言 SpringMVC是目前J2EE平台的主流Web框架,不熟悉的园友可以看SpringMVC源码阅读入门,它交代了SpringMVC的基础知识和源码阅读的技巧 本文将通过源码(基于Spring ...
随机推荐
- 判断是手机端还是PC短访问
第一种:判断是手机访问还是PC访问 <script> function browserRedirect() { var sUserAgent = navigator.userAgent.t ...
- 即时聊天APP(六) - 消息的接收以及EventBus使用
通常我们在接收消息的时候会有声音和震动的提示,因此我也加了代码达到这样的效果,这就要用到EventBus了,当然这里我也用到了自定义的广播,所以首先在Mainfests文件中加入以下代码: <r ...
- Linux 中 Xampp 的 https 安全证书配置
博客地址:http://www.moonxy.com 一.前言 HTTP 协议是不加密传输数据的,也就是用户跟你的网站之间传递数据有可能在途中被截获,破解传递的真实内容,所以使用不加密的 HTTP 的 ...
- sersync 实时同步
1.什么是实时同步 监控一个目录的变化, 当该目录触发事件(创建\删除\修改) 就执行动作, 这个动作可以是 rsync同步 ,也可以是其他. 2.为什么要实时同步 1.能解决nfs单点故障问题. ...
- Hadoop集群常用的shell命令
Hadoop集群常用的shell命令 Hadoop集群常用的shell命令 查看Hadoop版本 hadoop -version 启动HDFS start-dfs.sh 启动YARN start-ya ...
- javascript数组/对象数组的深浅拷贝问题
一.问题描述 在项目里的一个报名页面需要勾选两条信息(信息一和信息二),由于信息一和信息二所拥有的数据是一致的,所以后台只返回了一个对象数组,然后在前台设置了两个List数组来接收并加以区分.原型如下 ...
- java架构之路-(mysql底层原理)Mysql事务隔离与MVCC
上几篇博客我们大致讲了一下mysql的底层结构,什么B+tree,什么Hash需要回行啊,再就是讲了mysql优化的explain,这次我们来说说mysql的锁. mysql锁 锁从性能上分为乐观锁( ...
- python连接数据库查询
import sqlite3 as db conn = db.connect(r'D:/data/test.db') print ('Opend database successfully \n') ...
- Cisco交换机基本使用命令
作者:小啊博 QQ:762641008 转载请声明URL:https://www.cnblogs.com/-bobo/ 一.进入命令行 switch> ...
- docker容器添加对外映射端口
一般在运行容器时,我们都会通过参数 -p(使用大写的-P参数则会随机选择宿主机的一个端口进行映射)来指定宿主机和容器端口的映射,例如 docker run -it -d --name [contain ...