Sql 语句中 IN 和 EXISTS 的区别及应用
演示demo表:
student表
- DROP TABLE IF EXISTS `student`;
- CREATE TABLE `student` (
- `stuid` varchar(16) NOT NULL COMMENT '学号',
- `stunm` varchar(20) NOT NULL COMMENT '学生姓名',
- PRIMARY KEY (`stuid`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- -- ----------------------------
- -- Records of student
- -- ----------------------------
- INSERT INTO `student` VALUES ('1001', '张三');
- INSERT INTO `student` VALUES ('1002', '李四');
- INSERT INTO `student` VALUES ('1003', '赵二');
- INSERT INTO `student` VALUES ('1004', '王五');
- INSERT INTO `student` VALUES ('1005', '刘青');
- INSERT INTO `student` VALUES ('1006', '周明');
- INSERT INTO `student` VALUES ('1007', '吴七');
score表
- DROP TABLE IF EXISTS `score`;
- CREATE TABLE `score` (
- `stuid` varchar(16) NOT NULL,
- `courseno` varchar(20) NOT NULL,
- `scores` float DEFAULT NULL,
- PRIMARY KEY (`stuid`,`courseno`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- -- ----------------------------
- -- Records of score
- -- ----------------------------
- INSERT INTO `score` VALUES ('1001', 'C001', '67');
- INSERT INTO `score` VALUES ('1001', 'C002', '87');
- INSERT INTO `score` VALUES ('1001', 'C003', '83');
- INSERT INTO `score` VALUES ('1001', 'C004', '88');
- INSERT INTO `score` VALUES ('1001', 'C005', '77');
- INSERT INTO `score` VALUES ('1001', 'C006', '77');
- INSERT INTO `score` VALUES ('1002', 'C001', '68');
- INSERT INTO `score` VALUES ('1002', 'C002', '88');
- INSERT INTO `score` VALUES ('1002', 'C003', '84');
- INSERT INTO `score` VALUES ('1002', 'C004', '89');
- INSERT INTO `score` VALUES ('1002', 'C005', '78');
- INSERT INTO `score` VALUES ('1002', 'C006', '78');
- INSERT INTO `score` VALUES ('1003', 'C001', '69');
- INSERT INTO `score` VALUES ('1003', 'C002', '89');
- INSERT INTO `score` VALUES ('1003', 'C003', '85');
- INSERT INTO `score` VALUES ('1003', 'C004', '90');
- INSERT INTO `score` VALUES ('1003', 'C005', '79');
- INSERT INTO `score` VALUES ('1003', 'C006', '79');
- INSERT INTO `score` VALUES ('1004', 'C001', '70');
- INSERT INTO `score` VALUES ('1004', 'C002', '90');
- INSERT INTO `score` VALUES ('1004', 'C003', '86');
- INSERT INTO `score` VALUES ('1004', 'C004', '91');
- INSERT INTO `score` VALUES ('1004', 'C005', '80');
- INSERT INTO `score` VALUES ('1004', 'C006', '80');
- INSERT INTO `score` VALUES ('1005', 'C001', '71');
- INSERT INTO `score` VALUES ('1005', 'C002', '91');
- INSERT INTO `score` VALUES ('1005', 'C003', '87');
- INSERT INTO `score` VALUES ('1005', 'C004', '92');
- INSERT INTO `score` VALUES ('1005', 'C005', '81');
- INSERT INTO `score` VALUES ('1005', 'C006', '81');
- INSERT INTO `score` VALUES ('1006', 'C001', '72');
- INSERT INTO `score` VALUES ('1006', 'C002', '92');
- INSERT INTO `score` VALUES ('1006', 'C003', '88');
- INSERT INTO `score` VALUES ('1006', 'C004', '93');
- INSERT INTO `score` VALUES ('1006', 'C005', '82');
- INSERT INTO `score` VALUES ('1006', 'C006', '82');
course表
- DROP TABLE IF EXISTS `courses`;
- CREATE TABLE `courses` (
- `courseno` varchar(20) NOT NULL,
- `coursenm` varchar(100) NOT NULL,
- PRIMARY KEY (`courseno`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='课程表';
