kafka初认识(一)
首先贴出官网地址:https://kafka.apache.org/
一、 简介
Kafka 是 linkedin 使用 Scala 编写具有高水平扩展和高吞吐量的分布式消息系统。Kafka 对消息保存时根据 Topic 进行归类,发送消息者成为 Producer ,消息接受者成为 Consumer ,此外 kafka 集群有多个 kafka 实例组成,每个实例(server)称为 broker。无论是 Kafka集群,还是 producer 和 consumer 都依赖于 zookeeper 来保证系统可用性,为集群保存一些 meta 信息。(但新版本除外,不用依赖zookeeper)
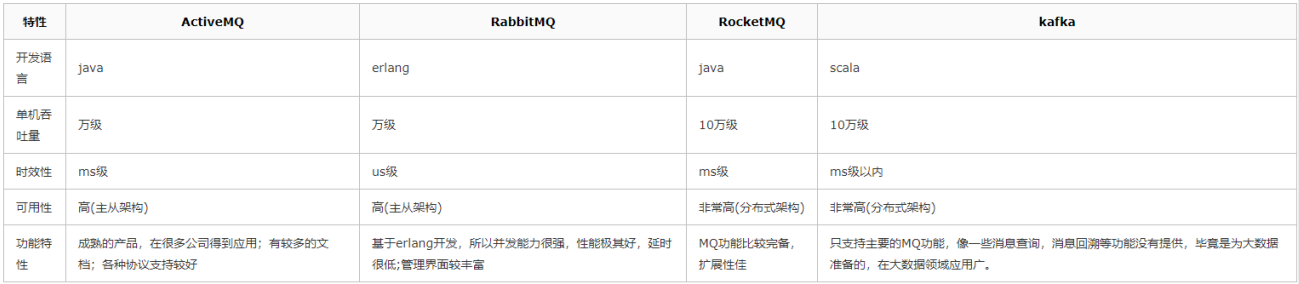
二、常用MQ性能对比
三、kafa主要功能
Apache Kafka 是 一个分布式流处理平台
流处理平台特性
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
Kafka 适合什么样的场景
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于消息队列)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。
四、kafa相关概念
AMQP (Advanced Message Queuing Protocol) ,是一个提供统一消息服务的标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件而设计。

一些基本的概念:
AMQP服务器端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列
消费者(Consumer):从消息队列中请求消息的客户端应用程序
生产者(Producer):向 broker 发布消息的客户端应用程序
Topics 和 Logs
Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka 中的 Topics 总是多订阅者模式,一个 topic 可以拥有一个或者多个消费者来订阅它的数据。对于每一个topic,Kafka集群都会维持一个分区日志,如图所示:
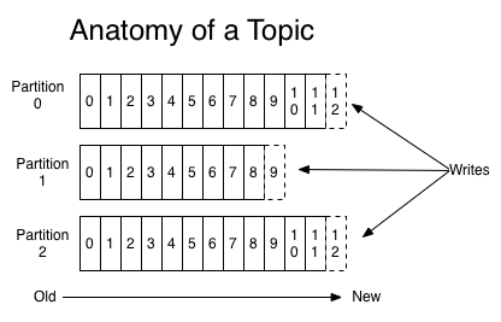
Partition
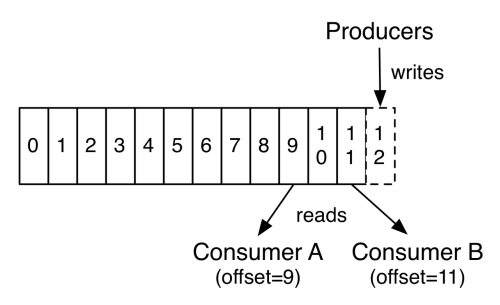
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。Kafka集群保持所有的消息,直到它们过期, 无论消息是否被消费了。 实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。 可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。kafka 并没有提供其他额外的索引机制来存储 offset,因为在 kafka 中几乎不允许对消息进行“随机读写”。再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元
Distribution
Log 的分区被分布到集群中的多个服务器上,每个服务器处理它分到的分区, 根据配置每个分区还可以复制到其它服务器作为备份容错。每个分区有一个 leader,零或多个 follower。Leader 处理此分区的所有的读写请求,而 follower 被动的复制数据。如果 leader 宕机,其它的一个 follower 会被推举为新的 leader。 一台服务器可能同时是一个分区的 leader,另一个分区的 follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
Producers
生产者往某个Topic上发布消息,生产者也负责选择发布到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择,也可以根据某种算法依照权重选择分区。开发者负责如何选择分区的算法。
Consumers
消费者使用一个消费组名称来进行标识,发布到 topic 中的每条记录被分配给订阅消费组中的一个消费者实例。消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例。
