自己动手实现java数据结构(八) 优先级队列
1.优先级队列介绍
1.1 优先级队列
有时在调度任务时,我们会想要先处理优先级更高的任务。例如,对于同一个柜台,在决定队列中下一个服务的用户时,总是倾向于优先服务VIP用户,而让普通用户等待,即使普通的用户是先加入队列的。
优先级队列和普通的先进先出FIFO的队列类似,最大的不同在于,优先级队列中优先级最高的元素总是最先出队的,而不是遵循先进先出的顺序。
1.2 堆
优先级队列的接口要求很简单。从逻辑上来说,向量、链表或者平衡二叉搜索树等数据结构都可用于实现优先级队列。但考虑到时间和空间的效率,就必须仔细斟酌和考量了。而一种被称为堆的数据结构非常适合实现优先级队列。’
堆和二叉搜索树类似,存储的元素在逻辑上是按照层次排放的,在全局任意地方其上层元素优先级大于下层元素,这一顺序性也被称为堆序性,而其中优先级最大的元素被放在最高的层级(大顶堆)。和二叉搜索树的排序方式不同的是,堆中元素的顺序并不是完全的排序,而只是维护了一种偏序关系,被称为堆序性。在这种偏序关系下,元素之间的顺序性比较疏散,维护堆序性的代价比较低,因而在实现优先级队列时,堆的效率要高于平衡二叉搜索树。
1.3 完全二叉堆
完全二叉堆是堆的一种,其元素在逻辑上是以完全二叉树的形式存放的,但实际却是存储在向量(数组)中的。在这里,我们使用完全二叉堆来实现优先级队列。

2.优先级队列ADT接口
- /**
- * 优先级队列 ADT接口
- */
- public interface PriorityQueue <E>{
- /**
- * 插入新数据
- * @param newData 新数据
- * */
- void insert(E newData);
- /**
- * 获得优先级最大值(窥视) 不删数据
- * @return 当前优先级最大的数据
- * */
- E peekMax();
- /**
- * 获得并且删除当前优先级最大值
- * @return 被删除的 当前优先级最大的数据
- */
- E popMax();
- /**
- * 获得当前优先级队列 元素个数
- * @return 当前优先级队列 元素个数
- * */
- int size();
- /**
- * 是否为空
- * @return true 队列为空
- * false 队列不为空
- * */
- boolean isEmpty();
- }
3.完全二叉堆实现细节
3.1 基础属性
完全二叉堆内部使用之前封装好的向量作为基础。和二叉搜索树类似,用户同样可以通过传入Comparator比较器来指定堆中优先级大小比较的逻辑。
- public class CompleteBinaryHeap<E> implements PriorityQueue<E>{
- /**
- * 内部向量
- * */
- private ArrayList<E> innerArrayList;
- /**
- * 比较逻辑
- * */
- private final Comparator<E> comparator;
- /**
- * 当前堆的逻辑大小
- * */
- private int size;
- }
构造方法:
- /**
- * 无参构造函数
- * */
- public CompleteBinaryHeap() {
- this.innerArrayList = new ArrayList<>();
- this.comparator = null;
- }
- /**
- * 指定初始容量的构造函数
- * @param defaultCapacity 指定的初始容量
- * */
- public CompleteBinaryHeap(int defaultCapacity){
- this.innerArrayList = new ArrayList<>(defaultCapacity);
- this.comparator = null;
- }
- /**
- * 指定初始容量的构造函数
- * @param comparator 指定的比较器逻辑
- * */
- public CompleteBinaryHeap(Comparator<E> comparator){
- this.innerArrayList = new ArrayList<>();
- this.comparator = comparator;
- }
- /**
- * 指定初始容量和比较器的构造函数
- * @param defaultCapacity 指定的初始容量
- * @param comparator 指定的比较器逻辑
- * */
- public CompleteBinaryHeap(int defaultCapacity, Comparator<E> comparator) {
- this.innerArrayList = new ArrayList<>(defaultCapacity);
- this.comparator = comparator;
- }
- /**
- * 将指定数组 转换为一个完全二叉堆
- * @param array 指定的数组
- * */
- public CompleteBinaryHeap(E[] array){
- this.innerArrayList = new ArrayList<>(array);
- this.comparator = null;
- this.size = array.length;
- // 批量建堆
- heapify();
- }
- /**
- * 将指定数组 转换为一个完全二叉堆
- * @param array 指定的数组
- * @param comparator 指定的比较器逻辑
- * */
- public CompleteBinaryHeap(E[] array, Comparator<E> comparator){
- this.innerArrayList = new ArrayList<>(array);
