python爬取ip地址
ip查询,异步get请求
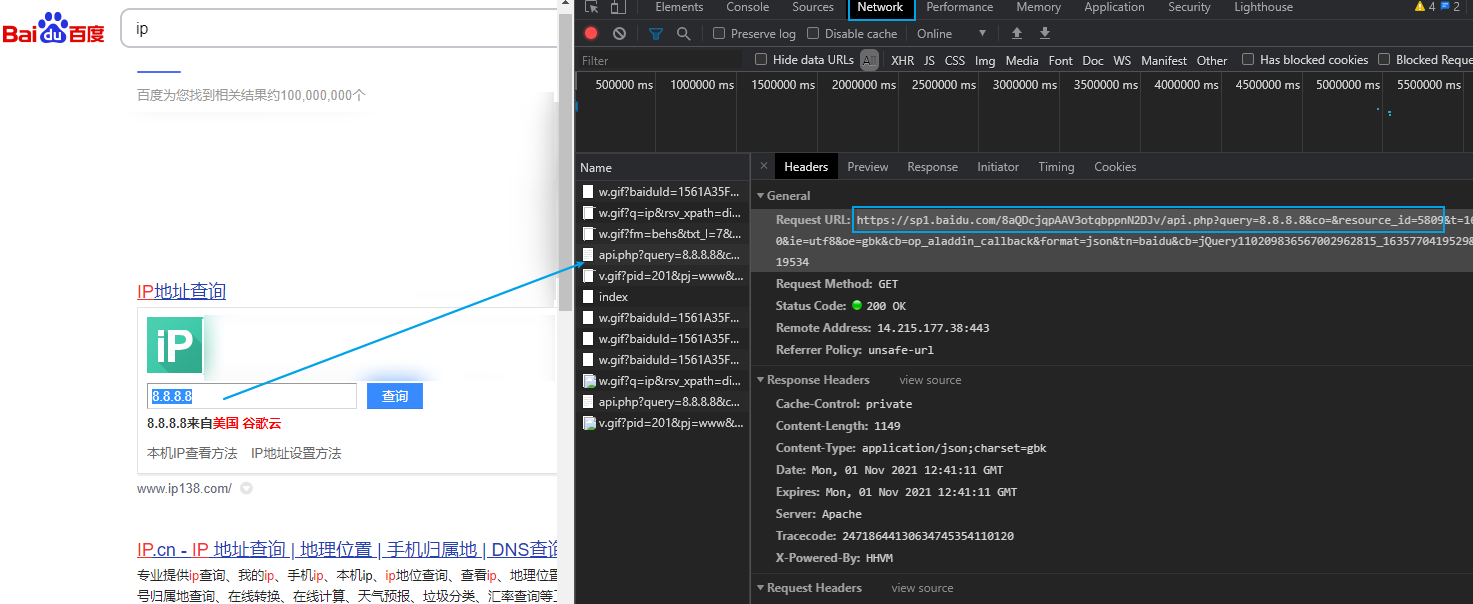
分析接口,请求接口响应json

发现可以data中获取 result.json()['data'][0]['location']
- # _*_ coding : utf-8 _*_
- # @Time : 2021/11/1 20:29
- # @Author : 秋泊酱
- # @File : ip抓取
- import requests
- ips = ['8.8.8.8']
- result = requests.get('https://sp1.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query='+ips[0]+'&co=&resource_id=5809',verify = False)
- print(result.json()['data'][0]['location'])

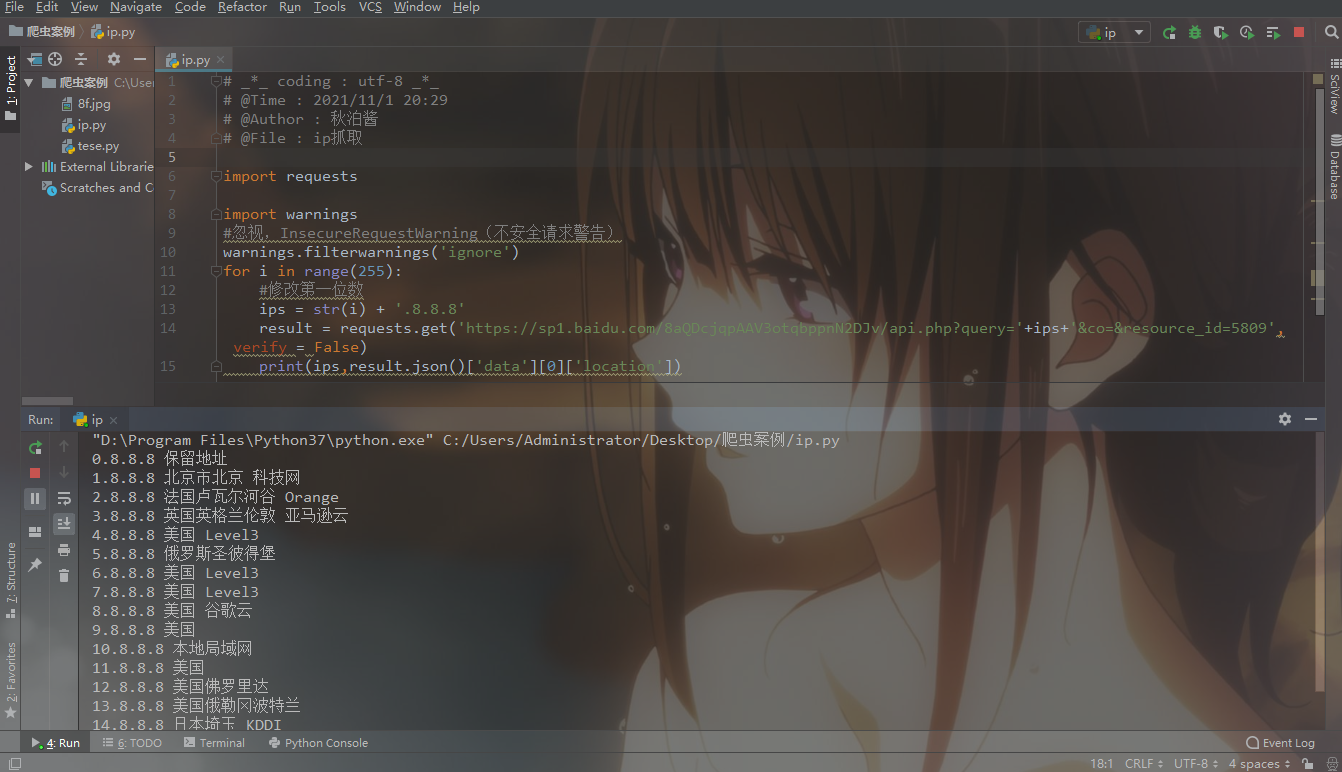
for构造255个ip池演示
- # _*_ coding : utf-8 _*_
- # @Time : 2021/11/1 20:29
- # @Author : 秋泊酱
- # @File : ip抓取
- import requests
- import warnings
- #忽视,InsecureRequestWarning(不安全请求警告)
- warnings.filterwarnings('ignore')
- for i in range(255):
- #修改第一位数
- ips = str(i) + '.8.8.8'
- result = requests.get('https://sp1.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query='+ips+'&co=&resource_id=5809',verify = False)
- print(ips,result.json()['data'][0]['location'])
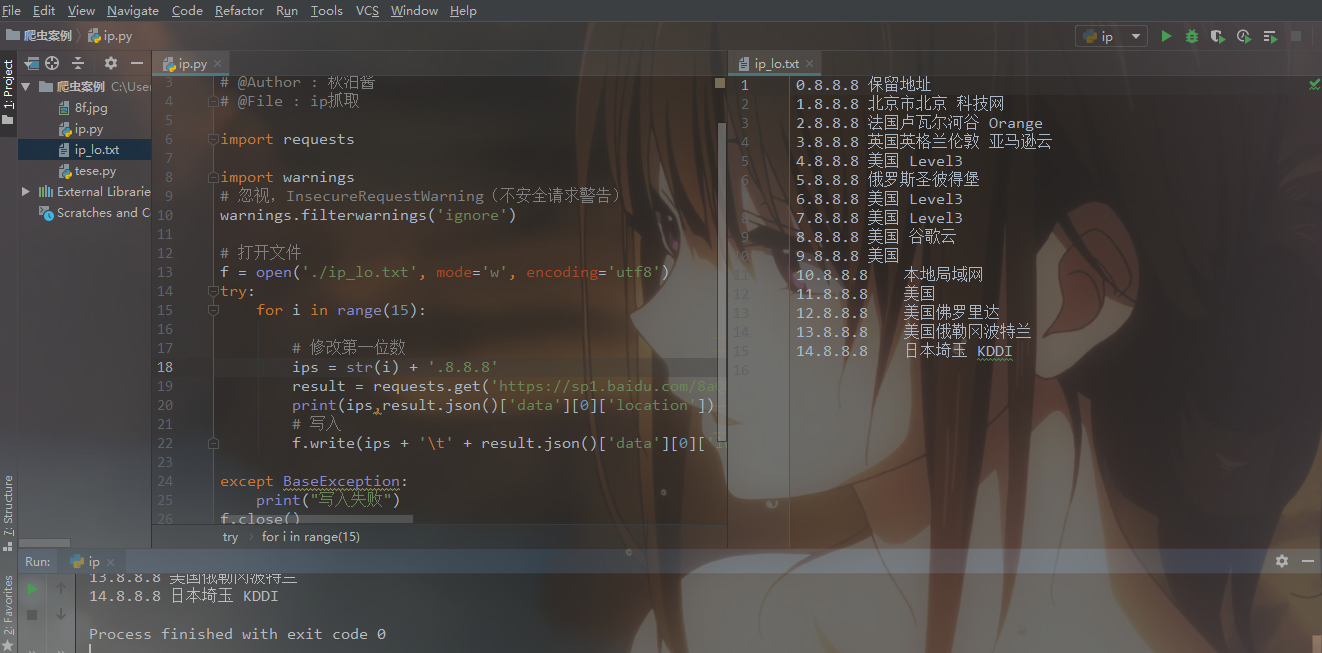
写入txt中
- # _*_ coding : utf-8 _*_
- # @Time : 2021/11/1 20:29
- # @Author : 秋泊酱
- # @File : ip爬取
- import requests
- import warnings
- # 忽视,InsecureRequestWarning(不安全请求警告)
