使用numba加速python科学计算
技术背景
python作为一门编程语言,有非常大的生态优势,但是其执行效率一直被人诟病。纯粹的python代码跑起来速度会非常的缓慢,因此很多对性能要求比较高的python库,需要用C++或者Fortran来构造底层算法模块,再用python进行上层封装的方案。在前面写过的这篇博客中,介绍了使用f2py将fortran代码编译成动态链接库的方案,这可以认为是一种“事前编译”的手段。但是本文将要介绍一种即时编译(Just In Time,简称JIT)的手段,也就是在临近执行函数前,才对其进行编译。以下截图来自于参考链接4,讲述了关于常见的一些编译场景的区别:

用numba.jit加速求平方和
numba中大部分加速的函数都是通过装饰器(decorator)来实现的,关于python中decorator的使用方法和场景,在前面写过的这篇博客中有比较详细的介绍,让我们直接使用numba的装饰器来解决一些实际问题。这里的问题场景是,随便给定一个数列,在不用求和公式的情况下对这个数列的所有元素求平方和,即:
\]
我们已知类似于这种求和的形式,其实是有很大的优化空间的,相比于直接用一个for循环来求解的话。这里我们直接展示一下案例代码:
# test_jit.py
from numba import jit
import time
import matplotlib.pyplot as plt
def adder(max): # 普通的循环求解
s = 0
for i in range(max):
s += i ** 2
return s
@jit(nopython=True)
def jit_adder(max): # 使用即时编译求解
s = 0
for i in range(max):
s += i ** 2
return s
if __name__ == '__main__':
time_adder = []
time_jit_adder = []
x = list(range(1, 10000000, 500000))
for i in x:
time1 = time.time()
s = adder(i)
time2 = time.time()
s = jit_adder(i)
time3 = time.time()
time_adder.append(time2 - time1)
time_jit_adder.append(time3 - time2)
# 开始作图
fig, ax1 = plt.subplots()
color = 'black'
ax1.set_xlabel('Numbers')
ax1.set_ylabel('Time (s)', color=color)
ax1.plot(x[1:], time_adder[1:], color=color, label='python')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx() # 第二个y-坐标轴
color = 'red'
ax2.set_ylabel('Time (s)', color=color)
ax2.plot(x[1:], time_jit_adder[1:], color=color, label='jit')
ax2.tick_params(axis='y', labelcolor=color)
plt.title('Running time difference via using jit')
fig.tight_layout()
plt.legend()
plt.savefig('jit.png')
运行该python文件,会在当前目录下产生一个双坐标轴的图像:
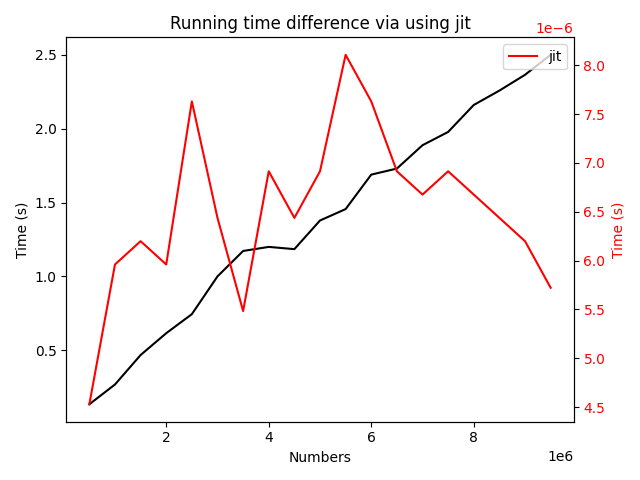
在这个计算结果中,使用了即时编译技术之后,求解的时间几乎被压缩到了微秒级别,而循环求和的方法却已经达到了秒级,加速倍数在\(10^5\)级别。
用numba.jit加速求双曲正切函数和
在上一个案例中,也许涉及到的计算过于的简单,导致了加速倍数超出了想象的情况。因此这里我们只替换所求解的函数,看看加速的倍数是否会发生变化。这里我们采用了双曲正切求和的函数:
\]
通过math来实现这个函数的计算,用以替换上一章节中求平方值的方法:
# test_jit.py
from numba import jit
import time
import matplotlib.pyplot as plt
