tensorflow使用多个gpu训练
关于多gpu训练,tf并没有给太多的学习资料,比较官方的只有:tensorflow-models/tutorials/image/cifar10/cifar10_multi_gpu_train.py
但代码比较简单,只是针对cifar做了数据并行的多gpu训练,利用到的layer、activation类型不多,针对更复杂网络的情况,并没有给出指导。自己摸了不少坑之后,算是基本走通了,在此记录下
一、思路
单GPU时,思路很简单,前向、后向都在一个GPU上进行,模型参数更新时只涉及一个GPU。多GPU时,有模型并行和数据并行两种情况。模型并行指模型的不同部分在不同GPU上运行。数据并行指不同GPU上训练数据不同,但模型是同一个(相当于是同一个模型的副本)。在此只考虑数据并行,这个在tf的实现思路如下:
模型参数保存在一个指定gpu/cpu上,模型参数的副本在不同gpu上,每次训练,提供batch_size*gpu_num数据,并等量拆分成多个batch,分别送入不同GPU。前向在不同gpu上进行,模型参数更新时,将多个GPU后向计算得到的梯度数据进行平均,并在指定GPU/CPU上利用梯度数据更新模型参数。
假设有两个GPU(gpu0,gpu1),模型参数实际存放在cpu0上,实际一次训练过程如下图所示:
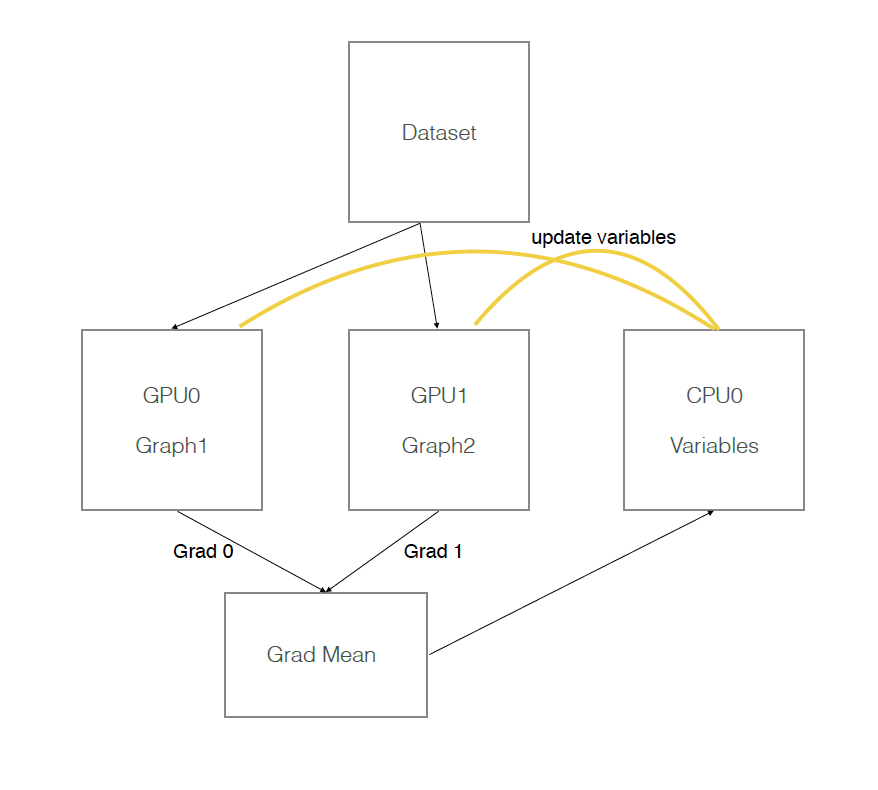
二、tf代码实现
大部分需要修改的部分集中在构建计算图上,假设在构建计算图时,数据部分基于tensorflow1.4版本的dataset类,那么代码要按照如下方式编写:
next_img, next_label = iterator.get_next()
image_splits = tf.split(next_img, num_gpus)
label_splits = tf.split(next_label, num_gpus)
tower_grads = []
tower_loss = []
counter = 0
for d in self.gpu_id:
with tf.device('/gpu:%s' % d):
with tf.name_scope('%s_%s' % ('tower', d)):
cross_entropy = build_train_model(image_splits[counter], label_splits[counter], for_training=True)
counter += 1
with tf.variable_scope("loss"):
grads = opt.compute_gradients(cross_entropy)
tower_grads.append(grads)
tower_loss.append(cross_entropy)
tf.get_variable_scope().reuse_variables() mean_loss = tf.stack(axis=0, values=tower_loss)
mean_loss = tf.reduce_mean(mean_loss, 0)
mean_grads = util.average_gradients(tower_grads)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = opt.apply_gradients(mean_grads, global_step=global_step)
第1行得到image和对应label
第2-3行对image和label根据使用的gpu数量做平均拆分(默认两个gpu运算能力相同,如果gpu运算能力不同,可以自己设定拆分策略)
第 4-5行,保存来自不同GPU计算出的梯度、loss列表
第7-16行,开始在每个GPU上创建计算图,最重要的是14-16三行,14,15把当前GPU计算出的梯度、loss值append到列表后,以便后续计算平均值。16行表示同名变量将会复用,这个是什么意思呢?假设现在gpu0上创建了两个变量var0,var1,那么在gpu1上创建计算图的时候,如果还有var0和var1,则默认复用之前gpu0上的创建的那两个值。
第18-20行计算不同GPU获取的grad、loss的平均值,其中第20行使用了cifar10_multi_gpu_train.py中的函数。
第23行利用梯度平均值更新参数。
注意:上述代码中,所有变量(vars)都放在了第一个GPU上,运行时会发现第一个GPU占用的显存比其他GPU多一些。如果想把变量放在CPU上,则需要在创建计算图时,针对每层使用到的变量进行设备指定,很麻烦,所以建议把变量放在GPU上。
tensorflow使用多个gpu训练的更多相关文章
- Tensorflow检验GPU是否安装成功 及 使用GPU训练注意事项
1. 已经安装cuda但是tensorflow仍然使用cpu加速的问题 电脑上同时安装了GPU和CPU版本的TensorFlow,本来想用下面代码测试一下GPU程序,但无奈老是没有调用GPU. imp ...