- warnings.filterwarnings('ignore')
- # 打开文件
- f = open('./ip_lo.txt', mode='w', encoding='utf8')
- try:
- for i in range(15):
- # 修改第一位数
- ips = str(i) + '.8.8.8'
- result = requests.get('https://sp1.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query='+ips+'&co=&resource_id=5809',verify = False)
- print(ips,result.json()['data'][0]['location'])
- # 写入
- f.write(ips + '\t' + result.json()['data'][0]['location'] + '\n')
- except BaseException:
- print("写入失败")
- f.close()
python爬取ip地址的更多相关文章
- python Requests库网络爬取IP地址归属地的自动查询
#IP地址查询全代码import requestsurl = "http://m.ip138.com/ip.asp?ip="try: r = requests.get(url + ...
- Python练习:爬虫练习,从一个提供免费代理的网站中爬取IP地址信息
西刺代理,http://www.xicidaili.com/,提供免费代理的IP,是爬虫程序的目标网站. 开始写程序 import urllib.requestimport re def open_u ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- Python爬取微信小程序(Charles)
Python爬取微信小程序(Charles) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90045204 一.前言 最近需要获取微信小 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
随机推荐
- 感恩笔记之SQL查询功能最简使用模板
感恩笔记之SQL查询功能最简使用模板 第一部分:SQL单表功能 1 语句主要关键字 SELECT --查询数据列 INTO --新建数据表 FROM --查询数据表 WHERE --筛选数据表结果 O ...
- Ubuntu 20.04上安装MySQL教程,ubuntu安装mysql
