网络编程 生产者消费者模型 GiL
守护线程
所谓守护 线程,是指在程序运行的时候在后台提供一种通用服务的线程,比如垃圾回收线程就是一个很称职的守护者,并且这种线程并不属于程序中不可或缺的部分。因此,当所有的非守护线程结束时,程序也就终止了,同时会杀死进程中的所有守护线程。反过来说,只要任何非守护线程还在运行,程序就不会终止。
from threading import Thread
import time ,os,random
def task(args):
print("%s is runnning%s"%(args,os.getpid()))
time.sleep(random.randint(1,3))
print("%s is done %s"%(args,os.getpid()))
if __name__ == '__main__':
t1=Thread(target=task,args=("t1",))
t2=Thread(target=task,args=("t2",))
t1.daemon=True
t1.start()
t2.start()
print("主")
结果:
t1 is runnning48492
t2 is runnning48492
主
t2 is done 48492
t1 is done 48492
互斥锁:当一个全局的共有资源,被多个线程同时进行调用会发生到意想不到的效果。比如我在使用打印机打印文件,还没有打完,这时别人也在用打印机打印,如果不加控制,打印的东西肯定是错乱乱的。
进程互斥锁.
互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
范例一不加互斥锁的情况下:
from multiprocessing import Process,Lock#互斥锁
import os,time def task():
print("%s print 1"%os.getpid())
time.sleep(3)
print("%s print 2"%(os.getpid()))
print("%s print 3"%(os.getpid()))
if __name__ == '__main__':
p1=Process(target=task)
p2=Process(target=task)
p3=Process(target=task)
p1.start()
p2.start()
p3.start()
结果:
26248 print 1
49232 print 1
49380 print 1
26248 print 2
26248 print 3
49232 print 2
49232 print 3
49380 print 2
49380 print 3
范例二:加互斥锁的情况:
from multiprocessing import Process,Lock#互斥锁
import os,time def task(mutex):
mutex.acquire()
print("%s print 1"%os.getpid())
time.sleep(3)
print("%s print 2"%(os.getpid()))
print("%s print 3"%(os.getpid()))
mutex.release()
if __name__ == '__main__':
mutex=Lock()
p1=Process(target=task,args=(mutex,))
p2=Process(target=task,args=(mutex,))
p3=Process(target=task,args=(mutex,))
p1.start()
p2.start()
p3.start()
结果:
6664 print 1#是不是这样显得很整洁,一个进程抢到后,直到执行完别的进程才能抢到
6664 print 2
6664 print 3
52764 print 1
52764 print 2
52764 print 3
33084 print 1
33084 print 2
33084 print 3
线程互斥锁,主要是保护数据安全,可以使子线程不可修改全局变量
范例要求,开启100个进程,然后每个进程减一,最后n的结果为0.