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程。
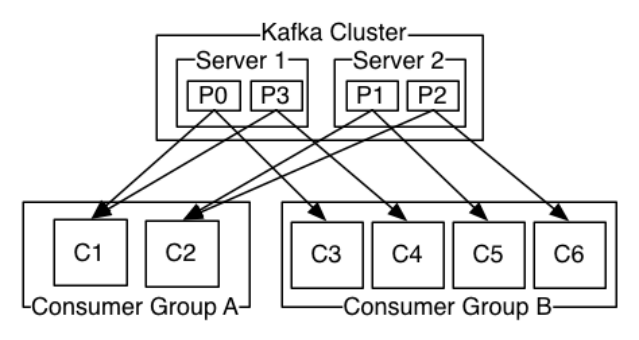
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者
"。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
Replication
每个partition还会被复制到其它服务器作为replication,这是一种冗余备份策略

- 同一个partition的多个replication不允许在同一broker上
- 每个partition的replication中,有一个leader ,零或多个follower
- leader处理此分区的所有的读写请求, follower仅仅被动的复制数据
- leader宕机后,会从follower中选举出新的leader
四个核心 API
- Producer API:允许一个应用程序发布一串流式的数据到一个或者多个 Kafka topic。
- Consumer API:允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- Streams API:允许一个应用程序作为一个流处理器,消费一个或者多个 topic 产生的输入流,然后生产一个输出流到一个或多个 topic 中去,在输入输出流中进行有效的转换。
- Connector API:允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
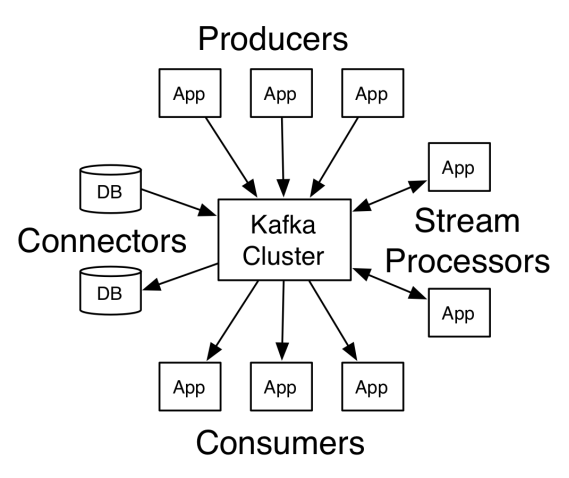
在Kafka中,客户端和服务器之间的通信是通过简单,高性能,语言无关的TCP协议完成的。此协议已版本化并保持与旧版本的向后兼容性。Kafka提供多种语言客户端。
kafka API - producer

Properties props = new Properties();
props.put("batch.size",16384); //默认值为16384
props.put("linger.ms",16384); //默认值为0
props.put("acks", "all");
props.put("retries",1);
//... Producer<String, String> producer = new KafkaProducer(props);
ProducerRecord<String, String> record =new ProducerRecord<String, String>("my-topic", "key", "value");
producer.send(record);
producer.close();
- Producer会为每个partition维护一个缓冲,用来记录还没有发送的数据,每个缓冲区大小用 batch.size指定,默认值为16k.
- linger.ms为,buffer中的数据在达到batch.size前,需要等待的时间
- acks用来配置请求成功的标准
kafka API - consumer
Kafka Simple Consumer
Simple Cnsumer 位于kafka.javaapi.consumer包中,不提供负载均衡、容错的特性每次获取数据都要指定topic、partition、offset、fetchSize
High-level Consumer
该客户端透明地处理kafka broker异常,透明地切换consumer的partition,通过和broker交互来实现consumer group级别的负载均衡。
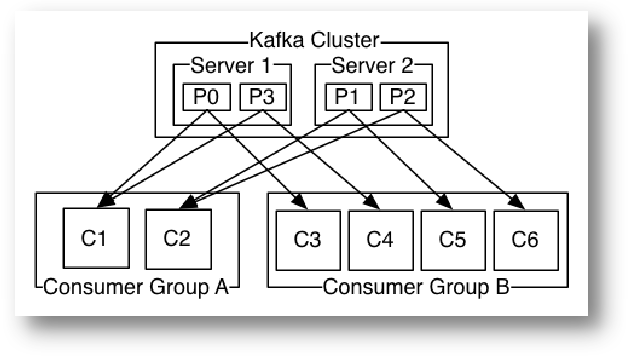
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
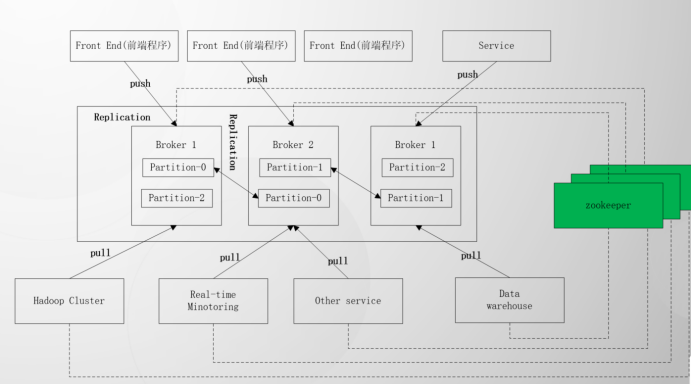
五、kafa整体架构
kafka初认识(一)的更多相关文章
- 【Spark深入学习 -15】Spark Streaming前奏-Kafka初体验
----本节内容------- 1.Kafka基础概念 1.1 出世背景 1.2 基本原理 1.2.1.前置知识 1.2.2.架构和原理 1.2.3.基本概念 1.2.4.kafka特点 2.Kafk ...
