论文笔记:(TOG2019)DGCNN : Dynamic Graph CNN for Learning on Point Clouds
Dynamic Graph CNN for Learning on Point Clouds
论文地址:https://arxiv.org/abs/1801.07829
代码:https://github.com/WangYueFt/dgcnn
别人复现的(pytorch版):https://github.com/AnTao97/dgcnn.pytorch

图1所示 利用该神经网络进行点云分割。下图:神经网络结构示意图。上图:网络各层生成的特征空间结构,特征上的颜色表示红点到所有剩余点的距离 (最左边一列为输入;中间三层为处理的结果;右边的图显示了分割结果)。观察更深层次的特征空间结构如何捕获语义上相似的结构,如机翼、机身或涡轮机,尽管它们在原始输入空间中有很大的距离。
个人见解:
- 本篇文章认为 pointnet++ 属于静态图卷积:pointnet++ 根据点对的欧氏距离构建图,然后在每一层进行图粗化操作。使用最远点采样选取点作为下一层的输入。这样使得每一层的图不断减小,但是图的结构没有改变(静态图或者固定图)。
- DGCNN 的动态图卷积,是因为 在特征空间取k近邻,每层计算的特征都不相同,也就是说图的连接关系由网络自己学习,因此相当于每一层的图都具有不同的顶点,edgconv的感受野最大可以达到整个点云的直径。
- 本文开门见山给出网络结构图,以及non-local的思想,简单来说就是相似特征不一定是在local局域内。
- 实验证明,特征空间中的距离可以更好的拉近相同语义点的距离。这样不仅学习到了点云的几何信息,而且学习如何对点云进行分组。
摘要
点云提供了一种灵活的几何表示,适用于计算机图形学中无数的应用;它们还包括大多数3D数据采集设备的原始输出。
尽管在图形和视觉领域,人工设计的点云特征已经被提出很久了,然而,最近卷积神经网络(CNNs)在图像分析方面的压倒性成功表明,将CNN的见解应用到点云世界的价值。
点云本身缺乏拓扑信息,所以设计模型去获得拓扑结构信息可以增强点云的表示能力。为此,我们提出了一种新的神经网络模块——Edge-Conv,其适用于基于cnn的点云
高级任务,包括分类和分割。
EdgeConv是可以作用在网络的每一层中的动态计算的图。
它是可微分的,可以插入到现有的架构中。
与现有的运行在外部空间或单独处理每个点的模块相比,EdgeConv具有几个吸引人的特性:它包含了局部邻域信息;它可以堆叠应用,学习全局形状属性;
而在多层系统中,特征空间的亲和度在原始嵌入中可能 跨越很长的距离捕获语义特征。
我们在标准基准测试上展示了模型的性能,包括ModelNet40、ShapeNetPart和S3DIS。
一、引言
点云,或二维或三维分散的点集合,可以说是最简单的形状表示;它们还包括3D传感技术的输出,包括激光雷达扫描仪和立体重建。由于效率考量或这些技术在噪声存在时的不稳定性,随着快速三维点云采集技术的出现,最近用于图形和视觉的技术经常直接处理点云,绕过昂贵的网格重建或去噪。最近的点云处理和分析应用包括室内导航[Zhu et al. 2017]、自动驾驶汽车[Liang et al. 2018;Qi et al 2017a;Wang et al 2018b],机器人[Rusu et al. 2008b],形状合成和建模[Golovinskiy et al. 2009;Guerrero等人2018]。
这些现代应用程序需要对点云进行高级处理。最近的算法不是识别明显的几何特征,比如角和边,而是搜索语义线索。这些特征并不完全适合计算或微分几何框架,通常需要基于学习的方法,通过对已标记或未标记数据集的统计分析得出相关信息。
本文主要考虑点云的分类和分割,这是点云处理中的两个模型任务。解决这些问题的传统方法使用手工特征来捕获点云的几何属性[Lu et al.2014; Rusu et al. 2009, 2008a]。最近,深度神经网络在图像处理方面的成功推动了一种数据驱动的方法来学习点云上的特征。深度点云处理和分析方法发展迅速,在各种任务中优于传统方法[Chang et al. 2015]。
然而,将深度学习应用于点云数据远非易事。最关键的是,标准的深度神经网络模型要求输入数据结构规则,而点云本质上是不规则的: 点位置在空间中连续分布,其顺序的任何排列都不会改变空间分布。使用深度学习模型处理点云数据的一种常见方法是首先将原始点云数据转换为体积表示,即3D网格[Maturana and Scherer 2015; Wu et al. 2015]。然而,这种方法通常会引入量化误差和过度的内存使用,使得获取高分辨率或细粒度的特性变得困难。
最先进的深度神经网络是专门为处理不规则点云而设计的,直接处理原始点云数据,而不是传递给中间的规则表示。这种方法是PointNet [Qi et al. 2017b]首创的,通过对每个点独立操作,然后使用对称函数来积累特征,从而实现点的排列不变性。PointNet的各种扩展都考虑点的邻域,而不是单独作用于每个点[Qi et al. 2017c; Shen et al. 2017];这使得网络可以利用局部特征,提高基本模型的性能。这些技术在很大程度上独立处理局部区域的点以保持排列不变性。然而, (要解决的问题)这种独立性忽略了点之间的几何关系,呈现了一个无法捕捉局部特征的基本限制。
为了解决这些缺点,我们提出了一种新的简单操作,称为EdgeConv,它捕获局部几何结构的同时保持排列不变性。EdgeConv并没有直接从它们的嵌入中生成点特征,而是 生成描述点与其相邻点之间关系的边缘特征。EdgeConv被设计成对邻居的顺序不变,因此是排列不变的。由于 EdgeConv显式地构造了一个局部图并学习了边缘的嵌入,因此该模型能够同时在欧氏空间和语义空间中对点进行分组。
EdgeConv易于实现并集成到现有的深度学习模型中,以提高其性能。在我们的实验中,我们将EdgeConv集成到PointNet的基本版本中,而不使用任何特性转换。我们展示了网络在几个数据集上达到最先进的性能,最值得注意的是在用于分类和分割的ModelNet40和S3DIS的结果。
关键的贡献 我们将工作的主要贡献总结如下:
- 我们提出了一种从点云学习的新操作,EdgeConv,更好地捕捉点云的局部几何特征,同时保持排列不变性。
- 我们展示了该模型可以通过动态更新一层到一层的关系图来学习语义分组点 (点云中形状相似的部分,在特征空间中的距离较小)。
- 我们演示了EdgeConv可以集成到多个现有模型中进行点云处理。
- 我们对EdgeConv进行了广泛的分析和测试,并证明它在基准数据集上达到了最先进的性能。
- 我们发布我们的代码,以促进可重现性和未来的研究。
补充:(缺点) EdgeConv考虑了点的坐标与领域点的距离,忽视了相邻点之间的向量方向(局部邻域图是无向图,中心点与邻域点谁指向谁并不知道),最终还是损失了一部分局部几何信息。
总结:当我们提出一个新的点云特征描述子的时候,我们可以从一下方面总结我们的创新点:
(1) 我们提出了某某某算子,该算子可以实现置换不变性、平移不变性、旋转不变性,同时可以捕获局部几何信息。
(2) 该算子可以通过堆叠或者循环使用,提取全局形状信息。
(3) 该算子可以集成到现有的模型中进行点云处理。
(4) 在标准数据集上实现了SOA效果。
二、相关工作
手工制作的特征 几何数据处理和分析中的各种任务——包括分割、分类和匹配——需要一些形状之间的局部相似概念。传统上,这种相似性是通过构造捕获局部几何结构的特征描述符来建立的。计算机视觉和图形学领域的无数论文提出了适合于不同问题和数据结构的点云的局部特征描述符。对手工设计的点特性的全面概述超出了本文的范围,但是我们建议读者参考[Biasotti et al. 2016; Guo et al. 2014;Van Kaick et al. 2011]。