- this.comparator = comparator;
- this.size = array.length;
- // 批量建堆
- heapify();
- }
3.2 辅助方法
由于完全二叉堆在逻辑上等价于一颗完全二叉树,但实际上却采用了一维的向量数据结构来存储元素。因而我们需要实现诸如getParentIndex、getLeftChildIndex、getRightChildIndex等方法来进行完全二叉树和向量表示方法的转换。
这里,定义了一些私有方法来封装常用的逻辑,用以简化代码。
- /**
- * 获得逻辑上 双亲节点下标
- * @param currentIndex 当前下标
- * */
- private int getParentIndex(int currentIndex){
- return (currentIndex - 1)/2;
- }
- /**
- * 获得逻辑上 左孩子节点下标
- * @param currentIndex 当前下标
- * */
- private int getLeftChildIndex(int currentIndex){
- return (currentIndex * 2) + 1;
- }
- /**
- * 获得逻辑上 右孩子节点下标
- * @param currentIndex 当前下标
- * */
- private int getRightChildIndex(int currentIndex){
- return (currentIndex + 1) * 2;
- }
- /**
- * 获得末尾下标
- * */
- private int getLastIndex(){
- return this.size - 1;
- }
- /**
- * 获得最后一个非叶子节点下标
- * */
- private int getLastInternal(){
- return (this.size()/2) - 1;
- }
- /**
- * 交换向量中两个元素位置
- * @param a 某一个元素的下标
- * @param b 另一个元素的下标
- * */
- private void swap(int a, int b){
- // 现暂存a、b下标元素的值
- E aData = this.innerArrayList.get(a);
- E bData = this.innerArrayList.get(b);
- // 交换位置
- this.innerArrayList.set(a,bData);
- this.innerArrayList.set(b,aData);
- }
- /**
- * 进行比较
- * */
- @SuppressWarnings("unchecked")
- private int compare(E t1, E t2){
- // 迭代器不存在
- if(this.comparator == null){
- // 依赖对象本身的 Comparable,可能会转型失败
- return ((Comparable) t1).compareTo(t2);
- }else{
- // 通过迭代器逻辑进行比较
- return this.comparator.compare(t1,t2);
- }
- }
3.3 插入和上滤
当新元素插入完全二叉堆时,我们直接将其插入向量末尾(堆底最右侧),此时新元素的优先级可能会大于其双亲元素甚至祖先元素,破坏了堆序性,因此我们需要对插入的新元素进行一次上滤操作,使完全二叉堆恢复堆序性。由于堆序性只和双亲和孩子节点相关,因此堆中新插入元素的非祖先元素的堆序性不会受到影响,上滤只是一个局部性的行为。
上滤操作
上滤的元素不断的和自己的双亲节点进行优先级的比较:
1. 如果上滤元素的优先级较大,则与双亲节点交换位置,继续向上比较。
2. 如果上滤元素的优先级较小(等于),堆序性恢复,终止比较,结束上滤操作。
3. 特别的,当上滤的元素被交换到树根节点时(向量下标第0位),此时由于上滤的元素是堆中的最大元素,终止上滤操作。
上滤操作的时间复杂度:
上滤操作时,上滤元素进行比较的次数正比于上滤元素的深度。因此,上滤操作的时间复杂度为O(logN)。
- @Override
- public void insert(E newData) {
- // 先插入新数据到 向量末尾
- this.innerArrayList.add(newData);
- // 获得向量末尾元素下标
- int lastIndex = getLastIndex();
- // 对向量末尾元素进行上滤,以恢复堆序性
- siftUp(lastIndex);
- }
- /**
- * 上滤操作
- * @param index 需要上滤的元素下标
- * */
- private void siftUp(int index){
- while(index >= 0){
- // 获得当前节点
- int parentIndex = getParentIndex(index);
- E currentData = this.innerArrayList.get(index);
- E parentData = this.innerArrayList.get(parentIndex);
- // 如果当前元素 大于 双亲元素
- if(compare(currentData,parentData) > 0){
- // 交换当前元素和双亲元素的位置
- swap(index,parentIndex);
- // 继续向上迭代
- index = parentIndex;
- }else{
- // 当前元素没有违反堆序性,直接返回
- return;
- }
- }
- }
3.4 删除和下滤
当优先级队列中极值元素出队时,需要在满足堆序性的前提下,选出新的极值元素。
