ELK之使用filebeat收集系统数据及其他程序并生成可视化图表
当您要面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,请告别 SSH 吧。Filebeat 将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
1,安装filebeat
rpm -ivh /nas/nas/softs/elk/6.5.4/filebeat-6.5.4-x86_64.rpm
查看模块
[root@prd-elk-kafka-01 ~]# filebeat modules list
Enabled:
kafka
system Disabled:
apache2
auditd
elasticsearch
haproxy
icinga
iis
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
suricata
traefik
如需要启用某个模块使用命令
filebeat modules enable system
修改配置文件把filebeat输出至elasticsearch和kibana
/etc/filebeat/filebeat.yml
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
output.elasticsearch:
hosts: ["172.16.90.24:9200"]
# username: "admin"
# password: "admin"
setup.kibana:
host: "172.16.90.24:5601"
processors:
- add_host_metadata:
- add_cloud_metadata:
# - drop_fields:
# fields: ["beat", "input", "source", "offset", "prospector","host"]
模块路径为/etc/filebeat/modules.d/
2,设置系统模块system
启用系统模块
/etc/filebeat/filebeat.yml
编辑系统模块配置文件,这里使用默认
/etc/filebeat/modules.d/system.yml
- module: system
# Syslog
syslog:
enabled: true # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths: # Convert the timestamp to UTC. Requires Elasticsearch >= 6.1.
#var.convert_timezone: false # Authorization logs
auth:
enabled: true # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths: # Convert the timestamp to UTC. Requires Elasticsearch >= 6.1.
#var.convert_timezone: false
系统模块每一台主机都需要安装,启用后查看kibana
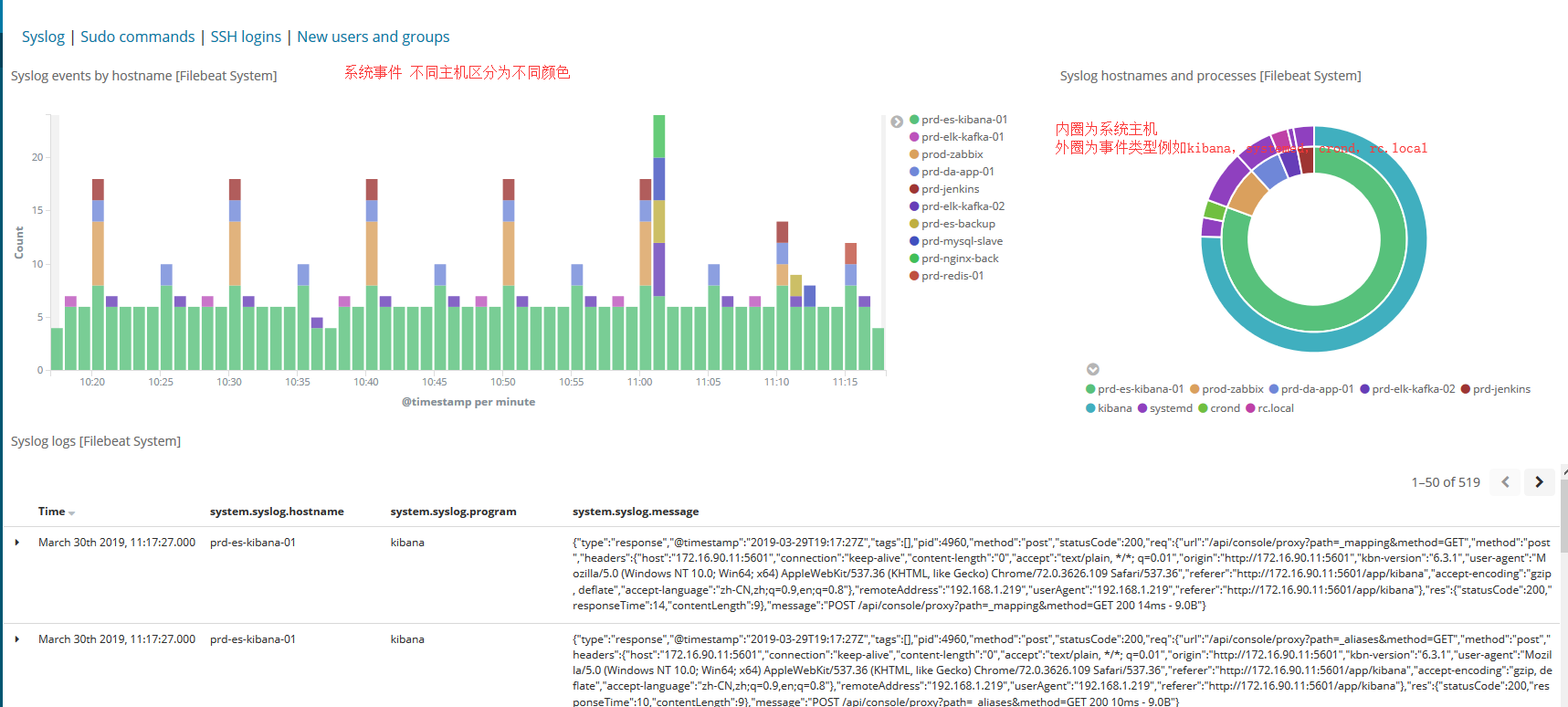
3,设置nginx模块
启动nginx模块