广义地说,可以分为外在描述符和内在描述符。外部描述子通常是从三维空间中形状的坐标推导出来的,包括形状上下文(shape context) [Belongie et al. 2001]、自旋图像(spin images) [Johnson and Hebert 1999],积分特征[Manay et al. 2006],基于距离的描述符[Ling and Jacobs 2007],点特征直方图[Rusu et al. 2009, 2008a],规范化直方图[Tombari et al. 2011],等等。内在描述符将三维形状视为一个流形,其度量结构离散为一个网格或图; 用度量表示的量对等距变形是不变的。这类的代表包括频谱描述符如global point signatures [Rustamov 2007], the heat and wave kernel signatures [Aubry et al.2011;Sun et al.2009],以及变体(Bronstein and Kokkinos 2010)。最近,有几种方法围绕标准描述符包装机器学习方案[Guoet et al. 2014;Shah et al. 2013]。
几何的深度学习 继卷积神经网络(CNNs)在视觉方面的突破性成果之后[Krizhevsky et al. 2012;LeCun et al. 1989],人们对将这种方法应用于几何数据有着浓厚的兴趣。与图像不同,几何学通常没有底层网格,需要新的构建块取代卷积和池化或适应网格结构。
作为克服这个问题的一种简单方法,基于视图的[Su et al. 2015;Wei et al. 2016]和体积表征[Klokov and Lempitsky2017; Maturana and Scherer 2015; Tatarchenko et al. 2017; Wu et al. 2015]-或他们的组合[Qi et al. 2016]-“放置”几何数据到网格上。最近,PointNet [Qi et al. 2017b,c]举例说明了广泛的一类基于非欧氏数据(图形和流形)的深度学习架构,称为几何深度学习[Bronstein et al. 2017]。这些可追溯到在图上构建神经网络的早期方法[Scarselli et al. 2009],最近改进了的门控循环单元[Li et al. 2016]和神经消息传递[Gilmer et al. 2017]。[ Bruna et al. 2013] 和 [Henaff et al. 2015]通过拉普拉斯特征向量对图进行广义卷积[Shuman et al. 2013]。在后续的工作中,使用多项式和rational spectral filters缓解了这种基础方法的计算缺陷[Defferrard et al.2016;Kipf and Welling 2017;Monti et al. 2017b, 2018],其中rational spectral filters [Levie et al.2017]避免拉普拉斯特征分解并保证定位。非欧氏卷积的另一种定义是使用空间滤波器而不是频谱滤波器。测地线CNN (GCNN)是一种基于网格的深度CNN,它使用局部内在参数化将patch的概念一般化[Masci et al. 2015]。与频谱方法相比,它的关键优点是更好的泛化,以及构造方向滤波器的简单方法。后续工作提出了使用各向异性扩散的不同局部制图技术[Boscaini et al. 2016]或高斯混合模型[Monti et al. 2017a; Veličković et al. 2017]。在[Halimi et al. 2018; Litany et al. 2017b]中,将可微函数映射层[Ovsjanikov et al. 2012]合并到几何深度神经网络中,可以对非刚性形状之间的对应关系进行内在的结构化预测。
几何深度学习的最后一类的方法试图拉回一个卷积操作通过把形状嵌入到一个平移不变性的结构域,例如球形[Sinha et al. 2016],环面[Maron et al. 2017],飞机[Ezuz et al . 2017],稀疏网络格子(Su et al . 2018年)或样条(Fey et al . 2018年)。
最后,我们应该提到几何生成模型,它试图概括模型,如自动编码器,变分自动编码器(VAE) [Kingma andWelling 2013],生成式对抗网络(GAN) [Goodfellow et al. 2014]到非欧几里得设置。这两种设置之间的一个基本区别是,输入和输出顶点之间缺乏规范顺序,因此需要解决输入-输出对应问题。在三维网格生成中,通常假设网格是给定的,其顶点是正序的;因此,生成问题仅仅是决定网格顶点的嵌入。[Kostrikovet al. 2017]为此任务提出了基于外部狄拉克算子的SurfaceNets。[Litany et al. 2017a]介绍了内部VAE网格并将其应用于形状补全;[Ranjan et al. 2018]等人使用了类似的架构用于3D人脸分析。对于点云,已经提出了多种生成架构[Fan et al. 2017;Li et al. 2018b;Yang et al. 2018]。
三、我们的方法
我们提出了一种受PointNet和卷积运算启发的方法。然而,与像PointNet那样处理单个点不同,我们利用了局部几何结构,构造了一个局部邻域图,并在连接相邻点对的边上应用类似卷积的操作,这是图神经网络的精神。我们在下面说明,这样的操作,称为边缘卷积(EdgeConv),具有介于平移不变性和非局域性之间的性质。
与CNN图不同,我们的图不是固定的,而是在网络的每一层之后动态更新的。也就是说,一个点的k近邻集合在网络中逐层变化,由嵌入序列计算。特征空间的邻近性与输入的邻近性不同,导致信息在整个点云中的非局部扩散。作为与现有工作的联系,非局域神经网络[Wang et al. 2018a]在视频识别领域探索了类似的思路以及[Xie et al. 2018]的后续工作,他提出利用非局部的块来对特征图进行去噪,以抵御对抗性攻击。
3.1 边缘卷积Edge Convolution
考虑一个具有n个点的F维点云,表示为X = {x1,…, xn}⊆RF。在最简单的设置中F = 3,每个点包含三维坐标xi = (xi,yi, zi);还可以包含表示颜色、表面法线等的额外坐标。在深度神经网络体系结构中,每一个后续层都对前一层的输出进行操作,所以更一般的维数F表示给定层的特征维数。
我们计算一个表示局部点云结构的有向图G = (V, E),其中V ={1,…,n}和E⊆V×V分别为顶点和边。在最简单的情况下,我们构造G为X在RF空间中的k-近邻(k-NN)图。图包含自循环,这意味着每个节点也指向自己。我们将边缘特征定义为eij = hΘ(xi, xj),其中hΘ:RF×RF→RF′是带有一组可学习参数的非线性函数。
最后,我们通过在边缘特征上应用通道对称聚合操作□(例如Σ或max)来定义EdgeConv操作,边缘特征与该点向每个顶点发出的所有边相关联的。因此,EdgeConv在第i个顶点的输出为
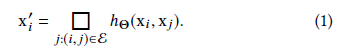
与图像上的卷积类比,我们将xi作为中心像素,{xj: (i, j)∈E}作为围绕中心像素的一个patch(如图2)。总体而言,给定一个有n个点的F维点云, EdgeConv生成具有相同点数的F '维点云。
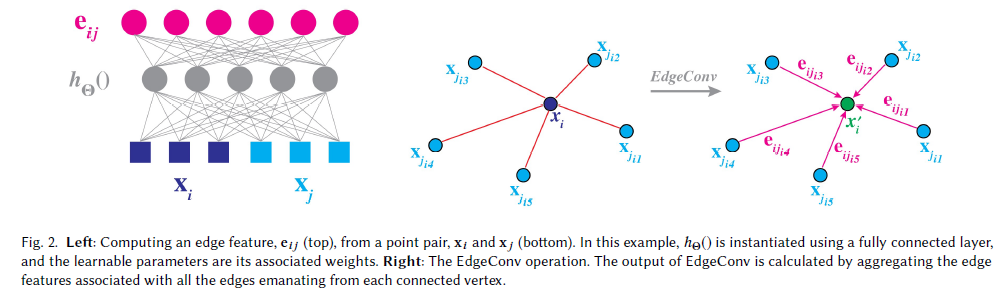
图2所示。左图: 从点对(xi,xj)(下)计算边缘特征eij(上)。在这个例子中,hΘ()是使用一个全连接层实现的,并且可学习的参数是它的相关权重。右:EdgeConv操作。EdgeConv的输出是通过聚合与每个连接顶点发出的所有边缘相关的边缘特征来计算的。
h的选择和□

