Hadoop MapReduce 保姆级吐血宝典,学习与面试必读此文!
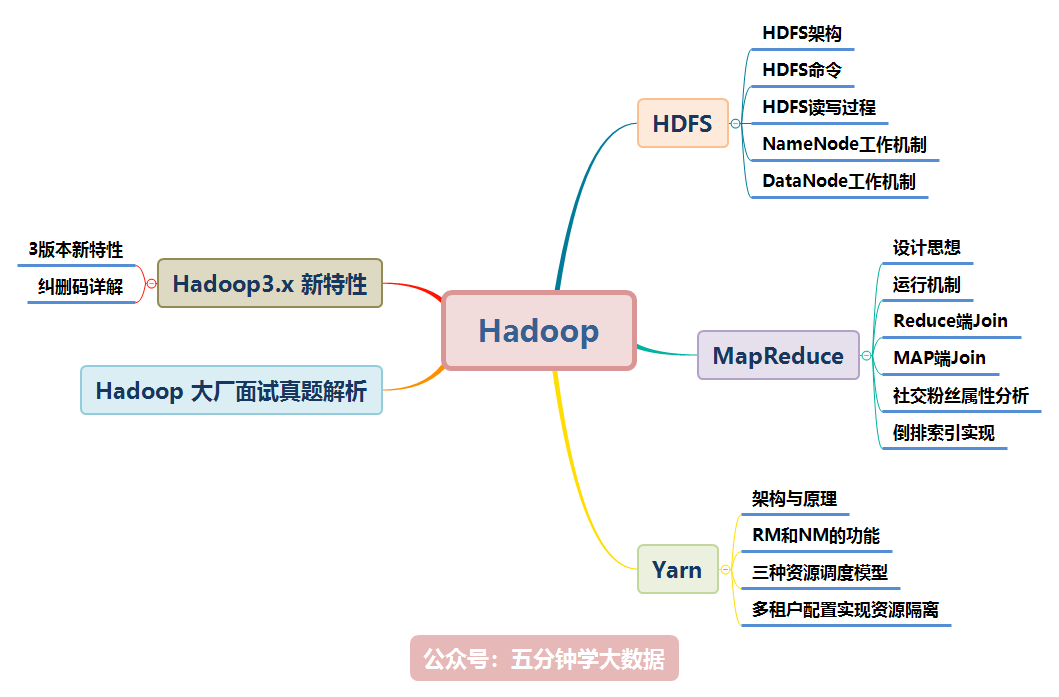
Hadoop 涉及的知识点如下图所示,本文将逐一讲解:
本文档参考了关于 Hadoop 的官网及其他众多资料整理而成,为了整洁的排版及舒适的阅读,对于模糊不清晰的图片及黑白图片进行重新绘制成了高清彩图。
目前企业应用较多的是Hadoop2.x,所以本文是以Hadoop2.x为主,对于Hadoop3.x新增的内容会进行说明!
二、MapReduce
1. MapReduce 介绍
MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
- Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
- Reduce负责“合”,即对map阶段的结果进行全局汇总。
- MapReduce运行在yarn集群
- ResourceManager
- NodeManager
这两个阶段合起来正是MapReduce思想的体现。
还有一个比较形象的语言解释MapReduce:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
1.1 MapReduce 设计构思
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop集群上。
既然是做计算的框架,那么表现形式就是有个输入(input),MapReduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output)。
对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而MapReduce就是一种简化并行计算的编程模型,降低了开发并行应用的入门门槛。
Hadoop MapReduce构思体现在如下的三个方面:
- 如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
- 构建抽象模型:Map和Reduce
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对Map的中间结果进行某种进一步的结果整理。
MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。通过以上两个编程接口,大家可以看出MapReduce处理的数据类型是<key,value>键值对。
- MapReduce框架结构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
- MR AppMaster:负责整个程序的过程调度及状态协调;
- MapTask:负责map阶段的整个数据处理流程;
- ReduceTask:负责reduce阶段的整个数据处理流程。
2. MapReduce 编程规范
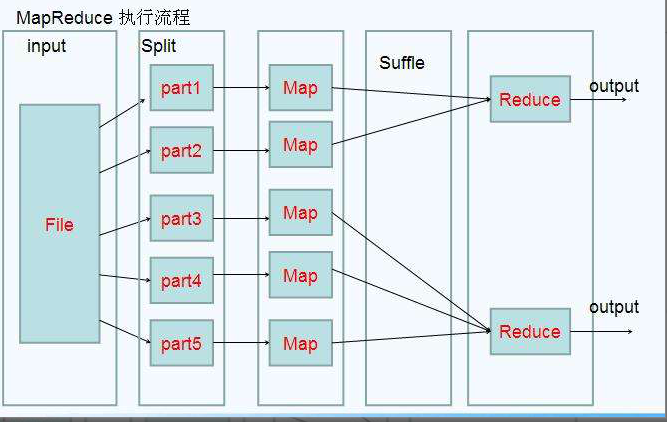
MapReduce 的开发一共有八个步骤, 其中 Map 阶段分为 2 个步骤,Shuffle 阶段 4 个步骤,Reduce 阶段分为 2 个步骤
- Map 阶段 2 个步骤:
- 1.1 设置 InputFormat 类, 将数据切分为 Key-Value(K1和V1) 对, 输入到第二步
- 1.2 自定义 Map 逻辑, 将第一步的结果转换成另外的 Key-Value(K2和V2) 对, 输出结果
- Shuffle 阶段 4 个步骤:
- 2.1 对输出的 Key-Value 对进行分区
- 2.2 对不同分区的数据按照相同的 Key 排序
- 2.3 (可选) 对分组过的数据初步规约, 降低数据的网络拷贝
- 2.4 对数据进行分组, 相同 Key 的 Value 放入一个集合中
- Reduce 阶段 2 个步骤:
- 3.1 对多个 Map 任务的结果进行排序以及合并, 编写 Reduce 函数实现自己的逻辑, 对输入的 Key-Value 进行处理, 转为新的 Key-Value(K3和V3)输出
- 3.2 设置 OutputFormat 处理并保存 Reduce 输出的 Key-Value 数据
3. Mapper以及Reducer抽象类介绍
为了开发我们的MapReduce程序,一共可以分为以上八个步骤,其中每个步骤都是一个class类,我们通过job对象将我们的程序组装成一个任务提交即可。为了简化我们的MapReduce程序的开发,每一个步骤的class类,都有一个既定的父类,让我们直接继承即可,因此可以大大简化我们的MapReduce程序的开发难度,也可以让我们快速的实现功能开发。
MapReduce编程当中,其中最重要的两个步骤就是我们的Mapper类和Reducer类
- Mapper抽象类的基本介绍
在hadoop2.x当中Mapper类是一个抽象类,我们只需要覆写一个java类,继承自Mapper类即可,然后重写里面的一些方法,就可以实现我们特定的功能,接下来我们来介绍一下Mapper类当中比较重要的四个方法
setup方法:
我们Mapper类当中的初始化方法,我们一些对象的初始化工作都可以放到这个方法里面来实现map方法:
读取的每一行数据,都会来调用一次map方法,这个方法也是我们最重要的方法,可以通过这个方法来实现我们每一条数据的处理cleanup方法:
在我们整个maptask执行完成之后,会马上调用cleanup方法,这个方法主要是用于做我们的一些清理工作,例如连接的断开,资源的关闭等等run方法:
如果我们需要更精细的控制我们的整个MapTask的执行,那么我们可以覆写这个方法,实现对我们所有的MapTask更精确的操作控制