filebeat modules enable nginx
修改配置文档
/etc/filebeat/modules.d/nginx.yml
输入access日志及error日志路径
- module: nginx
# Access logs
access:
enabled: true # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- "/opt/log/wwwaccess.log"
- "/opt/log/workaccess.log"
- "/opt/log/datavaccess.log" # Error logs
error:
enabled: true # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- "/opt/log/wwwerror.log"
- "/opt/log/workerror.log"
- "/opt/log/dataverror.log"
kibana查看


要显示客户端城市及浏览器信息需要安装elasticsearch插件
bin/elasticsearch-plugin install ingest-geoip
bin/elasticsearch-plugin install ingest-user-agent
4,设置redis模块
启用redis模块
filebeat modules enable redis
修改redis配置文件
/etc/filebeat/modules.d/redis.yml
- module: redis
# Main logs
log:
enabled: true # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/nas/nas/logs/redis/redis-server.log"] # Slow logs, retrieved via the Redis API (SLOWLOG)
slowlog:
enabled: true # The Redis hosts to connect to.
var.hosts: ["localhost:6379"] # Optional, the password to use when connecting to Redis.
var.password: "password"
kibana页面查看


5,设置kafka模块
启用kafka模块
filebeat modules enable kafka
修改配置文件
/etc/filebeat/modules.d/kafka.yml
- module: kafka
# All logs
log:
enabled: true # Set custom paths for Kafka. If left empty,
# Filebeat will look under /opt.
#var.kafka_home: # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- "/usr/local/kafka/logs/controller.log*"
- "/usr/local/kafka/logs/server.log*"
- "/usr/local/kafka/logs/state-change.log*"
- "/usr/local/kafka/logs/kafka-*.log*"
