队列&广搜
搜索里有深搜,又有广搜,而广搜的基础就是队列。
队列是一种特殊的线性表,只能在一段插入,另一端输出。输出的那一端叫做队头,输入的那一端叫队尾。是一种先进先出(FIFO)的数据结构。
正经的队列:
头文件:#include <queue>
入队:q.push(要入队的数)
返回第一个元素:q.front( )
从队列中移除第一个元素:q.pop( )
查看队列中元素的个数:q.size( )
返回队列的最后一个元素:q.back( )
用数组模拟的队列:
可以定义数组q[100001](可大可小)
队头为head,队尾为tail
注意:
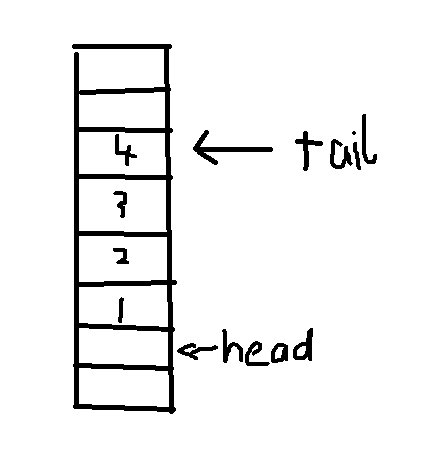
如图,head指向第一个实际元素的前一个位置,tail指向最后一个实际元素的位置
无论数组多大,总会有个界限,入队过多会溢出,而前面出队时会有空出来的位置,所以我们可以把一个数组循环使用。
代码如下:
void rudui(int x)
{tail++:
if(tail==n+)
tail=;
if(tail==head)//入队要判满
{printf("操作无效,队列已满");
return;}
q[tail]=x;
}
说了些基本定义,再来说说应用。
队列的应用和广搜是分不开的。
那什么是广搜?
就是一层一层的搜索,从第0层开始,每层都枚举出可能的情况,直到找到符合要求的情况为止
如图:

放个模板
这里是用数组模拟队列
int bfs()
{ 队列初始化;
head=;tail=;//记住tail指向最后一个实际元素!!
do{
head++;//head指向带扩展节点
for(int i=;i<=max;i++)//节点如何扩展
{
if(子节点符合条件)
{tail++;该节点入队;
if(与原来有重复)
{ 删除该节点;tail--;
}
else
{if(找到目标)输出并退出;
}
}
}
}while(head<tail);//队列不空就继续搜索
}
举个栗子:
例题1:
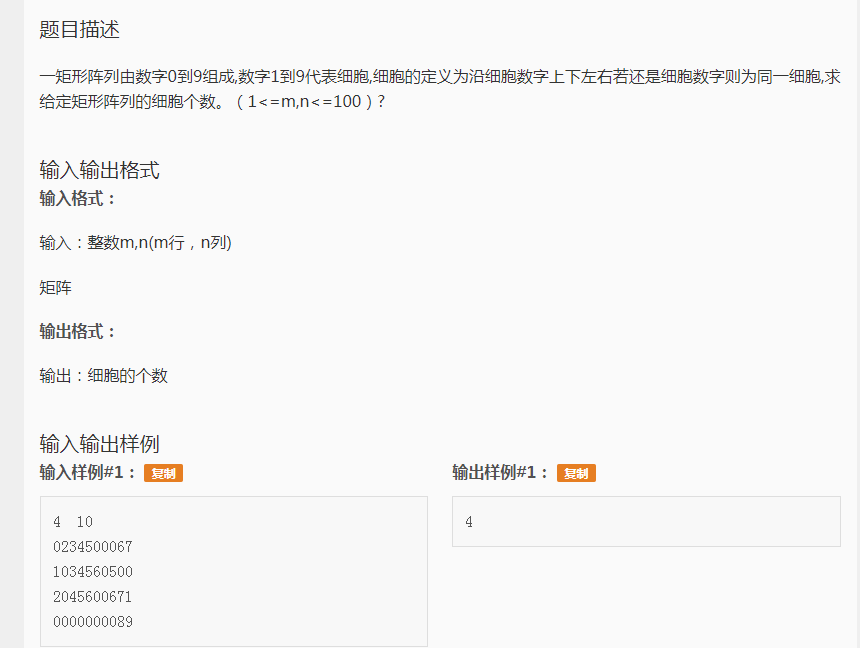
这个题就是广搜的典型例题。
在这道题中,所有非0数都可以看做是1,因为它们的值不影响判断。这样就可以用一个bool数组a[1001][1001]来表示这个矩阵
通过样例可以知道,矩阵的输入是没有空格的,所以要用字符型输入(这是个坑)
既然我们决定用bool型数组(只有0,1),而且还有前面那个坑。为了防止毒瘤的非法读入,我们先将整个a数组置为1。我们输入时判断一下,如果输入的字符是0,就把对应位置置为0。
然后就是搜索了。
先在main里找到1,再进行搜索,会省时间。
搜索时,记录下当前的i,j。从i,j的上下左右搜索,如果是1,就将这个位置的坐标放入队中,并将这个位置置为0,防止重复
入队的同时将队头出队,一直到队空为止,完成一次搜索,计数器加1.
