爬虫简介、requests 基础用法、urlretrieve()
1. 爬虫简介
2. requests 基础用法
3. urlretrieve()
1. 爬虫简介
爬虫的定义
网络爬虫(又被称为网页蜘蛛、网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
爬虫有什么用
- 市场分析:电商分析、商圈分析、一二级市场分析等
- 市场监控:电商、新闻、房源监控等
- 商机发现:招投标情报发现、客户资料发掘、企业客户发现等
认识网址的构成
一个网站的网址一般由域名 + 自己编写的页面所构成。我们在访问同一网站的网页时,域名一般是不会改变的,因此我们爬虫所需要解析的就是网站自己所编写的不同页面的入口 url,只有解析出来各个页面的入口,才能开始我们的爬虫。
了解网页的两种加载方法
只有同步加载的数据才能直接在网页源代码中直接查看到,异步加载的数据直接查看网页源代码是看不到的。
- 同步加载:改变网址上的某些参数会导致网页发生改变,例如:www.itjuzi.com/company?page=1(改变 page= 后面的数字,网页会发生改变)。
- 异步加载:改变网址上的参数不会使网页发生改变,例如:www.lagou.com/gongsi/(翻页后网址不会发生变化)。
- 同步任务:在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务。
- 异步任务:不进入主线程,而进入"任务队列"(task queue)的任务。有等主线程任务执行完毕,"任务队列"开始通知主线程,请求执行任务,该任务才会进入主线程执行(如回调函数)。
认识网页源码的构成
- html:描述网页的内容结构
- css:描述网页的样式排版布局
- JavaScript:描述网页的事件处理,即鼠标或键盘在网页元素上的动作后的程序
查看网页请求
请求头(Request Headers):
- Accept: text/html,image/* (浏览器可以接收的类型)
- Accept-Charset: ISO-8859-1 (浏览器可以接收的编码类型)
- Accept-Encoding: gzip,compress (浏览器可以接收压缩编码类型)
- Accept-Language: en-us,zh-cn (浏览器可以接收的语言和国家类型)
- Host: www.it315.org:80 (浏览器请求的主机和端口)
- If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT (某个页面缓存时间)
- Referer: http://www.it315.org/index.jsp (请求来自于哪个页面)
- User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) (浏览器相关信息)
- Cookie: (浏览器暂存服务器发送的信息)
- Connection: close(1.0)/Keep-Alive(1.1) (HTTP请求的版本的特点)
- Date: Tue, 11 Jul 2000 18:23:51 GMT (请求网站的时间)
响应头(Response Headers):
- Location: http://www.it315.org/index.jsp (控制浏览器显示哪个页面)
- Server: apache tomcat (服务器的类型)
- Content-Encoding: gzip (服务器发送的压缩编码方式)
- Content-Length: 80 (服务器发送显示的字节码长度)
- Content-Language: zh-cn (服务器发送内容的语言和国家名)
- Content-Type: image/jpeg; charset=UTF-8 (服务器发送内容的类型和编码类型)
- Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT (服务器最后一次修改的时间)
- Refresh: 1;url=http://www.it315.org (控制浏览器1秒钟后转发URL所指向的页面)
- Content-Disposition: attachment; filename=aaa.jpg (服务器控制浏览器下载方式打开文件)
- Transfer-Encoding: chunked (服务器分块传递数据到客户端)