我们简单的将当前向量末尾的元素放在堆顶,堆序性很有可能被破坏了。此时,我们需要对当前的堆顶元素进行一次下滤操作,使得整个完全二叉堆恢复堆序性。
下滤操作:
下滤的元素不断的和自己的左、右孩子节点进行优先级的比较:
1. 双亲节点最大,堆序性恢复,终止下滤。
2. 左孩子节点最大,当前下滤节点和自己的左孩子节点交换,继续下滤。
3. 右孩子节点最大,当前下滤节点和自己的右孩子节点交换,继续下滤。
4. 特别的,当下滤的元素抵达堆底时(成为叶子节点),堆序性已经恢复,终止下滤。
下滤操作时间复杂度:
下滤操作时,下滤元素进行比较的次数正比于下滤元素的高度。因此,下滤操作的时间复杂度为O(logN)。
- @Override
- public E popMax() {
- if(this.innerArrayList.isEmpty()){
- throw new CollectionEmptyException("当前完全二叉堆为空");
- }
- // 将当前向量末尾的元素和堆顶元素交换位置
- int lastIndex = getLastIndex();
- swap(0,lastIndex);
- // 暂存被删除的最大元素(之前的堆顶最大元素被放到了向量末尾)
- E max = this.innerArrayList.get(lastIndex);
- this.size--;
- // 对当前堆顶元素进行下滤,以恢复堆序性
- siftDown(0);
- return max;
- }
- /**
- * 下滤操作
- * @param index 需要下滤的元素下标
- * */
- private void siftDown(int index){
- int size = this.size();
- // 叶子节点不需要下滤
- int half = size >>> 1;
- while(index < half){
- int leftIndex = getLeftChildIndex(index);
- int rightIndex = getRightChildIndex(index);
- if(rightIndex < size){
- // 右孩子存在 (下标没有越界)
- E leftData = this.innerArrayList.get(leftIndex);
- E rightData = this.innerArrayList.get(rightIndex);
- E currentData = this.innerArrayList.get(index);
- // 比较左右孩子大小
- if(compare(leftData,rightData) >= 0){
- // 左孩子更大,比较双亲和左孩子
- if(compare(currentData,leftData) >= 0){
- // 双亲最大,终止下滤
- return;
- }else{
- // 三者中,左孩子更大,交换双亲和左孩子的位置
- swap(index,leftIndex);
- // 继续下滤操作
- index = leftIndex;
- }
- }else{
- // 右孩子更大,比较双亲和右孩子
- if(compare(currentData,rightData) >= 0){
- // 双亲最大,终止下滤
- return;
- }else{
- // 三者中,右孩子更大,交换双亲和右孩子的位置
- swap(index,rightIndex);
- // 继续下滤操作
- index = rightIndex;
- }
- }
- }else{
- // 右孩子不存在 (下标越界)
- E leftData = this.innerArrayList.get(leftIndex);
- E currentData = this.innerArrayList.get(index);
- // 当前节点 大于 左孩子
- if(compare(currentData,leftData) >= 0){
- // 终止下滤
- return;
- }else{
- // 交换 左孩子和双亲的位置
- swap(index,leftIndex);
- // 继续下滤操作
- index = leftIndex;
- }
- }
- }
- }
3.5 批量元素建堆
有时,我们需要将一个无序的元素集合数组转换成一个完全二叉堆,这一操作被称为批量建堆。
一个朴素的想法是:将无序集合中的元素依次插入一个空的完全二叉堆,对每一个新插入的元素进行上滤操作。使用上滤操作实现的对N个元素进行批量建堆的算法,其时间复杂度为O(n.logn),比较直观。
但还存在一种效率更加高效的批量建堆算法,是以下滤操作为基础实现的,被称为Floyd建堆算法。下滤操作可以看做是将两个较小的堆合并为一个更大堆的过程(单个元素可以被视为一个最小的堆),通过从底到高不断的下滤操作,原本无序的元素集合将通过不断的合并建立较小的堆,最终完成整个集合的建堆过程。
Floyd建堆算法的时间复杂度的证明较为复杂,其时间复杂度比起以上滤为基础的朴素算法效率高一个数量级,为O(n)。
简单的一种解释是:在完全二叉树中,低层元素的数量要远远少于高层的数量。高层元素的高度较高而深度较低;底层元素的高度较低而深度较高。由于上滤操作的时间复杂度正比于高度,对于存在大量底层元素的完全二叉堆很不友好,使得基于上滤的批量建堆算法效率较低。
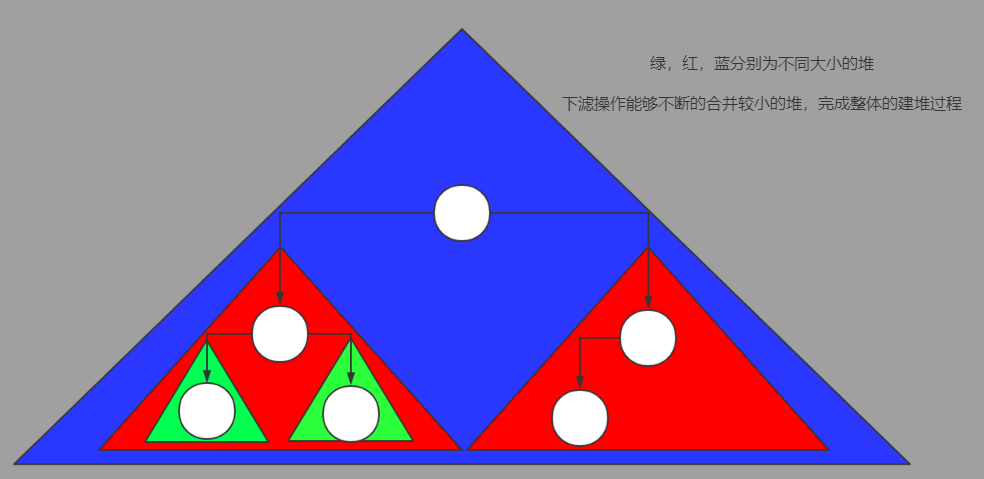
- /**
- * 批量建堆(将内部数组转换为完全二叉堆)
- * */
- private void heapify(){
- // 获取下标最大的 内部非叶子节点
- int lastInternalIndex = getLastInternal();
- // Floyd建堆算法 时间复杂度"O(n)"
- // 从lastInternalIndex开始向前遍历,对每一个元素进行下滤操作,从小到大依次合并
