kafka channle的应用案例
flume配置kafka channle的实战案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
最近在新公司负责大数据平台的建设,平台搭建完毕后,需要将云平台(我们公司使用的Ucloud的云服务器,大概320多台,还在扩容中),公司每个月光大数据服务费用就接近50万人民币。老板考虑成本问题,花了接近200万的前采购了50台服务器用于大数据平台的建设。我已经将集群部署好了,正准备将云上的环境原样搬到我的新平台上时,遇到了一系列的坑,我已经填了不少的坑。这不,关于flume的一个channel的选择也是一个坑。
我们知道常用的channel如下:
file channel的特点是:速度慢,支持容灾;
memory channel的特点是:速度快,断电丢数据,我们在Ucloud上使用的就是它;
kafka channel的特点是:高速缓存;
一.flume报错OOM
计划将kafka的数据通过flume抽取到hdfs上,真是flume略我千百变,我带flume如初恋啊。经过各种测试,我已经将flume的内存提升到12G,下面是我启动flume看到的信息,如下图:
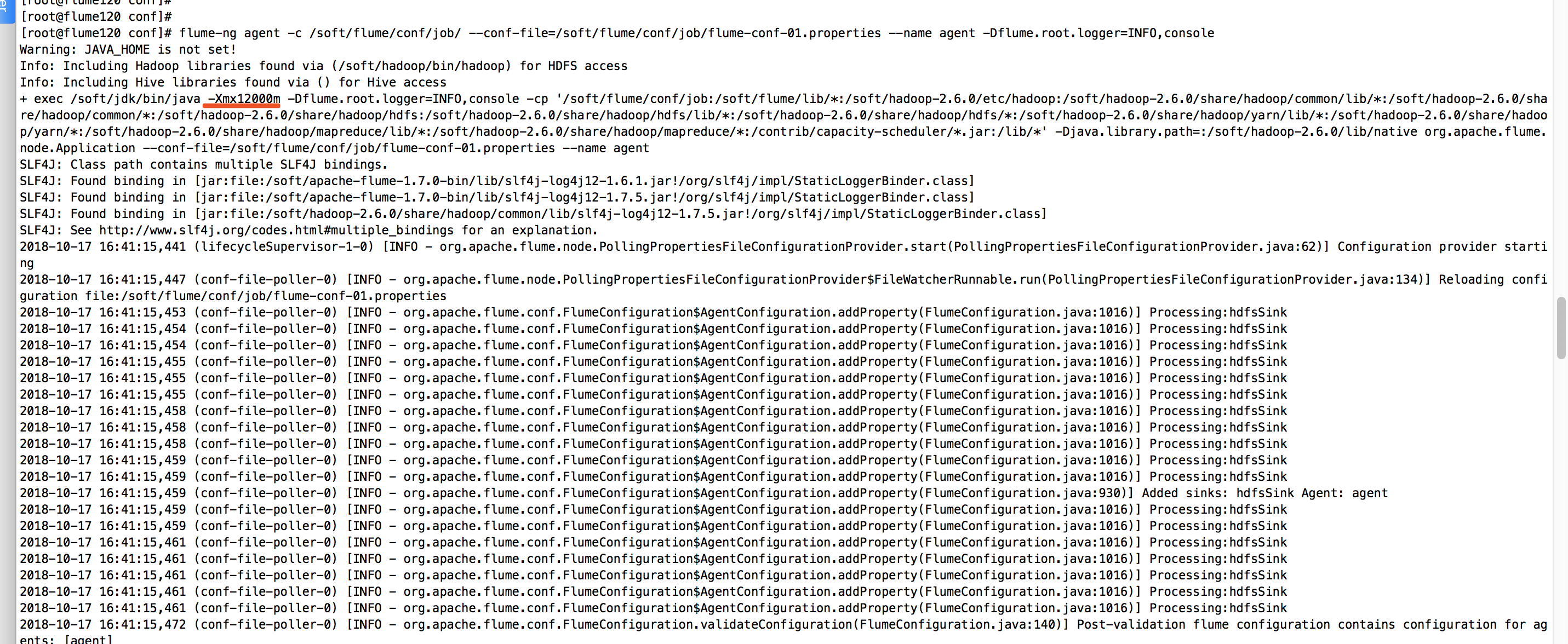
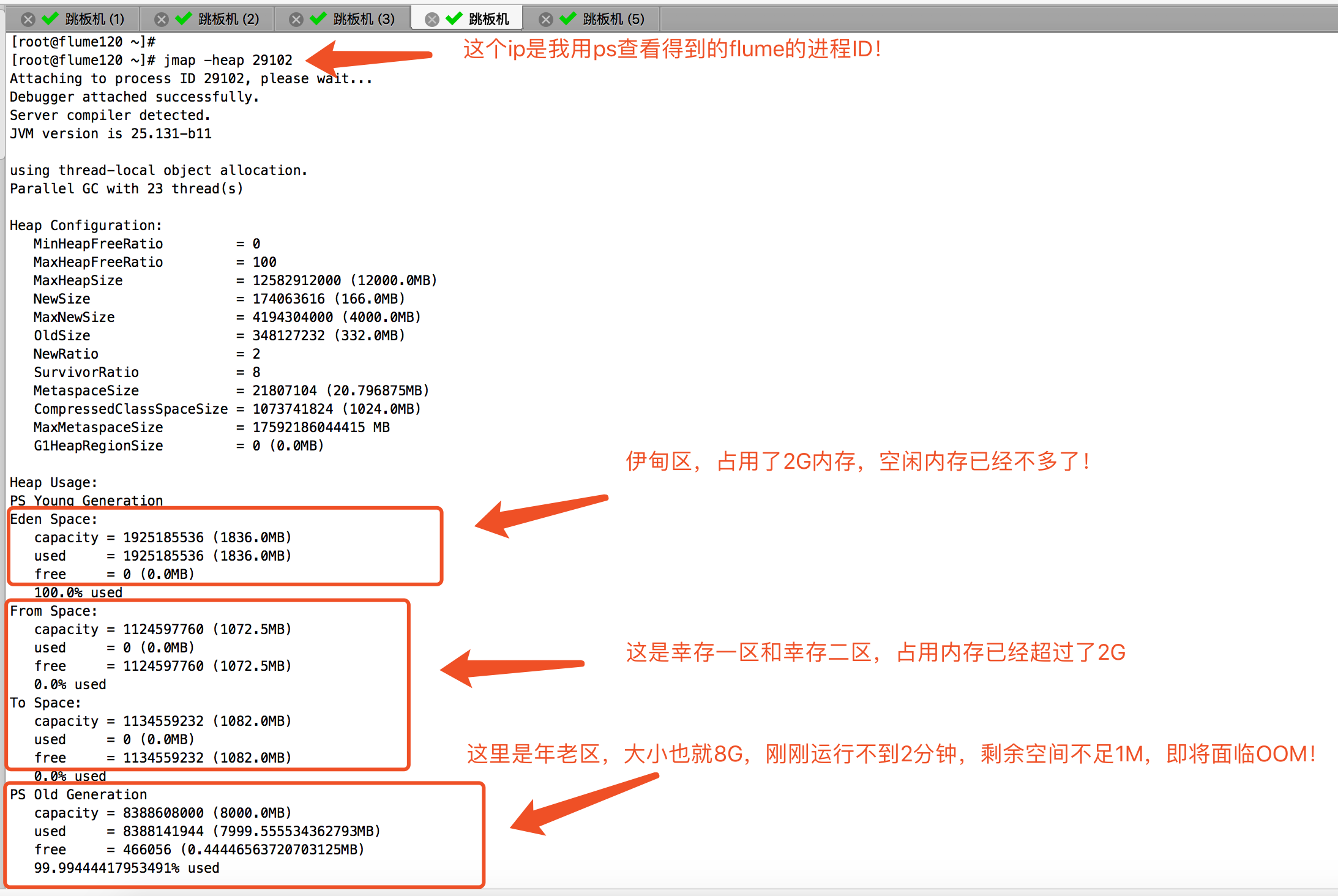
启动后,我开启了一个终端,查看JVM的内存使用情况,发现分分钟就给我吃满了!如下图:
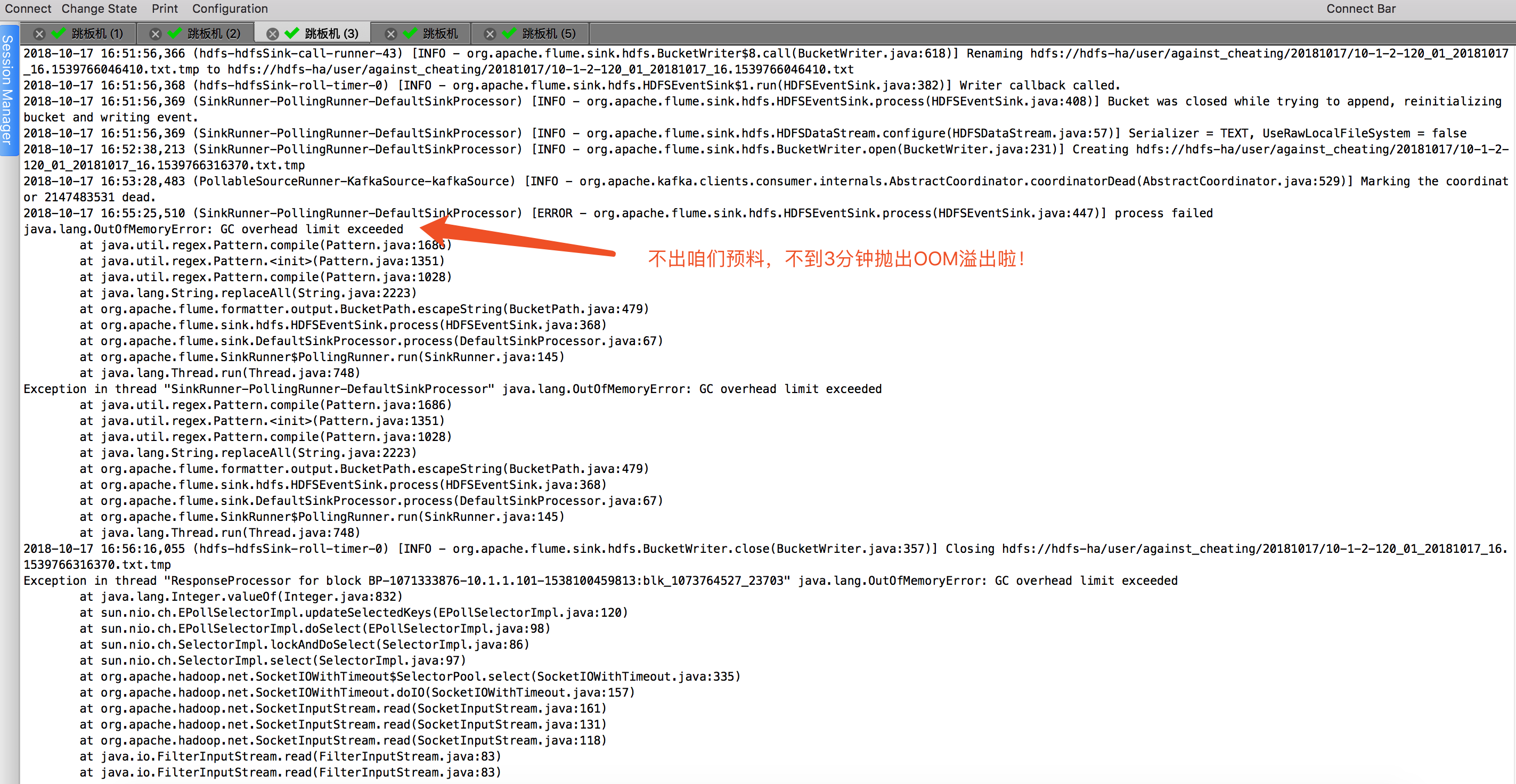
接下来,不到3分钟时间,flume就崩溃了,频繁抛出OOM的异常信息:
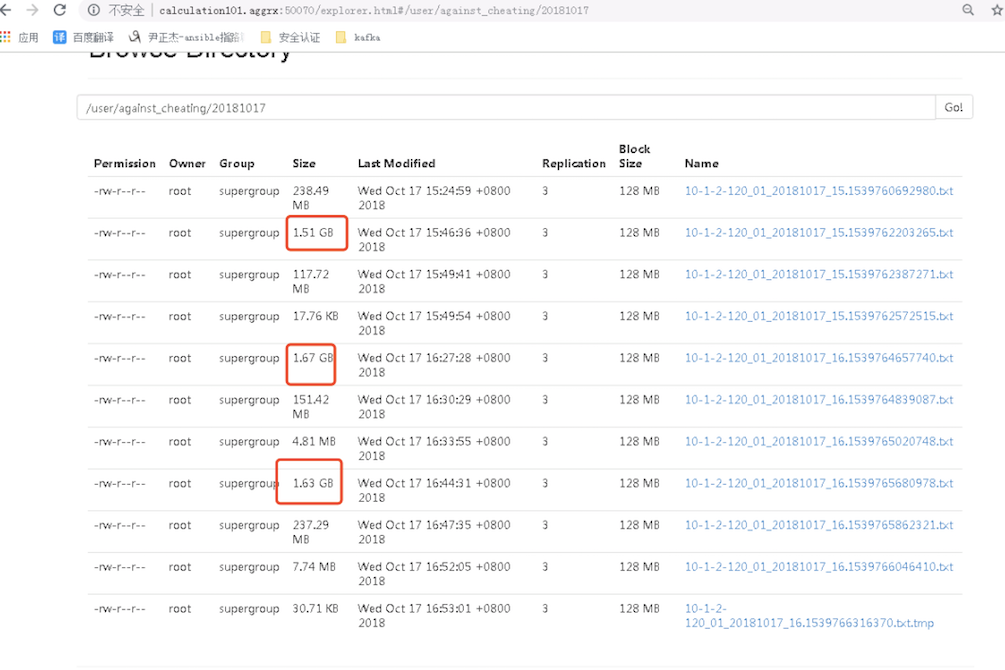
接下来,我们看一下hdfs集群中是否有数据,答案是肯定的,hdfs的确是有数据:
咋解决呢?大家可能说,你继续加大内存呗,12G不够,就给24G试试看!OK,我就JVM的堆内存调试到24G,启动程序:
