mysql表设计原则
0.三大范式及反范式
1.适度冗余, 让query尽量减少join
2. 大字段垂直分拆
3. 大表水平分拆
4.选择合适的数据类型


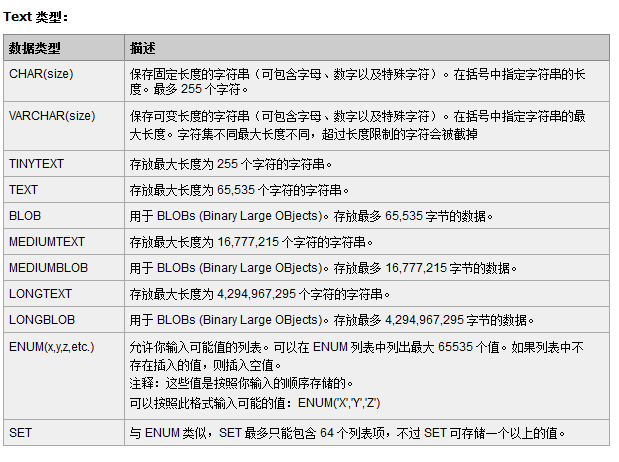
mysql表设计原则的更多相关文章
- mySql 数据库设计原则
mysql数据库设计原则: 必须使用InnoDB存储引擎 解读:支持事务.行级锁.并发性能更好.CPU及内存缓存页优化使得资源利用率更高 禁止使用存储过程.视图.触发器.Event 解读:高并发大数据 ...
- mysql表设计注意点
[原创]面试官:讲讲mysql表设计要注意啥 需要设计一个主键 因为你不设主键的情况下,innodb也会帮你生成一个隐藏列,作为自增主键.所以啦,反正都要生成一个主键,那你还不如自己指定一个主键,在有 ...
- 面试mysql表设计要注意啥
面试官:讲讲mysql表设计要注意啥? 引言 大家应该知道烟哥最近要(tiao 咳咳咳),嗯,不可描述! 随手讲其中一部分知识,都是一些烟哥自己平时工作的总结以及经验.大家看完,其实能避开很多坑.而且 ...
- mysql数据库关系表设计原则
三范式https://blog.csdn.net/qq_36432666/article/details/78934073 https://kb.cnblogs.com/page/138526/ ht ...
- 【转】Mysql索引设计原则
来源:https://segmentfault.com/a/1190000000473085 假设一高频查询如下SELECT * FROM user WHERE area='amoy' AND sex ...
- 【原创】面试官:讲讲mysql表设计要注意啥
引言 近期由于复习了一下mysql的内容,有些心得.随手讲其中一部分知识,都是一些烟哥自己平时工作的总结以及经验.大家看完,其实能避开很多坑.而且很多问题,都是面试中实打实会问到的! 比如 OK,具体 ...
- <转载>面试官: 讲讲MySql表设计需要注意什么?
作者:孤独烟 出处: http://rjzheng.cnblogs.com/ 综述 近期由于复习了一下MySQL的内容看到一篇比较好的文章,转载分享一下.大家看完,其实能避开很多坑.而且很多问题,都是 ...
- mysql表设计
model表 记录网站模块:如视频,音频,调查,01发布内容时.可以指定发布到哪个模块下02可以统计每个模块的访问量设计表注意点01主键不要用id (全部使用 当前表名+id 如modelid)02n ...
- 【MySQL】MySQL表设计的常用数据类型
整数类型,tinyint.smallint.mediumint.int.bigint 如果需要保存整数(不含小数),可以选择tinyint.smallint.mediumint.int.bigint, ...
随机推荐
- JS使用html()获取html代码获取不到input、textarea控件填写的值
我们可以重写一个方法 (function ($) { var oldHTML = $.fn.html; $.fn.formhtml = function () { if (arguments.leng ...
- 【LeetCode】191. Number of 1 Bits 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 右移32次 计算末尾的1的个数 转成二进制统计1的个 ...
- window11连接局域网共享失败处理办法
第一步1.按 Win + R 组合键,打开运行,并输入:gpedit.msc 命令,确定或回车,可以快速打开本地组策略编辑器2.本地组策略编辑器窗口中,依次展开到:计算机配置 - 管理模板 - 网络 ...
- 第九个知识点:香农(Shannon)定义的熵和信息是什么?
第九个知识点:香农(Shannon)定义的熵和信息是什么 这是计算机理论的最后一篇.我们讨论信息理论的基础概念,什么是香农定义的熵和信息. 信息论在1948年被Claude E.Shannon建立.信 ...
- The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization (DeepAugment)
目录 概 主要内容 ImageNet-R StreetView StoreFronts (SVSF) DeepFashion Remixed DeepAugment 实验结论 代码 Hendrycks ...
- BP网络简单实现
目录 BP算法的简单实现 Linear 全连接层 ReLu MSELoss 交叉熵损失函数 BP算法的简单实现 """ BPnet 简易实现 约定输入数据维度为(N, i ...
- java 语言基础作业
1.动手动脑 仔细阅读示例: EnumTest.java,运行它,分析运行结果? 程序运行结果: 实验结论:枚举类型是引用类型!枚举不属于原始数据类型,它的每个具体值都引用一个特定的对象.相同的值则引 ...
- 基于Spring MVC + Spring + MyBatis的【图书信息管理系统(一)】
资源下载:https://download.csdn.net/download/weixin_44893902/34867237 练习点设计:模糊查询.删除.新增 一.语言和环境 1.实现语言:JAV ...
- Android物联网应用程序开发(智慧城市)—— 用户注册界面开发
效果: 布局代码: <?xml version="1.0" encoding="utf-8"?> <RelativeLayout xmlns: ...
- .NET5.0 依赖注入,关于 Autofac 使用
前置 工具 VS2019 概念 关于以下几个概念,自行百度. 控制反转:IoC(Inversion of Control) 依赖注入: 容器:DI 容器(.NET Core 自带),Autofac(本 ...