import math
def adder(max):
s = 0
for i in range(max):
s += math.tanh(i ** 2)
return s
@jit(nopython=True)
def jit_adder(max):
s = 0
for i in range(max):
s += math.tanh(i ** 2)
return s
if __name__ == '__main__':
time_adder = []
time_jit_adder = []
x = list(range(1, 10000000, 500000))
for i in x:
time1 = time.time()
s = adder(i)
time2 = time.time()
s = jit_adder(i)
time3 = time.time()
time_adder.append(time2 - time1)
time_jit_adder.append(time3 - time2)
fig, ax1 = plt.subplots()
color = 'black'
ax1.set_xlabel('Numbers')
ax1.set_ylabel('Time (s)', color=color)
ax1.plot(x[1:], time_adder[1:], color=color, label='python')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'red'
ax2.set_ylabel('Time (s)', color=color)
ax2.plot(x[1:], time_jit_adder[1:], color=color, label='jit')
ax2.tick_params(axis='y', labelcolor=color)
plt.title('Running time difference via using jit')
fig.tight_layout()
plt.legend()
plt.savefig('jit.png')
最终得到的时间对比图结果如下所示:
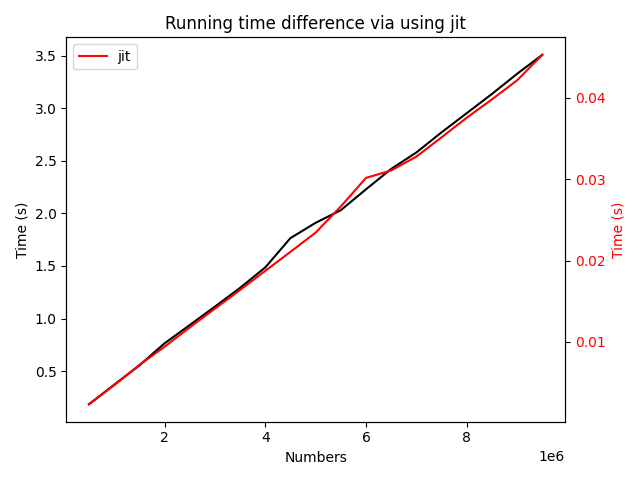
需要提醒的是,黑色的曲线所对应的坐标轴是左边黑色标识的坐标轴,而红色的曲线所对应的坐标轴是右边红色标识的坐标轴。因此,这个图给我们的提示信息是,使用即时编译技术之后,加速的倍率大约为\(10^2\)。这个加速倍率相对来说更加可以接受,因为C++等语言比python直接计算的速度在特定场景下大概就是要快上几百倍。
用numba.vectorize执行向量化计算
关于向量化计算的原理和方法,在这篇文章中有比较好的描述,这里放上部分截图说明:
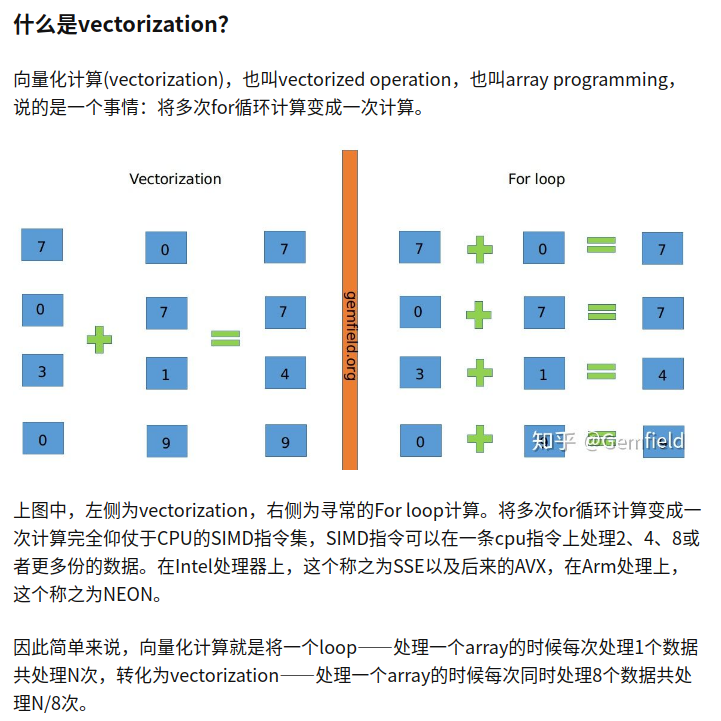

总结为,向量化计算的方法本质上也是一种并行化计算的方法,并行化技术的可行性是来源于SIMD技术,在指令集的层面对数据进行并行化的处理。在numpy的库中是自带支持SIMD的向量化计算的,因此速度非常的高,比如numpy.dot函数就是通过向量化计算来实现的。但是numpy能够执行的任务仅仅局限在numpy自身所支持的有限的函数上,因此如果是需要一个不同的函数,那么就需要用到numba的向量化计算模块了。
# test_vectorize.py
from numba import vectorize
import numpy as np
import time
import matplotlib.pyplot as plt
def ddot(max):
s = 0
np.random.seed(1)
a1 = np.random.randn(max)
np.random.seed(2)
a2 = np.random.randn(max)
for i in range(max):
s += a1[i] * a2[i]
return s
@vectorize
def jit_ddot(max):
s = 0
np.random.seed(1)
a1 = np.random.randn(max)
np.random.seed(2)
a2 = np.random.randn(max)
for i in range(max):
s += a1[i] * a2[i]
return s
def numpy_ddot(max):