- tensorflow 13:多gpu 并行训练
多卡训练模式: 进行深度学习模型训练的时候,一般使用GPU来进行加速,当训练样本只有百万级别的时候,单卡GPU通常就能满足我们的需求,但是当训练样本量达到上千万,上亿级别之后,单卡训练耗时很长,这个时 ...
- 使用GPU训练TensorFlow模型
查看GPU-ID CMD输入: nvidia-smi 观察到存在序号为0的GPU ID 观察到存在序号为0.1.2.3的GPU ID 在终端运行代码时指定GPU 如果电脑有多个GPU,Tensorfl ...
- Tensorflow 多gpu训练
Tensorflow可在训练时制定占用那几个gpu,但如果想真正的使用多gpu训练,则需要手动去实现. 不知道tf2会不会改善一下. 具体参考:https://wizardforcel.gitbook ...
- 使用Keras进行多GPU训练 multi_gpu_model
使用Keras训练具有多个GPU的深度神经网络(照片来源:Nor-Tech.com). 摘要 在今天的博客文章中,我们学习了如何使用多个GPU来训练基于Keras的深度神经网络. 使用多个GPU使我们 ...
- 『开发技术』GPU训练加速原理(附KerasGPU训练技巧)
0.深入理解GPU训练加速原理 我们都知道用GPU可以加速神经神经网络训练(相较于CPU),具体的速度对比可以参看我之前写的速度对比博文: [深度应用]·主流深度学习硬件速度对比(CPU,GPU,TP ...
- TensorFlow分布式(多GPU和多服务器)详解
本文介绍有关 TensorFlow 分布式的两个实际用例,分别是数据并行(将数据分布到多个 GPU 上)和多服务器分配. 玩转分布式TensorFlow:多个GPU和一个CPU展示一个数据并行的例子, ...
- Pytorch多GPU训练
Pytorch多GPU训练 临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练 原理 多卡训练的基本过程 首先把模型加载到一个主设备 把模型只读复制到多个设备 把大的batc ...
- 使用Deeplearning4j进行GPU训练时,出错的解决方法
一.问题 使用deeplearning4j进行GPU训练时,可能会出现java.lang.UnsatisfiedLinkError: no jnicudnn in java.library.path错 ...
随机推荐
- python字符串与列表的相互转换
学习内容: 1.字符串转列表 2.列表转字符串 1. 字符串转列表 s ='hello python !'li = s.split(' ') #注意:引号内有空格print (li)输出:['hell ...
- 产品开发- DFX
一.DFE(Design for Environment)面向环境的设计 二.DFM(Design for Manufacture)面向制造的设计 DFM的最终设计的主要目的是对产品成本的控制,主要包 ...
- MD5+Salt值
生成Salt值 package util; import java.util.Random; public class Salt { public String getSalt() { Random ...
- java第一次课
package java第一周学习2; 达达20173435 信1705-2 import java.text.SimpleDateFormat; import java.util.Date; pub ...
- c# js 删除table原行数据
function addtreetotable(obj){ var table1 = document.getElementById("Table1"); var hang = ...
- webpack常用loader和plugin及打包速度优化
优化 或 也可以用: 备用: 慎用的配置,用的不好会增加打包时间: 代码丑化插件:
- db2 reorg详解
reorgchk,检查table index 是否需要重组.reorg 重组,重新放置数据位置.runstats 统计信息,可以优化查询器 一个完整的日常维护规范可以帮助 DBA 理顺每天需要的操作, ...
- JavaScript常用,继承,原生JavaScript实现classList
原文链接:http://caibaojian.com/8-javascript-attention.html 基于 Class 的组件最佳实践(Class Based Components) 基于 C ...
- git操作中出现Unlink of file '......' failed. Should I try again?
在操作git中有时候会提示 Unlink of file '......' failed. Should I try again? 原因是你工作目录有某些文件正在被程序使用,这个程序多半是Idea,V ...
- 【转】Selenium - 封装WebDrivers (C#)
本文转载自:http://www.cnblogs.com/qixue/p/3977135.html Web element仍然使用OpenQA.Selenium.IWebElement, 本类库将Se ...