- -- ----------------------------
- -- Records of courses
- -- ----------------------------
- INSERT INTO `courses` VALUES ('C001', '大学语文');
- INSERT INTO `courses` VALUES ('C002', '新视野英语');
- INSERT INTO `courses` VALUES ('C003', '离散数学');
- INSERT INTO `courses` VALUES ('C004', '概率论与数理统计');
- INSERT INTO `courses` VALUES ('C005', '线性代数');
- INSERT INTO `courses` VALUES ('C006', '高等数学(一)');
- INSERT INTO `courses` VALUES ('C007', '高等数学(二)');
IN 语句:只执行一次
确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
具体sql示例:
SQL语句执行顺序详见:https://blog.csdn.net/wqc19920906/article/details/79411854
1、select * from student s where s.stuid in(select stuid from score ss where ss.stuid = s.stuid)执行结果:
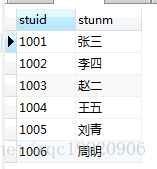
2、 select * from student s where s.stuid in(select stuid from score ss where ss.stuid <1005)执行结果:
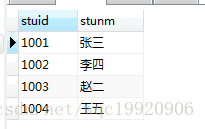
以上两个语句的执行流程:
首先会执行from语句找出student表,然后执行 in 里面的子查询,再然后将查询到的结果和原有的user表做一个笛卡尔积,再根据我们的student.stuid IN score.stuid的条件,将结果进行筛选(既比较stuid列的值是否相等,将不相等的删除)。最后,得到符合条件的数据。
EXISTS语句:执行student.length次
指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
具体示例:
select * from student s where EXISTS(select stuid from score ss where ss.stuid = s.stuid)这条sql语句的执行结果和上面的in的第一条执行结果是一样的。
但是,不一样的是它们的执行流程完全不一样:
使用exists关键字进行查询的时候,首先,我们先查询的不是子查询的内容,而是查我们的主查询的表,也就是说,我们先执行的sql语句是:
select * from student s结果为:
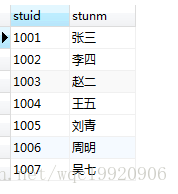
然后,根据表的每一条记录,执行以下语句,依次去判断where后面的条件是否成立:
EXISTS(select stuid from score ss where ss.stuid = s.stuid)如果成立则返回true不成立则返回false。如果返回的是true的话,则该行结果保留,如果返回的是false的话,则删除该行,最后将得到的结果返回。
区别及应用场景
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
以下为转载内容
原理解析补充:
select * from A
where id in(select id from B)
以上查询使用了in语句,in()只执行一次,它查出B表中的所有id字段并缓存起来.之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录.
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A);
Array B=(select id from B);
for(int i=0;i<A.length;i++) {
for(int j=0;j<B.length;j++) {
if(A[i].id==B[j].id) {
resultSet.add(A[i]);
break;
}
}
}
return resultSet;
可以看出,当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次.
如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差.
再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升.
结论:in()适合B表比A表数据小的情况
select a.* from A a
where exists(select 1 from B b where a.id=b.id)
以上查询使用了exists语句,exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false.
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A)
for(int i=0;i<A.length;i++) {
if(exists(A[i].id) { //执行select 1 from B b where b.id=a.id是否有记录返回
resultSet.add(A[i]);
}
}
return resultSet;
当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行.
如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等.
如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果.
再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
结论:exists()适合B表比A表数据大的情况
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.
比如在Northwind数据库中有一个查询为
SELECT c.CustomerId,CompanyName FROM Customers c
WHERE EXISTS(
SELECT OrderID FROM Orders o WHERE o.CustomerID=c.CustomerID)
这里面的EXISTS是如何运作呢?子查询返回的是OrderId字段,可是外面的查询要找的是CustomerID和CompanyName字段,这两个字段肯定不在OrderID里面啊,这是如何匹配的呢?
