Stream中的Pipeline理解
使用Stream已经快3年了,但是从未真正深入研究过Stream的底层实现。
今天开始把最近学到的Stream原理记录一下。
本篇文章简单描述一下自己对pipeline的理解。
基于下面一段代码:
public static void main(String[] args) {
List<String> list = Arrays.asList("123", "123123");
list.stream().map(item -> item+"").forEach(System.out::print);
}
1. stream()方法
显然,这里的list对象是一个ArrayList实例,debug代码进入stream方法,可以看见进入到Collection.java类中的stream()中

这里的源码如下:
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
关于分割迭代器的内容会在另外一篇文章详解,这里不再赘述。
进入StreamSupport.stream()方法:
StreamSupport.java
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
咱们可以看到Stream是一个ReferencePipeline.Head类的实例,
通过idea的类图结构功能,我们可以看到下面这个层次结构:
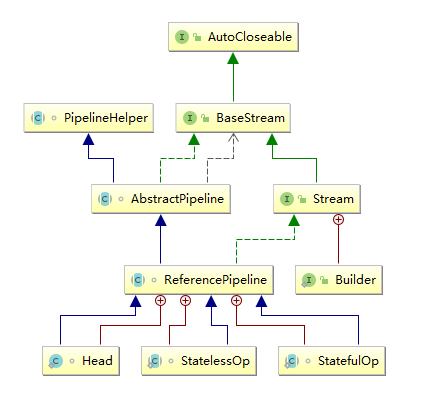
所有的流基本都是来自于BaseStream,AbstractPipeline,ReferencePipeline这三个抽象类或接口。
ReferencePipeline的实现类一共就三种:
- Head
- StatelessOp
- StatefulOp
查看了源码即可知道:AbstractPipeline其实就是一个双向链表中的一个节点。【我是这么理解的】
Head:代表的是流的源头,刚构建的时候流的一些属性被包含在这个对象。比如这个集合的元素,毕竟流的存在还是为了对一组元素的操作。
StatelessOp:代表的是无状态的操作,如map()
StatefulOp:代表的是有状态的操作,如sorted()
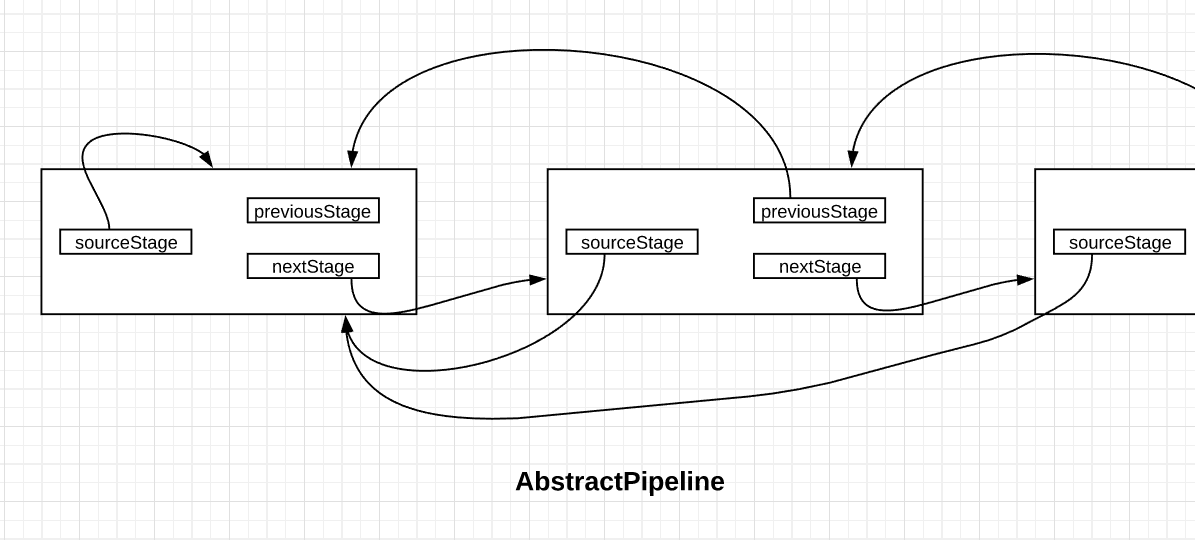
图中的每个节点都是一个AbstractPipeline的实现。
所以stream()方法执行之后,拿到的是一个ReferencePipeline.Head实例,并没有构建StatelessOp,StatefulOp实例。
2. map()方法
因为stream方法返回值是一个Head实例,而Head类并未重写map方法,所以map方法的实际执行还是走的ReferencePipeline类的map方法,如下:
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
这里的返回是一个继承于StatelessOp的匿名类。
关于Sink和TerminalOp的详解后续会单独开文章分析。
这里只需要理解这个map的返回值是一个继承于StatelessOp的匿名类。(StatelessOp是一个ReferencePipeline的实现)
