论文解读(BYOL)《Bootstrap Your Own Latent A New Approach to Self-Supervised Learning》
论文标题:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
论文方向:图像领域
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2006.07733
论文代码:https://github.com/deepmind/deepmind-research/tree/master/byol
1 介绍
BYOL,全称叫Bootstrap Your Own Latent,它在迭代的过程中引导网络的输出作为目标,训练过程中不需要negative pairs。它的特点就是:(1)不需要negative pairs;(2)对不同的batch size大小和数据增强方法适应性强。
使用BYOL的效果:使用标准的 ResNet 达到 74.3% top-1 的准确率和使用large ResNet 达到 79.6% top-1的准确率。
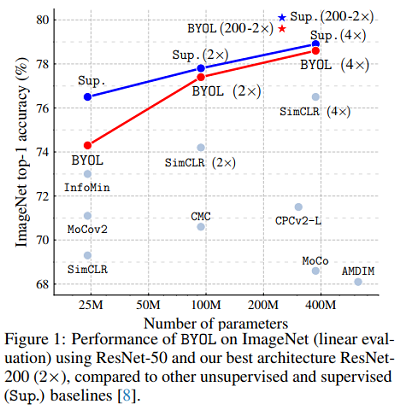
贡献:
- 引入了一种自监督的表示学习方法BYOL,在不使用负对的情况下,在ImageNet上的线性评估协议下获得最先进的结果。
- 在 半监督 和 transfer基准测试中,我们所学的表现优于最先进的水平。
- BYOL对批量和图像增强集的变化更有弹性。当仅使用随机裁剪作为图像增强时,BYOL的性能下降比强对比基线SimCLR小得多。
Q: linear evaluation protocol?
Q: frozen representation
2 BYOL框架
BYOL框架图:

如下图 2 所示,BYOL 由两个网络组成,一个称为online network,另一个称为 target network 。online network由三部分构成:encoder $f_{\theta}$, projector $g_{\theta} $ 和 predictor $q_{\theta}$;target network 和 online network 有相似的结构,唯一的不同就是它少了一个 predictor,它的 encoder 和 projector 分别用 $f_{\xi}$ 和 $ g_{\xi }$ 表示。
两个网络训练方式:
- online network 的参数 $\theta$ 用一般的梯度下降更新;
- target network 的参数 $\xi$ 不通过梯度下降来更新,而是由 $\theta$ 的指数移动平均($\xi \leftarrow \tau \xi+(1-\tau) \theta$)来更新。
- 即 $\begin{array}{l} \theta \leftarrow \text { optimizer }\left(\theta, \nabla_{\theta} \mathcal{L}_{\theta, \xi}^{\mathrm{BYOL}}, \eta\right) \\ \xi \leftarrow \tau \xi+(1-\tau) \theta \end{array}$
online network 在执行梯度下降更新时, 计算 loss:
$\mathcal{L}_{\theta, \xi}^{B Y O L}=\mathcal{L}_{\theta, \xi}+\widetilde{\mathcal{L}}_{\theta, \xi} $
其中 $ \mathcal{L}_{\theta, \xi}=2-2 \cdot \frac{\left\langle q_{\theta}\left(z_{\theta}\right), z_{\xi}^{\prime}\right\rangle}{\left\|q_{\theta}\left(z_{\theta}\right)\right\|_{2} \cdot\left\|z_{\xi}^{\prime}\right\|_{2}}$ 。 $\widetilde{\mathcal{L}}_{\theta, \xi}$ 是 $ \mathcal{L}_{\theta, \xi}$ 的对称形式:$ \mathcal{L}$ 的输入是 $ t$ 的 prediction 和 $ t^{\prime}$ 的 projection; $\widetilde{\mathcal{L}}$ 的输入是 $ t^{\prime} $ 的prediction 和 $ t$ 的 projection,相当于交叉预测对方的 projection 。
为什么加入了一个 target network ?