- Reducer抽象类基本介绍
同样的道理,在我们的hadoop2.x当中,reducer类也是一个抽象类,抽象类允许我们可以继承这个抽象类之后,重新覆写抽象类当中的方法,实现我们的逻辑的自定义控制。接下来我们也来介绍一下Reducer抽象类当中的四个抽象方法
setup方法:
在我们的ReduceTask初始化之后马上调用,我们的一些对象的初始化工作,都可以在这个类当中实现reduce方法:
所有从MapTask发送过来的数据,都会调用reduce方法,这个方法也是我们reduce当中最重要的方法,可以通过这个方法实现我们的数据的处理cleanup方法:
在我们整个ReduceTask执行完成之后,会马上调用cleanup方法,这个方法主要就是在我们reduce阶段处理做我们一些清理工作,例如连接的断开,资源的关闭等等run方法:
如果我们需要更精细的控制我们的整个ReduceTask的执行,那么我们可以覆写这个方法,实现对我们所有的ReduceTask更精确的操作控制
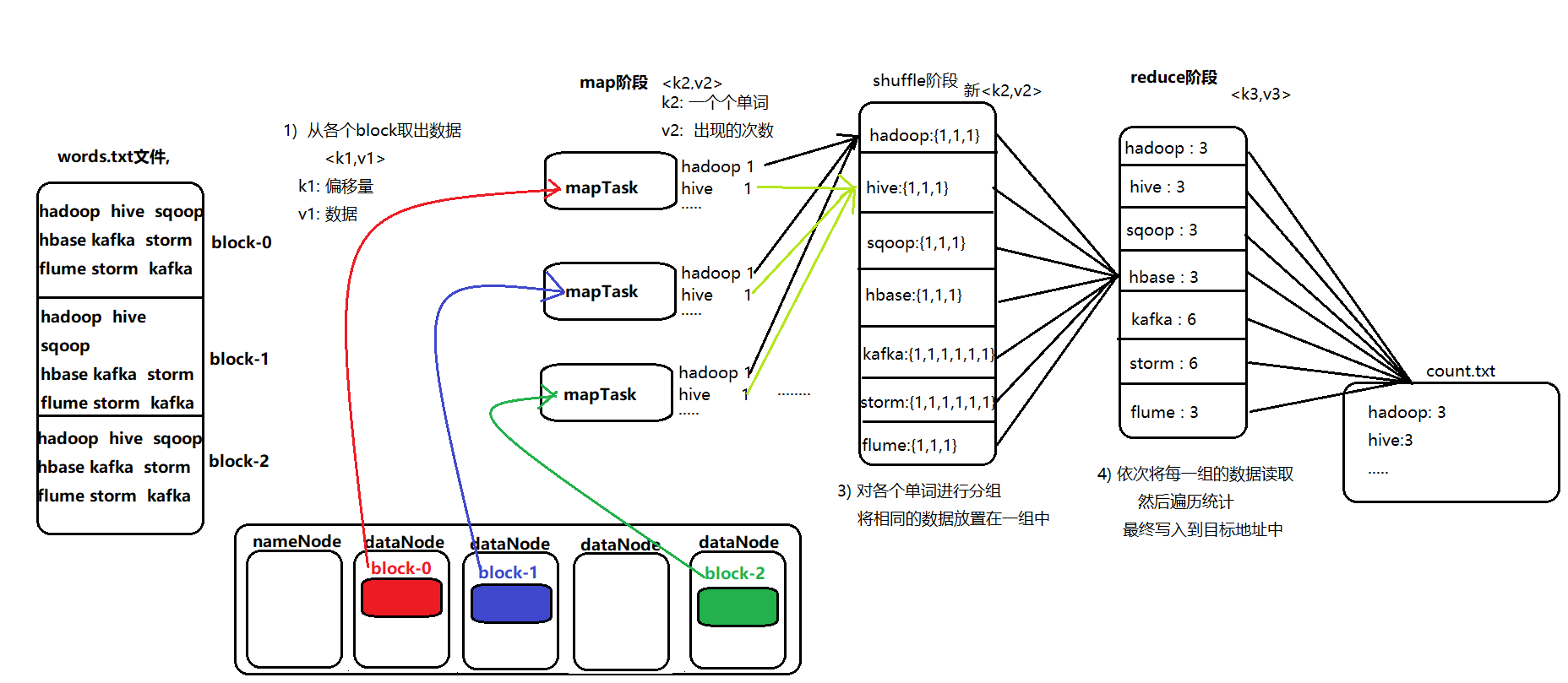
4. WordCount示例编写
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
node01服务器执行以下命令,准备数,数据格式准备如下:
cd /export/servers
vim wordcount.txt
#添加以下内容:
hello hello
world world
hadoop hadoop
hello world
hello flume
hadoop hive
hive kafka
flume storm
hive oozie
将数据文件上传到hdfs上面去
hdfs dfs -mkdir /wordcount/
hdfs dfs -put wordcount.txt /wordcount/
- 定义一个mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// mapper程序: 需要继承 mapper类, 需要传入 四个类型:
/* 在hadoop中, 对java的类型都进行包装, 以提高传输的效率 writable
keyin : k1 Long ---- LongWritable
valin : v1 String ------ Text
keyout : k2 String ------- Text
valout : v2 Long -------LongWritable
*/
public class MapTask extends Mapper<LongWritable,Text,Text,LongWritable> {
/**
*
* @param key : k1
* @param value v1
* @param context 上下文对象 承上启下功能
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. 获取 v1 中数据
String val = value.toString();
//2. 切割数据
String[] words = val.split(" ");
Text text = new Text();
LongWritable longWritable = new LongWritable(1);
//3. 遍历循环, 发给 reduce
for (String word : words) {
text.set(word);
context.write(text,longWritable);
}
}
}
- 定义一个reducer类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN : k2 -----Text
* VALUEIN : v2 ------LongWritable
* KEYOUT : k3 ------ Text
* VALUEOUT : v3 ------ LongWritable
*/
public class ReducerTask extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//1. 遍历 values 获取每一个值
long v3 = 0;
for (LongWritable longWritable : values) {
v3 += longWritable.get(); //1
}
//2. 输出
context.write(key,new LongWritable(v3));
}
}
- 定义一个主类,用来描述job并提交job
import com.sun.org.apache.bcel.internal.generic.NEW;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.nativeio.NativeIO;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
// 任务的执行入口: 将八步组合在一起
public class JobMain extends Configured implements Tool {
// 在run方法中编写组装八步
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), "JobMain");
//如果提交到集群操作. 需要添加一步 : 指定入口类
job.setJarByClass(JobMain.class);
//1. 封装第一步: 读取数据
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/wordcount.txt"));