3. forEach()方法
前提:流是含有流源的对象,并且它支持0个或多个中间操作,1个终止操作的特性。
通过idea查看发现foreach的实现有2个:

第一个是Head的实现,因为流源构造出来之后,直接调用forEach,有它自己的实现,对迭代做了优化。这里可后续添加细致分析。
第二个是ReferencePipeline的实现,即调用终止操作的节点不是流源节点。
我们这里只分析ReferencePipeline中的实现:
public void forEach(Consumer<? super P_OUT> action) {
/**
* ForEachOps.makeRef(action, false) 是构建终止操作,参考3.1
* evaluate()是触发终止操作的调用,参考3.2
*/
evaluate(ForEachOps.makeRef(action, false));
}
这里的evaluate方法可以想象成“执行”的意思。
ForEachOps.makeRef(action, false)方法可以想象成“构造一个终止操作”。--终止操作是一个名词,这里只是一个对象而已,如果这个“操作”没有得到触发,那么流什么也不会干。
所以这个evaluate可以理解成fire action performed.
3.1 构建终止操作
首先来看看TerminalOp接口,这是所有终止操作的抽象,每一个终止操作都是它的子类。
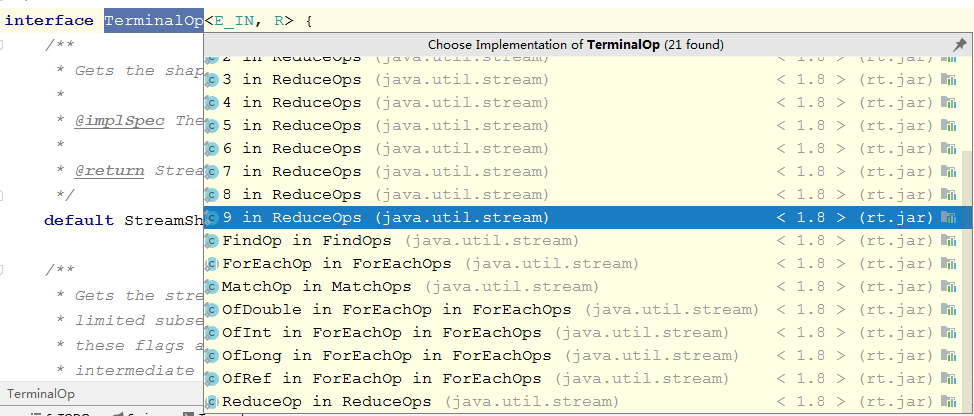
查看它的实现类,可以发现它的实现类的特点:
- FindOp in FindOps
示例:findFirst() - ReduceOp in ReduceOps
示例:reduce(BigDecimal.Zero, BigDecimal::add) - ForEachOp in ForEachOps
示例:forEach() - MatchOp in MatchOps
示例:anyMatch()
其中带s的是一个工厂类,用于生产不同的“终止操作”。
不带s的才是一个“终止操作”TerminalOp的实现类。
3.2 触发终止操作
其实这里也不是仅仅触发终止操作,这个方法里会把前面所有的中间操作apply到每一个元素上,并执行终止操作。
evaluate()的实现如下,暂时这里不做过多讨论,后续在sink的单独一篇文章中,分析具体流的执行过程。
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
总结
本文只是为了理解:流pipeline是一个什么概念,以及它有什么样的基本特性?
1、流pipeline是一个双向链表的节点,前后引用。
2、流由流源,中间操作和终止操作组成。
3、终止操作被触发的时候,所有的操作(中间+终止)才会被一一应用到元素上。这称为流的惰性。
4、有一些操作是具有短路的特性的,如:findFirst等。
Stream中的Pipeline理解的更多相关文章
- 【Java 8】Stream中的Pipeline理解
基于下面一段代码: public static void main(String[] args) { List<String> list = Arrays.asList("123 ...