边缘函数和聚合操作的选择对EdgeConv的性能有至关重要的影响。例如,当x1,…, xn表示规则网格上的图像像素,图G的连通度表示每个像素周围固定大小的patch,选择θm•xj作为边缘函数,sum作为汇聚操作,得到标准卷积:

这里,Θ=(θ1,…,θM)编码M个不同滤波器的权值。每个θm与x具有相同的维数,•表示欧几里得内积。
h的第二个选择是
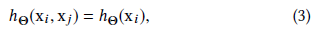
只编码全局形状信息而不考虑局部邻域结构。这种类型的操作在PointNet中使用,因此可以将其视为EdgeConv的一个特殊情况。
h的第三个选择是 Atzmon等人[2018]采用的

g是高斯核,μ计算欧几里得空间中的两两距离。
h的第四个选择是
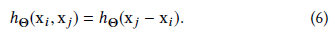
这种方法只对局部信息进行编码,将形状视为小块的集合,并失去全局结构。
最后,本文采用的第五种选择是非对称边缘函数
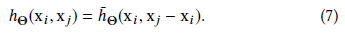
这显式地结合了全局形状结构(由patch centers xi的坐标捕获)和局部邻域信息(由xj−xi捕获)。特别地,我们定义我们的操作符为:
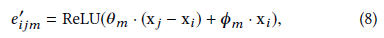
这个操作可以用共享的MLP实现,然后采取

