初识python 之 自动拆分转换文本内容
上一篇升级版,转换文件内容。


#!/user/bin env python
# author:Simple-Sir
# time:2021/7/9 23:32 def txt_2_list(filename):
dic = {}
dic_k = []
dic_v = []
with open(filename,'r',encoding='utf-8') as f:
for i in f.readlines():
j = i.strip('\n') # 删除换行符
li_k = j.split(',') # 以逗号分隔为列表
if len(li_k) == 2:
dic[li_k[0]] = li_k[1]
dic_k.append(li_k[0])
dic_v.append(li_k[1])
else:
dic_k.append(li_k[0])
return dic,dic_k,dic_v def get_word_in_list(info,dic_k):
word_li = []
while len(info) > 0:
m = 0
n = 0
for i in range(len(info)+1):
if info[:i] in dic_k:
word_li.append(info[:i])
info = info[i:]
n = 1
m = i
if n == 0:
word_li.append(info[0:1])
info = info[m+1:]
return word_li def translat_word(word_li,dic,dic_k):
get_v = []
for i in word_li:
if i in dic_k:
get_v.append(dic[i])
else:
get_v.append(i)
re_w = ('_').join(get_v)
return re_w if __name__ == '__main__':
dict_file = 'dir'
info_file = 'infofile'
info_k=txt_2_list(info_file)[1]
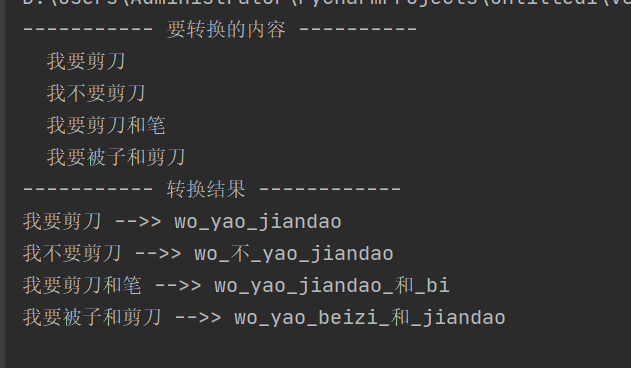
print('----------- 要转换的内容 ----------\n ',('\n ').join(info_k))
print('----------- 转换结果 ------------')
for info in info_k:
dic,dic_k,dic_v = txt_2_list(dict_file)
word_li = get_word_in_list(info, dic_k)
tw = translat_word(word_li,dic,dic_k)
print('%s -->> %s'%(info,tw))
自动拆分并转换文件内容
字典库:
剪刀,jiandao
被子,beizi
笔,bi
我,wo
要,yao

要转换的文件内容:
我要剪刀
我不要剪刀
我要剪刀和笔
我要被子和剪刀
转换结果:
初识python 之 自动拆分转换文本内容的更多相关文章
- python读取、写入txt文本内容
转载:https://blog.csdn.net/qq_37828488/article/details/100024924 python常用的读取文件函数有三种read().readline().r ...
- 初识python: 字符编码转换
指定当前文件编码格式:#-*- coding:utf-8 -*-unicode(万国码): 英文字母 1个字节,中文3个字节python中所有的字符都是unicode编码所有非unicode编码互转都 ...
- 对于pycharm和vscode下,从外部复制文本内容为python字符串内容是会自动加\u202a解决办法
先来看下这个python3源代码,表面上看没有语法毛病,如果源代码字符串内容是手动复制过来的文本内容,在pycharm和vscode下始终提示: pywintypes.error: (2, 'Shel ...
- Python: 转换文本编码
最近在做周报的时候,需要把csv文本中的数据提取出来制作表格后生产图表. 在获取csv文本内容的时候,基本上都是用with open(filename, encoding ='UTF-8') as f ...
- 利用Python imaplib和email模块 读取邮件文本内容及附件内容
python使用imap接收邮件的过程探索 https://www.cnblogs.com/yhlx/archive/2013/03/22/2975817.html #! encoding:utf8 ...