不加互斥锁
from threading import Thread,Lock
import time
n=100
def task():
global n
temp=n
time.sleep(0.1)
n=temp-1
if __name__ == '__main__':
t_1=[]
for i in range(10):
t=Thread(target=task,args=())
t_1.append(t)
t.start()
for t in t_1:
t.join()
print(n)
结果:
99
加互斥锁:
from threading import Thread,Lock
import time
n=100
def task(mutex):
global n
with mutex: #替代mutex。acquire 和mutex.release
temp=n
time.sleep(0.1)
n=temp-1
if __name__ == '__main__':
mutex=Lock()
t_1=[]
for i in range(10):
t=Thread(target=task,args=(mutex,))
t_1.append(t)
t.start()
for t in t_1:
t.join()
print(n)
结果:
90
范例:要求设计一个旅客买票系统,多个人可以显示剩余票数,但当一个人抢票成功后,票务系统里会自动减一,假设有一张票,一个人抢到后,别人都抢不到了。
from multiprocessing import Process ,Lock
import time,os,random,json def search():
with open("db1",encoding="utf-8") as read_f:
dic=json.load(read_f)
print("%s 还剩%s票"%(os.getpid(),dic["count"]))
def get():
with open("db1",encoding="utf-8") as read_f:
dic=json.load(read_f)
if dic["count"]>0:
dic["count"]-=1
time.sleep(random.randint(1,3))
with open("db1","w",encoding="utf-8") as write_f:
json.dump(dic,write_f)
print("%s抢票成功"%os.getpid()) def task(mutex):
search()
with mutex:
get() if __name__ == '__main__':
mutex=Lock()
for i in range(10):
p=Process(target=task,args=(mutex,))
p.start()
结果:
66892 还剩1票
6808 还剩1票
46144 还剩1票
27152 还剩1票
35884 还剩1票
47308 还剩1票
15256 还剩1票
44636 还剩1票
48744 还剩1票
62000 还剩1票
66892抢票成功
信号量: 为了防止出现因多个程序同时访问一个共享资源而引发的一系列问题,我们需要一种方法,它可以通过生成并使用令牌来授权,在任一时刻只能有一个执行线程访问 代码的临界区域。临界区域是指执行数据更新的代码需要独占式地执行。而信号量就可以提供这样的一种访问机制,让一个临界区同一时间只有一个线程在访问它, 也就是说信号量是用来调协进程对共享资源的访问的。其中共享内存的使用就要用到信号量。
进程池和信号量的区别:进程池至始至终只有4个人干活,而信号量开始分成100个进程,这100个进程去抢4个锁,至始至终有100个人干活。(面试中会用到)
信号量和互斥锁的区别:互斥锁同一时间只能有一个人抢到锁,信号了在同一时间有多个人抢到所。
from multiprocessing import Process,Semaphore
import time,random,os
def task(sm):
with sm:
print("%s 上厕所"%os.getpid())
time.sleep(random.randint(1,3))
if __name__ == '__main__':
sm=Semaphore(3)
for i in range(10):
p=Process(target=task,args=(sm,))
p.start()
进程之间通信
https://www.cnblogs.com/sticker0726/p/7931573.html
可以通过文件操作来实现确定速度慢,数据不安全,用硬盘资源
必须找到一种好的机制避免这几种缺点:IPC实现进程之间通过共享内存实现进程之间通信。具体的实现方式有两种:管道和队列
队列(先进先出)是基于管道加锁实现的。(以后用队列,管道自己要亲自加锁)
from multiprocessing import Queue #进程队列
import queue #线程队列
q=Queue() #受限于内存大小
q.put()
q.get()
#堆栈(后进先出)
queue.LifoQueue
#优先级队列(按照优先级出来)
q=queue.PriorityQueue(3)
q.put((10),"ddddd")#数字越小优先级越高
q.put((8),"dd")#数字越小优先级越高
生产者和消费者模型
生产者消费者模型:一类负责造数据,一类负责处理数据,
为什么要用生产者消费者模型?