3.2动态图更新
我们的实验表明,利用每一层产生的特征空间中最近邻重新计算图是有益的。这是我们的方法与处理固定输入图的 图的一个重要区别。这样的动态图更新就是我们的架构命名为动态图CNN (DGCNN)的原因。使用动态图更新,感受野与点云范围一样大,尽管是稀疏的。

3.3 性质
置换不变性 考虑一个层的输出

和一个排列算符π。输出x'i对输入xj的排列不变,因为max是一个对称函数(其他对称函数也适用)。聚合点特征的全局最大池化操作符也是排列不变的。
平移不变性 我们的操作符有一个“部分”平移不变性属性,因为我们选择的边缘函数(7)显式地暴露了函数中与平移相关的部分,并且可以选择性地禁用该部分。考虑一个应用于xj和xi的平移;我们可以证明,当平移T时,部分边缘特征保留了下来,特别是对于
平移后的点云我们有
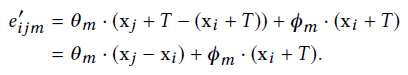
如果我们只考虑xj−xi,使其中的θm = 0,那么该算子对平移是完全不变的。然而,在这种情况下,该模型简化为基于一组无序的patch来识别一个对象,忽略了patch的位置和方向。该模型以xj−xi和xi为输入,在保持全局形状信息的同时考虑了patch的局部几何形状。
3.4 与现有方法比较
DGCNN与两类方法有关:PointNet和graph cnn,我们展示了它们是我们方法的特定设置。我们在表1中总结了不同的方法。

PointNet是我们方法中k = 1的特例,生成一个边设为空的图E =∅。PointNet中使用的边函数是hΘ(xi, xj) = hΘ(xi),它考虑的是全局几何而不是局部几何。PointNet++试图在局部区域应用PointNet解释局部结构。在我们的说法中,PointNet++首先根据点之间的欧几里得距离构造图,并在每一层应用一个图粗化操作。对于每一层,使用最远点采样(FPS)选择一些点;只有选中的点被保留,其他点在这一层之后被直接丢弃。通过这种方式,在对每一层进行操作后,图形变得更小。相比DGCNN, PointNet++使用点输入坐标计算成对距离,因此它们的图形在训练期间是固定的。PointNet++使用的边函数是hΘ(xi, xj) = hΘ(xj),聚合操作也是max。
在GCNN中, MoNet [Monti et al. 2017a], ECC [Simonovskyand Komodakis 2017], Graph Attention Networks [Veličković et al.2017], 和 the concurrent work [Atzmon et al. 2018]是最相关的方法。它们的共同特点是图上的局部patch的概念,在局部patch中可以定义卷积类型的操作。
具体来说,Monti et.al [2017a]使用图结构计算了一个局部“伪坐标系”u,其中邻域顶点在该坐标系下重新表示;卷积被定义为M-component混合高斯

其中,g为高斯核,⊙为逐对点积( **阿达马Hadamard** )积。{w1, . . . .wN }编码高斯的可学习参数(均值和协方差),{θ1,......,θM}是可学习的滤波器系数。(11)是我们一般操作(1)的一个实例,其特定的边缘函数为
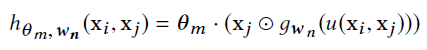
□=Σ。同样,它们的图结构是固定的,并且u是基于节点的度构造的。
补充:

[Atzmon et al. 2018]可以看作是[Monti et al. 2017a]的一个特例,其中与g是预定义的高斯函数。去除可学习的参数(w1,. . . .,wN)从点云构造稠密图,我们有