//2. 封装第二步: 自定义 map程序
job.setMapperClass(MapTask.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//3. 第三步 第四步 第五步 第六步 省略
//4. 第七步: 自定义reduce程序
job.setReducerClass(ReducerTask.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//5) 第八步 : 输出路径是一个目录, 而且这个目录必须不存在的
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/output"));
//6) 提交任务:
boolean flag = job.waitForCompletion(true); // 成功 true 不成功 false
return flag ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
JobMain jobMain = new JobMain();
int i = ToolRunner.run(configuration, jobMain, args); //返回值 退出码
System.exit(i); // 退出程序 0 表示正常 其他值表示有异常 1
}
}
提醒:代码开发完成之后,就可以打成jar包放到服务器上面去运行了,实际工作当中,都是将代码打成jar包,开发main方法作为程序的入口,然后放到集群上面去运行
5. MapReduce程序运行模式
- 本地运行模式
- mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
- 而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
- 怎样实现本地运行?写一个程序,不要带集群的配置文件本质是程序的conf中是否有
mapreduce.framework.name=local以及yarn.resourcemanager.hostname=local参数 - 本地模式非常便于进行业务逻辑的debug,只要在idea中打断点即可
【本地模式运行代码设置】
configuration.set("mapreduce.framework.name","local");
configuration.set("yarn.resourcemanager.hostname","local");
-----------以上两个是不需要修改的,如果要在本地目录测试, 可有修改hdfs的路径-----------------
TextInputFormat.addInputPath(job,new Path("file:///D:\\wordcount\\input"));
TextOutputFormat.setOutputPath(job,new Path("file:///D:\\wordcount\\output"));
- 集群运行模式
将mapreduce程序提交给yarn集群,分发到很多的节点上并发执行
处理的数据和输出结果应该位于hdfs文件系统
提交集群的实现步骤:
将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
yarn jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.hdfs.demo1.JobMain
6. MapReduce的运行机制详解
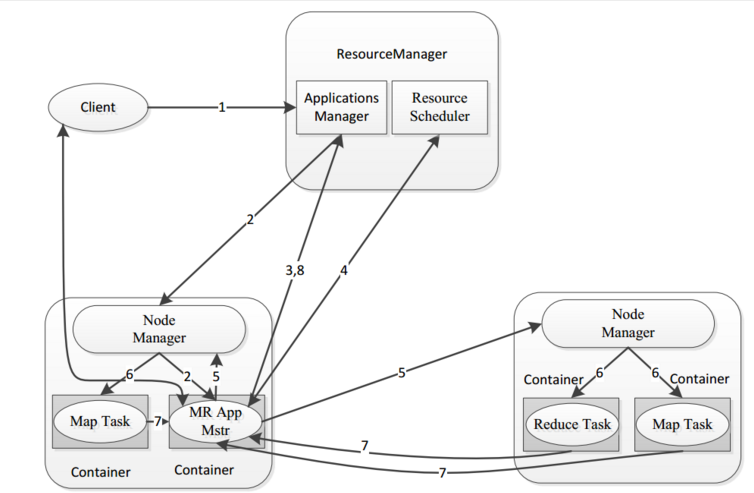
6.1 MapTask 工作机制
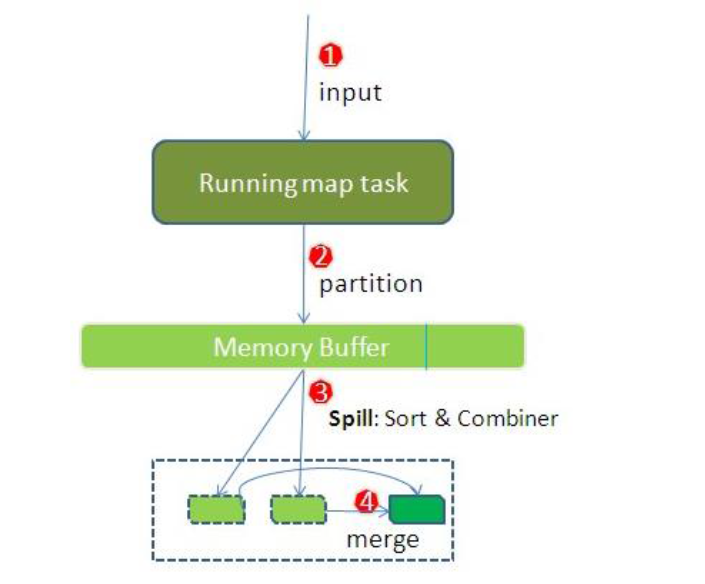
整个Map阶段流程大体如上图所示。
简单概述:inputFile通过split被逻辑切分为多个split文件,通过Record按行读取内容给map(用户自己实现的)进行处理,数据被map处理结束之后交给OutputCollector收集器,对其结果key进行分区(默认使用hash分区),然后写入buffer,每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据
详细步骤
- 读取数据组件 InputFormat (默认 TextInputFormat) 会通过
getSplits方法对输入目录中文件进行逻辑切片规划得到block, 有多少个block就对应启动多少个MapTask - 将输入文件切分为
block之后, 由RecordReader对象 (默认是LineRecordReader) 进行读取, 以\n作为分隔符, 读取一行数据, 返回<key,value>. Key 表示每行首字符偏移值, Value 表示这一行文本内容 - 读取
block返回<key,value>, 进入用户自己继承的 Mapper 类中,执行用户重写的 map 函数, RecordReader 读取一行这里调用一次 - Mapper 逻辑结束之后, 将 Mapper 的每条结果通过
context.write进行collect数据收集. 在 collect 中, 会先对其进行分区处理,默认使用 HashPartitioner
MapReduce 提供 Partitioner 接口, 它的作用就是根据 Key 或 Value 及 Reducer 的数量来决定当前的这对输出数据最终应该交由哪个 Reduce task 处理, 默认对 Key Hash 后再以 Reducer 数量取模. 默认的取模方式只是为了平均 Reducer 的处理能力, 如果用户自己对 Partitioner 有需求, 可以订制并设置到 Job 上