- for(int i=lastInternalIndex; i>=0; i--){
- siftDown(i);
- }
- }
4.堆排序
堆排序主要分为两步进行:
1. 堆排序首先将传入的数组转化为一个堆(floyd建堆算法,时间复杂度O(n))。
2. 和选择排序类似,堆排序每次都从未排序的区间中选择出一个极值元素置入已排序区域,在堆中极值元素就是堆顶元素,可以通过popMax方法(时间复杂度O(logN))获得。从数组末尾向前遍历,循环往复直至排序完成,总的时间复杂度为O(N logN)。
综上所述,堆排序的渐进时间复杂度为O(N logN)。同时由于堆排序能够在待排序数组中就地的进行排序,因此空间效率很高,空间复杂度为(O(1))。
- public static <T> void heapSort(T[] array){
- CompleteBinaryHeap<T> completeBinaryHeap = new CompleteBinaryHeap<>(array);
- for(int i=array.length-1; i>=0; i--){
- array[i] = completeBinaryHeap.popMax();
- }
- }
5.完整代码
优先级队列ADT接口:
- /**
- * 优先级队列 ADT接口
- */
- public interface PriorityQueue <E>{
- /**
- * 插入新数据
- * @param newData 新数据
- * */
- void insert(E newData);
- /**
- * 获得优先级最大值(窥视)
- * @return 当前优先级最大的数据
- * */
- E peekMax();
- /**
- * 获得并且删除当前优先级最大值
- * @return 被删除的 当前优先级最大的数据
- */
- E popMax();
- /**
- * 获得当前优先级队列 元素个数
- * @return 当前优先级队列 元素个数
- * */
- int size();
- /**
- * 是否为空
- * @return true 队列为空
- * false 队列不为空
- * */
- boolean isEmpty();
- }
完全二叉堆实现:
- /**
- * 完全二叉堆 实现优先级队列
- */
- public class CompleteBinaryHeap<E> implements PriorityQueue<E>{
- // =========================================成员属性===========================================
- /**
- * 内部向量
- * */
- private ArrayList<E> innerArrayList;
- /**
- * 比较逻辑
- * */
- private final Comparator<E> comparator;
- /**
- * 当前堆的逻辑大小
- * */
- private int size;
- // ===========================================构造函数========================================
- /**
- * 无参构造函数
- * */
- public CompleteBinaryHeap() {
- this.innerArrayList = new ArrayList<>();
- this.comparator = null;
- }
- /**
- * 指定初始容量的构造函数
- * @param defaultCapacity 指定的初始容量
- * */
- public CompleteBinaryHeap(int defaultCapacity){
- this.innerArrayList = new ArrayList<>(defaultCapacity);
- this.comparator = null;
- }
- /**
- * 指定初始容量的构造函数
- * @param comparator 指定的比较器逻辑
- * */
- public CompleteBinaryHeap(Comparator<E> comparator){
- this.innerArrayList = new ArrayList<>();
- this.comparator = comparator;
- }
- /**
- * 指定初始容量和比较器的构造函数
- * @param defaultCapacity 指定的初始容量
- * @param comparator 指定的比较器逻辑
- * */
- public CompleteBinaryHeap(int defaultCapacity, Comparator<E> comparator) {
- this.innerArrayList = new ArrayList<>(defaultCapacity);
- this.comparator = comparator;
- }
- /**
- * 将指定数组 转换为一个完全二叉堆
- * @param array 指定的数组
- * */
- public CompleteBinaryHeap(E[] array){
- this.innerArrayList = new ArrayList<>(array);
- this.comparator = null;
- this.size = array.length;
- // 批量建堆
- heapify();
- }
- /**
- * 将指定数组 转换为一个完全二叉堆
- * @param array 指定的数组
- * @param comparator 指定的比较器逻辑
- * */