可以实现程序的解耦,生产者不直接接触消费者。而是与队列打交道,可以一直的生产,提高生产者和消费者的效率
应用:
- 爬虫
- celery
两个线程下的生产者和消费者
from multiprocessing import Queue,Process
import time,random def procducer(q):
for i in range(10):
res='包子%s'%i
print('已经造好%s'%(res))
time.sleep(random.randint(1,2))
q.put(res) def consumer(q):
while True:
res = q.get()
if res is None: #当队列中取出是NOne时,结束循环
break print('吃%s'%res)
time.sleep(random.randint(1,3)) if __name__ == '__main__':
q=Queue()
p=Process(target=procducer,args=(q,))
c=Process(target=consumer,args=(q,))
p.start()
c.start()
p.join() #保证生产者生产完
q.put(None) #把none放入队列是为了让消费者结束程序
print('主进程')
结果:
已经造好包子0
已经造好包子1
吃包子0
已经造好包子2
吃包子1
已经造好包子3
已经造好包子4
吃包子2
已经造好包子5
已经造好包子6
吃包子3
已经造好包子7
吃包子4
已经造好包子8
已经造好包子9
吃包子5
主进程
吃包子6
吃包子7
吃包子8
吃包子9
但是在现实生产中我们不会用这种方式来实现生产者消费者模型而是用rabbitMQ软件来实现这个功能 所以这部分只是了解一下 点击进入RabbitMQ
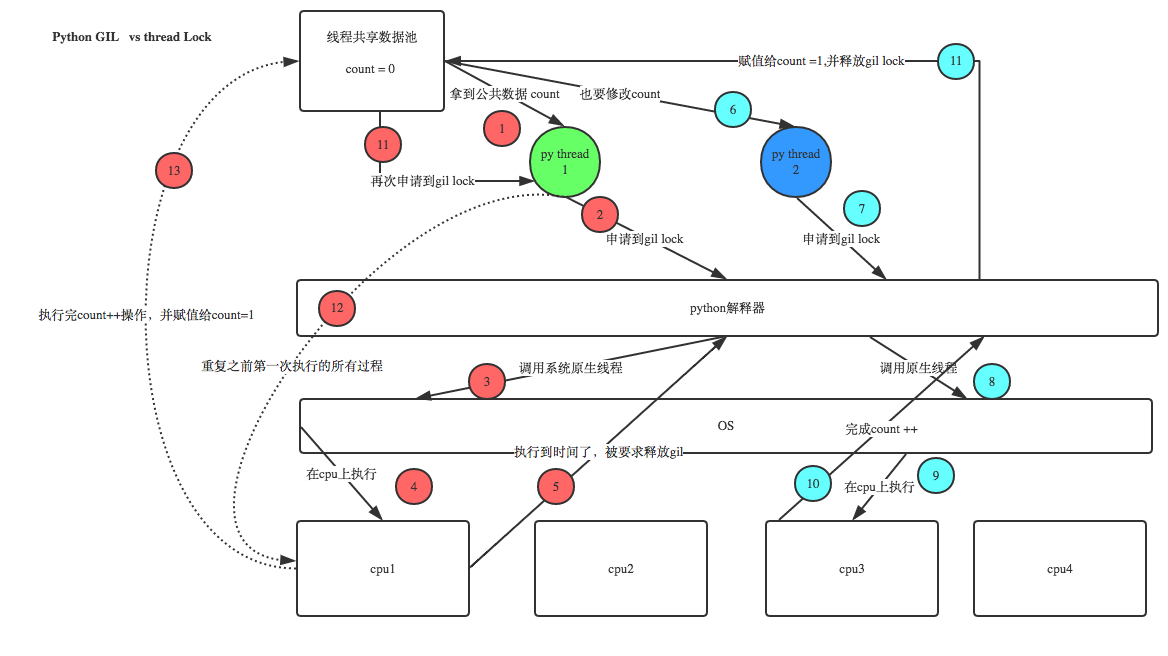
GIL锁:全局解释器锁(重点*********)
GIL锁是作用于多线程:
在Cpython解释器中,同一个进程下开启的多线程,由于有GIL的存在,同一时刻只能有一个线程被cpu执行,即使有多核也无法利用多核优势,无法并行(多核仅仅是对于计算性能的提升,对于IO阻塞不起作用)
首先需要明确的一点是GIL并不是Python的特性,python并没有GIL的锁。它是在实现Python解析器(CPython)时所引入的一个概念
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
为什么要有这把锁的存在呢? 因为Cpython解释中的垃圾回收机制(gc)不是线程安全的,如果没有了GIL锁,同一进程下的线程利用了多核实现了并行,但是在一个进程中只有一个垃圾回收线程,如果并行的线程中有相同的引用,这时候GC无法同时检测两个线程,导致无法判定该引用内存是保留还是删除导致数据不安全,GIL锁并不是保护你的数据而是保护的是垃圾回收线程的数据.

多核就是为了实现并行,既然cpython解释器同一时间只能只能有一个线程执行,那么多线程就没有就无法发挥多核优势了,这不就说明,Cpython的多线程没有用了.