- Stream中的Collector收集器原理
前言 Stream的基本操作因为平时工作中用得非常多(也能看到一些同事把Stream操作写得很丑陋),所以基本用法就不写文章记录了. 之所以能把Stream的操作写得很丑陋,完全是因为Stream底层 ...
- 理解Laravel中的pipeline
理解Laravel中的pipeline suoga 关注 0.1 2015.09.08 00:00* 字数 1533 阅读 7151评论 8喜欢 24 pipeline在laravel的启动过程中出 ...
- [Linux] 流 ( Stream )、管道 ( Pipeline ) 、Filter - 笔记
流 ( Stream ) 1. 流,是指可使用的数据元素一个序列. 2. 流,可以想象为是传送带上等待加工处理的物品,也可以想象为工厂流水线上的物品. 3. 流,可以是无限的数据. 4. 有一种功能, ...
- JAVA8之lambda表达式具体解释,及stream中的lambda使用
前言: 本人也是学习lambda不久,可能有些地方描写叙述有误,还请大家谅解及指正! lambda表达式具体解释 一.问题 1.什么是lambda表达式? 2.lambda表达式用来干什么的? 3.l ...
- Fouandation(NSString ,NSArray,NSDictionary,NSSet) 中常见的理解错误区
Fouandation 中常见的理解错误区 1.NSString //快速创建(实例和类方法) 存放的地址是 常量区 NSString * string1 = [NSString alloc]init ...
- linux中socket的理解
对linux中socket的理解 一.socket 一般来说socket有一个别名也叫做套接字. socket起源于Unix,都可以用“打开open –> 读写write/read –> ...
- BizTalk开发系列(十一) 在Orchestration中执行Pipeline
由于开发需要有时要在流程中执行Pipeline.比如从DB的某个字段中取消息的字符串并在流程中构造消息.该需要通过pipeline进行升级 属性字段,验证消息等处理.BizTalk架构已经开放了此接口 ...
- 谈谈我对Java中CallBack的理解
谈谈我对Java中CallBack的理解 http://www.cnblogs.com/codingmyworld/archive/2011/07/22/2113514.html CallBack是回 ...
随机推荐
- Spring事物入门简介及AOP陷阱分析
转载请注明出处: https://www.cnblogs.com/qnlcy/p/15237377.html 一.事务的定义 事务(Transaction),是指访问并可能更新数据库中各种数据项的一个 ...
- Django中使用MySQL数据库的连接配置
1. 安装pymysql pip install pymysql 2. 导入 # 在与 settings.py 同级目录下的 __init__.py 中引入模块和进行配置 import pymysql ...
- 20210809 Merchant,Equation,Rectangle
做过,但当时咕了 T3 Merchant 先特判 \(t=0\),之后斜率一定会起作用. 考虑最终选择的物品集合,它们的斜率和一定大于 \(0\),因此答案具有单调性,可以二分. 实现的时候注意细节 ...
- VS Code 搭建stm32开发环境
MCU免费开发环境 一般芯片厂家会提供各种开发IDE方案,通常其中就包括其自家的集成IDE,如: 意法半导体 STM32CubeIDE NXP Codewarrior TI CCS 另外也可以用ecl ...
- Redis——set,hash与列表
一.List列表 基于Linked List实现 元素是字符串类型 列表头尾增删快,中间增删慢,增删元素是常态 元素可以重复出现 最多包含2^32-1元素 列表的索引 从左至右,从0开始 从右至左,从 ...
- rune和byte在处理字符/字符串中的应用.
rune和byte在处理字符/字符串中的应用. 定义: rune是int32的别名,-2147483648->2147483647,常用来表示UNICODE字符集,可以用来处理包含中文/非中文的 ...
- 洛谷P1125——笨小猴(简易模拟)
https://www.luogu.org/problem/show?pid=1125 题目描述 笨小猴的词汇量很小,所以每次做英语选择题的时候都很头疼.但是他找到了一种方法,经试验证明,用这种方法去 ...
- 安卓学习记录(五)——体温表APP.2
一.项目结构 二.源码 1.数据层 db+dao+bean package com.example.tem.db; import android.content.Context; import and ...
- C#中List是链表吗?为什么可以通过下标访问
使用C#的同学对List应该并不陌生,我们不需要初始化它的大小,并且可以方便的使用Add和Remove方法执行添加和删除操作,但却可以使用下标来访问它的数据,它是我们常说的链表吗? List& ...
- disruptor笔记之三:环形队列的基础操作(不用Disruptor类)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...