- Set-Cookie: SS=Q0=5Lb_nQ; path=/search (服务器发送Cookie相关的信息)
- Expires: -1 (服务器控制浏览器不要缓存网页,默认是缓存)
- Cache-Control: no-cache (服务器控制浏览器不要缓存网页)
- Pragma: no-cache (服务器控制浏览器不要缓存网页)
- Connection: close/Keep-Alive (HTTP请求的版本的特点)
- Date: Tue, 11 Jul 2000 18:23:51 GMT (响应网站的时间)
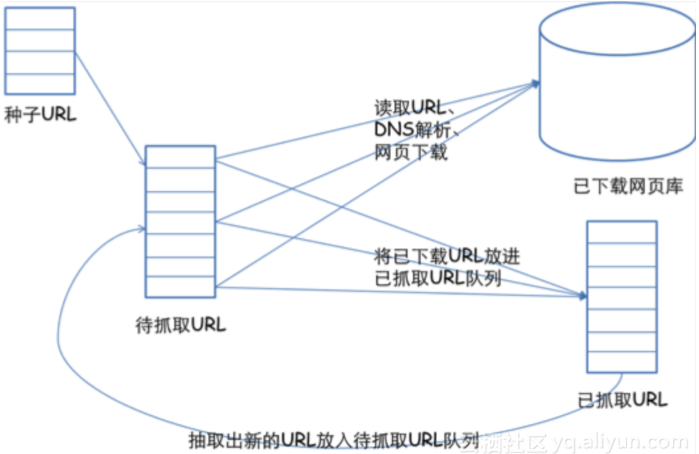
通用的网络爬虫框架
- 挑选种子 URL;
- 将这些 URL 放入待抓取的 URL 队列;
- 取出待抓取的 URL,下载并存储进已下载网页库中。此外,将这些 URL 放入已抓取 URL 队列;
- 分析已抓取队列中的 URL,并且将 URL 放入待抓取 URL 队列,从而进入下一循环。
2. requests 基础用法
详解:requests 库
Requests 库的主要方法
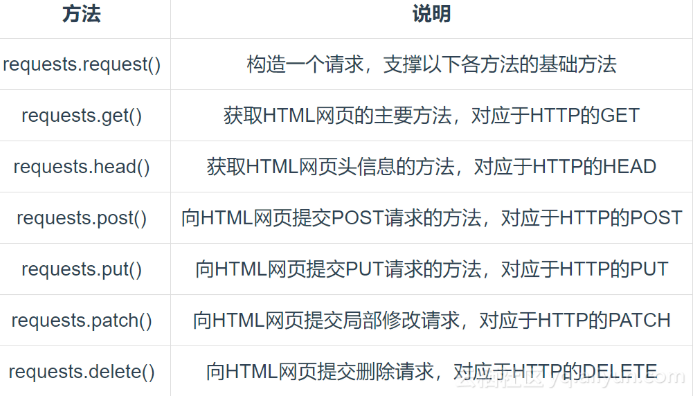
requests.get 方法:
1 # 使用get方法发送请求,返回包含网页数据的Response并存储到Response对象r中
2 r = requests.get(url)
- r.status_code:http 请求的返回状态,200 表示连接成功(HTTP 状态码)
- r.text:返回对象的文本内容
- r.content:猜测返回对象的二进制形式
- r.encoding:分析返回对象的编码方式
- r.apparent_encoding:响应内容编码方式(备选编码方式)
示例:分析豆瓣短评网页
1 import requests
2
3 url = ' https://book.douban.com/subject/27147922/?icn=index-editionrecommend'
4 r = requests.get(url, timeout=20) # 设置超时时间为20秒
5 # #print(r.text) # 打印返回文本
6 # 抛出异常
7 print(r.raise_for_status()) # None
3. urlretrieve()
用于直接将远程数据下载到本地。
- filename:指定了保存本地路径(如果参数未指定,urllib 会生成一个临时文件保存数据)。
- reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
- data:指post导服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
示例 1:下载图片
使用 urlretrieve():
1 from urllib.request import urlretrieve
2
3 urlretrieve("http://pic1.win4000.com/pic/b/20/b42b4ca4c5_250_350.jpg", "e:\\1.jpg")
使用 requests:
1 import requests
2
3 url = "http://pic1.win4000.com/pic/b/20/b42b4ca4c5_250_350.jpg"
4 r = requests.get(url)
5 with open("e:\\1.jpg", "wb") as fp:
6 fp.write(r.content)
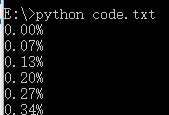
示例 2:下载文件并显示下载进度
1 import os
2 from urllib.request import urlretrieve
3
4 def cbk(a, b, c):
5 '''回调函数
6 @a:已经下载的数据块
7 @b:数据块的大小
8 @c:远程文件的大小
9 '''
10 per = 100*a*b/c
11 if per > 100:
12 per = 100
13 print('%.2f%%' % per)
14
15 url = 'http://www.python.org/ftp/python/2.7.5/Python-2.7.5.tar.bz2'
16 dir = os.path.abspath('.')