但是我们要知道 计算机的任务分为两种:
- 计算密集型任务:要进行大量的计算消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数. ,比如数据分析,
- io密集型任务:我们的web开发,io的时间99%的时间都花在请求网络,从数据库上搜索数据上,即使你使用多核进行并行,也只能快那么一点点,况且多核之间的切换还需要花时间。这时候你的多核优势就无法发挥出优势了 比如socket,爬虫,web
GIL什么时候会释放呢?
1.时间片的释放,即指定时间释放。在某个线程运行到一段时间后,它就会释放该GIL锁,让其他线程运行
from threading import Thread total = 0
def add():
global total
for i in range(1000000):
total += 1 def cut():
global total
for i in range(1000000):
total -= 1 if __name__ == '__main__':
add_th = Thread(target=add)
cut_th = Thread(target=cut)
add_th.start()
cut_th.start()
add_th.join()
cut_th.join()
print(total)
结果:
850531
我们可以看到每次执行结果都是不一样的,这说明,GIL是按照时间片来释放的,并不是真正的串行,如果是真正的串行的话,最后total的结果就是0
2.遇到io就会切换,即当该线程遇到io时就会释放GIL
from threading import Thread
import time total = 0
def add():
global total
time.sleep(3)
total = total + 50
print('add_total',total) def cut():
global total
total = total + 100
print('total',total) if __name__ == '__main__':
add_th = Thread(target=add)
cut_th = Thread(target=cut)
add_th.start()
cut_th.start()
add_th.join()
cut_th.join()
print(total)
结果:
total 100
add_total 150
150
你会发现,cut先打印出结果,这说明GIL遇到io释放了,被cut获得了,就先执行cut的
结论:在python中要用多核优势开启多进程,
- 当你的代码中计算密集型任务多时,使用多进程比使用多线程效率高,多线程在这时候就是鸡肋.
- 当你的代码中io密集型任务多时,使用多线程比多进程效率高.
我们现在写的程序都是i/0密集型的因为要走网路io,所以说Cpython的多线程是有用
GIL锁和互斥锁
机智的同学可能会问到这个问题,就是既然你之前说过了,Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock?
首先我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock
网络编程 生产者消费者模型 GiL的更多相关文章
- python网络编程--进程(方法和通信),锁, 队列,生产者消费者模型
1.进程 正在进行的一个过程或者说一个任务.负责执行任务的是cpu 进程(Process: 是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础.在 ...
- 网络编程基础----并发编程 ---守护进程----同步锁 lock-----IPC机制----生产者消费者模型
1 守护进程: 主进程 创建 守护进程 辅助主进程的运行 设置进程的 daemon属性 p1.daemon=True 1 守护进程会在主进程代码执行结束后就终止: 2 守护进程内无法再开启子进程 ...
- 4、网络并发编程--僵尸进程、孤儿进程、守护进程、互斥锁、消息队列、IPC机制、生产者消费者模型、线程理论与实操
昨日内容回顾 操作系统发展史 1.穿孔卡片 CPU利用率极低 2.联机批处理系统 CPU效率有所提升 3.脱机批处理系统 CPU效率极大提升(现代计算机雏形) 多道技术(单核CPU) 串行:多个任务依 ...
- 进程,线程,GIL,Python多线程,生产者消费者模型都是什么鬼
1. 操作系统基本知识,进程,线程 CPU是计算机的核心,承担了所有的计算任务: 操作系统是计算机的管理者,它负责任务的调度.资源的分配和管理,统领整个计算机硬件:那么操作系统是如何进行任务调度的呢? ...
- 多道技术 进程 线程 协程 GIL锁 同步异步 高并发的解决方案 生产者消费者模型
本文基本内容 多道技术 进程 线程 协程 并发 多线程 多进程 线程池 进程池 GIL锁 互斥锁 网络IO 同步 异步等 实现高并发的几种方式 协程:单线程实现并发 一 多道技术 产生背景 所有程序串 ...