- 接下来, 会将数据写入内存, 内存中这片区域叫做环形缓冲区, 缓冲区的作用是批量收集 Mapper 结果, 减少磁盘 IO 的影响. 我们的 Key/Value 对以及 Partition 的结果都会被写入缓冲区. 当然, 写入之前,Key 与 Value 值都会被序列化成字节数组
环形缓冲区其实是一个数组, 数组中存放着 Key, Value 的序列化数据和 Key, Value 的元数据信息, 包括 Partition, Key 的起始位置, Value 的起始位置以及 Value 的长度. 环形结构是一个抽象概念。
缓冲区是有大小限制, 默认是 100MB. 当 Mapper 的输出结果很多时, 就可能会撑爆内存, 所以需要在一定条件下将缓冲区中的数据临时写入磁盘, 然后重新利用这块缓冲区. 这个从内存往磁盘写数据的过程被称为 Spill, 中文可译为溢写. 这个溢写是由单独线程来完成, 不影响往缓冲区写 Mapper 结果的线程. 溢写线程启动时不应该阻止 Mapper 的结果输出, 所以整个缓冲区有个溢写的比例 spill.percent. 这个比例默认是 0.8, 也就是当缓冲区的数据已经达到阈值 buffer size * spill percent = 100MB * 0.8 = 80MB, 溢写线程启动, 锁定这 80MB 的内存, 执行溢写过程. Mapper 的输出结果还可以往剩下的 20MB 内存中写, 互不影响
- 当溢写线程启动后, 需要对这 80MB 空间内的 Key 做排序 (Sort). 排序是 MapReduce 模型默认的行为, 这里的排序也是对序列化的字节做的排序
如果 Job 设置过 Combiner, 那么现在就是使用 Combiner 的时候了. 将有相同 Key 的 Key/Value 对的 Value 合并在起来, 减少溢写到磁盘的数据量. Combiner 会优化 MapReduce 的中间结果, 所以它在整个模型中会多次使用
\
那哪些场景才能使用 Combiner 呢? 从这里分析, Combiner 的输出是 Reducer 的输入, Combiner 绝不能改变最终的计算结果. Combiner 只应该用于那种 Reduce 的输入 Key/Value 与输出 Key/Value 类型完全一致, 且不影响最终结果的场景. 比如累加, 最大值等. Combiner 的使用一定得慎重, 如果用好, 它对 Job 执行效率有帮助, 反之会影响 Reducer 的最终结果
- 合并溢写文件, 每次溢写会在磁盘上生成一个临时文件 (写之前判断是否有 Combiner), 如果 Mapper 的输出结果真的很大, 有多次这样的溢写发生, 磁盘上相应的就会有多个临时文件存在. 当整个数据处理结束之后开始对磁盘中的临时文件进行 Merge 合并, 因为最终的文件只有一个, 写入磁盘, 并且为这个文件提供了一个索引文件, 以记录每个reduce对应数据的偏移量
【mapTask的一些基础设置配置】
| 配置 | 默认值 | 解释 |
|---|---|---|
mapreduce.task.io.sort.mb |
100 | 设置环型缓冲区的内存值大小 |
mapreduce.map.sort.spill.percent |
0.8 | 设置溢写的比例 |
mapreduce.cluster.local.dir |
${hadoop.tmp.dir}/mapred/local |
溢写数据目录 |
mapreduce.task.io.sort.factor |
10 | 设置一次合并多少个溢写文件 |
6.2 ReduceTask 工作机制
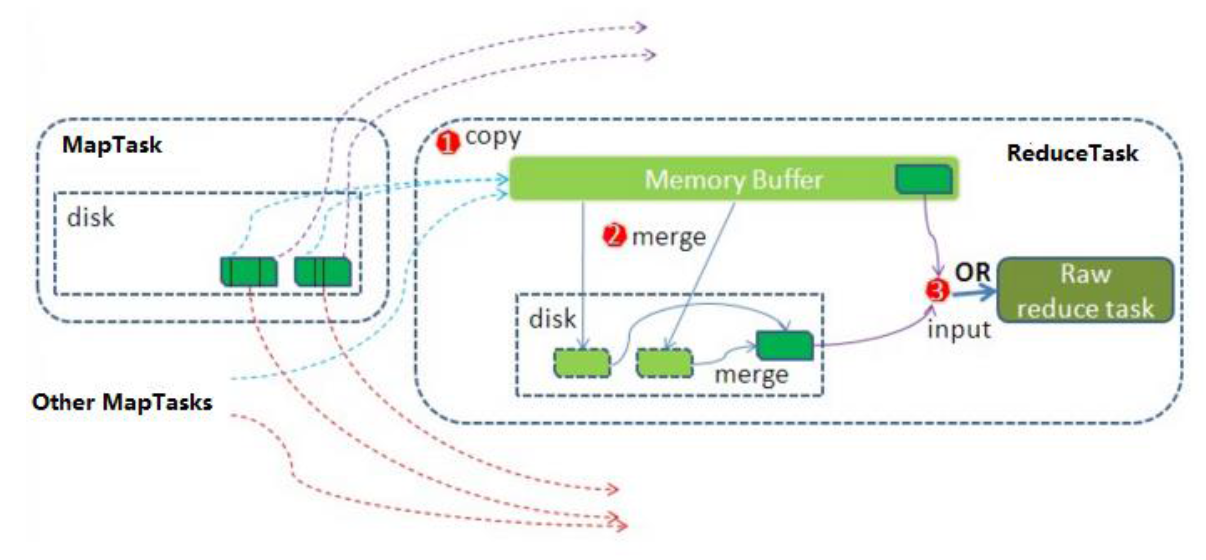
Reduce 大致分为 copy、sort、reduce 三个阶段,重点在前两个阶段。copy 阶段包含一个 eventFetcher 来获取已完成的 map 列表,由 Fetcher 线程去 copy 数据,在此过程中会启动两个 merge 线程,分别为 inMemoryMerger 和 onDiskMerger,分别将内存中的数据 merge 到磁盘和将磁盘中的数据进行 merge。待数据 copy 完成之后,copy 阶段就完成了,开始进行 sort 阶段,sort 阶段主要是执行 finalMerge 操作,纯粹的 sort 阶段,完成之后就是 reduce 阶段,调用用户定义的 reduce 函数进行处理
详细步骤
- Copy阶段,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求maptask获取属于自己的文件。
- Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活。merge有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的文件。
- 合并排序。把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
- 对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
6.3 Shuffle 过程
map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 shuffle
shuffle: 洗牌、发牌 ——(核心机制:数据分区,排序,分组,规约,合并等过程)
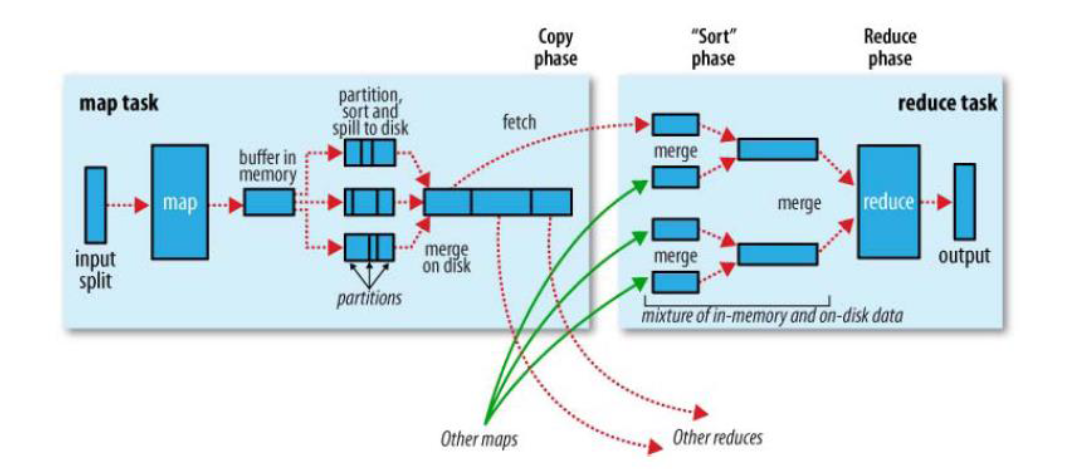
shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 阶段和 reduce 阶段。一般把从 Map 产生输出开始到 Reduce 取得数据作为输入之前的过程称作 shuffle。
Collect阶段:将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存的是 key/value,Partition 分区信息等。Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了 combiner,还会将有相同分区号和 key 的数据进行排序。Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个 MapTask 最终只产生一个中间数据文件。Copy阶段:ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。Merge阶段:在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。Sort阶段:在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶段已经对数据进行了局部的排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:mapreduce.task.io.sort.mb 默认100M
7. Reduce 端实现 JOIN
7.1 需求
假如数据量巨大,两表的数据是以文件的形式存储在 HDFS 中, 需要用 MapReduce 程序来实现以下 SQL 查询运算
select a.id,a.date,b.name,b.category_id,b.price from t_order a left join t_product b on a.pid = b.id
- 商品表
| id | pname | category_id | price |
|---|---|---|---|
| P0001 | 小米5 | 1000 | 2000 |
| P0002 | 锤子T1 | 1000 | 3000 |
- 订单数据表
| id | date | pid | amount |
|---|---|---|---|
| 1001 | 20150710 | P0001 | 2 |
| 1002 | 20150710 | P0002 | 3 |
7.2 实现步骤
通过将关联的条件作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task,在reduce中进行数据的串联
- 定义orderBean
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderJoinBean implements Writable {
private String id=""; // 订单id
private String date=""; //订单时间
private String pid=""; // 商品的id
private String amount=""; // 订单的数量
private String name=""; //商品的名称
private String categoryId=""; // 商品的分类id
private String price=""; //商品的价格
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public String getAmount() {
return amount;
}
public void setAmount(String amount) {
this.amount = amount;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCategoryId() {
return categoryId;
}
public void setCategoryId(String categoryId) {
this.categoryId = categoryId;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
@Override
public String toString() {
return id + "\t" + date + "\t" + pid + "\t" + amount + "\t" + name + "\t" + categoryId + "\t" + price;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(date);
out.writeUTF(pid);
out.writeUTF(amount);
out.writeUTF(name);
out.writeUTF(categoryId);
out.writeUTF(price);
}
@Override
public void readFields(DataInput in) throws IOException {
id = in.readUTF();
date = in.readUTF();
pid = in.readUTF();
amount = in.readUTF();
name = in.readUTF();
categoryId = in.readUTF();
price = in.readUTF();
}
}