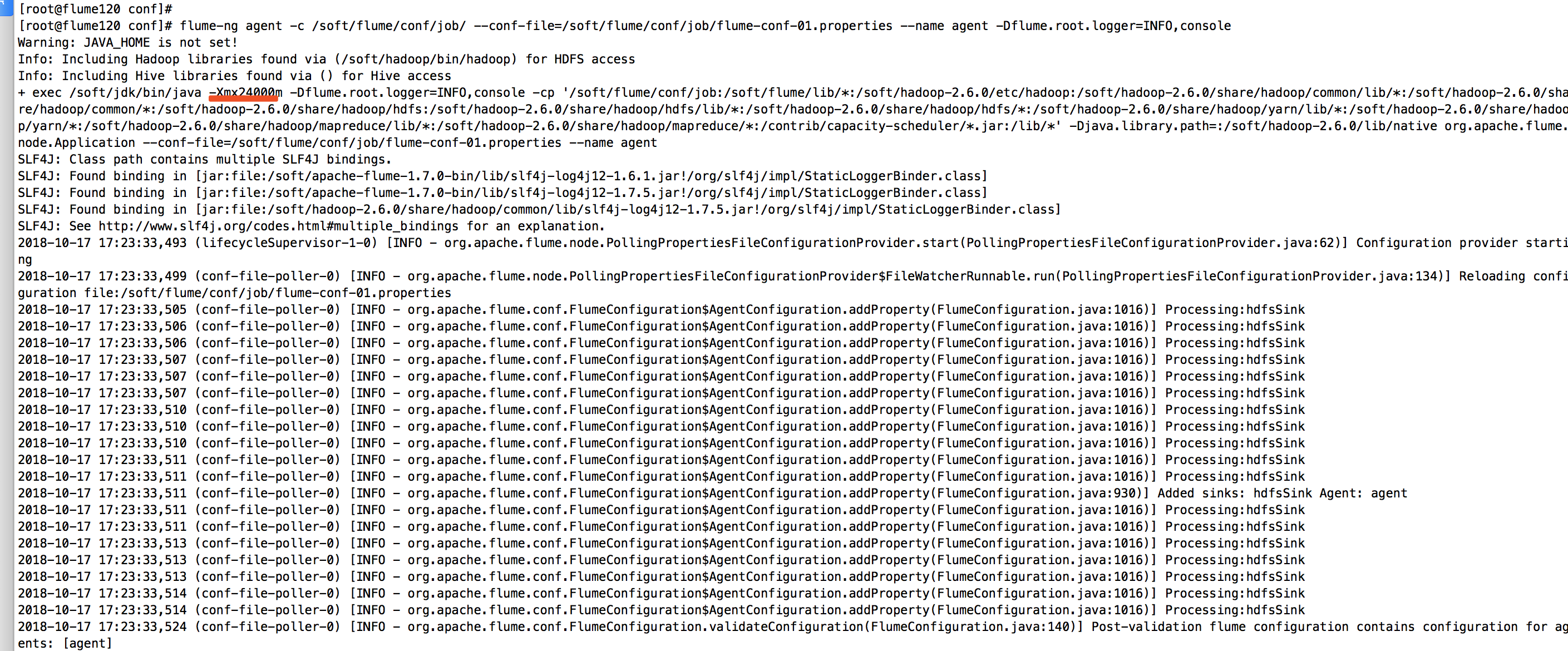
在后端查看flume的进程ID:

查看JVM的运行情况,如下:

经过上面的改造后,我一致在等OOM,可惜一个小时过去了,始终没有抛出OOM异常,我有点小失落,也有点小开心。开心的是终于不崩溃了,失落的是还剩下4个G,那我原来打算在这台服务器上开启8个flume进程的计划是要泡汤了,因为是总大小总共才32G,有上面解决方案呢?查看官网,据说是有种基于Kafka channel的模式。也是本篇博客的想要说的主角。
二.分析OOM的解决方案
1>.分析为什么会抛OOM溢出
其实想象大家也知道,source是kafka,而sink是hdfs,他们两个的吞吐量闭着眼睛大家都知道谁是快谁慢。
hdfs集群的工作原理可知,它在写数据和读取数据时都会和NameNode这个服务器进行交互,需要一系列验证操作,最后读操作或者写操作依然不是和NameNode进行交互,而是client直接跟DataNode进行交互。
kafka则是基于partition来进行消费的,网上有些文章说partition的数越多,意味着kafka的吞吐量就越大,其实这个说法并不严谨,parition的数量应该小于集群的core总数,因为每个消费者基于paritition进行消费时,服务器都会开启一个线程去应酬,如果你一台服务器paritrion响应的特别多,设计到上下文切换反而不理想了。一个消费者可以去集群同时对多个partition进行消费。
以上的观点仅是我个人对Kafka和hdfs的理解,如果哪里有说的不对的话,欢迎各位大神之路!综上所述,我们都说kafka的速度要远远大于hdfs,kafka是顺序写入磁盘的,他的速度可达到300M/s,我们可以毫不客气的说,顺序写入磁盘相比随机写入内存的速度有过之而无不及。