# Convert the timestamp to UTC. Requires Elasticsearch >= 6.1.
#var.convert_timezone: false
kibana查看

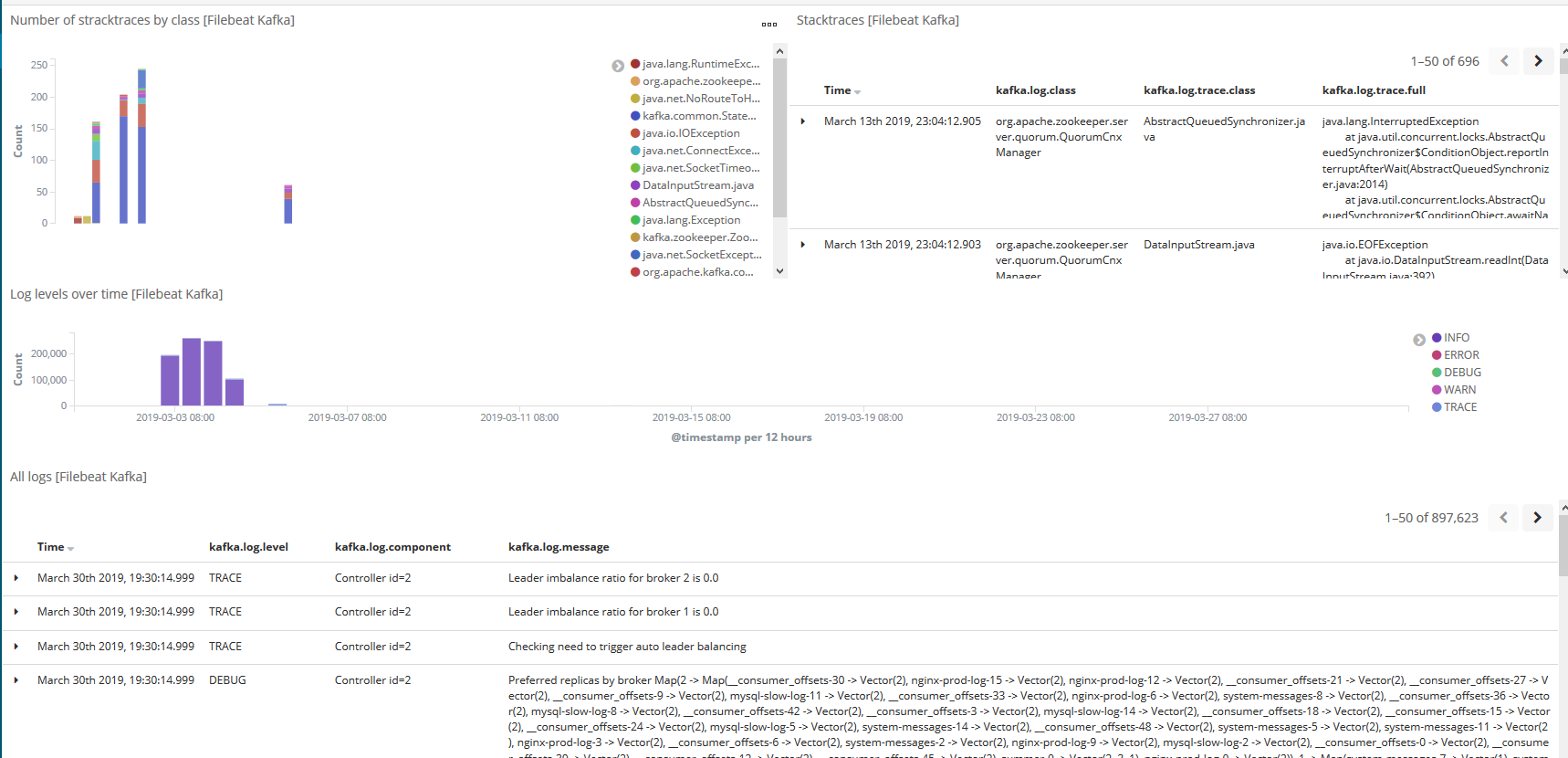
6,设置MySQL模块
开启mysql模块
filebeat modules enable mysql
修改配置文件
/etc/filebeat/modules.d/mysql.yml
输入日志及慢查询日志文件路径
- module: mysql
# Error logs
error:
enabled: true # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/mysql3306.log"] # Slow logs
slowlog:
enabled: true # Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/nas/nas/logs/mysql/slow3306.log"]