- Cleave.js – 自动格式化表单输入框的文本内容
Cleave.js 有一个简单的目的:帮助你自动格式输入的文本内容. 这个想法是提供一个简单的方法来格式化您的输入数据以增加输入字段的可读性.通过使用这个库,您不需要编写任何正则表达式来控制输入文本的 ...
- 转换 Html 内容为纯文本内容(html,文本互转)
转自http://www.cnblogs.com/jyshi/archive/2011/08/09/2132762.html : /// <summary> /// 转换纯文本内容为 HT ...
- css为超过一定宽度的文本内容自动加上省略号
当在html中某个地方添加文本内容的时候如果内容过长我们会希望他超过一定宽度之后,其余的可以被截断,后面补充为省略号: 实现方式: 1.设置css样式为文本不换行: 2.位包裹文本的标签指定宽度: 3 ...
- jq选择器(jq 与 js 互相转换),jq操作css样式 / 文本内容, jq操作类名,jq操作全局属性,jq获取盒子信息,jq获取位置信息
jq选择器(jq 与 js 互相转换) // 获取所有的页面元素jq对象 $('css3选择器语法'); var $box = $(".box:nth-child(1)"); 获取 ...
随机推荐
- css clip样式 属性功能及作用
clip clip 在学前端的小伙伴前,估计是很少用到的,代码中也是很少看见的,但是,样式中有这样的代码,下面让我们来讲讲他吧! 这个我也做了很久的开发没碰到过这个属性,知道我在一个项目中,有一个功能 ...
- 什么是maven(一)
转自博主--一杯凉茶 我记得在搞懂maven之前看了几次重复的maven的教学视频.不知道是自己悟性太低还是怎么滴,就是搞不清楚,现在弄清楚了,基本上入门了.写该篇博文,就是为了帮助那些和我一样对于m ...
- 深度学习初探——符号式编程、框架、TensorFlow
一.命令式编程(imperative)和符号式编程(symblic) 命令式: import numpy as np a = np.ones(10) b = np.ones(10) * 2 c = b ...
- linux系统目录初识
目录 今日内容概要 内容详细 系统目录结构介绍 目录结构知识描述 今日内容概要 系统目录结构介绍 目录结构详细描述 内容详细 系统目录结构介绍 # 1.linux系统中的目录 一切从根开始 结构拥有层 ...
- shell脚本 awk实现查看ip连接数
一.简介 处理文本,是awk的强项了. 无论性能已经速度都是让人惊叹! 二.使用 适用:centos6+ 语言:英文 注意:无 awk 'BEGIN{ while("netstat -an& ...
- java中注释、关键字、标识符,数据类型(上)
一.java中的注释(有3种) 注释:是给写代码的人看的,注释不会被执行 单行注释:用符号"//"实现 多行注释:用"/* */ " 实现 javaDoc(文档 ...
- 转:android相对布局
android相对布局 Activity布局初步 - 相对布局 1. 相对布局的基本概念 一个控件的位置它决定于它和其他控件的关系,好处:比较灵活:缺点:掌握比较复杂. 2. 相对布局常用属性介绍 这 ...
- greeting-150
拿到程序例行检查,可以看出程序是32位的程序 将程序放入ida中进入主函数查看 但是我们将程序运行一次后发现程序还运行了nao的程序 说明程序在中间还引用了nao函数,通过代码审计我们可以很直接的看到 ...
- cmcc_simplerop
这是一道系统调用+rop的题. 先来就检查一下保护. 32位程序,只开启了堆栈不可执行.ida看一下伪代码. 代码也很简洁,就是直接让你溢出.这里ida反汇编显示的v4具体ebp的距离是0x14,再加 ...
- 月薪过2w的IT程序员都是怎么做到的?
先说结论:要月入过2万,不能仅仅靠技术,更要找个肯给到这份工资的平台.也就是说,尽量去大城市,尽量去大公司. 我在上海,先说下我知道的薪资情况,基本上,只要有3年开发经验,能过大厂或外企的面试, ...