好了,上面说了一堆的废话,咱们回归正题,为什么会OOM呢?原因很简单,我们形象的说:想必大家都喝过可乐吧,可乐的汽水瓶形状大家也应该清楚吧,我们将可乐瓶的瓶盖去掉,然后把可乐瓶的平底削去,我们假设我们在粗的一端(原来的瓶底)注水进去,然后水会送细的一端(原来的瓶盖)出去没毛病吧?理论上来说,如果粗的一端源源不断的网可乐瓶中注水,水也会远远不断的从小瓶盖中出去,但是当粗的一端流入端的速度远远高于流出端的速度,那么可乐瓶容器很快就会积累很多的水,知道把可能瓶注满水,当注满水以后,这个时候还要往里面注水的话,可乐瓶容器可能会变形,设置可能会将可能瓶撑爆。
如果你看懂了我上面的描述,那么你我们在结合kafka和hdfs,说一说,谁是瓶底,谁是瓶盖,谁是可乐瓶呢?我的理解是此时我们的瓶底的一端就是kafka,可乐瓶本身就是memory channel,瓶口那一端就是hdfs。那么瓶子被水撑满最终爆裂就好比咱们的OOM。
2>.编写flume的配置文件(该配置文件我是根据生产环境稍作改动,可供参考)
[root@flume120 ~]# cat /soft/flume/conf/job/flume-conf-.properties
#定义别名
agent.sources = kafkaSource
agent.channels = fileChannel
agent.sinks = hdfsSink #绑定关系
agent.sources.kafkaSource.channels = fileChannel
agent.sinks.hdfsSink.channel = fileChannel #指定source源为kafka source
agent.sources.kafkaSource.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafkaSource.kafka.bootstrap.servers = 10.1.3.116:,10.1.3.117:,10.1.3.118:,10.1.3.119:,10.1.3.120:
agent.sources.kafkaSource.topic = against_cheating_01
agent.sources.kafkaSource.groupId =