- 定义 Mapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class MapperJoinTask extends Mapper<LongWritable,Text,Text,OrderJoinBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 通过文件片的方式获取文件的名称
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
//1. 获取每一行的数据
String line = value.toString();
//2. 切割处理
String[] split = line.split(",");
OrderJoinBean orderJoinBean = new OrderJoinBean();
if(fileName.equals("orders.txt")){
// 订单的数据
orderJoinBean.setId(split[0]);
orderJoinBean.setDate(split[1]);
orderJoinBean.setPid(split[2]);
orderJoinBean.setAmount(split[3]);
}else{
// 商品的数据
orderJoinBean.setPid(split[0]);
orderJoinBean.setName(split[1]);
orderJoinBean.setCategoryId(split[2]);
orderJoinBean.setPrice(split[3]);
}
//3. 发送给reduceTask
context.write(new Text(orderJoinBean.getPid()),orderJoinBean);
}
}
- 定义 Reducer
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReducerJoinTask extends Reducer<Text,OrderJoinBean,Text,OrderJoinBean> {
@Override
protected void reduce(Text key, Iterable<OrderJoinBean> values, Context context) throws IOException, InterruptedException {
//1. 遍历 : 相同的key会发给同一个reduce, 相同key的value的值形成一个集合
OrderJoinBean orderJoinBean = new OrderJoinBean();
for (OrderJoinBean value : values) {
String id = value.getId();
if(id.equals("")){
// 商品的数据
orderJoinBean.setPid(value.getPid());
orderJoinBean.setName(value.getName());
orderJoinBean.setCategoryId(value.getCategoryId());
orderJoinBean.setPrice(value.getPrice());
}else {
// 订单数据
orderJoinBean.setId(value.getId());
orderJoinBean.setDate(value.getDate());
orderJoinBean.setPid(value.getPid());
orderJoinBean.setAmount(value.getAmount());
}
}
//2. 输出即可
context.write(key,orderJoinBean);
}
}
- 定义主类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobReduceJoinMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1. 获取job对象
Job job = Job.getInstance(super.getConf(), "jobReduceJoinMain");
//2. 拼装八大步骤
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\reduce端join\\input"));
job.setMapperClass(MapperJoinTask.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(OrderJoinBean.class);
job.setReducerClass(ReducerJoinTask.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(OrderJoinBean.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("D:\\reduce端join\\out_put"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
JobReduceJoinMain jobReduceJoinMain = new JobReduceJoinMain();
int i = ToolRunner.run(conf, jobReduceJoinMain, args);
System.exit(i);
}
}
缺点:这种方式中,join的操作是在reduce阶段完成,reduce端的处理压力太大,map节点的运算负载则很低,资源利用率不高,且在reduce阶段极易产生数据倾斜
8. Map端实现 JOIN
8.1 概述
适用于关联表中有小表的情形.