其中u是欧氏空间中xi和xj的成对距离。
当MoNet和其他图网络假设一个给定的固定图,在这个固定图上应用类似卷积的操作时,据我们所知,我们的方法是第一个在可学习参数更新时,图从一层变化到另一层,甚至在训练期间相同的输入上变化的方法。通过这种方法,我们的模型不仅学习了如何提取局部几何特征,还学习了如何对点云中的点进行分组。图4展示了不同特征空间中的距离,举例说明了原始嵌入中更深层次的距离携带着较长距离的语义信息。
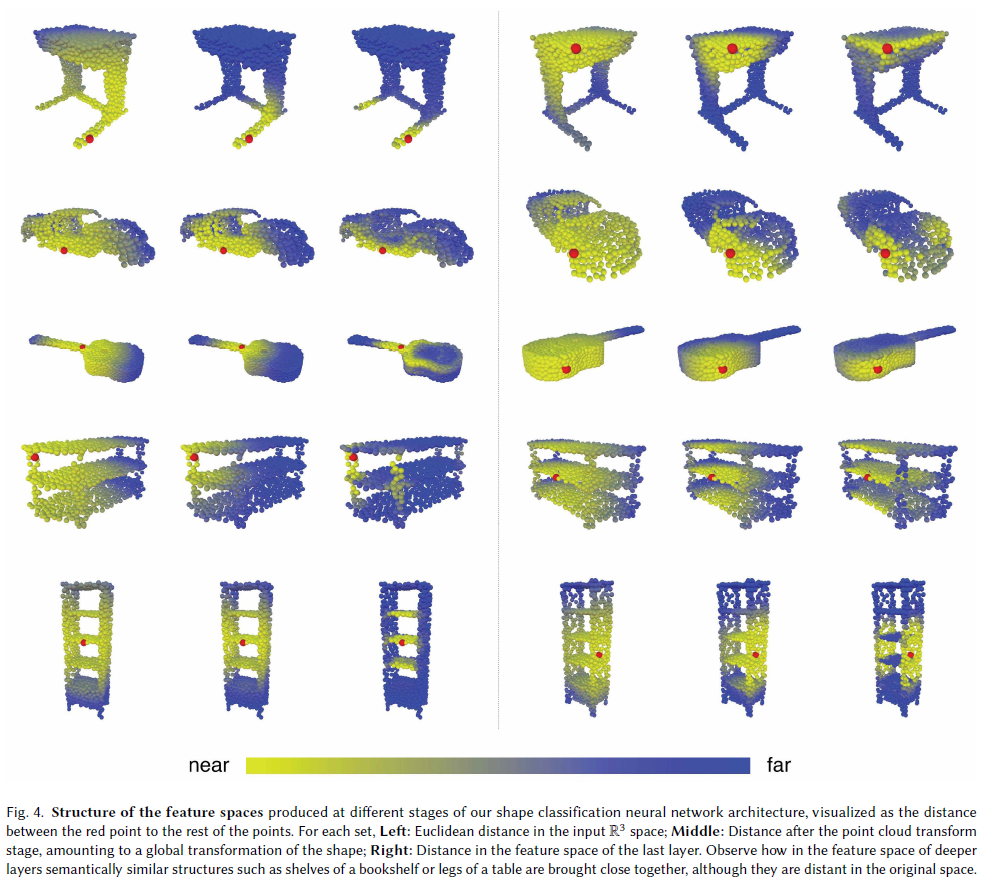
图4所示。在我们的形状分类神经网络体系结构的不同阶段产生的特征空间的结构,可视化为红点到其余点之间的距离。对于每个集合,左:输入R3空间中的欧氏距离;中间:点云变换阶段后的距离,相当于形状的全局变换; 右:最后一层特征空间中的距离。观察在更深层次的特征空间中,语义上相似的结构(如书架的架子或桌子的腿)是如何紧密结合在一起的,尽管它们在原始空间中是遥远的。
四、评估
在本节中,我们将评估使用EdgeConv为不同任务构建的模型:分类、部件分割和语义分割。我们还将实验结果可视化,以说明与以往工作的关键差异。
4.1 分类
数据 我们在ModelNet40 [Wu et al. 2015]分类任务中评估我们的模型,包括预测以前未见过的形状的类别。数据集包含来自40个类别的12311个网格CAD模型。9,843个模型用于训练和2,468个模型用于测试。我们遵循Qi等人[2017b]的实验设置。对于每个模型,从网格面均匀采样1024个点;点云被重新缩放以适应单位球体。只使用采样点的(x,y, z)坐标,原始网格被丢弃。在训练过程中,我们通过随机缩放目标和扰动目标和点的位置来增加数据。
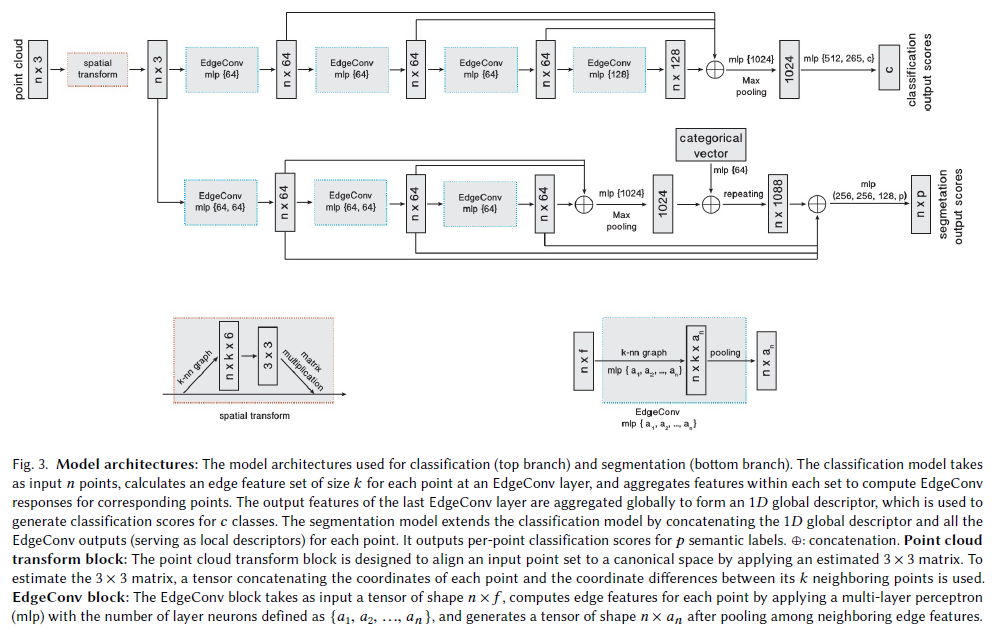
结构 分类任务所使用的网络架构如图3所示(顶部分支不含空间变压器网络)。我们使用四个EdgeConv层来提取几何特征。四个EdgeConv层使用三个共享的全连接层(64、64、128、256)。我们根据每个EdgeConv层的特征重新计算图,并为下一层使用新的图。对于所有EdgeConv层,最近邻的数目k是20(对于表2中的最后一行,k是40)。Skip-connect包括提取多尺度特征和一个共享的完全连接层(1024)来聚合多尺度特征,其中我们将之前层的特征连接起来,得到64+64+128+256=512维点云。然后,采用全局最大/sum pooling方法获得点云的全局特征,得到两个全连接层(512,256)用于变换全局特征。在最后两个全连接层中使用Dropout(保持概率为0.5)。所有层包括LeakyReLU和批归一化。使用验证集选择数字k。我们将训练数据分割为80%用于训练,20%用于验证,以搜索最优k。选择k后,对整个训练数据进行再训练,对测试数据进行评价。其他超参数的选择也是类似的。