agent.sources.kafkaSource.kafka.consumer.timeout.ms =
agent.sources.kafkaSource.kafka.consumer.request.timeout.ms =
agent.sources.kafkaSource.kafka.consumer.fetch.max.wait.ms=
agent.sources.kafkaSource.kafka.consumer.offset.flush.interval.ms =
agent.sources.kafkaSource.kafka.consumer.session.timeout.ms =
agent.sources.kafkaSource.kafka.consumer.heartbeat.interval.ms =
agent.sources.kafkaSource.kafka.consumer.enable.auto.commit = false
agent.sources.kafkaSource.interceptors = i1
agent.sources.kafkaSource.interceptors.i1.userIp = true
agent.sources.kafkaSource.interceptors.i1.type = host #指定channel类型为kafka
agent.channels.fileChannel.type = org.apache.flume.channel.kafka.KafkaChannel
agent.channels.fileChannel.kafka.bootstrap.servers = 10.1.3.116:,10.1.3.117:,10.1.3.118:,10.1.3.119:,10.1.3.120:
agent.channels.fileChannel.kafka.topic = channel_against_cheating_01
agent.channels.fileChannel.kafka.consumer.group.id = flume-consumer-against_cheating_01
agent.channels.fileChannel.kafka.consumer.timeout.ms =
agent.channels.fileChannel.kafka.consumer.request.timeout.ms =
agent.channels.fileChannel.kafka.consumer.fetch.max.wait.ms=
agent.channels.fileChannel.kafka.consumer.offset.flush.interval.ms =
agent.channels.fileChannel.kafka.consumer.session.timeout.ms =
agent.channels.fileChannel.kafka.consumer.heartbeat.interval.ms =
agent.channels.fileChannel.kafka.consumer.enable.auto.commit = false #指定sink的类型为hdfs
agent.sinks.hdfsSink.type = hdfs
agent.sinks.hdfsSink.hdfs.path = hdfs://hdfs-ha/user/against_cheating/%Y%m%d
agent.sinks.hdfsSink.hdfs.filePrefix = ---120_01_%Y%m%d_%H
agent.sinks.hdfsSink.hdfs.fileSuffix = .txt
agent.sinks.hdfsSink.hdfs.useLocalTimeStamp = true
agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType=DataStream
agent.sinks.hdfsSink.hdfs.rollCount =
agent.sinks.hdfsSink.hdfs.rollSize =
