利用词向量进行推理(Reasoning with word vectors)
The amazing power of word vectors | the morning paper (acolyer.org)
What is a word vector?
At one level, it’s simply a vector of weights. In a simple 1-of-N (or ‘one-hot’) encoding every element in the vector is associated with a word in the vocabulary. The encoding of a given word is simply the vector in which the corresponding element is set to one, and all other elements are zero.
从某种角度来说,词向量(word vector)仅仅是对应单词的权重用的向量化表示。在独热编码中,向量中的每个编码元素与一个文本对应的词汇表中的特定的一个单词有联系,一个单词会对应一个独热向量,这个独热向量中对应这个单词的维度的元素会被置为1,其余的全都置为0.
Suppose our vocabulary has only five words: King, Queen, Man, Woman, and Child. We could encode the word ‘Queen’ as:
假设我们的词汇表只有5个单词,国王、女王、男人、女人和孩子,那么我们可以把“女王”编码为:
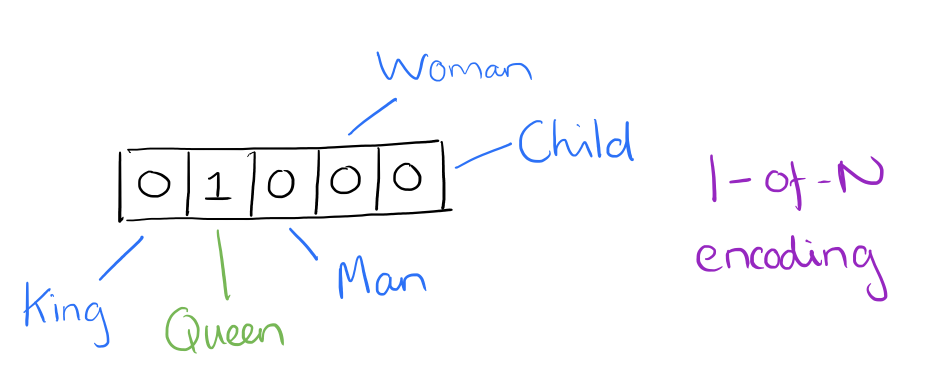
Using such an encoding, there’s no meaningful comparison we can make between word vectors other than equality testing.
但是这样的编码会使得两个向量之间没有什么比较意义,除了判断两个向量是否相等。
In word2vec, a distributed representation of a word is used. Take a vector with several hundred dimensions (say 1000). Each word is representated by a distribution of weights across those elements. So instead of a one-to-one mapping between an element in the vector and a word, the representation of a word is spread across all of the elements in the vector, and each element in the vector contributes to the definition of many words.
在word2vec中,我们对单词使用了一种数值分散(非零数值分散)的表示方法。假设一个向量有好几百维(比如1000维),每个单词都会被1000个权重表示,这些权重很有可能非零而且表示的是与其他单词的关系的大小。所以一个单词的表示会与这个1000维的向量的所有其他元素都有关系,每个元素都会对这个单词的定义做或多或少的贡献,所以我们会用其代替使用一 一映射的独热编码来表示单词或词组。