在Ubuntu 20.04上安装MySQL教程 先决条件 确保您以具有sudo特权的用户身份登录. 在Ubuntu上安装MySQL 在撰写本文时,Ubuntu存储库中可用的MySQL的最新版本是MyS ...
- 10.2 PHP
WEB资源类型 静态资源:原始形式与响应内容一致,在客户端浏览器执行 动态资源:原始形式通常为程序文件,需要在服务器端执行之后,将执行结果返回给客户端 WEB相关语言 客户端技术:html JavaS ...
- react之组建通信
父组件与子组件通信 父组件将自己的状态传递给子组件,子组件当做属性来接收,当父组件更改自己状态的时候,子组件接收到的属性就会发生改变 父组件利用ref对子组件做标记,通过调用子组件的方法以更改子组件的 ...
- 洛谷3317 SDOI2014重建(高斯消元+期望)
qwq 一开始想了个错的做法. 哎 直接开始说比较正确的做法吧. 首先我们考虑题目的\(ans\)该怎么去求 我们令\(x\)表示原图中的某一条边 \[ans = \sum \prod_{x\in t ...
- WPF实现Win10汉堡菜单
WPF开发者QQ群: 340500857 | 微信群 -> 进入公众号主页 加入组织 前言 有小伙伴提出需要实现Win10汉堡菜单效果. 由于在WPF中没有现成的类似UWP的汉堡菜单,所以我们 ...
- PAT (Basic Level) Practice (中文)1026 程序运行时间 (15分)
1026 程序运行时间 (15分) 要获得一个 C 语言程序的运行时间,常用的方法是调用头文件 time.h,其中提供了 clock() 函数,可以捕捉从程序开始运行到 clock() 被调用时所耗费 ...
- 从零到熟悉,带你掌握Python len() 函数的使用
摘要:本文为你带来如何找到长度内置数据类型的使用len() 使用len()与第三方数据类型 提供用于支持len()与用户定义的类. 本文分享自华为云社区<在 Python 中使用 len() 函 ...
- go-zero 实战之 blog 系统
go-zero 实战项目:blog 本文以 blog 的网站后台为例,着重介绍一下如何使用 go-zero 开发 blog 的用户模块. 本文涉及的所有资料都已上传 github 仓库 kougazh ...
- [技术博客]OKhttp3使用get,post,delete,patch四种请求
OKhttp3使用get,post,delete,patch四种请求 1.okhttp简介 okhttp封装了大量http操作,大大简化了安卓网络请求操作,是现在最火的安卓端轻量级网络框架.如今okh ...