np.random.seed(1)
a1 = np.random.randn(max)
np.random.seed(2)
a2 = np.random.randn(max)
return np.dot(a1, a2)
if __name__ == '__main__':
time_ddot = []
time_jit_ddot = []
time_numpy_ddot = []
x = list(range(1, 1000000, 50000))
for i in x:
time1 = time.time()
s = ddot(i)
time2 = time.time()
s = jit_ddot(i)
time3 = time.time()
s = numpy_ddot(i)
time4 = time.time()
time_ddot.append(time2 - time1)
time_jit_ddot.append(time3 - time2)
time_numpy_ddot.append(time4 - time3)
fig, ax1 = plt.subplots()
color = 'black'
ax1.set_xlabel('Numbers')
ax1.set_ylabel('Time (s)', color=color)
ax1.plot(x[1:], time_ddot[1:], color=color, label='python')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'red'
ax2.set_ylabel('Time (s)', color=color)
ax2.plot(x[1:], time_jit_ddot[1:], color=color, label='jit')
ax2.plot(x[1:], time_numpy_ddot[1:], 's', color=color, label='numpy')
ax2.tick_params(axis='y', labelcolor=color)
plt.title('Running time difference via using jit')
fig.tight_layout()
plt.legend()
plt.savefig('jit.png')
运行结果如下:
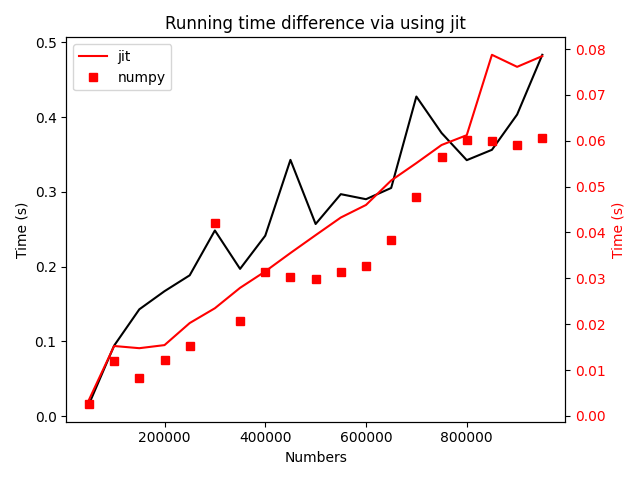
可以看到虽然相比与numpy的同样的向量化计算方法,numba速度略慢一些,但是都比纯粹的python代码性能要高两个量级。这里也给我们一个启发,如果追求极致的性能,最好是尽可能的使用numpy中已有的函数。当然,在一些数学函数的计算上,numpy的速度比math还是要慢上一些的,这里我们就不展开介绍了。
总结概要
本文介绍了numba的两个装饰器的原理与测试案例,以及python中两坐标轴绘图的案例。其中基于即时编译技术jit的装饰器,能够对代码中的for循环产生较大的编译优化,可以配合并行技术使用。而基于SIMD的向量化计算技术,也能够在向量的计算中,如向量间的乘加运算等场景中,实现巨大的加速效果。这都是非常底层的优化技术,但是要分场景使用,numba这个强力的工具并不能保证在所有的计算场景下都能够产生如此的加速效果。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/numba.html
作者ID:DechinPhy
更多原著文章请参考:https://www.cnblogs.com/dechinphy/
参考链接
- https://zhuanlan.zhihu.com/p/78882641
- https://blog.csdn.net/yuanzhoulvpi/article/details/105307338
- https://zhuanlan.zhihu.com/p/68805601
- https://zhuanlan.zhihu.com/p/193035135
- https://zhuanlan.zhihu.com/p/72953129
使用numba加速python科学计算的更多相关文章
- 使用numba加速python程序
前面说过使用Cython来加速python程序的运行速度,但是相对来说程序改动较大,这次就说一种简单的方式来加速python计算速度的方法,就是使用numba库来进行,numba库可以使用JIT技术即 ...
