python简单爬虫(爬取pornhub特定关键词的items图片集)
请提前搭好梯子,如果没有梯子的话直接403。
1.所用到的包
requests: 和服务器建立连接,请求和接收数据(当然也可以用其他的包,socket之类的,不过requests是最简单好用的)
BeautifulSoup:解析从服务器接收到的数据
urllib: 将网页图片下载到本地
import requests
from bs4 import BeautifulSoup
import urllib
2.获取指定页面的html内容并解析
我这里选取"blowjob"作为关键字
key_word='blowjob'
url = 'https://www.pornhub.com/video/search?search='+key_word
html=requests.get(url) soup=BeautifulSoup(html.content,'html.parser')
3.从html中筛到全部image并进行遍历
使用find_all函数,将所有img区块中包含属性'width':"150"的存储到jpg_data列表中,并对jpg_data列表进行遍历
jpg_data=soup.find_all('img',attrs={'width':"" })
for cur in jpg_data:
pic_src=cur['src']
4.进一步筛选,并找到图片地址进行下载操作
cur['src']为当前图片地址,cur['alt']为当前图片标题,urllib.requests.urlretrieve操作将图片保存到当地,默认地址为本py文件所在目录,如有需要也可自定义保存目录。
for cur in jpg_data:
pic_src=cur['src']
if(".jpg" in pic_src):
filename=cur['alt']+'.jpg'
with open(filename,'wb') as f:
f.write(bytes(pic_src,encoding='utf-8'))
print(filename)
f.close()
完整代码:
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} url = 'https://www.pornhub.com/video/search?search=blowjob'
html=requests.get(url,headers=headers) soup=BeautifulSoup(html.content,'html.parser')
jpg_data=soup.find_all('img',attrs={'width':"" })
for cur in jpg_data:
pic_src=cur['src']
if(".jpg" in pic_src):
filename=cur['alt']+'.jpg'
with open(filename,'wb') as f:
f.write(bytes(pic_src,encoding='utf-8'))
print(filename)
f.close()
以上所作示例仅爬取了keyword关键词搜索下第一页的图片内容,如需要爬取多页,
可在url后加'&page=xx'并进行遍历
for i in range(0,10):
url = 'https://www.pornhub.com/video/search?search=blowjob'+'&page='+str(i)
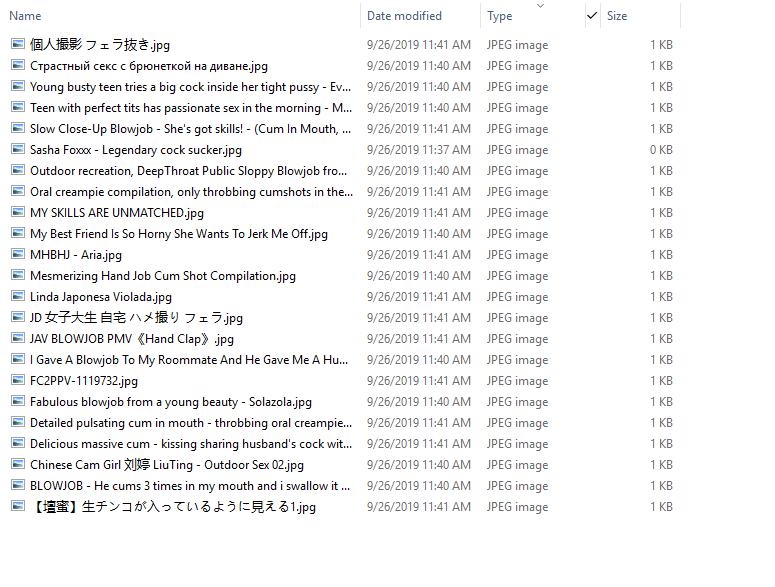
程序运行结果:

python简单爬虫(爬取pornhub特定关键词的items图片集)的更多相关文章
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- 【Python】Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
随机推荐
- Python基础学习笔记(一)python发展史与优缺点,岗位与薪资
相信有好多朋友们都是第一次了解python吧,可能大家也听过或接触过这个编程语言.那么到底什么是python呢?它在什么机缘巧合下诞生的呢?又为什么在短短十几年时间内就流行开来呢?就请大家带着疑问,让 ...
- 本地搭建持续集成(AzureDevops)
下载地址:https://visualstudio.microsoft.com/zh-hans/downloads/ 首先你需要SQL2017以上版本 ,不支持以下版本 完成下载之后进行安装(可选中文 ...
- codeblocks无法调试的相关解决思路
代码无法调试!? 难受... 现在给你提供两种常见的导致codeblocks无法调试的原因以及相应的解决方案. 原因一: 在创建工程目录时,保存路径中有中文. 重要的事情说三遍: 切记,工程目录的保存 ...
- Elasticsearch和solr之我为什么选择solr
老大:这个项目需要用到搜索引擎,小李你去学习一下. 小李:喳! 小李:以前用过的搜索引擎是solr4.7,那已经是两年前使用的了不知道现在有没有更好的解决方案了呢? 小李打开了google,百度,bi ...
- codeforces-214(Div. 2)-C. Dima and Salad+DP恰好背包花费
codeforces-214(Div. 2)-C. Dima and Salad 题意:有不同的沙拉,对应不同的颜值和卡路里,现在要求取出总颜值尽可能高的沙拉,同时要满足 解法:首先要把除法变成乘法, ...
- bzoj 2002 弹飞绵羊 lct裸题
上一次用分块过了, 今天换了一种lct(link-cut tree)的写法. 学lct之前要先学过splay. lct 简单的来说就是 一颗树, 然后每次起作用的都是其中的某一条链. 所以每次如果需要 ...
- HDU 1018 Big Number 斯特林公式
Big Number 题意:算n!的位数. 题解:对于一个数来算位数我们一般都是用while去进行计算,但是n!这个数太大了,我们做不到先算出来在去用while算位数. while(a){ cnt++ ...
- 深度递归必须知道的尾调用(Lambda)
引导语 本文从一个递归栈溢出说起,像大家介绍一下如何使用尾调用解决这个问题,以及尾调用的原理,最后还提供一个解决方案的工具类,大家可以在工作中放心用起来. 递归-发现栈溢出 现在我们有个需求,需要计算 ...
- XML的相关基础知识分享
XML和Json是两种最常用的在网络中数据传输的数据序列化格式,随着时代的变迁,XML序列化用于网络传输也逐渐被Json取代,前几天,单位系统集成开发对接接口时,发现大部分都用的WebService技 ...
- Go语言基础之文件操作
本文主要介绍了Go语言中文件读写的相关操作. 文件是什么? 计算机中的文件是存储在外部介质(通常是磁盘)上的数据集合,文件分为文本文件和二进制文件. 打开和关闭文件 os.Open()函数能够打开一个 ...