contrastive learning 会陷入 collapse(所有图像的表征向量都一样),这在负样本不足的情况下很容易产生。
BYOL
- 借鉴了 Mean Teacher 中的指数移动平均策略;
- 交叉预测 projection。target network可以看作是对 online network 学习的总结,历史经验往往能使模型更加稳定。交叉预测 projection 就是使 online netork 与历史经验保持一定的联系,从而得到更平稳的训练过程。
算法流程:

3 启发
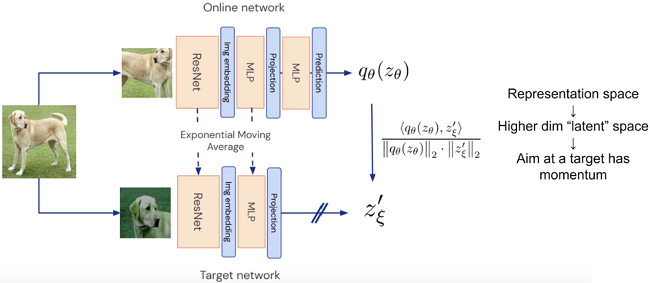
联系GAN,两个网络学到的表示要尽可能相同,但总互相干扰(动量法)。
4 实验
4.1 Linear evaluation on ImageNet
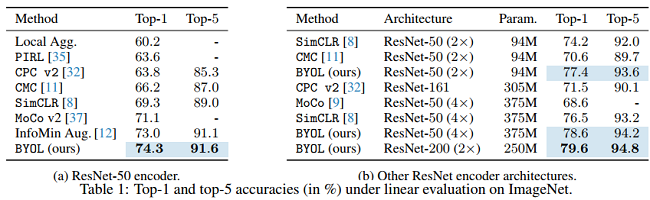
对比之前的自监督方法,BYOL(采用 ResNet encoder (1 $\times$))效果更好,在 Top-1 上达74.3的准确率,在 Top-5 上达 91.6 的准确率。更换 encoder 框架后效果依然很好。
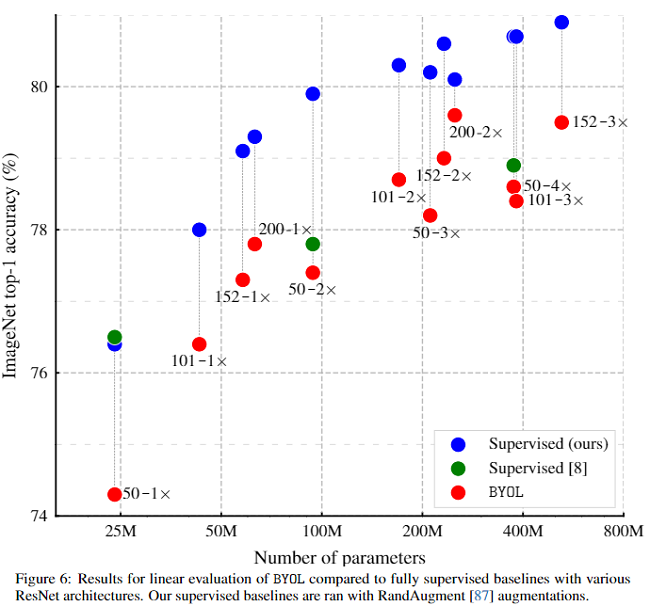
显然无监督方法 BYOL 的效果要比自监督的 BYOL 效果要差,但是比大部分其他监督方法要好。
4.2 Semi-supervised training on ImageNet
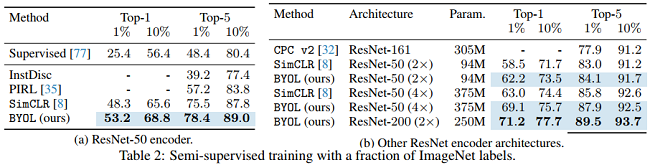
在获得表示后,使用训练集上的 label 对BYOL's representation 进行微调。
(a) 可以看到 BYOL 在 Top-1 和 Top-5上的效果比InstDisc、PIRL、SimCLR效果要好。
(b) 可以看到采用不同的 Encoder Architecture 效果依然显著。
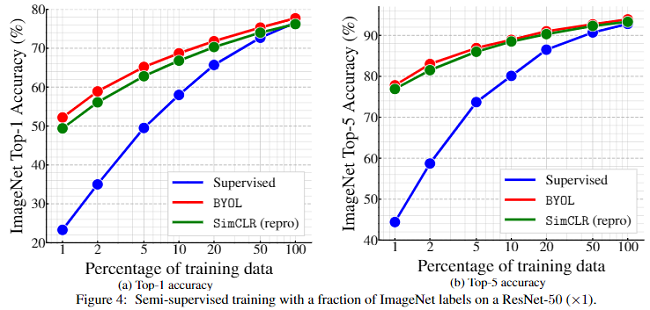
图 4 采用不同的微调率(1% and 10%),使用 ResNet-50(1 $\times$ ) 在不同 ImageNet traininjg data 上的表现。
从图 4 可以看出有监督方法在 training data少的情况下表现是很糟糕的,使用全部 training data 的效果还是比较好的,但是无监督方法仍然可以通过微调达到一个可以媲美有监督方法的实验结果。
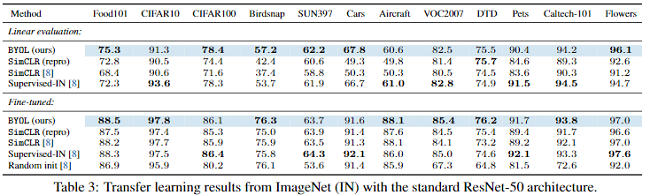
4.3 Transfer to other classification tasks
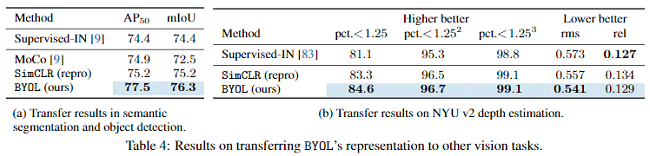
4.4 Ablation Study
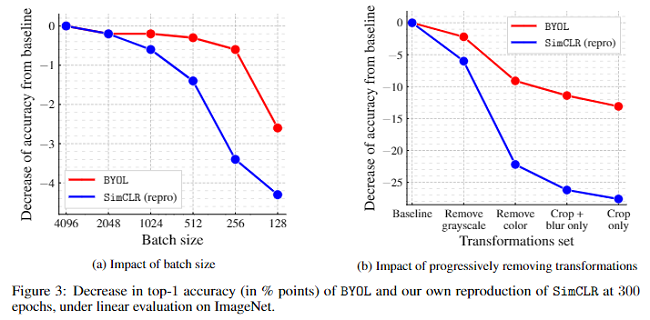
这里采用不同的 Batch size 和SimCLR做消融实验。
从图中可以看出SumCLR对Batch size 的变化更加敏感,因为它需要更多的负样本。BYOL对样本数不是很敏感,这是它的优势。
5 总结
- + BYOL learns it's representation by predicting previous versions of its outputs, without using negative pairs.
- + BYOL bridges most of the remaining gapbetween self-supervised methods and the supervised learning baseline.