- Kafka初入门简单配置与使用
一 Kafka概述 1.1 Kafka是什么 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算. 1)Apache Kafka是一个开源消息系统,由Scala写成. ...
- 一、Kafka初认识
一.kafka使用背景 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我 ...
- Filebeat+Kafka+Logstash+ElasticSearch+Kibana搭建完整版
1. 了解各个组件的作用 Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读) Kafka ...
- Hadoop生态圈-Kafka的本地模式部署
Hadoop生态圈-Kafka的本地模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Kafka简介 1>.什么是JMS 答:在Java中有一个角消息系统的东西,我 ...
- Docker实战之Kafka集群
1. 概述 Apache Kafka 是一个快速.可扩展的.高吞吐.可容错的分布式发布订阅消息系统.其具有高吞吐量.内置分区.支持数据副本和容错的特性,适合在大规模消息处理场景中使用. 笔者之前在物联 ...
- Kafka(一)-- 初体验
一.概念 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素. 这些 ...
- Storm+kafka的HelloWorld初体验
从16年4月5号开始学习kafka,后来由于项目需要又涉及到了storm. 经过几天的扫盲,到今天16年4月13日,磕磕碰碰的总算是写了一个kafka+storm的HelloWorld的例子. 为了达 ...
- kafka 学习之初体验
学习问题: 1.kafka是否需要zookeeper?2.kafka是什么?3.kafka包含哪些概念?4.如何模拟客户端发送.接受消息初步测试?(kafka安装步骤)5.kafka cluster怎 ...
随机推荐
- VS2017 Debug时候出现 Script Error An error has occurred in the script on this page. 解决办法
解决办法: Menu -> Debug -> Options -> Debugging/General -> 取消最后面的Enable Diagnostic Tools whi ...
- MySQL binlog 自动清理脚本
# vim /data/scripts/delete_mysql_binlog.sh 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ...
- inotify与rsync实现实时同步记录文档
目录 安装 配置 参考链接 安装 安装rsync yum -y install rsync 安装inotify-tools 这是一个实时监听文件变换的工具 wget -O /etc/yum.repos ...
- SpringBoot - 搭建静态资源存储服务器
目录 前言 环境 实现效果 具体实现 文件上传 配置类 上传接口 上传实现 辅助类 实体 上传测试 文件访问 配置类 项目源码 前言 记录下SpringBoot下静态资源存储服务器的搭建. 环境 wi ...
- Robot Framework(7)- DateTime 测试库常用的关键字列表
如果你还想从头学起Robot Framework,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1770899.html 前言 所有关键字 ...
- 通过JDK动态代理实现 Spring AOP
1.新建一个目标类 接口:public interface IUserService //切面编程 public void addUser(); public void updateUser( ); ...
- 第05课:GDB 常用命令详解(上)
本课的核心内容如下: run 命令 continue 命令 break 命令 backtrace 与 frame 命令 info break.enable.disable 和 delete 命令 li ...
- 一文了解Promise使用与实现
前言 Promise 作为一个前端必备技能,不管是从项目应用还是面试,都应该对其有所了解与使用. 常常遇到的面试五连问: 说说你对 Promise 理解? Promise 的出现解决了什么问题? Pr ...
- Linux安装Cockpit监控服务
CentOS/RHEL 8的新特性之一就是自带了一个cockpit的监控服务.通过c/s架构模式运行,客户端输入ip:端口即可访问 这类似于glances监控. 如果你不是使用的centos/rhel ...
- Python与Mysql 数据库的连接,以及查询。
python与mysql数据库的连接: pymysql是python中对数据库的连接模块:因此应当首先安装pymysql数据库模块. 执行pip install pymysql 命令. 然后在pyth ...