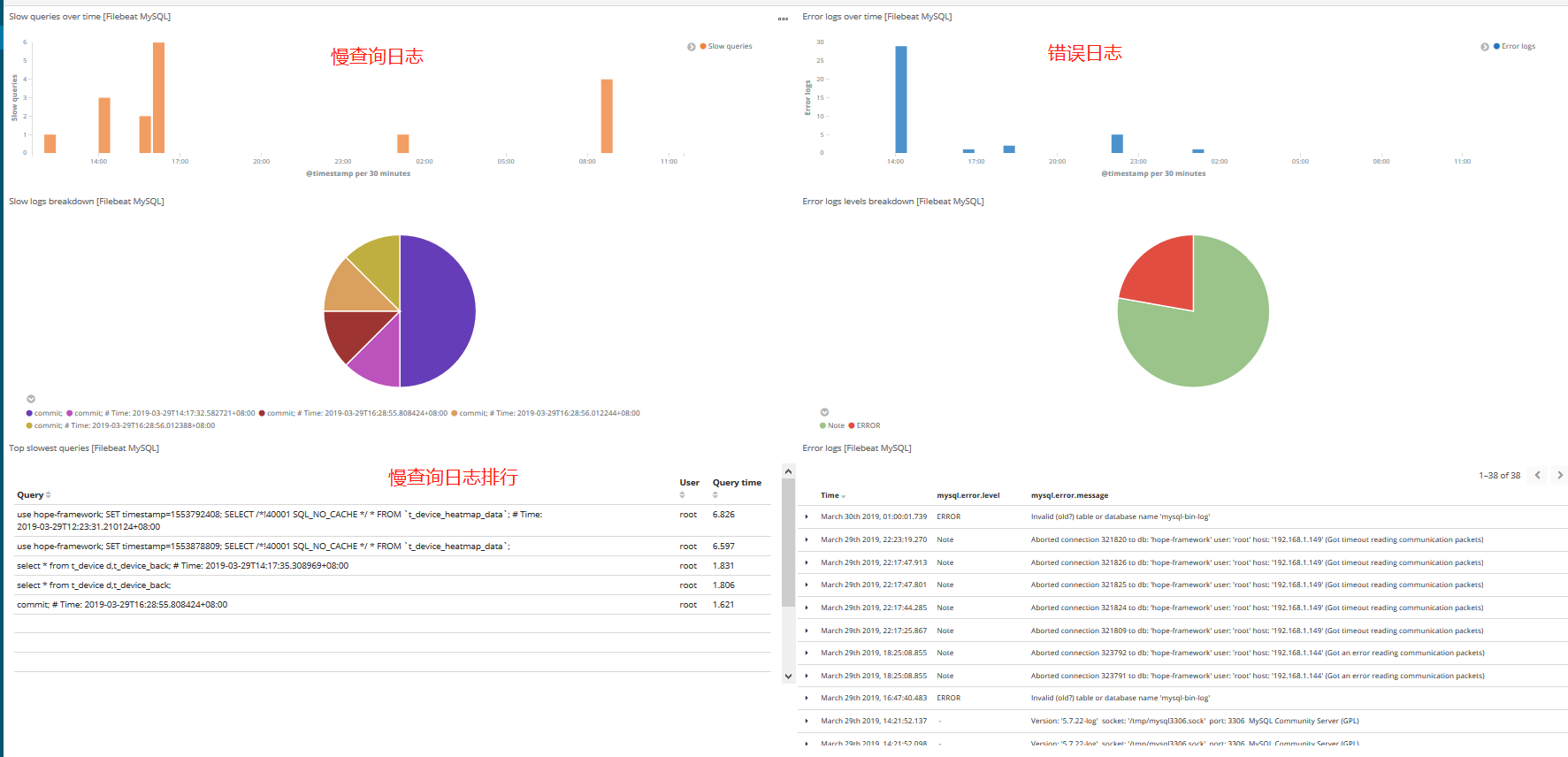
kibana查看
更多模块查看官方文档https://www.elastic.co/guide/en/beats/filebeat/6.5/filebeat-modules.html
ELK之使用filebeat收集系统数据及其他程序并生成可视化图表的更多相关文章
- ELK之使用metricbeat收集系统数据及其他程序并生成可视化图表
将 Metricbeat 部署到您所有的 Linux.Windows 和 Mac 主机,并将它连接到 Elasticsearch 就大功告成啦:您可以获取系统级的 CPU 使用率.内存.文件系统.磁盘 ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- Kubernetes部署ELK并使用Filebeat收集容器日志
本文的试验环境为CentOS 7.3,Kubernetes集群为1.11.2,安装步骤参见kubeadm安装kubernetes V1.11.1 集群 1. 环境准备 Elasticsearch运行时 ...