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
EXISTS 指定一个子查询,检测 行 的存在。
语法: EXISTS subquery
参数: subquery 是一个受限的 SELECT 语句 (不允许有 COMPUTE 子句和 INTO 关键字)。
结果类型: Boolean 如果子查询包含行,则返回 TRUE ,否则返回 FLASE 。
| 例表A:TableIn | 例表B:TableEx |
 |
 |
(一). 在子查询中使用 NULL 仍然返回结果集
select * from TableIn where exists(select null)
等同于: select * from TableIn
(二). 比较使用 EXISTS 和 IN 的查询。注意两个查询返回相同的结果。
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
select * from TableIn where ANAME in(select BNAME from TableEx)
(三). 比较使用 EXISTS 和 = ANY 的查询。注意两个查询返回相同的结果。
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
select * from TableIn where ANAME=ANY(select BNAME from TableEx)
NOT EXISTS 的作用与 EXISTS 正好相反。如果子查询没有返回行,则满足了 NOT EXISTS 中的 WHERE 子句。
结论:
EXISTS(包括
NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS内部有一个子查询语句(SELECT ... FROM...),
我将其称为EXIST的内查询语句。其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。
一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
分析器会先看语句的第一个词,当它发现第一个词是SELECT关键字的时候,它会跳到FROM关键字,然后通过FROM关键字找到表名并把表装入内存。接着是找WHERE关键字,如果找不到则返回到SELECT找字段解析,如果找到WHERE,则分析其中的条件,完成后再回到SELECT分析字段。最后形成一张我们要的虚表。
WHERE关键字后面的是条件表达式。条件表达式计算完成后,会有一个返回值,即非0或0,非0即为真(true),0即为假(false)。同理WHERE后面的条件也有一个返回值,真或假,来确定接下来执不执行SELECT。
分析器先找到关键字SELECT,然后跳到FROM关键字将STUDENT表导入内存,并通过指针找到第一条记录,接着找到WHERE关键字计算它的条件表达式,如果为真那么把这条记录装到一个虚表当中,指针再指向下一条记录。如果为假那么指针直接指向下一条记录,而不进行其它操作。一直检索完整个表,并把检索出来的虚拟表返回给用户。EXISTS是条件表达式的一部分,它也有一个返回值(true或false)。
在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,可以通过使用 EXISTS 条件句防止插入重复记录。
INSERT INTO TableIn (ANAME,ASEX)
SELECT top 1 '张三', '男' FROM TableIn
WHERE not exists (select * from TableIn where TableIn.AID = 7)
EXISTS与IN的使用效率的问题,通常情况下采用exists要比in效率高,因为IN不走索引,但要看实际情况具体使用:
IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
问题和解决
问题1:
--users表有1000条记录,id自增,id都大于0
select * from users where exists (select * from users limit 0); --输出多少条记录?
select * from users where exists (select * from users where id < 0); --输出多少条记录?
答案(请选中查看):
10000条
0条
原因:
exists查询的本质,只要碰到有记录,则返回true;所以limit根本就不会去管,或者说执行不到。
问题2:
exists可以完全代替in吗?
不能。
例如:
--没有关联字段的情况:枚举常量
select * from areas where id in (4, 5, 6);
--没有关联字段的情况:这样exists对子查询,要么全true,要么全false
select * from areas where id in (select city_id from deals where deals.name = 'xxx');
举个相关exists的sql优化例子:
9、用exists替代in(发现好多程序员不知道这个怎么用):
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接。
在这种情况下,使用exists(或not exists)通常将提高查询的效率。
举例:
(低效)
select ... from table1 t1 where t1.id > 10 and pno in (select no from table2 where name like 'www%');
(高效)
select ... from table1 t1 where t1.id > 10 and exists (select 1 from table2 t2 where t1.pno = t2.no and name like 'www%');
10、用not exists替代not in:
在子查询中,not in子句将执行一个内部的排序和合并。
无论在哪种情况下,not in都是最低效的 (因为它对子查询中的表执行了一个全表遍历)。
为了避免使用not in,我们可以把它改写成外连接(Outer Joins)或not exists。
11、用exists替换distinct:
当提交一个包含一对多表信息的查询时,避免在select子句中使用distinct. 一般可以考虑用exists替换
举例:
(低效)
select distinct d.dept_no, d.dept_name from t_dept d, t_emp e where d.dept_no = e.dept_no;
(高效)
select d.dept_no, d.dept_name from t_dept d where exists (select 1 from t_emp where d.dept_no = e.dept_no);
exists使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果.
12、用表连接替换exists:
通常来说,采用表连接的方式比exists更有效率。
举例:
(低效)
select ename from emp e where exists (select 1 from dept where dept_no = e.dept_no and dept_cat = 'W');
SELECT ENAME
(高效)
select ename from dept d, emp e where e.dept_no = d.dept_no and dept_cat = 'W';
Sql 语句中 IN 和 EXISTS 的区别及应用的更多相关文章
- SQL语句中in 与 exists的区别
SQL语句中in 与 exists的区别 SQL中EXISTS检查是否有结果,判断是否有记录,返回的是一个布尔型(true/false); IN是对结果值进行比较,判断一个字段是否存在于几个值的范围中 ...