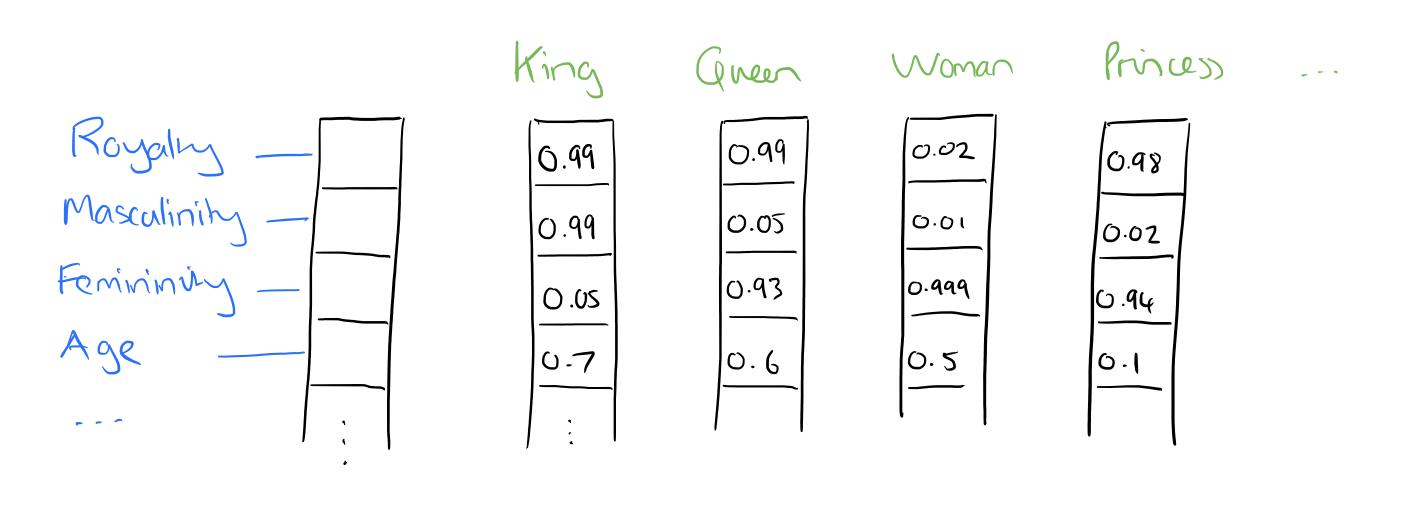
royaling:与皇室相关的;masculining:与男子汉气概相关的;feminining:与女子特点相关的;Age:年龄。
从图中我们可以看到,King和Queen与royaling很相关,这显而易见,所以这个维度上King和Queen的分数应该要高点,其他也是如此。
另外可以这样思考:VGueen - VWoman = [0.97 0.04 -0.069 0.1](记为Vt),这个向量表示什么意思?Vman+Vt 等于什么呢?约等于VKing吗?下面会给出答案。
Reasoning with word vectors
We find that the learned word representations in fact capture meaningful syntactic and semantic regularities in a very simple way. Specifically, the regularities are observed as constant vector offsets between pairs of words sharing a particular relationship. For example, if we denote the vector for word i as xi, and focus on the singular/plural relation, we observe that xapple – xapples ≈ xcar – xcars, xfamily – xfamilies ≈ xcar – xcars, and so on. Perhaps more surprisingly, we find that this is also the case for a variety of semantic relations, as measured by the SemEval 2012 task of measuring relation similarity.
我们发现模型学习到的词表示方法(词向量)实际上能够以一种很简单的方式表示单词对应的语法(Kings,King)和语义规律。更具体的来说,这些规律是用拥有特定关系的词对所对应的两个向量的差来表示的。例如,假设我们把单词i对应的向量记为Vi,那么对于表示单复数这个维度上的数值K来说应该有:applesk – applek ≈ carsk – cark, ≈ familiesk – familyk .可能更让人惊讶的是,我们发现在2012年的SemEval关系相似度测量任务中,各种各样的语义(语义:这个单词是什么意思)关系都可以有上述所说的性质。
The vectors are very good at answering analogy questions of the form a is to b as c is to ?. For example, man is to woman as uncle is to ? (aunt) using a simple vector offset method based on cosine distance.