使用分布式缓存,可以将小表分发到所有的map节点,这样,map节点就可以在本地对自己所读到的大表数据进行join并输出最终结果,可以大大提高join操作的并发度,加快处理速度
8.2 实现步骤
先在mapper类中预先定义好小表,进行join
引入实际场景中的解决方案:一次加载数据库
- 定义Mapper
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapperTask extends Mapper<LongWritable, Text, Text, Text> {
private Map<String,String> map = new HashMap<>();
// 初始化的方法, 只会被初始化一次
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cacheFiles = DistributedCache.getCacheFiles(context.getConfiguration());
URI fileURI = cacheFiles[0];
FileSystem fs = FileSystem.get(fileURI, context.getConfiguration());
FSDataInputStream inputStream = fs.open(new Path(fileURI));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String readLine ="";
while ((readLine = bufferedReader.readLine() ) != null ) {
// readlLine: product一行数据
String[] split = readLine.split(",");
String pid = split[0];
map.put(pid,split[1]+"\t"+split[2]+"\t"+split[3]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. 读取一行数据: orders数据
String line = value.toString();
//2. 切割
String[] split = line.split(",");
String pid = split[2];
//3. 到map中获取商品信息:
String product = map.get(pid);
//4. 发送给reduce: 输出
context.write(new Text(pid),new Text(split[0]+"\t"+split[1]+"\t"+product +"\t"+split[3]));
}
}
- 定义主类
import com.itheima.join.reduce.JobReduceJoinMain;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class JobMapperJoinMain extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception {
//设置缓存的位置, 必须在run的方法的最前, 如果放置在job任务创建后, 将无效
// 缓存文件的路径, 必须存储在hdfs上, 否则也是无效的
DistributedCache.addCacheFile(new URI("hdfs://node01:8020/cache/pdts.txt"),super.getConf());
//1. 获取job 任务
Job job = Job.getInstance(super.getConf(), "jobMapperJoinMain");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("E:\\传智工作\\上课\\北京大数据30期\\大数据第六天\\资料\\map端join\\map_join_iput"));
job.setMapperClass(MapperTask.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("E:\\传智工作\\上课\\北京大数据30期\\大数据第六天\\资料\\map端join\\out_put_map"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
JobMapperJoinMain jobMapperJoinMain = new JobMapperJoinMain();
int i = ToolRunner.run(conf, jobMapperJoinMain, args);
System.exit(i);
}
}
9. 社交粉丝数据分析
9.1 需求分析
以下是qq的好友列表数据,冒号前是一个用户,冒号后是该用户的所有好友(数据中的好友关系是单向的)
A:B,C,D,F,E,O
B:A,C,E,K
C:A,B,D,E,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
【解题思路】
第一步
map
读一行 A:B,C,D,F,E,O
输出 <B,A><C,A><D,A><F,A><E,A><O,A>
在读一行 B:A,C,E,K
输出 <A,B><C,B><E,B><K,B>
REDUCE
拿到的数据比如<C,A><C,B><C,E><C,F><C,G>......
输出:
<A-B,C>
<A-E,C>
<A-F,C>
<A-G,C>
<B-E,C>
<B-F,C>.....
第二步
map
读入一行<A-B,C>
直接输出<A-B,C>
reduce
读入数据 <A-B,C><A-B,F><A-B,G>.......
输出: A-B C,F,G,.....
9.2 实现步骤
第一个MapReduce代码实现
【Mapper类】
public class Step1Mapper extends Mapper<LongWritable,Text,Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1:以冒号拆分行文本数据: 冒号左边就是V2
String[] split = value.toString().split(":");
String userStr = split[0];
//2:将冒号右边的字符串以逗号拆分,每个成员就是K2
String[] split1 = split[1].split(",");
for (String s : split1) {
//3:将K2和v2写入上下文中
context.write(new Text(s), new Text(userStr));
}
}
}
【Reducer类】
public class Step1Reducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//1:遍历集合,并将每一个元素拼接,得到K3
StringBuffer buffer = new StringBuffer();
for (Text value : values) {
buffer.append(value.toString()).append("-");
}
//2:K2就是V3
//3:将K3和V3写入上下文中
context.write(new Text(buffer.toString()), key);
}
}
JobMain:
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1:获取Job对象
Job job = Job.getInstance(super.getConf(), "common_friends_step1_job");
//2:设置job任务
//第一步:设置输入类和输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("file:///D:\\input\\common_friends_step1_input"));
//第二步:设置Mapper类和数据类型
job.setMapperClass(Step1Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//第三,四,五,六
//第七步:设置Reducer类和数据类型
job.setReducerClass(Step1Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步:设置输出类和输出的路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("file:///D:\\out\\common_friends_step1_out"));
//3:等待job任务结束
boolean bl = job.waitForCompletion(true);
return bl ? 0: 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
第二个MapReduce代码实现
【Mapper类】
public class Step2Mapper extends Mapper<LongWritable,Text,Text,Text> {
/*
K1 V1
0 A-F-C-J-E- B
----------------------------------
K2 V2
A-C B
A-E B
A-F B
C-E B
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1:拆分行文本数据,结果的第二部分可以得到V2
String[] split = value.toString().split("\t");
String friendStr =split[1];
//2:继续以'-'为分隔符拆分行文本数据第一部分,得到数组
String[] userArray = split[0].split("-");
//3:对数组做一个排序
Arrays.sort(userArray);
//4:对数组中的元素进行两两组合,得到K2
/*
A-E-C -----> A C E
A C E
A C E
*/
for (int i = 0; i <userArray.length -1 ; i++) {