agent.sinks.hdfsSink.hdfs.rollInterval =
agent.sinks.hdfsSink.hdfs.batchSize =
agent.sinks.hdfsSink.hdfs.threadsPoolSize =
agent.sinks.hdfsSink.hdfs.idleTimeout =
agent.sinks.hdfsSink.hdfs.minBlockReplicas =
agent.sinks.hdfsSink.hdfs.callTimeout=
agent.sinks.hdfsSink.hdfs.request-timeout=
agent.sinks.hdfsSink.hdfs.connect-timeout= [root@flume120 ~]#
3>.启动flume
[root@flume120 ~]# cd /soft/flume/shell/
[root@flume120 shell]#
[root@flume120 shell]# ll
total
-rwxr-xr-x root root Oct : start_flume_against_cheating_01.sh
-rwxr-xr-x root root Oct : start_flume_against_cheating_02.sh
-rwxr-xr-x root root Oct : start_flume_against_cheating_03.sh
-rwxr-xr-x root root Oct : start_flume_against_cheating_04.sh
-rwxr-xr-x root root Oct : start_flume_against_cheating_05.sh
[root@flume120 shell]#
[root@flume120 shell]# cat start_flume_against_cheating_01.sh #我们直接执行这个脚本就行,默认就可以执行啦!