训练 我们使用学习速率为0.1的SGD,使用余弦退火将学习速率降低到0.001 [Loshchilov and Hutter 2017]。批量规范化的动量是0.9,我们不使用批量规范化衰减。批大小为32,动量为0.9。
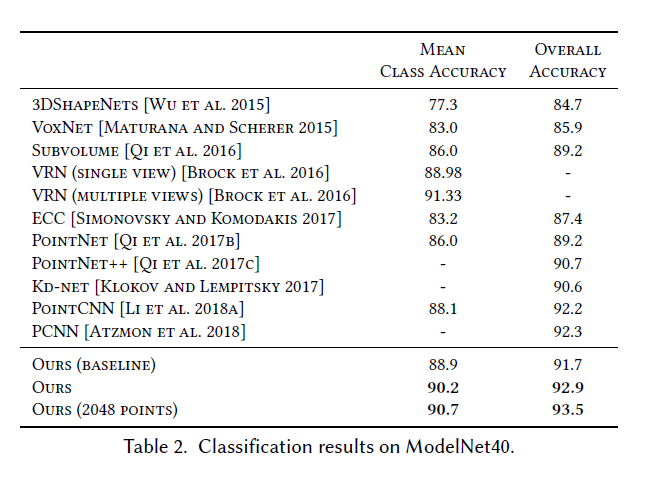
结果 表2显示了分类任务的结果。我们的模型在这个数据集上取得了最好的结果。我们使用固定图的基线(由输入点云的邻近度决定)比pointnet++好1.0%。在该数据集上采用动态图重计算的改进版本取得了较好的效果。所有实验都使用除最后一行外包含1024个点的点云进行。我们用2048点进一步测试模型。2048点使用的k是40,以保持相同的密度。注意,PCNN [Atzmon et al. 2018]使用了额外的增强技术,比如在训练和测试期间从1200个点中随机抽取1024个点。
4.2 模型复杂度
我们使用ModelNet40 [Wu et al. 2015]分类实验来比较我们的模型与之前的先进水平的复杂性。表3显示,我们的模型实现了模型复杂性(参数数量)和计算复杂性之间的最佳折衷(以正向通过时间测量),由此得到的分类精度。
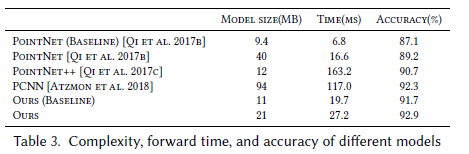
我们使用固定k-NN图的基线模型比之前的最先进的PointNet++准确率高1.0%,同时快7倍。我们的模型的一个更先进的版本包括一个动态更新的图计算,其性能分别超过了PointNet++、PCNN 2.2%和0.6%,而我们的模型则是更高效的。本节中,每次实验的点的个数都是1024。
4.3 在ModelNet40上的更多实验
我们还在ModelNet40数据集上对模型的各种设置进行了实验[Wu等人2015]。特别地,我们分析了不同距离度量、xi−xj的明确使用以及更多点的有效性。
表4显示了结果。“Centralization”是指将xi和xi−xj连接起来作为边缘特征,而不是将xi和xj连接起来。“Dynamic graph recomputation”表示我们重构图而不是使用固定的图。通过使用xi和xi−xj的连接显式地集中每个补丁可以提高大约0.5%的整体精度。通过动态更新图,大约有0.7%的改进,图4也表明模型可以提取语义上有意义的特征。使用更多的点进一步提高了整体精度0.6