for (int j = i+1; j < userArray.length ; j++) {
//5:将K2和V2写入上下文中
context.write(new Text(userArray[i] +"-"+userArray[j]), new Text(friendStr));
}
}
}
}
【Reducer类】
public class Step2Reducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//1:原来的K2就是K3
//2:将集合进行遍历,将集合中的元素拼接,得到V3
StringBuffer buffer = new StringBuffer();
for (Text value : values) {
buffer.append(value.toString()).append("-");
}
//3:将K3和V3写入上下文中
context.write(key, new Text(buffer.toString()));
}
}
【JobMain】
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1:获取Job对象
Job job = Job.getInstance(super.getConf(), "common_friends_step2_job");
//2:设置job任务
//第一步:设置输入类和输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("file:///D:\\out\\common_friends_step1_out"));
//第二步:设置Mapper类和数据类型
job.setMapperClass(Step2Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//第三,四,五,六
//第七步:设置Reducer类和数据类型
job.setReducerClass(Step2Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步:设置输出类和输出的路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("file:///D:\\out\\common_friends_step2_out"));
//3:等待job任务结束
boolean bl = job.waitForCompletion(true);
return bl ? 0: 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
10. 倒排索引建立
10.1 需求分析
需求:有大量的文本(文档、网页),需要建立搜索索引
思路分析:
首选将文档的内容全部读取出来,加上文档的名字作为key,文档的value为1,组织成这样的一种形式的数据
map端数据输出:
hello-a.txt 1
hello-a.txt 1
hello-a.txt 1
reduce端数据输出:
hello-a.txt 3
10.2 代码实现
public class IndexCreate extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new IndexCreate(),args);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), IndexCreate.class.getSimpleName());
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\倒排索引\\input"));
job.setMapperClass(IndexCreateMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(IndexCreateReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///D:\\倒排索引\\outindex"));
boolean bool = job.waitForCompletion(true);
return bool?0:1;
}
public static class IndexCreateMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
Text text = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取文件切片
FileSplit fileSplit = (FileSplit) context.getInputSplit();
//通过文件切片获取文件名
String name = fileSplit.getPath().getName();
String line = value.toString();
String[] split = line.split(" ");
//输出 单词--文件名作为key value是1
for (String word : split) {
text.set(word+"--"+name);
context.write(text,v);
}
}
}
public static class IndexCreateReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable value = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
value.set(count);
context.write(key,value);
}
}
}
Hadoop MapReduce 保姆级吐血宝典,学习与面试必读此文!的更多相关文章
- 四万字32图,Kafka知识体系保姆级教程宝典
本文目录: 一.消息队列 Apache Pulsar Pulsar 与 Kafka 对比 二.Kafka基础 三.Kafka架构及组件 四.Kafka集群操作 五.Kafka的JavaAPI操作 六. ...
- 保姆级教程——Ubuntu16.04 Server下深度学习环境搭建:安装CUDA8.0,cuDNN6.0,Bazel0.5.4,源码编译安装TensorFlow1.4.0(GPU版)
写在前面 本文叙述了在Ubuntu16.04 Server下安装CUDA8.0,cuDNN6.0以及源码编译安装TensorFlow1.4.0(GPU版)的亲身经历,包括遇到的问题及解决办法,也有一些 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- JavaWeb和WebGIS学习笔记(七)——MapGuide Open Source安装、配置以及MapGuide Maestro发布地图——超详细!目前最保姆级的MapGuide上手指南!
JavaWeb和WebGIS学习笔记(七)--MapGuide Open Source安装.配置以及MapGuide Maestro发布地图 超详细!目前最保姆级的MapGuide上手指南! 系列链接 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
随机推荐
- Python之pytesseract模块-实现OCR
在给PC端应用做自动化测试时,某些情况下无法定位界面上的控件,但我们又想获得界面上的文字,则可以通过截图后从图片上去获取该文字信息.那么,Python中有没有对应的工具来实现OCR呢?答案是有的,它叫 ...
- 🏆【Alibaba工具型技术系列】「EasyExcel技术专题」摒除OOM!让你的Excel操作变得更加优雅和安全
前提概要 针对于后端开发者而言的,作为报表的导入和导出是一个很基础且有很棘手的问题!之前常用的工具和方案大概有这么几种: JXL(Java Excel API 工具服务),此种只支持xls的文件格式, ...
- Activiti 学习(一)—— Activiti 基础
工作流概述 在一个公司中,每一项业务的开始和结束,都可以理解为一个工作流,例如,公司的费用报销的基本流程如下: 如图所示的工作流:员工先提出费用报销申请,提交该申请给部门领导,部门领导审批后,再提交给 ...
- Python入门学习之:10分钟1500访问量
看效果: 不扯没用的,直接上代码: # author : sunzd # date : 2019/9/01 # position : beijing from fake_useragent impor ...
- view+element+java登陆验证码
一.前端: 1.页面标签: <el-row :gutter="20"> <el-col :span="24"> <el-input ...
- 【曹工杂谈】Maven IOC容器的下半场:Google Guice
Maven容器的下半场:Guice 前言 在前面的文章里,Maven底层容器Plexus Container的前世今生,一代芳华终落幕,我们提到,在Plexus Container退任后,取而代之的底 ...
- ByteArrayOutputStream小测试
import java.io.*; import org.junit.Test; public class ByteArrayOutputStreamTest { @Test public void ...
- java中各个类相互调用资源的原理
当我们要进行跨类的调用/使用的时候,比如当前类调用另一个类中的变量或方法时, 这时需要一定的条件,如果那些将要被调用的变量或方法是static(静态)变量,也叫类变 量,那么可以通过类名调用,相 ...
- Docker部署启动错误,需要手动进入Docker的容器里,启动程序,排查错误
#docker-compose build --no-cache //重新创建容器,不管有没有 #docker-compose up #docker-compose up -d //后台启动并运行容器 ...
- Android学习记录(一)——安装Android Studio
"工欲善其事必先利其器"学习安卓开发的第一步,安装Android Studio. 一.什么是Android Studio? Android Studio 是谷歌推出的一个Andro ...