- public CompleteBinaryHeap(E[] array, Comparator<E> comparator){
- this.innerArrayList = new ArrayList<>(array);
- this.comparator = comparator;
- this.size = array.length;
- // 批量建堆
- heapify();
- }
- // ==========================================外部方法===========================================
- @Override
- public void insert(E newData) {
- // 先插入新数据到 向量末尾
- this.innerArrayList.add(newData);
- // 获得向量末尾元素下标
- int lastIndex = getLastIndex();
- // 对向量末尾元素进行上滤,以恢复堆序性
- siftUp(lastIndex);
- }
- @Override
- public E peekMax() {
- // 内部数组第0位 即为堆顶max
- return this.innerArrayList.get(0);
- }
- @Override
- public E popMax() {
- if(this.innerArrayList.isEmpty()){
- throw new CollectionEmptyException("当前完全二叉堆为空");
- }
- // 将当前向量末尾的元素和堆顶元素交换位置
- int lastIndex = getLastIndex();
- swap(0,lastIndex);
- // 暂存被删除的最大元素(之前的堆顶最大元素被放到了向量末尾)
- E max = this.innerArrayList.get(lastIndex);
- this.size--;
- // 对当前堆顶元素进行下滤,以恢复堆序性
- siftDown(0);
- return max;
- }
- @Override
- public int size() {
- return this.size;
- }
- @Override
- public boolean isEmpty() {
- return this.size() == 0;
- }
- @Override
- public String toString() {
- //:::空列表
- if(this.isEmpty()){
- return "[]";
- }
- //:::列表起始使用"["
- StringBuilder s = new StringBuilder("[");
- //:::从第一个到倒数第二个元素之间
- for(int i=0; i<size-1; i++){
- //:::使用", "进行分割
- s.append(this.innerArrayList.get(i)).append(",").append(" ");
- }
- //:::最后一个元素使用"]"结尾
- s.append(this.innerArrayList.get(size-1)).append("]");
- return s.toString();
- }
- public static <T> void heapSort(T[] array){
- CompleteBinaryHeap<T> completeBinaryHeap = new CompleteBinaryHeap<>(array);
- for(int i=array.length-1; i>=0; i--){
- array[i] = completeBinaryHeap.popMax();
- }
- }
- // =========================================内部辅助函数===========================================
- /**
- * 上滤操作
- * @param index 需要上滤的元素下标
- * */
- private void siftUp(int index){
- while(index >= 0){
- // 获得当前节点
- int parentIndex = getParentIndex(index);
- E currentData = this.innerArrayList.get(index);
- E parentData = this.innerArrayList.get(parentIndex);
- // 如果当前元素 大于 双亲元素
- if(compare(currentData,parentData) > 0){
- // 交换当前元素和双亲元素的位置
- swap(index,parentIndex);
- // 继续向上迭代
- index = parentIndex;
- }else{
- // 当前元素没有违反堆序性,直接返回
- return;
- }
- }
- }
- /**
- * 下滤操作
- * @param index 需要下滤的元素下标
- * */
- private void siftDown(int index){
- int size = this.size();
- // 叶子节点不需要下滤
- int half = size >>> 1;
- while(index < half){
- int leftIndex = getLeftChildIndex(index);
- int rightIndex = getRightChildIndex(index);
- if(rightIndex < size){
- // 右孩子存在 (下标没有越界)
- E leftData = this.innerArrayList.get(leftIndex);