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com
#Data:Thu Oct :: CST #将监控数据发送给ganglia,需要指定ganglia服务器地址,使用请确认是否部署好ganglia服务!
#nohup flume-ng agent -c /soft/flume/conf/job/ --conf-file=/soft/flume/conf/job/flume-conf-.properties --name agent -Dflume.monitoring.type=ganglia -Dflume.monitoring.hosts=10.1.2.120: -Dflume.root.logger=INFO,console >> /soft/flume/logs/flume-ganglia-.log >& & #启动flume自身的监控参数,默认执行以下脚本
nohup flume-ng agent -c /soft/flume/conf/job/ --conf-file=/soft/flume/conf/job/flume-conf-.properties --name agent -Dflume.monitoring.type=http -Dflume.monitoring.port= -Dflume.root.logger=INFO,console >> /soft/flume/logs/flume-http-.log >& & [root@flume120 shell]#
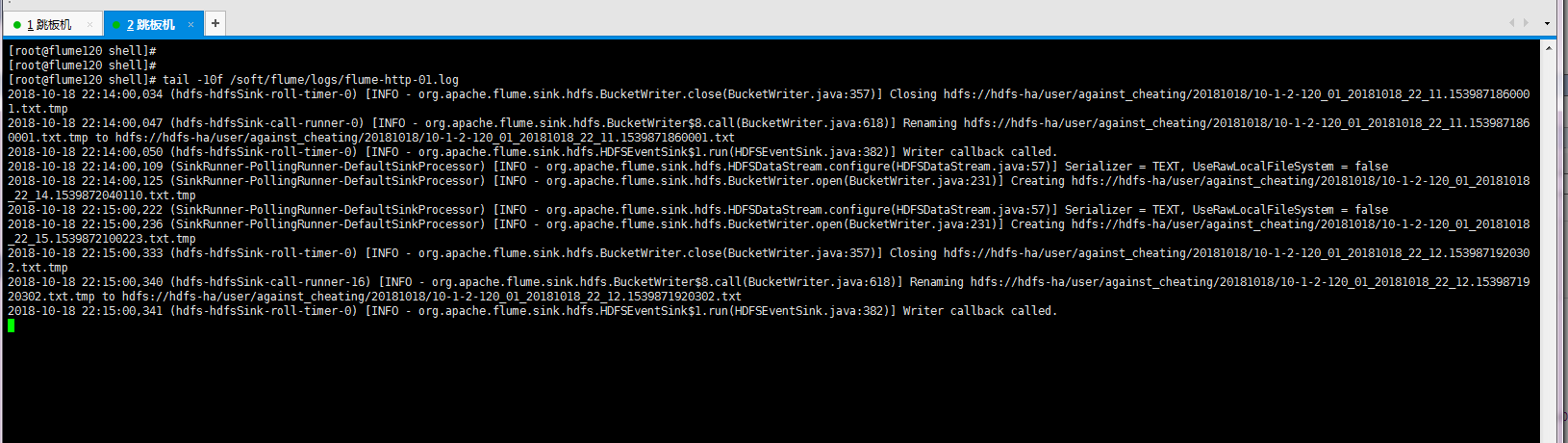
4>.查看日志([root@flume120 shell]# tail -10f /soft/flume/logs/flume-http-01.log)
kafka channle的应用案例的更多相关文章
- SpringBoot2 整合Kafka组件,应用案例和流程详解
本文源码:GitHub·点这里 || GitEE·点这里 一.搭建Kafka环境 1.下载解压 -- 下载 wget http://mirror.bit.edu.cn/apache/kafka/2.2 ...