这样的向量非常适合于分析“a对应b,那么c对应什么”这样的分析性问题。例如,如果男人对应女人,那么伯父应该对应什么?(伯母)
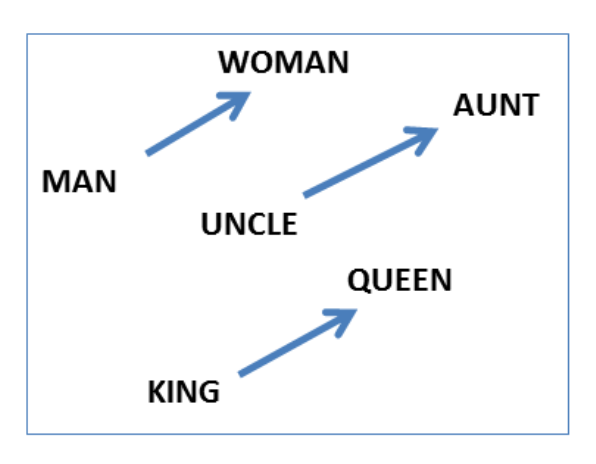
For example, here are vector offsets for three word pairs illustrating the gender relation:
如下图所示,图中用向量的差(相对偏移量)表示了三个词对之间的性别关系。
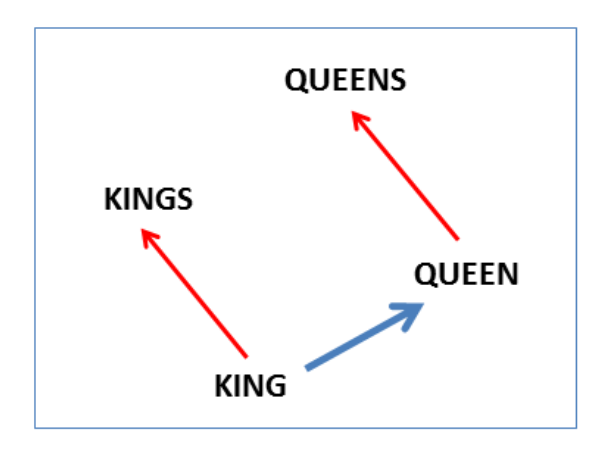
And here we see the singular plural relation:
另外还有单复数的关系:
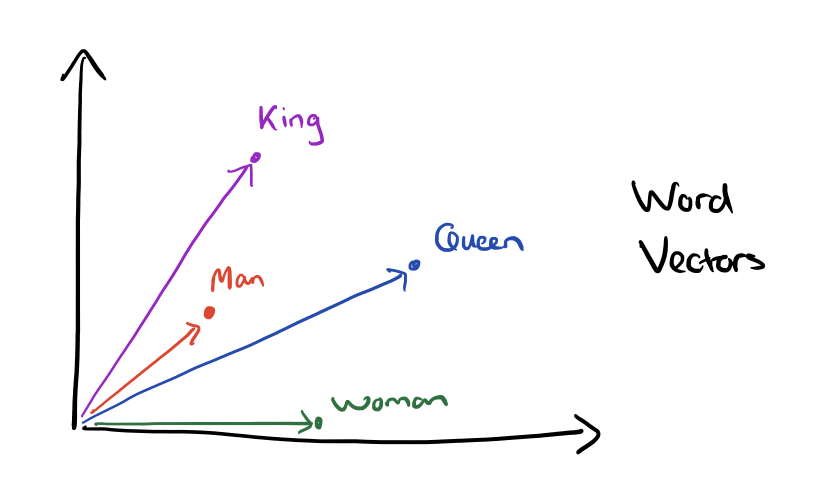
This kind of vector composition also lets us answer “King – Man + Woman = ?” question and arrive at the result “Queen” !
上图所展示的向量有助于我们回答“国王-男人+女士=?”的问题,另外答案就是“女王”。
利用词向量进行推理(Reasoning with word vectors)的更多相关文章
- NLP(二十) 利用词向量实现高维词在二维空间的可视化
准备 Alice in Wonderland数据集可用于单词抽取,结合稠密网络可实现其单词的可视化,这与编码器-解码器架构类似. 代码 from __future__ import print_fun ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)
R语言由于效率问题,实现自然语言处理的分析会受到一定的影响,如何提高效率以及提升词向量的精度是在当前软件环境下,比较需要解决的问题. 笔者认为还存在的问题有: 1.如何在R语言环境下,大规模语料提高运 ...