- E rightData = this.innerArrayList.get(rightIndex);
- E currentData = this.innerArrayList.get(index);
- // 比较左右孩子大小
- if(compare(leftData,rightData) >= 0){
- // 左孩子更大,比较双亲和左孩子
- if(compare(currentData,leftData) >= 0){
- // 双亲最大,终止下滤
- return;
- }else{
- // 三者中,左孩子更大,交换双亲和左孩子的位置
- swap(index,leftIndex);
- // 继续下滤操作
- index = leftIndex;
- }
- }else{
- // 右孩子更大,比较双亲和右孩子
- if(compare(currentData,rightData) >= 0){
- // 双亲最大,终止下滤
- return;
- }else{
- // 三者中,右孩子更大,交换双亲和右孩子的位置
- swap(index,rightIndex);
- // 继续下滤操作
- index = rightIndex;
- }
- }
- }else{
- // 右孩子不存在 (下标越界)
- E leftData = this.innerArrayList.get(leftIndex);
- E currentData = this.innerArrayList.get(index);
- // 当前节点 大于 左孩子
- if(compare(currentData,leftData) >= 0){
- // 终止下滤
- return;
- }else{
- // 交换 左孩子和双亲的位置
- swap(index,leftIndex);
- // 继续下滤操作
- index = leftIndex;
- }
- }
- }
- }
- /**
- * 批量建堆(将内部数组转换为完全二叉堆)
- * */
- private void heapify(){
- // 获取下标最大的 内部非叶子节点
- int lastInternalIndex = getLastInternal();
- // Floyd建堆算法 时间复杂度"O(n)"
- // 从lastInternalIndex开始向前遍历,对每一个元素进行下滤操作,从小到大依次合并
- for(int i=lastInternalIndex; i>=0; i--){
- siftDown(i);
- }
- }
- /**
- * 获得逻辑上 双亲节点下标
- * @param currentIndex 当前下标
- * */
- private int getParentIndex(int currentIndex){
- return (currentIndex - 1)/2;
- }
- /**
- * 获得逻辑上 左孩子节点下标
- * @param currentIndex 当前下标
- * */
- private int getLeftChildIndex(int currentIndex){
- return (currentIndex * 2) + 1;
- }
- /**
- * 获得逻辑上 右孩子节点下标
- * @param currentIndex 当前下标
- * */
- private int getRightChildIndex(int currentIndex){
- return (currentIndex + 1) * 2;
- }
- /**
- * 获得当前向量末尾下标
- * */
- private int getLastIndex(){
- return this.size - 1;
- }
- /**
- * 获得最后一个非叶子节点下标
- * */
- private int getLastInternal(){
- return (this.size()/2) - 1;
- }
- /**
- * 交换向量中两个元素位置
- * @param a 某一个元素的下标
- * @param b 另一个元素的下标
- * */
- private void swap(int a, int b){
- // 现暂存a、b下标元素的值
- E aData = this.innerArrayList.get(a);
- E bData = this.innerArrayList.get(b);
- // 交换位置
- this.innerArrayList.set(a,bData);
- this.innerArrayList.set(b,aData);
- }
- /**
- * 进行比较
- * */
- @SuppressWarnings("unchecked")
- private int compare(E t1, E t2){
- // 迭代器不存在
- if(this.comparator == null){
- // 依赖对象本身的 Comparable,可能会转型失败
- return ((Comparable) t1).compareTo(t2);
- }else{
- // 通过迭代器逻辑进行比较
- return this.comparator.compare(t1,t2);
- }
- }
- }
本系列博客的代码在我的 github上:https://github.com/1399852153/DataStructures,存在许多不足之处,请多多指教。
自己动手实现java数据结构(八) 优先级队列的更多相关文章
- java PriorityBlockingQueue 基于优先级队列,的读出操作可以阻止.
java PriorityBlockingQueue 基于优先级队列.的读出操作可以阻止. package org.rui.thread.newc; import java.util.ArrayLis ...