17 work_path = os.path.join(dir, 'Python-2.7.5.tar.bz2')
18 urlretrieve(url, work_path, cbk)
执行效果:
爬虫简介、requests 基础用法、urlretrieve()的更多相关文章
- 【Python爬虫】selenium基础用法
selenium 基础用法 阅读目录 初识selenium 基本使用 查找元素 元素互交操作 执行JavaScript 获取元素信息 等待 前进后退 Cookies 选项卡管理 异常处理 初识sele ...
- 爬虫3 requests基础之下载图片用content(二进制内容)
res = requests.get('http://soso3.gtimg.cn/sosopic/0/11129365531347748413/640') # print(res.content) ...
- 爬虫3 requests基础之 乱码编码问题
import requests res = requests.get('http://www.quanshuwang.com') res.encoding = 'gbk' print(res.text ...
- 爬虫3 requests基础2 代理 证书 重定向 响应时间
import requests # 代理 # proxy = { # 'http':'http://182.61.29.114.6868' # } # res = requests.get('http ...
- 爬虫3 requests基础
import requests # get实例 # res = requests.get('http://httpbin.org/get') # # res.encoding='utf-8' # pr ...
- 爬虫之requests 高级用法
1. 文件上传 import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post("http://h ...
- MongoDB简介---MongoDB基础用法(一)
Mongo MongoDB是一个基于分布式文件存储的数据库.MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的. MongoDB 将数据存储为一 ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Python爬虫十六式 - 第三式:Requests的用法
Requests: 让 HTTP 服务人类 学习一时爽,一直学习一直爽 Hello,大家好,我是Connor,一个从无到有的技术小白.今天我们继续来说我们的 Python 爬虫,上一次我们说到了 ...
随机推荐
- svn报错Previous operation has not finished; run 'cleanup' if it was interrupted
- docker 上传到docker hub 采坑
前面是仓库名称 后面可以命名img名字 docker push gaodi2345/wj:docker_gui
- 后端程序员之路 49、SSDB
正如Redis似乎是为替换memcached一样,SSSB是一个国人开发的旨在替换Redis的kv数据库. SSDB - 高性能的支持丰富数据结构的 NoSQL 数据库, 替代 Redishttp:/ ...
- 后端程序员之路 28、一个轻量级HTTP Server的实现
提到http server,一般用到的都是Apache和nginx这样的成熟软件,但是,有的情况下,我们也许也会用一些非常轻量级的http server.http server的c++轻量级实现里,M ...
- C++的指针,引用,指向指针的引用和Java中的引用
#include <iostream> #include<algorithm> using namespace std; class Test { public: Test(i ...
- HDOJ-1711(KMP算法)
Number Sequence HDOJ-1711 1.这里使用的算法是KMP算法,pi数组就是前缀数组. 2.代码中使用到了一个技巧就是用c数组看成是复合字符串,里面加一个特殊整数位-1000006 ...
- Hi3559AV100 NNIE RFCN开发:V4L2->VDEC->VPSS->NNIE->VGS->VO系统整体动态调试实现
下面随笔将给出Hi3559AV100 NNIE RFCN开发:V4L2->VDEC->VPSS->NNIE->VGS->VO系统整体动态调试实现,最终的效果是:USB摄像 ...
- .NET并发编程-反应式编程
本系列学习在.NET中的并发并行编程模式,实战技巧 本小节开始学习反应式编程.本系列保证最少代码呈现量,虽然talk is cheap, show me the code被奉为圭臬,我的学习习惯是,只 ...
- Flink实时计算topN热榜
TopN的常见应用场景,最热商品购买量,最高人气作者的阅读量等等. 1. 用到的知识点 Flink创建kafka数据源: 基于 EventTime 处理,如何指定 Watermark: Flink中的 ...
- apktool 回编译报错:No resource identifier found for attribute 'xxxxxx' in package 'android' W:
C:\xxxx\app-release\res\layout-v26\xxxx.xml:5: error: No resource identifier found for attribute 'xx ...