- PyTorch基础——词向量(Word Vector)技术
一.介绍 内容 将接触现代 NLP 技术的基础:词向量技术. 第一个是构建一个简单的 N-Gram 语言模型,它可以根据 N 个历史词汇预测下一个单词,从而得到每一个单词的向量表示. 第二个将接触到现 ...
- 词向量word2vec(图学习参考资料)
介绍词向量word2evc概念,及CBOW和Skip-gram的算法实现. 项目链接: https://aistudio.baidu.com/aistudio/projectdetail/500940 ...
- 【CS224n-2019学习笔记】Lecture 1: Introduction and Word Vectors
附上斯坦福cs224n-2019链接:https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/ 文章目录 1.课程简单介绍 1.1 本 ...
- 词向量 词嵌入 word embedding
词嵌入 word embedding embedding 嵌入 embedding: 嵌入, 在数学上表示一个映射f:x->y, 是将x所在的空间映射到y所在空间上去,并且在x空间中每一个x有y ...
- Word Representations 词向量
常用的词向量方法word2vec. 一.Word2vec 1.参考资料: 1.1) 总览 https://zhuanlan.zhihu.com/p/26306795 1.2) 基础篇: 深度学习wo ...
- 词袋模型(BOW,bag of words)和词向量模型(Word Embedding)概念介绍
例句: Jane wants to go to Shenzhen. Bob wants to go to Shanghai. 一.词袋模型 将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个 ...
随机推荐
- SpringCloud微服务实战——搭建企业级开发框架(三十五):SpringCloud + Docker + k8s实现微服务集群打包部署-集群环境部署
一.集群环境规划配置 生产环境不要使用一主多从,要使用多主多从.这里使用三台主机进行测试一台Master(172.16.20.111),两台Node(172.16.20.112和172.16.20.1 ...
- 使用.NET 6开发TodoList应用(7)——使用AutoMapper实现GET请求
系列导航 使用.NET 6开发TodoList应用文章索引 需求 需求很简单:实现GET请求获取业务数据.在这个阶段我们经常使用的类库是AutoMapper. 目标 合理组织并使用AutoMapper ...
- C++之面试题(4)
题目描述 来源:牛客网 对于一个有序数组,我们通常采用二分查找的方式来定位某一元素,请编写二分查找的算法,在数组中查找指定元素. 给定一个整数数组A及它的大小n,同时给定要查找的元素val,请返回它在 ...
- c++内存分布之虚函数(单一继承)
系列 c++内存分布之虚函数(单一继承) [本文] c++内存分布之虚函数(多继承) 结论 1.虚函数表指针 和 虚函数表 1.1 影响虚函数表指针个数的因素只和派生类的父类个数有关.多一个父类,派生 ...
- c++之可变参数格式化字符串(c++11可变模板参数)
本文将使用 泛型 实现可变参数. 涉及到的关见函数: std::snprintf 1.一个例子 函数声明及定义 1 // 泛型 2 template <typename... Args> ...
- 【LeetCode】469. Convex Polygon 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 计算向量夹角 日期 题目地址:https://leet ...
- 【LeetCode】119. 杨辉三角 II Pascal‘s Triangle II(Python & Java)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题思路 方法一: 空间复杂度 O ( k ∗ ( k + 1 ...
- 【LeetCode】114. Flatten Binary Tree to Linked List 解题报告(Python & C++ & Java)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 先序遍历 递归 日期 题目地址:https://le ...
- 晴天小猪历险记之Hill(Dijkstra优先队列优化)
描述 这一天,他来到了一座深山的山脚下,因为只有这座深山中的一位隐者才知道这种药草的所在.但是上山的路错综复杂,由于小小猪的病情,晴天小猪想找一条需时最少的路到达山顶,但现在它一头雾水,所以向你求助. ...
- Pikachu漏洞练习-SQL-inject(三)