- Python+SparkStreaming+kafka+写入本地文件案例(可执行)
从kafka中读取指定的topic,根据中间内容的不同,写入不同的文件中. 文件按照日期区分. #!/usr/bin/env python # -*- coding: utf-8 -*- # @Tim ...
- kafka拦截器原理|案例实操
拦截器原理 Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑. 对于producer而言,interceptor使得用 ...
- 【Kafka】实时看板案例
目录 项目需求 项目模型 实现步骤 项目需求 快速计算双十一当天的订单量和销售金额 项目模型 实现步骤 一.创建topic bin/kafka-topics.sh --create --topic i ...
- kafka笔记博客
大数据数据流组件选择: https://www.cnblogs.com/yinzhengjie/articles/11155051.html 初识Apache Kafka 核心概念: https:// ...
- Kafka集群优化篇-调整broker的堆内存(heap)案例实操
Kafka集群优化篇-调整broker的堆内存(heap)案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看kafka集群的broker的堆内存使用情况 1>. ...
- Spark-Streaming kafka count 案例
Streaming 统计来自 kafka 的数据,这里涉及到的比较,kafka 的数据是使用从 flume 获取到的,这里相当于一个小的案例. 1. 启动 kafka Spark-Streaming ...
- kafka入门1:安装及配置
1下载 官方下载地址:https://kafka.apache.org/downloads 案例使用版本:kafka_2.11-1.1.0.tgz 2上传服务器 使用ftp工具将压缩包放置到服务器上 ...
- 【转载】Understanding When to use RabbitMQ or Apache Kafka
https://content.pivotal.io/rabbitmq/understanding-when-to-use-rabbitmq-or-apache-kafka RabbitMQ: Erl ...
随机推荐
- JavaScript —— 数组
Array方法 1.查找元素 indexOf()用来查找传进来的参数在目标数组中是否存在.如果目标数组包含该参数,就返回该元素在数组中的索引:如果不包含,就返回-1. 如果数组中包含多个相同的元素,i ...
- Linux环境C程序设计
Linux基础 常用shell命令 命令 说明 命令 说明 man 查看联机帮助 ls 查看目录及文件列表 cp 复制目录或文件 mv 移动目录或文件 cd 改变文件或目录 rm 删除文件或目录 mk ...
- b总结
Beta 答辩总结 评审表 组名 格式 内容 ppt 演讲 答辩 总计 天机组 15 15 13 15 14 72 PMS 16 16 15 16 16 79 日不落战队 16 17 17 17 17 ...
- shell脚本--制作自己的服务脚本
首先注意一下,我用的环境是centos6.5,中间有一些操作和在Ubuntu上有一些地方的操作是不同的, 编写脚本 首先看一个实例:假设有一个test的服务,可以通过命令对test进行启动.关闭或者重 ...
- C语言复制文件的两种简单的方法【从根本解决问题】
网上的方法大致有这样几种: 1.使用操作系统提供的复制文件的API 2.使用C语言本身提供的复制文件的函数 3.直接读写文件,从文件角度来操作,从而直接将一个文件复制 这里我们使用的就是这第三种. 复 ...
- [转帖]git命令参考手册
git init # 初始化本地git仓库(创建新仓库) git ...
- Qt__状态栏(statusBar)
转自豆子空间 状态栏位于主窗口的最下方,提供一个显示工具提示等信息的地方.一般地,当窗口不是最大化的时候,状态栏的右下角会有一个可以调节大小的控制点:当窗口最大化的时候,这个控制点会自动消失.Qt提供 ...
- String()与toString的区别
1..toString()可以将所有的的数据都转换为字符串,但是要排除null 和 undefined 代码示例: var a = null.toString()--报错 var b = underf ...
- 【Mysql】—— 索引的分类
注意:索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引.MyISAM和InnoDB存储引擎:只支持BTREE索引,也就是说默认使用BTREE,不能够更换.MEMORY/HEAP存储引 ...
- target存放的是编译后的.class文件地方 默认情况下不会讲非class文件放入进入 如果要使用非.class文件 需要通过增加配置方式自动加入文件
target存放的是编译后的.class文件地方 默认情况下不会讲非class文件放入进入 如果要使用非.class文件 需要通过增加配置方式自动加入文件