代码如下:
#include<iostream>
#include<cstdio>
using namespace std;
int n,m,num,dx[]={-,,,},dy[]={,,,-};//预处理出4个方向
bool a[][];
void justdoit(int p,int q)
{ a[p][q]=;
int x,y,head,tail,i;
int h[][];
num++;
h[][]=p;h[][]=q;//h[head][1]为横坐标,h[head][2]为纵坐标
head=;tail=;
do{
head++;
for(int i=;i<=;i++)
{x=h[head][]+dx[i];y=h[head][]+dy[i];
if((a[x][y])&&(x>=)&&(y>=)&&(x<m)&&(y<n))
{tail++;
h[tail][]=x;//坐标入队
h[tail][]=y;
a[x][y]=;
}
}
}while(head<tail);
}//其实就是套模板
int main()
{char c[];
scanf("%d %d",&m,&n);
for(int i=;i<=m-;i++)
{for(int j=;j<=n-;j++)
a[i][j]=;
}
for(int i=;i<m;i++)
{
scanf("%s",c);
for(int j=;j<n;j++)
{if(c[j]==''){a[i][j]=;
}
}
}
for(int i=;i<m;i++)
{for(int j=;j<n;j++)
if(a[i][j])justdoit(i,j);
}
printf("%d",num);
}
例题2:

这个题显然没有什么数学规律可以解方程什么的,所以我们好像只能搜索了。
从a,b两点搜索到1会造成一些时间的浪费,因为(1,1)在棋盘的一角,而a和b在棋盘中间,会造成在左下角方向的浪费
如图:
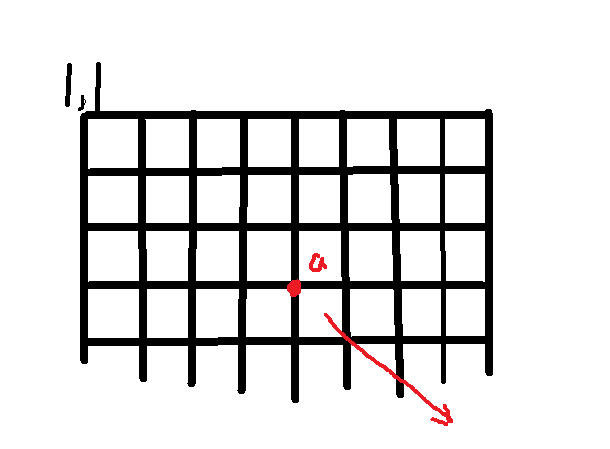
如果从a搜索到(1,1),会造成在箭头方向上的浪费,所以我们从(1,1)开始搜,搜到a停止
这里有两个点,参照对a的搜索方式,我们可以a,b一起搜。
先用p[101][101]数组将棋盘表示出来,所有的p[i][j]都初始化为-1,表示都没有到过
同时用dl[100001][4]数组来模仿队列,记录当前的所有到过点的坐标
其中dl[i][1]为横坐标,dl[i][2]为纵坐标,dl[i][3]为到达当前坐标所用最小步数
边界:点的横纵坐标大于0
一旦到达a和b,输出并结束程序
代码如下:
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
int ax,ay,bx,by,dx[]={-,-,-,-,,,,,-,-,,},dy[]={-,,-,,-,,-,,-,,-,};
int numa,numb;
int main()
{
scanf("%d%d%d%d",&ax,&ay,&bx,&by);
int dl[][]={};
int p[][];
dl[][]=;dl[][]=;dl[][]=;//这里从(1,1)开始跳,跳到a,b两点坐标结束(???)
memset(p,0xff,sizeof(p));//dl[i][3]记录跳到(dl[i][1],dl[i][2]的步数)
p[][]=;//用p数组表示棋盘上的每个点,到过就+1,初始为-1(方便统计只到过一次的点)
int head=,tail=;
while(head<=tail)
{
for(int i=;i<=;i++)
{int x=dl[head][]+dx[i],y=dl[head][]+dy[i];//12个方向
if(x>&&y>)//若从(1,1)开始跳,则不能超出棋盘
{
if(p[x][y]==-)//之前没有到过这个点
{p[x][y]=dl[head][]+;//到达点(x,y)所需要的步数p为跳到上一个(x,y)的步数再加一
tail++;
getchar();
dl[tail][]=x;//记录坐标
dl[tail][]=y;
dl[tail][]=p[x][y];//记录跳到(x,y)的步数
}
if(p[ax][ay]>&&p[bx][by]>)//肯定不可能0步就跳到
{printf("%d\n%d\n",p[ax][ay],p[bx][by]);
return ;
}
}
} head++;
}
}
队列&广搜的更多相关文章
- HDU-1226-超级密码-队列+广搜+大数取模
Ignatius花了一个星期的时间终于找到了传说中的宝藏,宝藏被放在一个房间里,房间的门用密码锁起来了,在门旁边的墙上有一些关于密码的提示信息: 密码是一个C进制的数,并且只能由给定的M个数字构成,同 ...