我们还用不同数量的k个最近邻进行实验,如表5所示。对于所有实验,点数仍然是1024。虽然我们没有对所有可能的k进行详尽的试验,但我们发现,当k较大时,性能会下降。这证实了我们的假设,对于一定密度,当k较大时,欧几里得距离无法近似测地线距离,破坏了每个patch的几何形状。

我们进一步评估我们的模型相对于点云密度的稳健性(训练时用的1024个点与k = 20)。我们模拟测试过程中随机输入点掉落的环境。从图5可以看出,即使剔除了一半的点,模型仍然可以得到合理的结果。然而,当点云数量低于512点时,表现就会急剧下降。

4.4 部件分割
数据 我们扩展了我们的EdgeConv模型架构,用于ShapeNet部件数据集上的部件分割任务[Yi et al. 2016]。对于这个任务,点云集合中的每个点都被分类到几个预定义的部件类别标签中的一个。数据集包含16,881个来自16个对象类别的3D形状,总共注释了50个部分。从每个训练形状中采样2048个点,大多数采样点集合的标记少于6个部分。在我们的实验中,我们遵循Chang等人[2015]的官方训练/验证/测试分割方案。
架构 网络架构如图3所示(分支)。经过空间变压器网络,三个Conv层被使用。一个共享的全连接层(1024)聚合来自前一层的信息。Skip-connect用于将所有EdgeConv输出包括为局部特征描述符。最后,利用三个共享的全连接层(256,256,128)对点特征进行变换。批处理规范、dropout和ReLU以类似的方式包括在我们的分类网络中。
训练 我们采用与分类任务相同的训练设置。在两台NVIDIA TITAN X gpu上进一步实现了分布式训练方案,以保持训练批量的大小。
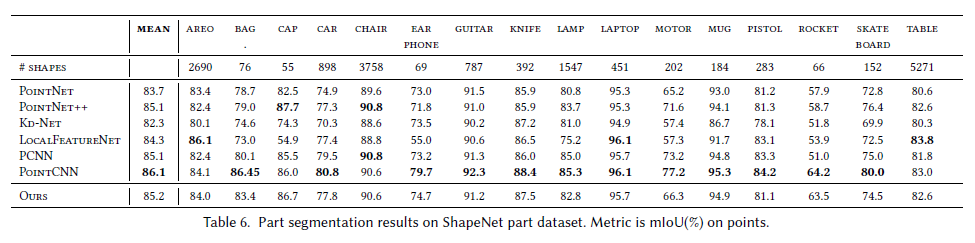
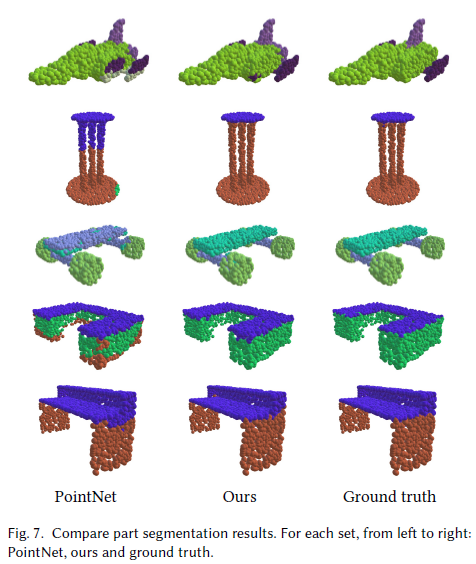
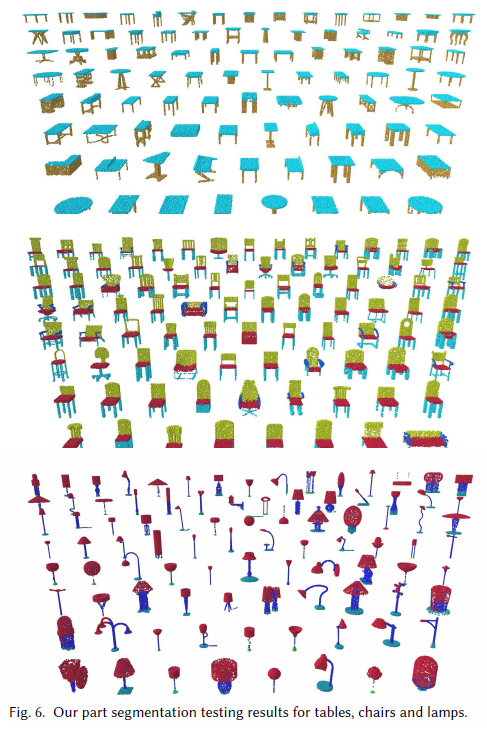
结果 我们使用点上的交集和并集之比(IoU)来评估我们的模型,并与其他基准进行比较。我们遵循与PointNet相同的评估方案:一个形状的IoU是通过将该形状中发生的不同部分的IoU进行平均来计算的,而一个类别的IoU是通过将属于该类别的所有形状的IoU进行平均来得到的。平均IoU (mIoU)的计算方法是将所有测试形状的IoU平均起来。我们将我们的结果与PointNet [Qi et al. 2017b]、PointNet++ [Qi et al. 2017c]、Kd-Net [Klokov and Lempitsky 2017]、LocalFeatureNet进行比较[Shen et al. 2017], PCNN [Atzmon et al. 2018], PointCNN [Li et al. 2018a]。评价结果如表6所示。我们还在图7中可视化地比较了我们的模型和PointNet的结果。图6显示了更多的示例。
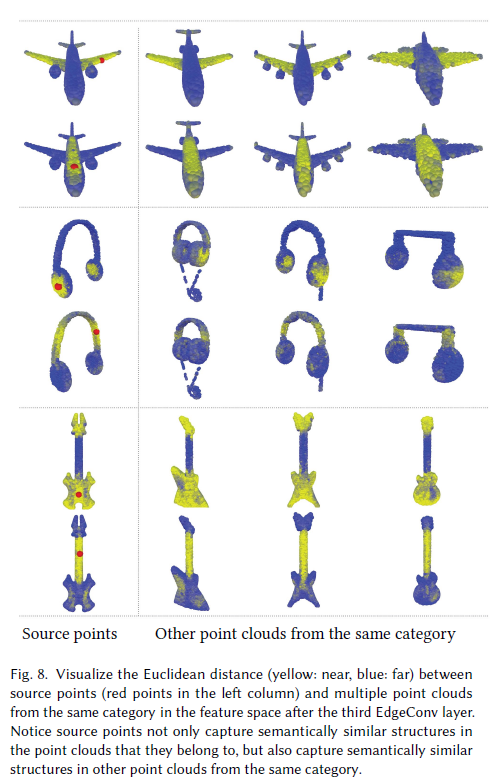
点云间距离 接下来,我们将探索使用我们的特性捕获的不同点云之间的关系。图8所示,我们从一个源点云中取一个红点,计算其在特征空间中与同一类别其他点云中的点的距离。一个有趣的发现是,尽管点来自不同的来源,但如果它们来自语义相似的部分,它们就会彼此接近。在本实验中我们的分割模型的第三层之后,我们对特征进行评估。
对不完整数据进行分割 我们的模型对部分数据具有鲁棒性。我们模拟形状的一部分以不同的百分比从六个侧面(顶部、底部、右侧、左侧、前部和后部)中丢失。结果如图9所示。在左侧,示出平均IOU与“保留比率”之比。在右边,飞机模型的结果是可视化的。

4.5 室内场景分割
数据 我们评估我们的模型在斯坦福大尺度三维室内空间数据集(S3DIS) [Armeni et al.2016]用于语义场景分割任务。该数据集包含了6个室内区域的3D扫描点云,共272个房间。每个点都属于13个语义范畴之一。木板、书柜、椅子、天花板和beam-plus杂物。我们遵循与Qi等人[2017b]相同的设置,其中每个房间被分割成面积为1m×1m的块体,每个点表示为一个9D矢量(XYZ、RGB和归一化空间坐标)。在训练过程中,每个块对4,096个点进行采样,所有点都用于测试。我们也对6个区域使用相同的6倍交叉验证,并报告平均评价结果。
本任务所使用的模型与部件分割模型相似,不同之处在于每个输入点都生成了语义对象类的概率分布,这里没有使用分类向量。我们将我们的模型与PointNet [Qi等人2017b]和PointNet基线(PointNet baseline)进行比较,使用额外的点特征(局部点密度、局部曲率和法线)来构建手工制作的特征,然后反馈给MLP分类器。我们进一步将我们的工作与[Engelmann et al. 2017]和PointCNN [Li et al. 2018a]进行比较。Engelmann等人[2017]提出了网络架构,以扩大3D场景的接受域。在他们的工作中提出了两种不同的方法:MS+CU处理具有合并单元的多尺度块特征; G+RCU为具有循环合并单元的网块。我们在表7中报告了评估结果,并在图10中直观地比较了PointNet和我们模型的结果。