- Sql语句中IN和exists的区别及应用
表展示 首先,查询中涉及到的两个表,一个user和一个order表,具体表的内容如下: user表: order表: in 确定给定的值是否与子查询或列表中的值相匹配.in在查询的时候,首先查询子查询 ...
- Sql 语句中 IN 和 EXISTS 的区别
IN 语句:只执行一次 确定给定的值是否与子查询或列表中的值相匹配.in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选.所以相对内表比较小的时候,in的速度较快 ...
- 面试被问之-----sql优化中in与exists的区别
曾经一次去面试,被问及in与exists的区别,记得当时是这么回答的:''in后面接子查询或者(xx,xx,xx,,,),exists后面需要一个true或者false的结果",当然这么说也 ...
- 【SQL】查询语句中in和exists的区别
in in可以分为三类: 一. 形如select * from t1 where f1 in ( &apos:a &apos:, &apos:b &apos:),应该和 ...
- SQL查询中in和exists的区别分析
select * from A where id in (select id from B); select * from A where exists (select 1 from B where ...
- sql语句中where和having的区别
WHERE语句在GROUPBY语句之前:SQL会在分组之前计算WHERE语句. HAVING语句在GROUPBY语句之后:SQL会在分组之后计算HAVING语句.
- SQL语句中SUM与COUNT的区别
SUM是对符合条件的记录的数值列求和 COUNT 是对查询中符合条件的结果(或记录)的个数 例如: 表fruit id name price 1 apple 3.00 2 ...
- 解析sql语句中left_join、inner_join中的on与where的区别
以下是对在sql语句中left_join.inner_join中的on与where的区别进行了详细的分析介绍,需要的朋友可以参考下 table a(id, type):id type ---- ...
随机推荐
- AT2390-[AGC016F]Games on DAG【状压dp,SG函数】
正题 题目链接:https://www.luogu.com.cn/problem/AT2390 解题思路 \(n\)个点的\(DAG\),\(m\)条边可有可无,\(1\)和\(2\)上有石头.求有多 ...
- spring 创建Bean最全实现方法
创建bean方式,spring创建bean的方式包含:自动注入方式和人工注入方式.分别为:1)xml 配置化方式 2)@bean注解注入方式3)@Component方式 4)接口注入方式 5)imp ...
- 10.7 URI
URI: Uniform Resource Identifier 统一资源标识符 URL: Uniform Resource Locator 统一资源定位符 URN: Uniform R ...
- 基础篇——Pycharm的安装与使用 初学者此篇够用
简介 Pycharm是python编程过程中最为推荐的编辑调试软件之一,其使用简单,界面友好,也成了学习Python路上必须学会的软件之一,本篇教程简单介绍一下windows用户从安装到日常使用的基本 ...
- CentOS7安装Python3和VIM8
参考:http://blog.sina.com.cn/s/blog_45249ad30102yulz.html
- 从commons-beanutils反序列化到shiro无依赖的漏洞利用
目录 0 前言 1 环境 2 commons-beanutils反序列化链 2.1 TemplatesImple调用链 2.2 PriorityQueue调用链 2.3 BeanComparator ...
- bzoj1503 郁闷的出纳员(平衡树,思维)
题目大意: 现在有n个操作和一个最低限度m \(I\)命令\(I\ k\)新建一个工资档案,初始工资为k. \(A\)命令$A\ k $把每位员工的工资加上k \(S\)命令$S\ k $把每位员工的 ...
- spoj2 prime1 (区间筛)
给定t组询问,每组询问包括一个l和r,要求\([l,r]\)的素数有哪些 其中\(t \le 10,1 \le l \le r \le 1000000000 , r-l \le 100000\) Qw ...
- js--typeof 和 instanceof 判断数据类型的区别及开发中的使用
前言 日常的开发中,我们经常会遇到判断一个变量的数据类型或者该变量是否为空值的情况,你是如何去选择判断类型的操作符的?本文来总结记录一下我们开发人员必须掌握的关于 typeof 和 instanceo ...
- Flask的环境配置
Flask django是大而全,提供所有常用的功能 flask是小而精,只提供核心功能 环境配置 为了防止 django和 flask环境相互冲突,可以使用 虚拟环境分割开 pip instal ...