- python并发编程之多进程(二):互斥锁(同步锁)&进程其他属性&进程间通信(queue)&生产者消费者模型
一,互斥锁,同步锁 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的, 竞争带来的结果就是错乱,如何控制,就是加锁处理 part1:多个进程共享同一打印终 ...
- Python之路(第三十八篇) 并发编程:进程同步锁/互斥锁、信号量、事件、队列、生产者消费者模型
一.进程锁(同步锁/互斥锁) 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的, 而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理. 例 ...
- python并发编程-进程间通信-Queue队列使用-生产者消费者模型-线程理论-创建及对象属性方法-线程互斥锁-守护线程-02
目录 进程补充 进程通信前言 Queue队列的基本使用 通过Queue队列实现进程间通信(IPC机制) 生产者消费者模型 以做包子买包子为例实现当包子卖完了停止消费行为 线程 什么是线程 为什么要有线 ...
- [并发编程 - socketserver模块实现并发、[进程查看父子进程pid、僵尸进程、孤儿进程、守护进程、互斥锁、队列、生产者消费者模型]
[并发编程 - socketserver模块实现并发.[进程查看父子进程pid.僵尸进程.孤儿进程.守护进程.互斥锁.队列.生产者消费者模型] socketserver模块实现并发 基于tcp的套接字 ...
随机推荐
- MI200e电力线通讯
最近做课设,选了电力线通讯这种途径,经过百度google等一番查询,最终敲定了mi200e这块国产芯片. 课设要求就是双机通讯,互传传感器信息以及模拟一个时钟 然后淘宝买了拆机的成品,我拿回来把mcu ...
- LINQ to Entities 不识别方法“System.String get_Item(Int32)”,因此该方法无法转换为存储表达式。
1.LINQ to Entities 不识别方法“System.String get_Item(Int32)”,因此该方法无法转换为存储表达式.项目中发现linq to entities 不识别? , ...
- JavaEE XML的读写(利用JDom对XML文件进行读写)
1.有关XML的写 利用JDom2包,JDom2这个包中,至少引入org.jdom2.*;如果要进行XML文件的写出,则要进行导入org.jdom2.output.*; package com.lit ...
- while循环和递归
这个问题是在数据结构的二叉树添加结点的时候碰见 添加新结点的时候可以用while循环自身解决(这里这个方式更好) 也可以用递归解决 递归就像小明去楼顶取东西 ,从一楼开始爬,看,不是的,继续爬,每层 ...
- HTTP协议中长连接与短连接的区别
在HTTP/1.0中, 默认使用的是短连接.也就是说, 浏览器和服务器每进行一次HTTP操作, 就建立一次连接, 但任务结束就中断连接.如果客户端浏览器访问的某个HTML或其他类型的 Web 页中包含 ...
- springboot启动配置原理之二(运行run方法)
public ConfigurableApplicationContext run(String... args) { StopWatch stopWatch = new StopWatch(); s ...
- VSCode汉化
1.打开VSCode 点击箭头指示地方 在搜索框中输入chinese 然后安装中文简体 2.按住 Ctrl+shift+p 选择配置显示语言 然后会看见下面的样子 添加 "locale&q ...
- webpack不同版本导致的promise不存在问题
之前采用的axios是基于promise的,但是IE并没有内置promise,所以要提前install一个promise插件: npm install promise import Promise f ...
- photoshop打开图片显示的是索引,无法编辑解决
问题如图: 解决方法: 这是因为图像模式是索引颜色,具体为啥图片打开是索引模式我也不是很清楚(捂脸),改成RGB颜色即可修改了 图像=>模式=>RGB颜色 如图:
- 『Python』库安装
1.安装指定版本的tensorflow 虽然官网有4种安装方式,并且推荐用anaconda的方式,但是有时候我们需要指定版本的tensorflow,而pip可以做到. 比如我装的是anaconda3. ...