- - Sensitive to batch size & opimizer choices
6 参考
论文解读(BYOL)《Bootstrap Your Own Latent A New Approach to Self-Supervised Learning》的更多相关文章
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- 自监督图像论文复现 | BYOL(pytorch)| 2020
继续上一篇的内容,上一篇讲解了Bootstrap Your Onw Latent自监督模型的论文和结构: https://juejin.cn/post/6922347006144970760 现在我们 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
随机推荐
- Docker部署ELK之部署filebeat7.6.0(3)
1. filebeat介绍 Filebeat是用于转发和集中日志数据的轻量级传送工具.Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logsta ...
- 解决tomcat7中request会对中文重新编码,导致后台接收到为encode编码后参数问题
package xxx; import java.io.IOException; import java.io.UnsupportedEncodingException; import java.ut ...
- Shell-01-变量
变量 系统常用变量 #!/bin/bash echo "默认shell: $SHELL" echo "当前用户家目录: $HOME" echo "内部 ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- elk 7.9.3 版本容器化部署
ELK-V7.9.3 部署 为什么用到ELK? 平时我们需要进行日志分析的时候,可以直接在日志文件中 grep.awk 就可以过滤出自己想要的信息及关键字,但规模较大的场景中,此方法极大的减低了效率, ...
- RHEL 7 “There are no enabled repos” 的解决方法
RHEL 7 "There are no enabled repos" 的解决方法 [root@system1 Desktop]# yum install squidLoaded ...
- TP6 服务器响应500时没有错误信息的解决方案
重点!!!! 首先,确认你的电脑管理员账户是否含有中文!!!!!!就像下面这种:所以出现了没有错误提示 查看nginx日志显示\vendor\topthink\framework\src\thi ...
- javascript(js)反转字符串
网上看到的都是这个写法较多: str.split('').reverse().join(''); 这里发现一个ES6的写法也可以达到同样的效果: Array.from(str).reverse().j ...
- 【springcloud alibaba】注册中心之nacos
1.为什么需要注册中心 1.1 没有注册中心会怎么样 1.2 注册中心提供什么功能以及解决什么问题 2.常用的微服务注册中心对比 3.案例项目父工程 4.nacos作为注册中心的使用 4.1 单机版的 ...
- C++ 保存读取二进制
一.保存二进制 #include <iostream> #include <fstream> int main(){ float* output = new float[100 ...