- ELK之使用filebeat收集java运行日志
安装filebeat修改配置文件/etc/filebeat/filebeat.yml filebeat.prospectors: - type: log enabled: true #日志路径 pat ...
- filebeat收集日志到elsticsearch中并使用ingest node的pipeline处理
filebeat收集日志到elsticsearch中 一.需求 二.实现 1.filebeat.yml 配置文件的编写 2.创建自定义的索引模板 3.加密连接到es用户的密码 1.创建keystore ...
- nGrinder对监控机器收集自定义数据及源码分析
转载:https://blog.csdn.net/neven7/article/details/50782451 0.背景 性能测试工具nGrinder支持在无需修改源码的情况下,对目标服务器收集自定 ...
- [Xcode 实际操作]七、文件与数据-(1)获取程序沙箱结构中常用的几个目录
目录:[Swift]Xcode实际操作 本文将演示如何获取程序沙箱结构中,常见的几个目录. 在项目导航区,打开视图控制器的代码文件[ViewController.swift] import UIKit ...
- 使用VS2017 编写Linux系统上的Opencv程序
背景 之前写图像算法的程序都是在window10下使用VS编写,VS这个IDE结合“ImageWatch.vsix“插件,用于调试opencv相关的图像算法程序十分方便.后因项目需要,需将相关程序移植 ...
- Kafka+Zookeeper+Filebeat+ELK 搭建日志收集系统
ELK ELK目前主流的一种日志系统,过多的就不多介绍了 Filebeat收集日志,将收集的日志输出到kafka,避免网络问题丢失信息 kafka接收到日志消息后直接消费到Logstash Logst ...
随机推荐
- 【PMP】组织结构类型
1.简单型 描述:人员并肩工作,所有者/经营者直接做出主要决定并监督执行. PM角色:兼职(协调员) PM权限:极少(无) 项目管理人员:极少(无) 资源可用性:极少(无) 项目预算管理人:负责人 2 ...
- Effective Java 第三版——67. 明智谨慎地进行优化
Tips 书中的源代码地址:https://github.com/jbloch/effective-java-3e-source-code 注意,书中的有些代码里方法是基于Java 9 API中的,所 ...
- Centos7.4别名设置提高工作效率
一.打开 .bashrc文件 1.位置:~(cd ~)目录下 2.cat .bashrc 原文件内容如下: # .bashrc # User specific aliases and function ...
- Atitit uke公司简介与基本制度建设草案v11 r66 .docx
Atitit uke公司简介与基本制度建设草案v11 r66 .docx Uke org prj Author撰写人: 作者:: 绰号:老哇的爪子claw of Eagle 偶像破坏者Iconocl ...
- webview调起浏览器
调起浏览器 url = "intent://" + url +"#Intent;scheme=http;action=android.intent.action.VIEW ...
- 【Java】的四种引用的区别
强引用:如果一个对象具有强引用,它就不会被垃圾回收器回收.即使当前内存空间不足,JVM 也不会回收它,而是抛出 OutOfMemoryError 错误,使程序异常终止.如果想中断强引用和某个对象之间的 ...
- kernel事件通知userspace
https://stackoverflow.com/questions/31646466/how-to-send-signal-from-kernel-to-user-space
- Spring+SpringMVC重复加载配置文件问题
sping+springmvc的框架中,IOC容器的加载过程 http://my.oschina.net/xianggao/blog/596476 基本上是先加载ContextLoaderListen ...
- python -- ajax数组传递和后台接收
phper转pythoner 在当初使用php做网站开发的时候,前端ajax传递数据的时候,就是直接将一个数组传递过去,后台用$_POST['key']接收即可,没有考虑那么细,想来这不都是理所当然的 ...
- iOS 之地图坐标体系和转换
一.坐标体系 首先我们要明白,开发者能接触到哪些坐标体系呢? 第一种分类: 1. GPS,WGS-84,原始坐标体系.一般用国际标准的GPS记录仪记录下来的坐标, 都是GPS的坐标.很可惜,在中国,任 ...