- windows下安装python科学计算环境,numpy scipy scikit ,matplotlib等
安装matplotlib: pip install matplotlib 背景: 目的:要用Python下的DBSCAN聚类算法. scikit-learn 是一个基于SciPy和Numpy的开源机器 ...
- Python科学计算(二)windows下开发环境搭建(当用pip安装出现Unable to find vcvarsall.bat)
用于科学计算Python语言真的是amazing! 方法一:直接安装集成好的软件 刚开始使用numpy.scipy这些模块的时候,图个方便直接使用了一个叫做Enthought的软件.Enthought ...
- 目前比较流行的Python科学计算发行版
经常有身边的学友问到用什么Python发行版比较好? 其实目前比较流行的Python科学计算发行版,主要有这么几个: Python(x,y) GUI基于PyQt,曾经是功能最全也是最强大的,而且是Wi ...
- Python科学计算之Pandas
Reference: http://mp.weixin.qq.com/s?src=3×tamp=1474979163&ver=1&signature=wnZn1UtW ...
- Python 科学计算-介绍
Python 科学计算 作者 J.R. Johansson (robert@riken.jp) http://dml.riken.jp/~rob/ 最新版本的 IPython notebook 课程文 ...
- Python科学计算库
Python科学计算库 一.numpy库和matplotlib库的学习 (1)numpy库介绍:科学计算包,支持N维数组运算.处理大型矩阵.成熟的广播函数库.矢量运算.线性代数.傅里叶变换.随机数生成 ...
- Python科学计算基础包-Numpy
一.Numpy概念 Numpy(Numerical Python的简称)是Python科学计算的基础包.它提供了以下功能: 快速高效的多维数组对象ndarray. 用于对数组执行元素级计算以及直接对数 ...
- Python科学计算PDF
Python科学计算(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1VYs9BamMhCnu4rfN6TG5bg 提取码:2zzk 复制这段内容后打开百度网盘手机A ...
随机推荐
- Java常用类:Arrays类
一.简介 全类名:java.util.Arrays 描述: 此类包含用来操作数组(比如排序和搜索)的各种方法. 此类还包含一个允许将数组作为列表来查看的静态工厂. 注意: 除非特别注明,否则如果指定数 ...
- 清华大学-成绩排序(排序+解决MLE问题)
成绩排序 成绩排序 这里需要注意的就是超内存的问题. 解决方法就是通过指针的方式,每次动态开n大小的内存,而不是一开始就分配. #include<bits/stdc++.h> using ...
- SpringBoot启动流程分析原理(一)
我们都知道SpringBoot自问世以来,一直有一个响亮的口号"约定优于配置",其实一种按约定编程的软件设计范式,目的在于减少软件开发人员在工作中的各种繁琐的配置,我们都知道传统的 ...
- Idea 报错 xxxx too long
问题:写单元测试,debug时,报错如下图 解决方法1: 在项目/.idea/workspace.xml文件中添加一行代码如下 <component name="PropertiesC ...
- Typora的一些快捷键
语法格式 快捷键 标题 # + 空格 = 一级标题, ## + 空格 =二级标题, 以此类推 shift + 数字1 =一级标题 ,shift + 数字2 =二级标题 , 以此类推 有序列表 1 ...
- 2019 南京网络赛 B super_log 【递归欧拉降幂】
一.题目 super_log 二.分析 公式很好推出来,就是$$a^{a^{a^{a^{...}}}}$$一共是$b$个$a$. 对于上式,由于指数太大,需要降幂,这里需要用到扩展欧拉定理: 用这个定 ...
- windows使用vscode设置免密登录linux服务器
秘钥原理解释 id_rsa.pub是公钥,部署在服务器上 id_rsa是私钥,放在windows本地 本质上它们都是个文本文件 操作流程 生成秘钥对(windows和linux均可) ssh-keyg ...
- 基于sk_learn的k近邻算法实现-mnist手写数字识别且要求97%以上精确率
1. 导入需要的库 from sklearn.datasets import fetch_openml import numpy as np from sklearn.neighbors import ...
- [go-linq]-Go的.NET LINQ式查询方法
关于我 我的博客|文章首发 开发者的福音,go也支持linq了 坑爹的集合 go在进行集合操作时,有很不舒服的地方,起初我真的是无力吐槽,又苦于找不到一个好的第三方库,只能每次写着重复代码.举个栗子 ...
- 微信小程序实现搜索关键词高亮
目录 1,前言 2,思路 3,代码逻辑 1,前言 项目中碰到一个需求,搜索数据并且关键词要高亮显示,接到需求,马上开干.先上效果图.源码已经做成了小程序代码片段,放入了GitHub了,文章底部有源码链 ...