- 自己动手实现java数据结构(一) 向量
1.向量介绍 计算机程序主要运行在内存中,而内存在逻辑上可以被看做是连续的地址.为了充分利用这一特性,在主流的编程语言中都存在一种底层的被称为数组(Array)的数据结构与之对应.在使用数组时需要事先 ...
- java中PriorityQueue优先级队列使用方法
优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最高优先权的元素. PriorityQueue是从JDK1.5开始提供的新的数据结构接口. 如果不提供Comparator的话,优先 ...
- 《转》JAVA中PriorityQueue优先级队列使用方法
该文章转自:http://blog.csdn.net/hiphopmattshi/article/details/7334487 优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最 ...
- 【转】java中PriorityQueue优先级队列使用方法
优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最高优先权的元素. PriorityQueue是从JDK1.5开始提供的新的数据结构接口. 如果不提供Comparator的话,优先 ...
- java 中PriorityQueue优先级队列使用方法
1.前言 优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最高优先权的元素. PriorityQueue是从JDK1.5开始提供的新的数据结构接口. 如果想实现按照自己的意愿进行优 ...
- 用Python实现数据结构之优先级队列
优先级队列 如果我们给每个元素都分配一个数字来标记其优先级,不妨设较小的数字具有较高的优先级,这样我们就可以在一个集合中访问优先级最高的元素并对其进行查找和删除操作了.这样,我们就引入了优先级队列 这 ...
- 自己动手实现java数据结构(四)双端队列
1.双端队列介绍 在介绍双端队列之前,我们需要先介绍队列的概念.和栈相对应,在许多算法设计中,需要一种"先进先出(First Input First Output)"的数据结构,因 ...
- 自己动手实现java数据结构(二) 链表
1.链表介绍 前面我们已经介绍了向量,向量是基于数组进行数据存储的线性表.今天,要介绍的是线性表的另一种实现方式---链表. 链表和向量都是线性表,从使用者的角度上依然被视为一个线性的列表结构.但是, ...
随机推荐
- c++沉思录 学习笔记 第五章 代理类
Vehicle 一个车辆的虚基类 class Vehicle {public: virtual double weight()const = 0; virtual void start() = 0; ...
- c++ 计算cpu占用率
计算CPU占用率就是获取系统总的内核时间 用户时间及空闲时间 其中空闲时间就是内核空转 所以内核时间包含空闲时间 然后计算 运行时间 = 内核时间 加 用户时间 减去 空闲时间 间隔时间 = 内核时 ...
- AX_Currency
Currency::curAmount(9.23,"HKD"); Currency::curAmount2CurAmount(9.23,"RMB"," ...
- canvasJS
- tensorflow o. 到 tensorflow 1. 部分改变
一下内容为笔者实际应用中遇到的问题,可能(必须)不全,后面会持续更新. (1) tf.nn.run_cell 改为 tf.contrib.rnn (2) tf.reduce_mean 改为 ...
- Linux环境下java开发环境搭建一 JDK搭建
第一步:下载jdk压缩文件 第二步:上传到家目录下的soft目录下,可以采用winscp,此处下载的是.tar.gz文件 第三步:解压压缩文件,并在/usr/local目录下创建一个jdk7的目录,并 ...
- Python从入门到精通之First!
Python的种类 Cpython Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上. Jy ...
- Linux学习---条件预处理的应用
预处理的使用: ⑴包含头文件 #include ⑵宏定义 #define 替换,不进行语法检查 ①常量宏定义:#define 宏名 (宏体) (加括号为防止不进行语法检查而出现的错误) eg:# ...
- qhfl-6 购物车
购物车中心 用户点击价格策略加入购物车,个人中心可以查看自己所有购物车中数据 在购物车中可以删除课程,还可以更新购物车中课程的价格策略 所以接口应该有四种请求方式, get,post,patch,de ...
- Makefile入门
相信大家对makefile都不陌生,在Linux下编写程序基本都离不开makefile的编写,我们都知道多个.c文件经过编译器编译后得到多个.o文件,这些文件是互相独立的,但最终我们要得到一个可正常运 ...