- SPOJ-Grid ,水广搜easy bfs
SERGRID - Grid 一个水广搜我竟然纠结了这么久,三天不练手生啊,况且我快三个月没练过搜索了... 题意:n*m的方格,每个格子有一个数,意味着在此方格上你可以上下左右移动s[x][y]个格 ...
- hdu 1253 胜利大逃亡(广搜,队列,三维,简单)
题目 原来光搜是用队列的,深搜才用栈,我好白痴啊,居然搞错了 三维的基础的广搜题 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #in ...
- VIJOS-P1340 拯救ice-cream(广搜+优先级队列)
题意:从s到m的最短时间.(“o"不能走,‘#’走一个花两个单位时间,‘.'走一个花一个单位时间) 思路:广搜和优先队列. #include <stdio.h> #include ...
- poj 3278:Catch That Cow(简单一维广搜)
Catch That Cow Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 45648 Accepted: 14310 ...
- 双向广搜 POJ 3126 Prime Path
POJ 3126 Prime Path Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 16204 Accepted ...
- hdu 1242:Rescue(BFS广搜 + 优先队列)
Rescue Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Total Submis ...
- HDU 1253 (简单三维广搜) 胜利大逃亡
奇葩!这么简单的广搜居然爆内存了,而且一直爆,一直爆,Orz 而且我也优化过了的啊,尼玛还是一直爆! 先把代码贴上睡觉去了,明天再来弄 //#define LOCAL #include <ios ...
- hdu 1175 连连看 (广搜,注意解题思维,简单)
题目 解析见代码 #define _CRT_SECURE_NO_WARNINGS //这是非一般的最短路,所以广搜到的最短的路不一定是所要的路线 //所以应该把所有的路径都搜索出来,找到最短的转折数, ...
随机推荐
- [spring源码] 小白级别的源码解析(一)
一直都在用spring,但是每次一遇到spring深入的问题,就是比较懵的状态.最近花了段时间学习了一下spring源码. 1,spring版本介绍 虽然工作中,一直在用到spring,可能有时候,并 ...
- 在Eclipse下搭建Hibernate框架(加载hibernate工具插件,离线)
下载hibernate工具包完成之后,对其进行解压可以得到众多文件夹,其中就有一个jbosstools-hibernate开头的文件夹,进入其中可以得到features和plugins两个文件夹,在E ...
- SQL-45 将titles_test表名修改为titles_2017。
题目描述 将titles_test表名修改为titles_2017.CREATE TABLE IF NOT EXISTS titles_test (id int(11) not null primar ...
- [Spring Boot]什么是Spring Boot
<Spring Boot是什么> Spring Boot不是一个框架 是一种用来轻松创建具有最小或零配置的独立应用程序的方式 用来开发基于Spring的应用,但只需非常少的配置. 它提供了 ...
- Windows10 bypassUAC绕过用户账户控制
使用这个github上的项目: https://github.com/L3cr0f/DccwBypassUAC 可以自行编译 全程UAC不介入,没反应. 测试: 权限提升真实有效
- Centos yum 命令行 安装KDE Desktop
1:修改yum源为本地源 (见相关随笔:centos 配置本地yum源) 2:# yum groupinstall "X Window System" ← 安装基本的X系统组件# ...
- flask中自定义过滤器
第一种方法: 1,第一步:自定义过滤器函数 # 自定义一个函数,将list里面的数据进行排序 def list_sort(list) return list.sort() 2.第二步:注册过滤器 第一 ...
- CSS精简工具——除去多余的css样式
有时候开发网页中在改版之后,存在很多无意义的样式,对于后期的管理和维护很不友好. 如果手动去删除,很可能会导致出现更混乱的问题. 最近找到一个Chrome插件,CSS remove and combi ...
- OpenCV3 SVM ANN Adaboost KNN 随机森林等机器学习方法对OCR分类
转摘自http://www.cnblogs.com/denny402/p/5032839.html opencv3中的ml类与opencv2中发生了变化,下面列举opencv3的机器学习类方法实例: ...
- OneStopEnglish corpus: A new corpus for automatic readability assessment and text simplification-paper
这篇论文的related work非常详尽地介绍了各种readability的语料 abstract这个paper描述了onestopengilish这个三个level的文本语料的收集和整理,阐述了再 ...