五、讨论
在本文中,我们提出了一种新的点云学习算子,并展示了它在各种任务上的性能。我们的模型表明,局部几何特征对3D识别任务很重要,即使引入了深度学习中的机器。
虽然我们的架构可以很容易地集成到现有的基于点云的图、学习和视觉等方法中,但我们的实验也为未来的研究和扩展指明了几种途径。我们实现的一些细节可以修改和/或重新设计,以提高效率或可伸缩性,例如,纳入快速数据结构,而不是计算成对距离来评估k-最近邻查询。我们还可以考虑较大的点组之间的高阶关系,而不是将它们配对考虑。另一个可能的扩展是是设计一个非共享的变压器网络,工作在每个局部补丁不同,增加了我们模型的灵活性。
我们的实验表明,内在特征同样可以是有价值,甚至比点坐标更有价值;开发一个新的、有价值的、在理论上讲得通的实际框架,以平衡内在的和有意义的在学习过程中的外在考虑因素将需要从几何处理的理论和实践中得到启示。鉴于此。我们将考虑将我们的技术应用于更抽象的领域。来自文档检索等应用的点云和图像处理,而不是三维几何;超越拓宽我们的技术的适用性,这些实验将提供洞察几何学在抽象数据处理中的作用。
参考:https://zhuanlan.zhihu.com/p/267895014?utm_source=qq
https://blog.csdn.net/qq_39426225/article/details/101980690
论文笔记:(TOG2019)DGCNN : Dynamic Graph CNN for Learning on Point Clouds的更多相关文章
- 【论文阅读】DGCNN:Dynamic Graph CNN for Learning on Point Clouds
毕设进了图网络的坑,感觉有点难,一点点慢慢学吧,本文方法是<Rethinking Table Recognition using Graph Neural Networks>中关系建模环节 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
https://blog.csdn.net/zouxy09/article/details/9993371 自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一 ...
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 2018-01-28 15:4 ...
- [论文笔记] CUDA Cuts: Fast Graph Cuts on the GPU
Paper:V. Vineet, P. J. Narayanan. CUDA cuts: Fast graph cuts on the GPU. In Proc. CVPR Workshop, 200 ...
- 论文笔记之:Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 2013
Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 2013 在基于Gr ...
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要 神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的.在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上 ...
- 论文笔记:(CVPR2017)PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
目录 一. 存在的问题 二. 解决的方案 1.点云特征 2.解决方法 三. 网络结构 四. 理论证明 五.实验效果 1.应用 (1)分类: ModelNet40数据集 (2)部件分割:ShapeNet ...
- 论文笔记之:Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation
Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation Google 2016.10.06 官方 ...
随机推荐
- redHat6设置ip地址
产生需求的原因: 最近新安装了redhat6,可是在相互ping的过程中发现redhat6的并没有配置静态的ip地址,于是我尝试使用windows的方式去配置,可效果并不如意,于是如何在redhat6 ...
- [Docker核心之容器、数据库文件的导入导出、容器镜像的导入导出]
[Docker核心之容器.数据库文件的导入导出] 使用 Docker 容器 在 Docker 中,真正对外提供服务的还是容器,容器是对外提供服务的实例,容器的本质是进程. 运行一个容器 docker ...
- Mysql优化(出自官方文档) - 第二篇
Mysql优化(出自官方文档) - 第二篇 目录 Mysql优化(出自官方文档) - 第二篇 1 关于Nested Loop Join的相关知识 1.1 相关概念和算法 1.2 一些优化 1 关于Ne ...
- Java知识复习(四)
最近准备跳槽,又要好好复习基本知识了.过了个年,前面刚接触的springboot也只能先放放了.就先把自己复习了哪些罗列出来吧. Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用== ...
- Bootstrap中宽度大于指定宽度时有空白的解决方法
<div class="container-fluid"></div> 其中container-fluid的作用是占100%
- Windows批处理文件编写宝典
原贴:批处理新手入门导读 现在的教程五花八门,又多又杂.如何阅读,从哪里阅读,这些问题对新手来说,都比较茫然. 这篇文章的目的就是帮助新手理清学习顺序,快速入门.进步 1.如果你从来没有接触甚至没有听 ...
- Linux安装及管理程序
一,常见的软件包封装类型 二.RPM包管理工具 三.查询RPM软件包信息 四.安装.升级.卸载RPM软件包 五.解决软件包依赖关系的方法 六.源代码编译 七.安装yum源仓库 一,常见的软件包封装类型 ...
- 浙江大学计算机程序设计能力考试(PAT)简介
计算机程序设计能力考试(Programming Ability Test,简称 PAT)旨在通过统一组织的在线考试及自动评测方法客观地评判考生的算法设计与程序设计实现能力,科学地评价计算机程序设计人才 ...
- Simpleperf分析之Android系统篇
[译]Simpleperf分析之Android系统篇 译者按: Simpleperf是用于Native的CPU性能分析工具,主要用来分析代码执行耗时.本文是主文档的一部分,系统篇. 原文见aosp仓库 ...
- 15、修改sqldeveloper的JDK路径
15.1.说明: 1.第一次使用Oracle SQL Developer时会提示选择JDK路径(只会在第一次使用时提示), 如果选择了高版本的JDK(1.8)路径,可能会出现了如下两种情况: (1)s ...